第十六课.Pytorch-geometric入门(一)
目录
- PyG安装
- 图结构基础
- 基准数据集
- Mini-Batches
- 构建GCN
PyG安装
Pytorch-geometric即PyG,是一个基于pytorch的图神经网络框架。其官方链接为:PyG
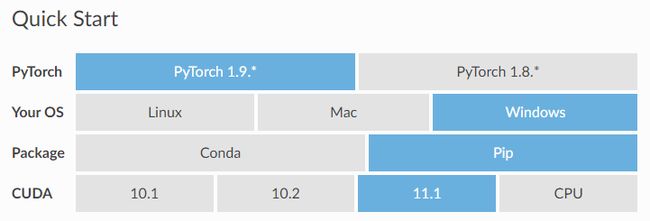
在安装PyG之前,我们需要先安装好pytorch,建议使用更高版本的pytorch,比如 pytorch1.9.x + cuda11.1,然后使用pip安装,对于windows系统,我们可以做以下操作:
pip install torch-scatter torch-sparse torch-cluster torch-spline-conv torch-geometric -f https://pytorch-geometric.com/whl/torch-1.9.0+cu111.html
图结构基础
在PyG中,一个Graph被定义为 g = ( X , ( I , E ) ) g=(X,(I,E)) g=(X,(I,E)),其中, X X X表示节点的特征矩阵, N N N为节点的个数, F F F为每个节点的特征维数;我们用元组 ( I , E ) (I,E) (I,E)表示图的邻接矩阵(COO稀疏格式), I I I是边的索引, E E E是 D D D维的边特征。
关于COO格式的稀疏矩阵
普通稀疏矩阵的最常见存储方式为坐标存储法(coordinate format),把矩阵的行列值 ( i , j , v ) (i,j,v) (i,j,v)记录下来,假设现在获得一个邻接矩阵,我们可以用COO格式保存:

观察邻接矩阵,非零的元素表示有边存在,矩阵中共有9个非零元素,因此有9条单向的边。我们从左向右,从上到下记录这些边在矩阵中的索引,以及值;例如第一条边,值为1,位于矩阵的第0行,第0列。
特别的,对于Graph,我们只考虑边的连接关系时,邻接矩阵的值就只有0和1,因此,我们可以省略COO格式中的value这个对象。
一个Graph本质是torch_geometric.data.Data的实例,它包括以下几个常见对象(属性,attributes):
data.x:节点的特征矩阵,形状为[num_nodes,num_node_features]data.edge_index:图的边索引,用COO稀疏矩阵格式保存,形状为[2,num_edgs],数据类型为torch.long;data.edge_attr:边的特征矩阵,形状为[num_edges,num_edge_features];data.y:计算损失所需的目标数据,target,针对训练的目标可能有不同的形状,比如节点级别的形状为[num_nodes,*],或者图级别的形状为[1,*];
下面我们构建一个简单的无权无向图,每个节点的特征维数为1:

import torch
from torch_geometric.data import Data
"""
边的邻接矩阵为:
[[0,1,0],
[1,0,1],
[0,1,0]]
"""
edge_index=torch.tensor([[0,1,1,2],
[1,0,2,1]],dtype=torch.long)
x=torch.tensor([[-1],[0],[1]],dtype=torch.float)
data=Data(x=x,edge_index=edge_index)
print(data) # Data(edge_index=[2, 4], x=[3, 1])
注意到,图虽然只有两条边,但我们需要定义4个索引元组来说明一条边的两个方向。
我们可以将图数据迁移到GPU上:
device=torch.device("cuda")
data=data.to(device)
基准数据集
PyG 包含大量常见的基准数据集,例如所有 Planetoid 数据集(Cora、Citeseer、Pubmed)。初始化数据集很简单。 数据集的初始化将自动下载其原始文件并将其处理为之前描述的数据格式。 例如,要加载 ENZYMES 数据集(由 6 个类别中的 600 个图组成):
from torch_geometric.datasets import TUDataset
# 第一次调用会将数据集下载保存至'./datasets'下
dataset=TUDataset(root='./datasets',name='ENZYMES')
print(dataset) # ENZYMES(600)
print(len(dataset)) # 600
print(dataset.num_classes) # 6
print(dataset.num_node_features) # 3
我们现在可以访问数据集中的所有 600 个图:
data=dataset[0]
print(data) # Data(edge_index=[2, 168], x=[37, 3], y=[1])
print(data.is_undirected()) # True
我们可以看到数据集中的第一个图包含 37 个节点,每个节点有 3 个特征。 有 168/2 = 84 条无向边,并且该图恰好分配给一个类。 此外,数据对象正好持有一个图级别目标。
现在,我们下载 Cora,一个半监督图节点分类的基准数据集:
from torch_geometric.datasets import Planetoid
dataset=Planetoid(root='./datasets',name='Cora')
print(len(dataset)) # 1, 只有1个图
print(dataset.num_classes) # 7
print(dataset.num_node_features) # 1433
在这里,数据集仅包含一个无向图:
data=dataset[0]
print(data.is_undirected()) # True
print(data.num_nodes) # 2708
print(data.train_mask.sum().item()) # 140
print(data.val_mask.sum().item()) # 500
print(data.test_mask.sum().item()) # 1000
这次,Data对象为每个节点保存了一个标签,以及附加的节点级属性:train_mask,val_mask,test_mask,其中:
train_mask:表示针对哪些节点进行训练(140个节点);val_mask:表示针对哪些节点进行验证(500个节点);test_mask:表示针对哪些节点进行测试(1000个节点);
Mini-Batches
神经网络通常以批处理方式进行训练。 PyG 通过创建稀疏块对角邻接矩阵(由 edge_index 定义)并在节点维度中连接特征和目标矩阵来实现小批量的并行化。 这种组合允许在一批中的示例上有不同数量的节点和边。
PyG 包含自己的 torch_geometric.loader.DataLoader,它已经负责这个串联过程。 我们通过一个例子来了解它:
from torch_geometric.datasets import TUDataset
from torch_geometric.data import DataLoader
dataset=TUDataset(root='./datasets',name='ENZYMES')
loader=DataLoader(dataset,batch_size=32,shuffle=True)
for batch in loader:
print(batch.num_graphs) # 32
torch_geometric.data.Batch 继承自 torch_geometric.data.Data 并包含一个名为 batch 的附加属性。batch是一个列向量,它将每个节点映射到批处理中的相应图中。
构建GCN
现在我们使用一个简单的GCN层并在Cora引文数据集上复现实验。
首先加载Cora数据集:
from torch_geometric.datasets import Planetoid
dataset=Planetoid(root="./datasets",name="Cora")
现在实现一个两层GCN:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
class GCN(nn.Module):
def __init__(self):
super().__init__()
self.conv1=GCNConv(dataset.num_node_features,16)
self.conv2=GCNConv(16,dataset.num_classes)
def forward(self,data):
x,edge_index=data.x,data.edge_index
x=self.conv1(x,edge_index)
x=F.relu(x)
x=F.dropout(x)
x=self.conv2(x,edge_index)
# print(x.size()) # torch.Size([2708, 7])
return F.log_softmax(x,dim=-1)
定义损失函数和优化方法,训练模型:
device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model=GCN().to(device)
data=dataset[0].to(device)
print(data) # Data(edge_index=[2, 10556], test_mask=[2708], train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])
print(data.num_nodes) # 2708
optimizer=torch.optim.Adam(model.parameters(),lr=0.01,weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out=model(data)
loss=F.nll_loss(out[data.train_mask],data.y[data.train_mask])
loss.backward()
optimizer.step()
最后在测试节点上评估模型:
model.eval()
pred = model(data).argmax(dim=-1) # argmax返回最大值的索引
print(pred.size()) # torch.Size([2708])
print(pred[data.test_mask].size()) # torch.Size([1000])
print(data.test_mask) # bool型, torch.Size([2708])
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print('Accuracy: {}'.format(acc)) # Accuracy: 0.775