ICLR 2022 | 视觉Transformer超越ResNet!从头开始训练!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:集智书童
 When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations
When Vision Transformers Outperform ResNets without Pretraining or Strong Data Augmentations
论文:https://arxiv.org/abs/2106.01548
本文证明了在没有大规模预训练或强数据增广的情况下,在ImageNet上从头开始训练时,所得ViT的性能优于类似大小和吞吐量的ResNet!而且还拥有更敏锐的注意力图。
作者单位:谷歌, UCLA
1简介
Vision Transformers(ViTs)和MLPs标志着在用通用神经架构替换手动特征或归纳偏置方面的进一步努力。现有工作通过大量数据为模型赋能,例如大规模预训练和/或重复的强数据增广,并且还报告了与优化相关的问题(例如,对初始化和学习率的敏感性)。
因此,本文从损失几何的角度研究了ViTs和MLP-Mixer,旨在提高模型在训练和推理时的泛化效率。可视化和Hessian揭示了收敛模型极其敏感的局部最小值。
同时通过使用最近提出的锐度感知优化器提高平滑度,进而大大提高了ViT和MLP-Mixer在跨越监督、对抗、对比和迁移学习(例如,+5.3% 和 +11.0%)的各种任务上的准确性和鲁棒性使用简单的Inception进行预处理,ViT-B/16和Mixer-B/16在ImageNet上的准确率分别为Top-1)。
作者研究表明,改进的平滑度归因于前几层中较稀疏的活动神经元。在没有大规模预训练或强数据增强的情况下,在ImageNet上从头开始训练时,所得 ViT的性能优于类似大小和吞吐量的ResNet。同时还拥有更敏锐的注意力图。
2Background和Related Work
最近的研究发现,ViT中的self-attention对性能并不是至关重要的,因此出现了一些专门基于mlp的架构。这里作者以MLP-Mixer为例。MLP-Mixer与ViT共享相同的输入层;也就是说,它将一个图像分割成一系列不重叠的Patches/Toekns。然后,它在torkn mlp和channel mlp之间交替使用,其中前者允许来自不同空间位置的特征融合。
3ViTs和MLP-Mixers收敛到锐局部极小值
目前的ViTs、mlp-mixer和相关的无卷积架构的训练方法很大程度上依赖于大量的预训练或强数据增强。它对数据和计算有很高的要求,并导致许多超参数需要调整。
现有的研究表明,当在ImageNet上从头开始训练时,如果不结合那些先进的数据增强,尽管使用了各种正则化技术(例如,权重衰减,Dropout等)ViTs的精度依然低于类似大小和吞吐量的卷积网络。同时在鲁棒性测试方面,vit和resnet之间也存在较大的差距。
此外,Chen等人发现,在训练vit时,梯度会出现峰值,导致精确度突然下降,Touvron等人也发现初始化和超参数对训练很敏感。这些问题其实都可以归咎于优化问题。
在本文中,作者研究了ViTs和mlp-mixer的损失情况,从优化的角度理解它们,旨在减少它们对大规模预训练或强数据增强的依赖。
3.1 ViTs和MLP-Mixers收敛到极sharp局部极小值
众所周知,当模型收敛到曲率小的平坦区域时模型会具有更好的泛化性能。在[36]之后,当resnet、vit和MLP-Mixers在ImageNet上使用基本的初始风格预处理从头开始训练时,作者绘制损失图:

如图1(a)到1(c)所示,ViTs和mlp-mixer比ResNets收敛到更清晰的区域。
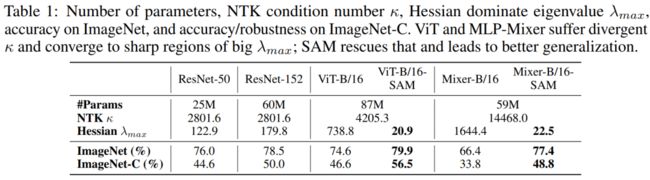
在表1中,通过计算主要的Hessian特征值进一步验证了结果。ViT和MLP-Mixer的值比ResNet大一个数量级,并且MLP-Mixer的曲率在3种中是最大的(具体分析见4.4节)。
3.2 Small training errors
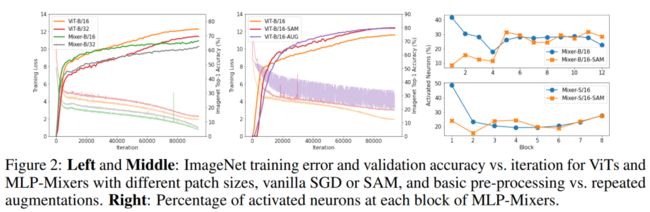
这种向sharp区域的收敛与图2(左)所示的训练动态一致。尽管Mixer-B/16参数少于ViT-B/16(59M vs 87M),同时它有一个小的训练误差,但测试性能还是比较差的,这意味着使用cross-token MLP学习的相互作用比ViTs’ self-attention机制更容易过度拟合。这种差异可能解释了mlp-mixer更容易陷入尖锐的局部最小值。
3.3 ViTs和MLP-Mixers的可训练性较差
此外,作者还发现ViTs和MLP-Mixers的可训练性较差,可训练性定义为通过梯度下降优化的网络的有效性。Xiao等人的研究表明,神经网络的可训练性可以用相关的神经切线核(NTK)的条件数来表征:
其中是雅可比矩阵。
用表示NTK 的特征值,最小的特征值以条件数κ的速率指数收敛。如果κ是发散的,那么网络将变得不可训练。如表1所示,ResNets的κ是相当稳定的,这与之前的研究结果一致,即ResNets无论深度如何都具有优越的可训练性。然而,当涉及到ViT和时,条件数是不同的MLP-Mixer,证实了对ViTs的训练需要额外的辅助。
4CNN-Free视觉架构优化器原理
常用的一阶优化器(如SGD,Adam)只寻求最小化训练损失。它们通常会忽略与泛化相关的高阶信息,如曲率。然而,深度神经网络的损失具有高度非凸性,在评估时容易达到接近0的训练误差,但泛化误差较高,更谈不上在测试集具有不同分布时的鲁棒性。
由于对视觉数据缺乏归纳偏差ViTs和MLPs放大了一阶优化器的这种缺陷,导致过度急剧的损失scene和较差的泛化性能,如前一节所示。假设平滑收敛时的损失scene可以显著提高那些无卷积架构的泛化能力,那么最近提出的锐度感知最小化(SAM)可以很好的避免锐度最小值。
4.1 SAM:Overview
从直觉上看,SAM寻找的是可以使整个邻近训练损失最低的参数w,训练损失通过构造极小极大目标:
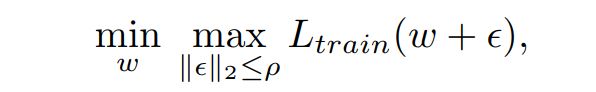
其中是neighbourhood ball的大小。在不失一般性的情况下,这里使用范数作为其强经验结果,这里为了简单起见省略了正则化项。
由于内部最大化下式的确切解很难获得:

因此,这里采用了一个有效的一阶近似:
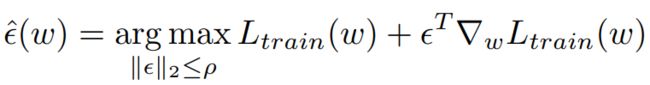
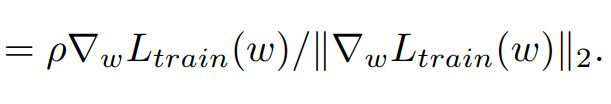
在范数下,是当前权值的缩放梯度。计算后,SAM基于锐度感知梯度更新w。
4.2 SAM优化器实质上改进了ViTs和MLP-Mixers
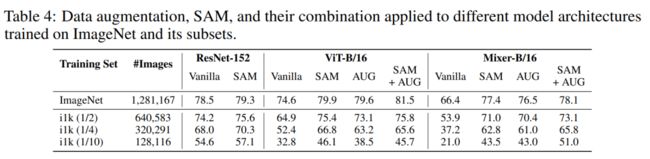
作者在没有大规模的预训练或强大的数据增强的情况下训练了vit和MLP-Mixers。直接将SAM应用于vit的原始ImageNet训练pipeline,而不改变任何超参数。pipeline使用了基本的Inception-style的预处理。最初的mlp-mixer的训练设置包括强数据增强的组合;也用同样的Inception-style的预处理来替换它,以便进行公平的比较。
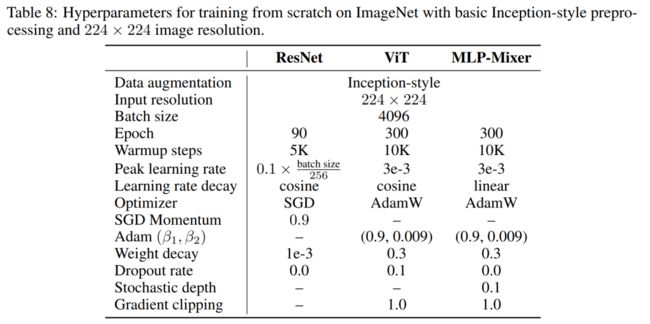
注意,在应用SAM之前,我们对学习速率、权重衰减、Dropout和随机深度进行网格搜索。
1 局部极小值周围的平滑区域
由于SAM, ViTs和mlp-mixer都汇聚在更平滑的区域,如图1(d)和1(e)所示。
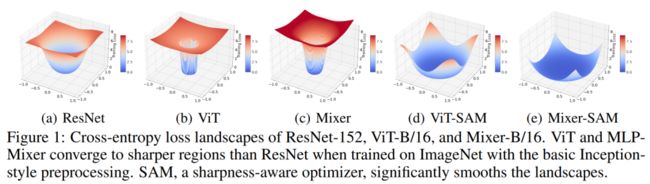
曲率测量,即Hessian矩阵的最大特征值,也减小到一个小值(见表1)。
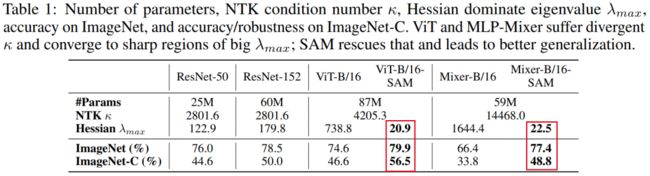
2 Higher accuracy
随之而来的是对泛化性能的极大改进。在ImageNet验证集上,SAM将ViT-B/16的top-1精度从74.6%提高到79.9%,将Mixer-B/16的top-1精度从66.4%提高到77.4%。
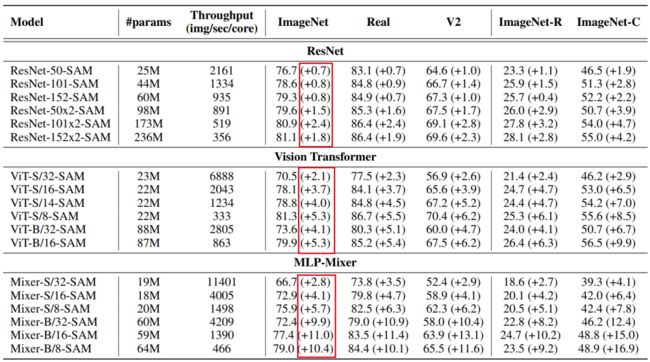
相比之下,类似规模的ResNet-152的性能提高了0.8%。根据经验,改进的程度与架构中内置的归纳偏差水平呈负相关。与基于注意力的ViTs相比,具有inherent translation equivalence和locality的ResNets从landscape smoothing中获益较少。MLP-Mixers从平滑的loss geometry中获得最多。
此外,SAM对更大容量(例如:+4.1%的Mixer-S/16 vs. +11.0%的Mixer-B/16)和更长的patch序列(例如:+2.1%的vits/32 vs. +5.3%的vits /8)的模型带来了更大的改进。
3 Better robustness
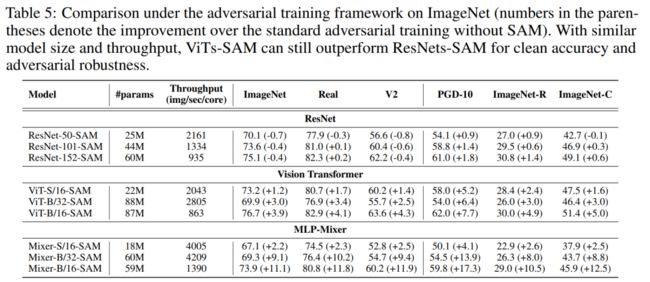
作者还使用ImageNet-R和ImageNetC评估了模型的鲁棒性,并发现了smoothed loss landscapes的更大影响。在ImageNet-C上,它通过噪音、恶劣天气、模糊等来破坏图像,实验了5种严重程度上19种破坏的平均精度。如表1和表2所示, ViT-B/16和Mixer-B/16的精度分别增加了9.9%和15.0%。
4.3 无需预训练或强大的数据增强ViTs优于ResNets
模型体系结构的性能通常与训练策略合并,其中数据增强起着关键作用。然而,数据增广的设计需要大量的领域专业知识,而且可能无法在图像和视频之间进行转换。由于有了锐度感知优化器SAM,可以删除高级的数据增强,并专注于体系结构本身(使用基本的Inception-style的预处理)。
当使用SAM在ImageNet上从0开始训练时,ViT的准确性(在ImageNet、ImageNet-Real和ImageNet V2上)和健壮性(在ImageNet-R和ImageNet-R上)方面都优于类似和更大的ResNet(在推理时也具有相当的吞吐量)。
ViT-B/16在ImageNet、ImageNet-r和ImageNet-C上分别达到79.9%、26.4%和56.6%的top精度,而对应的ResNet-152则分别达到79.3%、25.7%和52.2%(见表2)。对于小型架构,vit和resnet之间的差距甚至更大。在ImageNet上,ViT-S/16的表现比同样大小的ResNet-50好1.4%,在ImageNet-C上好6.5%。SAM还显著改善了MLP-Mixers的结果。
4.4 SAM后的内在变化
作者对模型进行了更深入的研究,以理解它们如何从本质上改变以减少Hessian的特征值以及除了增强泛化之外的变化意味着什么。
结论1:每个网络组件具有Smoother loss landscapes
在表3中,将整个体系结构的Hessian分解成与每一组参数相关的小的斜对角Hessian块,试图分析在没有SAM训练的模型中,是什么特定的成分导致爆炸。
作者观察到较浅的层具有较大的Hessian特征值,并且第1个linear embedding layer产生sharpest的几何形状。
此外,ViTs中的多头自注意(MSA)和MLP-Mixers中的token mlp(Token mlp)跨空间位置混合信息,其相对较低。SAM一致地降低了所有网络块的。
可以通过递归mlp的Hessian矩阵得到上述发现。设和分别为第k层激活前的值和激活后的值。它们满足
402 Payment Required
,其中 为权值矩阵, 为激活函数(mlp-mixer中的GELU)。为了简单起见,在这里省略偏置项。Hessian矩阵 相对于 的对角块可递归计算为: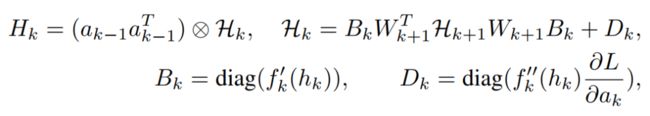
其中⊗为Kronecker product,为第层的预激活Hessian,L为目标函数。因此,当递归公式反向传播到浅层时,Hessian范数累积,这也解释了为什么表3中第一个块的比最后一个块大得多。

结论2:Greater weight norms
应用SAM后,作者发现激活后的值的范数和权重的范数变得更大(见表3),说明常用的权重衰减可能不能有效地正则化ViTs和MLP-Mixers。
结论3:MLP-Mixers中较稀疏的active neurons
根据递归公式(3)到(4),作者确定了另一个影响Hessian的MLP-Mixers的内在度量:激活神经元的数量。
事实上,是由大于零的被激活神经元决定的,因为当输入为负时,GELU的一阶导数变得非常小。因此,活跃的GELU神经元的数量直接与Hessian规范相连。
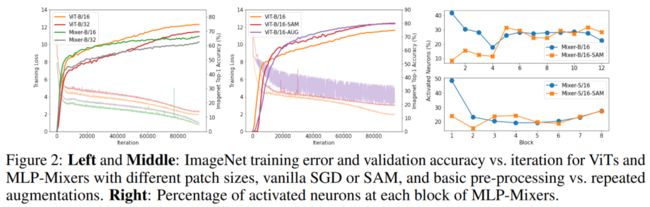
图2(右)显示了每个块中被激活的神经元的比例,使用ImageNet训练集的10%进行计算。可以看到,SAM极大地减少了前几层被激活神经元的比例,使它们处于更稀疏的状态。这一结果也说明了图像patch的潜在冗余性。
结论4:ViTs的active neurons高度稀疏
虽然公式(3)和(4)只涉及mlp,但仍然可以观察到vit的第1层激活神经元的减少(但不如MLP-Mixers显著)。更有趣的是,作者发现ViT中被激活神经元的比例比ResNets或MLP-Mixers中要小得多——在大多数ViT层中,只有不到5%的神经元的值大于零。换句话说,ViT为网络修剪提供了巨大的潜力。
这种稀疏性也可以解释为什么一个Transformer可以处理多模态信号(视觉、文本和音频)?
结论5:ViTs中有更多的感知注意力Maps

在图3中可视化了classification token的attention map。有趣的是,经过SAM优化的ViT模型能够编码合理的分割信息,比传统SGD优化训练的模型具有更好的可解释性。
结论6:Higher training errors
如图2(左)所示,使用SAM的ViT-B/16比使用vanilla SGD的训练误差更高。当在训练中使用强数据增强时,这种正则化效应也会发生,它迫使网络显式地学习RandAugment中的旋转平移等方差和mixup中的线性插值等先验。然而,增益对不同的训练设置很敏感(第5.2节),并导致高噪声损失曲线(图2(中间))。
5实验
具有smoother loss geometry的ViTs和MLP-Mixers可以更好地迁移到下游任务。

上述论文PDF下载
后台回复:0606,即可下载上述论文
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看