对象存储 S3 在分布式文件系统中的应用
当前,业内擅长非结构化数据的存储方式主要是文件存储和对象存储。文件存储和对象存储各有千秋,文件存储不仅能兼顾多个应用和多个用户访问,更突出的优势是方便文件共享;对象存储凭借灵活性和扁平架构得到了广泛的好评,容量达到 EB 级以上,实现理论上的对象存储容量和对象数量无限扩充。然而,由于对象存储的访问接口协议单一,数据访问性能较差的问题,使其可适用的范围受到了一定程度的限制。以下内容是焱融科技架构师彭德跃的部分演讲实录:
今天,我将基于当前情况的背景,给大家分享一下,焱融科技是如何解决这个难题的。
为什么需要分布式文件存储
首先,我们从业务背景开始介绍,为什么客户会需要分布式文件存储。
我们以 AI、机器学习、自动驾驶为例,他们有一个共同特点就是需要文件接口和支持海量文件存储的文件系统。同时,只有文件系统提供极高的性能,才能满足他们对业务的需求。
以焱融科技的客户为例,客户实际业务会不停地增长,为此存储也需要随着业务一起扩展。请注意,这是客户的必要需求。因为我们是软件定义的存储,且具备客户需要的功能。从部署上来说,我们支持 3 个节点部署,未来在业务持续增长过程中,可以随时扩容。同时,我们是一个 POSIX 兼容的存储,在客户业务上,不需要进行修改,可以直接在 YRCloudFile 上使用,十分便捷。

目前,上云已经发展了很多年了,基本属于既定事实。为了支持公有云部署,我们基于焱融科技核心产品 YRCloudFile 推出了焱融 SaaS 文件存储,为帮助用户在不同公有云上运行的业务创建自己的共享文件存储空间。
从高性能文件存储系统 YRCloudFile 架构图上看,可以发现我们的上层可以支撑很多客户端连接,通过以太网或者高速 InfiniBand 网络连接 YRCloudFile 分布式存储集群,其分布式存储集群是由标准 X86 服务器组建起来的,与大多数文件系统一样,我们会分为元数据集群、数据集群和管理集群。另外,我们在 X86 服务器下,对接了大多数的对象存储系统,目前已经适配的有 AWS、腾讯云、阿里云等等。
在了解到 YRCloudFile 以后,我们来详细说一下 S3 和文件系统的结合,以及为什么客户需要 S3。
这不仅仅是一个业务问题,它也是一个技术问题。我们在和客户交流的时候,通常他们都会提到一个需求——在做机器学习的过程中,由于计算量特别大,所以需要很大的存储空间,为了进一步节约成本,他们希望把部分数据存储到对象存储里。
举个例子,客户拥有 10TB 的热层空间,一次计算可能只用把部分数据加载到热层里,在完成计算以后,这部分数据可能就不用了,客户希望能将这部分数据自动上传到 S3 上。这样不仅能满足客户的业务和性能需求,又能节省他的成本,还不需要调整业务逻辑。
除此以外,我们还需要兼顾客户的数据流转,也就是数据的可访问性。比如,客户将数据放到阿里云上,他们在北京、上海都能访问到。还有一种情况是,异地调取数据,也就是当客户在北京机房产生的数据,可以上传到 S3,之后他在上海的机房,也可以读取数据,用于计算。
为了一次性满足客户这么多的需求,我们做了两个技术设计——Tiering 和 DataLoad。接下来,我将详细和大家聊一聊这两个技术设计。
冷热分层 (Tiering) 的设计
1、分清主次
首先,我们需要先从 YRCloudFile 本身出发。现在已经有很多企业已经在使用 S3 了,上面也存储了海量数据,如果我们要和 S3 结合的话,我们首先要考虑 YRCloudFile 本身的优势,比如性能、经历过实际的检验等等,并如何将产品本身优点和 S3 结合起来。
当前,业内的典型做法是 S3 文件网关,我们该如何理解它呢?举个例子,假设我在阿里云上有 1 万个对象,我在文件网关给它套一个文件接口,它最主要的功能就是我可以通过文件接口去访问数据,但是这样的做法会有一些问题:
- 难以支持读写,因为对象存储是不可修改的;
- 如果支持修改的话,处理起来会比较麻烦。再加上为了满足性能需求,你的文件网关肯定是要有本地持久化数据的;
- 在上述条件下,如果从文件网关上,把对象读到本地硬盘,那么就会存在数据安全性问题;
- 如果当本地硬盘出现故障,那么数据就容易出现问题,这时你又需要多做一个副本,这会让网关层变得很“厚重”。
在考虑到这些问题以后,我们很坚定地决定要在 YRCloudFile 上实现 S3 的应用。
2、文件切片
其次,我们还需要考虑文件是否要切片。举个例子,现在有一个 1GB 的文件,如果我们要进行文件切片,那就会被拆分为 256 个对象。
虽然文件切片与否各有利弊,但是我们从 YRCloudFile 的角度考虑,如果采取文件切片的措施,可能会改变 IO 流程,可能会对原本的性能产生影响。为此,我们采取了逻辑切片的方式,它的优势就是可以让我们有更灵活的处理方法,最主要的方面就体现在它的切片大小是可以调节的。
比如,客户使用的是阿里云,并且配置了很高的带宽。为了满足这一特点,我们可以把逻辑切片调大一些,让性能更好一些。但是如果客户业务出现转变,可能不再使用阿里云,而是使用其他价格较低的云,这时我们也可以“自适应”,无需做其他调整,让客户使用起来更方便、灵活。
3、性能
关于性能的部分,我们以看电影为例,假设我们在播放电影的时候,只想看中间的部分,实际上我可以通过 Http 接口去直接读取指定的数据段,相比物理切片来说,它的数据传输量是一样的,并不需要每次都把整个对象读取完毕。这也是一个很重要的点,它可以帮助我们提高读写性能。
具体我们是如何保证性能呢?这里,我给大家分享一下焱融科技的几大原则:
第一,我们不重复传输数据,只做数据缓存。比如你现在有 1 GB 的对象在云上,我只需要访问中间 1 MB 的数据,那么我们会把这中间 1 MB 的数据下载到本地,后续访问就会直接在本地实现,这也是我们实现 Tiering 高性能最主要的一点。
第二,在我们给文件做一个本地的索引和预读。通过本地索引,我们清晰地知道数据是否需要从 S3 上读取。通过预读机制,我们能基于用户 IO 的特点,提前从 S3 上预读数据到本地。
4、缓存模式
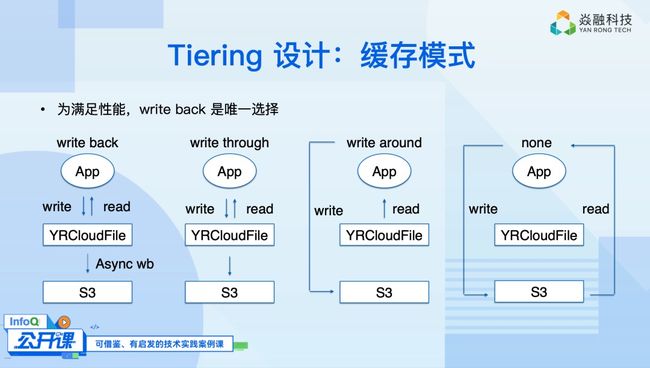
缓存相信大家都不陌生,我在这里就简单地和大家讨论我们要做一个什么样的缓存。
如上图所示,我们一共有四种模式,分别是:
- Write back 缓存,可实现直接读写;
- Write through 缓存,可同时读取 YRCloudFile 和 S3;
- Write around 缓存,可从 YRCloudFile 读取,直接写在 S3;
- None 缓存,仅支持 S3。
为了满足性能要求,我们默认采用 write back 缓存方式,从而实现了热数据被存储在热层,来满足用户的性能需求。而冷数据会被异步地 write back 到 S3,来节省热层存储空间和成本。
5、只读 or 读写
接下来,还有一个非常重点的问题,那就是支持只读还是读写,这个问题对产品整个设计有非常大的影响。
首先,我们来理解一下“只读”,它指的是我从来不会修改我的业务数据,比如现在对象在 S3 上,我只会把它下载做计算,而不会修改它。
“读写”则是我不仅需要将数据下载做计算,还需要修改数据,即便是只改一个字节,那也是做了修改的操作。大家都知道, S3 对象是不支持修改的,如果要修改,只能用修改后生成的新的 S3 对象去完整覆盖旧的 S3 对象。
为了适应更广泛的业务场景,去满足更灵活的客户需求,我们坚持支持“读写”,虽然从技术角度来看,“读写”的挑战会更大,但是它的灵活性是“只读”无法比拟的,会让用户使用起来更流畅、舒适。
6、S3 计费

除了技术角度以外,我们还考虑到了客户的费用问题。上图是某公有云的计费截图,我们可以看到 S3 的计费不仅有外网的流量费用、传输费用,还有 API 请求调用次数的费用。
如果我们不使用逻辑切片的方式,而是做比如 4MB 大小的物理切片,那么会产生大量的 S3 对象,也会产生更多的 S3 API 调用次数,继而产生更多的费用。这也是我们不做物理切片的原因之一。
DataLoad 的设计
从应用场景角度分析,企业需要数据云端互通,我们以两个典型场景为例:
第一个场景是,企业在 S3 上有一批数据,但是现在需要放在 YRCloudFile 上进行训练,并通过内置的 DataLoad 功能关联 S3 bucket,使数据直接关联到本地。
在这个场景下,我们需要去考虑,数据在关联的过程中,是否需要加载到 YRCloudFile 里,如果它不加载会出现什么情况。另外,如果要加载的话,我们是需要采用同步加载,还是异步加载呢?在不同的情况下,我们都会有相应的一个机制。
第二个场景是异地数据使用。以某家企业为例,公司总部在北京,他有一批数据需要传递到上海,通过 DataLoad 功能,他可以把北京的数据关联到 S3 上,让上海分公司可以直接访问。
为了满足上述两个场景需求,YRCloudFile DataLoad 功能应运而生,帮助企业实现一键同步数据,并可以直接用于计算,这对企业来说是非常友好的。
DataLoad 具体是如何设计的呢?实际上,它的设计和 Tiering 是非常类似的,主要是场景有所不同。实际上 DataLoad 的实现几乎是能完整复用 Tiering 的实现。
我认为其中最主要的一个原因是我们 Tiering 没有做物理切片。在不做物理切片的情况下,我们可以直接把 5GB 的数据文件关联到 YRCloudFile,S3 对象和 YRCloudFile 文件很直观地一一对应起来,这天然满足了 DataLoad 功能的用户需求和设计需求。而在做物理切片的情况下,一个 5GB 的对象需要先切成很多小块,然后才能再写回对象存储里。
用户通过 YRCloudFile DataLoad 功能,将 S3 上的数据直接关联为 YRCloudFile 文件系统中的目录和文件,直接满足用户利用 S3 上已知数据的计算需求。
比如用户在 S3 bucket 中已有 100 万个 object,现在要使用 YRCloudFile DataLoad 的话 S3 和文件系统的连接。DataLoad 会自动扫描 S3 bucket,根据 S3 object 的路径,在 YRCloudFile 中创建出对应的目录和文件,然后用户业务就可以像使用本地文件一样,使用这些 DataLoad 关联下来的 S3 数据集。
我们在实现 DataLoad 时,也做了充分的性能考虑。比如 DataLoad 在创建对象和文件的关联时,我们将其分为不同的阶段,比如扫描 S3 bucket 阶段、创建文件阶段、数据拉取阶段等,每个阶段都支持配置不同的策略,比如扫描 bucket 时,可以通过设置 pattern 去过滤需要的数据。比如在数据拉取时,我们默认配置为异步地、按需地拉取。
另外,用户在使用 DataLoad 时,除了一开始建立起对象和文件的关联后,用户可能还需要实时感知 S3 bucket 中对象的变化,比如对象的新增和删除等。YRCloudFile DataLoad 实现了订阅机制,并适配了阿里云、腾讯云等各种云产商各异的订阅通知机制,对用户提供一致的订阅功能体验。
总结
用户在处理非结构化数据过程的实践中,既需要利用文件存储的性能,又需要对象存储的成本和容量优势,我们今天讨论了 YRCloudFile Tiering 和 DataLoad 是如何满足用户业务需求的,我们讨论了 Tieiring 和 DataLoad 产品设计和技术方案的关键思路的。希望能给大家带来一些启发和帮助。最后,期待下次与大家有更多的技术交流。