深度学习的视觉跟踪:一个全面的调查
本篇文章翻译自一篇外文文献,仅供学习之用。
Deep Learning for Visual Tracking: A Comprehensive Survey
Seyed Mojtaba Marvasti-Zadeh, Student Member, IEEE, Li Cheng, Senior Member, IEEE,
Hossein Ghanei-Yakhdan, and Shohreh Kasaei, Senior Member, IEEE
摘要—视觉目标跟踪是计算机视觉中最抢手但最具挑战性的研究主题之一。鉴于病态问题的性质及其在各种实际场景中的流行程度,许多大型基准数据集已经建立,并已开发出许多方法并证明了这些方法在近年来取得了重大进展-主要是基于最近的深度学习(DL)的方法。这项调查旨在系统地调查当前基于DL的视觉跟踪方法,基准数据集和评估指标。它还广泛评估和领先的视觉跟踪方法。首先,从六个方面总结了基于DL的方法的基本特征,主要动机和贡献关键方面:网络体系结构,网络开发,视觉跟踪的网络培训练,网络目标,网络输出以及利用相关滤波器的优势。其次,比较了流行的视觉跟踪基准及其各自的属性,并总结了它们的评估指标。第三,在集合上检查基于DL的最新方法成熟的OTB2013,OTB2015,VOT2018和LaSOT基准测试。最后,通过对这些状态进行关键分析,在数量和质量上都采用了最先进的方法,研究了它们在各种常见情况下的优缺点。可以作为从业人员的使用指南,帮助他们权衡何时,在何种条件下选择哪种方法。它还有助于讨论正在进行中的问题,并阐明有前途的研究方向。
目录
Deep Learning for Visual Tracking: A Comprehensive Survey
1. 介绍
2.深层视觉跟踪方法的分类法
2.1 网络架构
2.1.1卷积神经网络(CNN)
2.1.2暹罗神经网络(SNN)
2.1.3递归神经网络(RNN)
2.1.4生成对抗网络(GAN)
2.1.5自定义网络
2.2 网络利用
2.2.1模型重用或深度可用的功能
2.2.2用于视觉跟踪的深度功能
2.3网络训练
2.3.1 仅离线培训
2.3.2仅在线培训
2.3.3离线和在线培训
2.4网络目标
2.4.1基于分类的目标函数
2.4.2基于回归的目标函数
2.4.3基于分类和回归的目标函数
2.5网络输出
3. 视觉跟踪基准数据集
3.1视觉跟踪数据集
3.2 评估指标
3.2.1 绩效考核
3.2.2 性能图
4.实验分析
4.1定量比较
4.2每个基准数据集最具挑战性的属性
4.3讨论
5 结论和未来方向
致谢
参考文献:
1. 介绍
通用视觉跟踪旨在在只有目标的初始状态(在视频帧中)可用时估计未知视觉目标的轨迹。视觉跟踪是一个开放且有吸引力的研究领域(见图1),具有广泛的类别和应用。包括自动驾驶汽车[1]-[4],自动机器人[5],[6],监视[7]-[10],增强现实[11]-[13],无人机(UAV)跟踪[ 14],体育[15],外科手术[16],生物学[17]-[19],海洋探险[20],仅举几例。在复杂的现实世界场景中,视觉跟踪(即无模型跟踪,实时学习,单镜头,2D信息)的不适定定义更具挑战性,其中可能包括任意类别的目标外观及其运动模型(例如,人,无人机,动物,车辆),不同的成像特征(例如,静态/移动摄像机,平滑/突然运动,摄像机分辨率)以及环境条件的变化(例如,照明变化,背景混乱,拥挤的场景) )。尽管传统的视觉跟踪方法利用了各种框架-例如判别相关滤波器(DCF)[21]-[24],轮廓跟踪[25],[26],内核跟踪[27]-[29],点跟踪[30], [31]等这些方法在不受约束的环境中无法提供令人满意的结果。主要原因是手工制作的目标表示形式(例如定向梯度直方图(HOG)[32]和颜色名称(CN))[33]和不灵活的目标建模。基于ImageNet大规模视觉识别竞赛(ILSVRC)[39]中深度学习(DL)的突破[34]-[38]和视觉对象跟踪(VOT)挑战[40]-[46]的启发,基于DL的方法有视觉跟踪社区吸引了很多兴趣,以提供强大的视觉跟踪器。尽管卷积神经网络(CNN)最初一直是主导网络,但是广泛的体系结构,例如暹罗神经网络(SNN),递归神经网络(RNN),自动编码器(AE),生成对抗网络(GAN)和自定义目前正在研究神经网络。
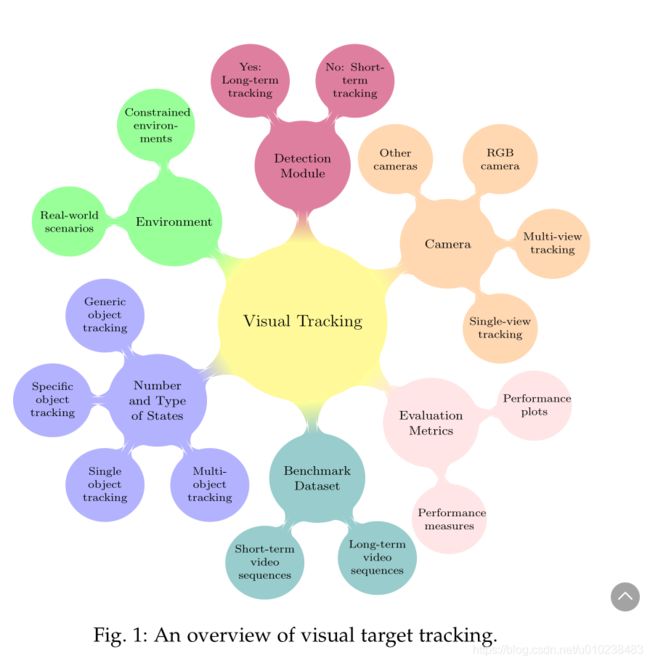
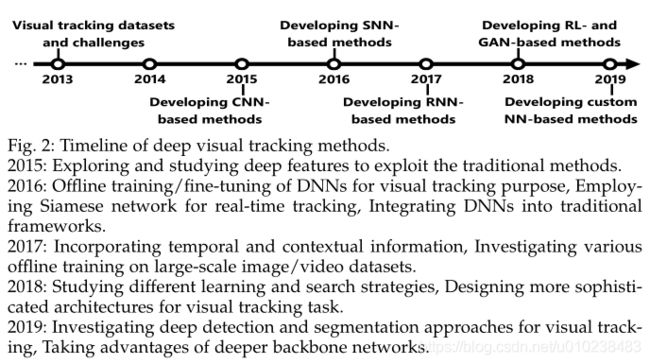
图2展示了近年来深度视觉跟踪器发展的简要历史。基于DL的最新视觉跟踪器具有独特的特性,例如对深度架构的利用,骨干网络,学习过程,训练数据集,网络目标,网络输出,所利用的深度特征的类型,CPU / GPU实施,编程语言和框架,速度等。此外,在过去的几年中,已经提出了一些视觉跟踪基准数据集,用于视觉跟踪方法的实际训练和评估。尽管具有各种属性,但其中一些基准数据集具有共同的视频序列。因此,本文提供了对基于DL的方法,其基准数据集和评估指标的比较研究,以促进视觉跟踪社区开发高级方法。
视觉跟踪方法可以大致分为DL在计算机视觉革命之前和之后的两个主要类别。第一类视觉跟踪调查论文[47]-[50]主要回顾了基于经典对象和运动表示的传统方法,然后系统地,实验性地或同时检查了它们的优缺点。考虑到基于DL的视觉跟踪器的巨大进步,这些论文的审查方法已经过时了。另一方面,第二类评论了有限的深度视觉跟踪器[51]-[53]。论文[51],[52](论文的两个版本)将81和93个手工制作的深度视觉跟踪器分为相关滤波器跟踪器和非相关滤波器跟踪器,然后应用了基于体系结构和跟踪机制的进一步分类。这些论文通过有限的研究来研究基于<40 DL的方法。尽管论文[54]特别研究了九种基于SNN的方法的网络分支,层和训练方面,但它不包括基于SNN的最新跟踪器(例如[55]-[57])以及部分利用SNN的自定义网络(例如[58])。上一篇综述文章[53]根据结构,功能和训练对43种基于DL的方法进行了分类。然后,使用不同的基于手工制作的视觉跟踪方法评估16个基于DL的视觉跟踪器。从结构的角度来看,这些跟踪器分为34种基于CNN的方法(包括10种CNN匹配和24种CNN分类),5种基于RNN的方法以及其他4种基于体系结构的方法(例如AE)。此外,从网络功能的角度来看,这些方法可分为特征提取网络(FEN)或端到端网络(EEN)。 FEN是在不同任务上利用预训练模型的方法,而EEN则根据它们的输出进行分类。即对象得分,置信度图和边界框(BB)。从网络培训的角度来看,这些方法分为NP-OL,IP-NOL,IP-OL,VP-NOL和VP-OL类别,其中NP,IP,VP,OL和NOL是缩写分别没有预训练,图像预训练,视频预训练,在线学习和没有在线学习。
尽管付出了所有努力,但没有全面的研究来不仅对基于DL的跟踪器,其动机和对不同问题的解决方案进行广泛分类,而且根据不同的挑战性场景对最佳方法进行实验性分析。 受这些关注的驱使,本次调查的主要目标是填补这一空白,并调查目前存在的主要问题和未来方向。 此调查与先前调查的主要区别如下。
与先前调查的差异:尽管目前有评论文章,但本文仅关注于129种基于DL的最新视觉跟踪方法,这些方法已在主要图像处理和计算机视觉会议和期刊上发表。这些方法包括HCFT [59],DeepSRDCF [60],FCNT [61],CNN-SVM [62],DPST [63],CCOT [64],GOTURN [65],SiamFC [66],SINT [ 67],MDNet [68],HDT [69],STCT [70],RPNT [71],DeepTrack [72],CNT [73],CF-CNN [74],TCNN [75],RDLT [76], PTAV [77],[78],CREST [79],UCT / UCT-Lite [80],DSiam / DSiamM [81],TSN [82],WECO [83],RFL [84],IBCCF [85], DTO [86],SRT [87],R-FCSN [88],GNET [89],LST [90],VRCPF [91],DCPF [92],CFNet [93],ECO [94],DeepCSRDCF [ 95],MCPF [96],BranchOut [97],DeepLMCF [98],Obli-RaFT [99],ACFN [100],SANet [101],DCFNet / DCFNet2 [102],DET [103],DRN [104] ],DNT [105],STSGS [106],TripletLoss [107],DSLT [108],UPDT [109],ACT [110],DaSiamRPN [111],RT-MDNet [112],StructSiam [113],MMLT [114],CPT [115],STP [116],Siam-MCF [117],Siam-BM [118],WAEF [119],TRACA [120],VITAL [121],DeepSTRCF [122],SiamRPN [ 123],SA-Siam [124],Flow-Track [125],DRT [126],LSART [127],RASNet [128],MCCT [129],DCPF2 [130],VDSR-SRT [131],FCSFN [132],FRPN2T-Siam [133],FMFT [134],IMLCF [135],TGGAN [136],DAT [137],DCTN [138],FPRNet [139],HCFT [140],adaDDCF [141],YCNN [142],DeepHPFT [143],CFCF [144],CFSRL [145],P2T [146],DCDCF [147],FICFNet [148],LCTdeep [149],HSTC [150],DeepFWDCF [151],CF-FCSiam [152] ,MGNet [153],ORHF [154],ASRCF [155],ATOM [156],C-RPN [157],GCT [158],RPCF [159],SPM [160],SiamDW [56],SiamMask [ 57],SiamRPN ++ [55],TADT [161],UDT [162],DiMP [163],ADT [164],CODA [165],DRRL [166],SMART [167],MRCNN [168], MM [169],MTHCF [170],AEPCF [171],IMM-DFT [172],TAAT [173],DeepTACF [174],MAM [175],ADNet [176],[177],C2FT [178] ,DRL -IS [179],DRLT [180],EAST [181],HP [182],P-Track [183],RDT [184]和SINT ++ [58]。
跟踪器包括73种基于CNN,35种基于SNN,15种基于自定义(包括基于AE,强化学习(RL)和组合网络),三种基于RNN以及三种基于GAN的方法。本文的一个主要贡献和新颖之处在于包括和比较了基于SNN的视觉跟踪方法,这些方法在当前的视觉跟踪社区中引起了人们的极大兴趣。此外,回顾了基于GAN和自定义网络(包括基于RL的方法)的最新视觉跟踪器。尽管本次调查中的方法分为利用现成的深层特征和用于视觉跟踪的深层特征(类似于[53]中的FEN和EEN),但这些方法的详细特征(例如预训练或骨干)还介绍了网络,被利用的层,训练数据集,目标函数,跟踪速度,使用的功能,跟踪输出的类型,CPU / GPU实现,编程语言,DL框架。从网络培训的角度来看,本次调查独立研究了现成的深层功能和用于视觉跟踪的深层功能。由于深入的现成功能(即从FEN中提取的功能)大多已在ImageNet上针对对象识别任务进行了预训练,因此将独立审查其训练细节。因此,用于视觉跟踪目的的网络培训被归类为基于DL的方法,这些方法仅利用离线培训,仅利用在线培训或利用离线和在线培训程序。最后,本文生成器在四个视觉跟踪数据集上生成了45种最新视觉跟踪方法的不同方面。
本文的主要贡献概括如下:
1)基于DL的最新视觉跟踪方法根据其体系结构(即CNN,SNN,RNN,GAN和自定义网络),网络开发(即现成的深层功能和视觉跟踪的深层功能),用于视觉跟踪的网络训练(即,仅脱机训练,仅在线训练,脱机和在线训练),网络目标(即,基于回归,基于分类以及基于分类和回归的两者) ),以及开发相关过滤器的优势(即DCF框架并利用相关过滤器/层/功能)。以前没有进行过这样的研究,该研究涵盖了视觉跟踪方法的详细分类中的所有这些方面。
2)总结了基于DL的方法解决视觉跟踪问题的主要动机和贡献。据我们所知,这是第一篇研究视觉跟踪方法的主要问题和建议解决方案的论文。此分类为设计准确且健壮的基于DL的视觉跟踪方法提供了正确的见解。
3)基于基本特征(包括视频数量,帧数量,类或群集数量,序列属性,标签缺失以及与其他数据集的重叠),最近的视觉跟踪基准数据集包括OTB2013 [185],VOT [40] ]-[46],ALOV [48],OTB2015 [186],TC128 [187],UAV123 [188],NUS-PRO [189],NfS [190],DTB [191],TrackingNet [192],OxUvA [ 193],BUAA-PRO [194],GOT10k [195]和LaSOT [196]进行了比较。
4)最后,对著名的OTB2013,OTB2015,VOT2018和LaSOT视觉跟踪数据集进行了广泛的定量和定性实验评估,并根据不同方面对最新的视觉跟踪器进行了分析。此外,本文不仅为VOT2018数据集指定了最具挑战性的视觉属性,而且首次为OTB2015和LaSOT数据集指定了最具挑战性的视觉属性。最后,根据TraX协议[197],对VOT工具包[45]进行了修改,以定性比较不同的方法。
根据比较,得出以下结论:
1)由于基于SNN的方法在视觉跟踪的性能和效率之间具有令人满意的平衡,因此它们是最有吸引力的深度体系结构。此外,视觉跟踪方法最近试图利用RL和GAN方法的优势来完善其决策制定并减轻训练数据的不足。基于这些优点,最近的视觉跟踪方法旨在设计用于视觉跟踪目的的自定义神经网络。
2)深度特征的离线端到端学习适当地适应了预训练的特征以进行视觉跟踪。尽管DNN的在线训练增加了计算复杂度,使得大多数方法都不适合实时应用,但它可以帮助视觉跟踪器适应明显的外观变化,防止视觉干扰,并提高视觉跟踪的准确性和鲁棒性方法。因此,利用离线和在线培训程序可以提供更强大的视觉跟踪器。
3)利用更深更广的骨干网,区分目标和背景的区分能力。
4)最佳的视觉跟踪方法既使用回归目标函数又使用分类目标函数,不仅可以估计最佳目标建议,还可以找到最紧密的BB进行目标定位。
5)利用不同的功能可以增强目标模型的鲁棒性。例如,由于这个原因,大多数基于DCF的方法都融合了深层次的现成功能和手工制作的功能(例如HOG和CN)。同样,对互补特征(例如时间或上下文信息)的利用也导致了针对目标表示的更多区分性和鲁棒性。
6)基于DL的视觉跟踪方法最具挑战性的属性是遮挡,视野外和快速运动。此外,具有类似语义的视觉干扰器可能会导致漂移问题。
本文的其余部分如下。第2节介绍了深度视觉跟踪方法的分类法。在第3节中对视觉跟踪基准数据集和评估指标进行了简要比较。在第4节中对最新的视觉跟踪方法进行了实验比较。最后,第5节总结了结论和未来的方向。
2.深层视觉跟踪方法的分类法
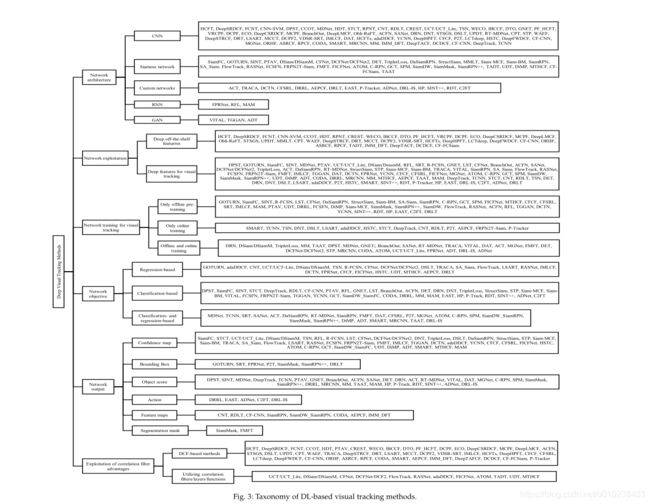 本节中的三个主要组成部分:目标表示/信息,培训过程和学习过程描述。 然后,提出了基于DL的方法的综合分类法。
本节中的三个主要组成部分:目标表示/信息,培训过程和学习过程描述。 然后,提出了基于DL的方法的综合分类法。
基于DL的方法的主要动机之一是通过利用/融合深层特征,利用上下文信息或运动信息以及选择更具区分性和鲁棒性的深层特征来改善目标表示。同样,基于DL的方法旨在有效地为视觉跟踪系统训练DNN。他们的一般动机可以理解为采用不同的网络培训(例如,网络预培训,在线培训或两者兼有)或处理某些培训问题(例如,缺少培训数据,对培训数据的过度拟合和计算复杂性)。无监督训练是使用大量未标记样本的另一种最新方案,可以通过根据上下文信息对这些样本进行聚类,将训练数据映射到多个空间或利用基于一致性的目标函数来执行。最后,基于DL的跟踪器根据其学习过程的主要动机可用于在线更新方案,宽高比估计,比例估计,搜索策略以及提供长期记忆的功能。
在下文中,基于网络架构,网络开发,用于视觉跟踪目的的网络训练,网络目标,网络输出以及相关过滤器优势的利用等六个主要方面对基于DL的视觉跟踪方法进行了分类。 基于DL的视觉跟踪方法的拟议分类法如图2所示。 3.此外,其他重要细节包括预先训练的网络,骨干网络,被利用的层,深度特征的类型,手工和深度特征的融合,训练数据集,跟踪输出,跟踪速度,硬件实现细节,编程语言和DL框架将在本节中介绍。 在本节中,不仅对基于DL的最新视觉跟踪方法进行了分类,而且对这些方法的主要动机和贡献进行了分类,这些方法和方法可以提供有用的观点来确定未来的方向。
2.1 网络架构
尽管CNN已被广泛用于基于DL的方法中,但近年来,还主要开发了其他体系结构来提高视觉跟踪器的效率和鲁棒性。 根据基于各种深度结构的技术的范围,分类法包括基于CNN,基于SNN,基于GAN,基于RNN和基于自定义网络的方法。
2.1.1卷积神经网络(CNN)
受到CNN在计算机视觉任务中的突破以及一些诱人的优势(例如参数共享,稀疏交互和主导表示)的激励,各种各样的方法都利用CNN进行视觉跟踪。 主要基于以下动机列出了基于CNN的视觉跟踪器。
• 强大的目标表示:提供强大的目标表示是采用CNN进行视觉跟踪的主要优势。为了实现学习用于目标建模的通用表示并构建更强大的目标模型的目标,方法的主要贡献发布到:
i)在大规模数据集上进行CNN离线训练以进行视觉跟踪[63],[68],[80],[89],[97],[100],[101],[104],[112],[ 116],[135],[137],[142],[144],[153],[165],[168],[169],[173],
ii)设计特定的深度卷积网络,而不采用预先训练的模型[63],[68],[70],[72],[73],[75],[76],[80],[82], [89],[97],[100],[101],[104],[105],[108],[112],[116],[127],[135],[137],[141 ],[142],[144],[146],[150],[153],[165],[167]-[169],[171],[173],
iii)构建多个目标模型以捕获各种目标外观[75],[116],[127],[129],[130],[143],[146],[172],
iv)合并空间和时间信息以提高模型的概括性[79],[82],[106],[119],[122],[137],[151],[153],
v)融合不同的深度特征以开发互补的空间和语义信息[64],[101],[108],[109],[135],
vi)学习不同的目标模型,例如相对模型[104]或基于零件的模型[116],[127],[146],以处理部分遮挡和变形,以及
vii)利用两流网络[127]来防止过度拟合并学习旋转信息。
• 平衡训练数据:根据视觉跟踪的定义,在第一帧中只有一个正样本会增加过拟合的风险。尽管可以将任意背景信息视为每个帧中的负面信息,但是基于不完美目标估计的目标采样也可能导致嘈杂/不可靠的训练样本。这些问题影响视觉跟踪方法的性能。为了缓解它们,基于CNN的方法建议:
i)域适应机制(即,在样本不足的情况下,将学习到的知识从源域转移到目标域)[89],[165],
ii)各种更新机制(例如定期更新,随机更新,短期更新和长期更新)[105],[129],[143],[149],[169],
iii)用于正样本和负样本挖掘的卷积Fisher判别分析(FDA)[141],
iv)用于在线集成学习的多分支CNN [97],以及
v)有效的抽样策略以增加训练样本的数量[171]。
• 计算复杂性问题:尽管在目标估计精度方面CNN取得了长足进步,但基于CNN的方法仍存在较高的计算复杂性。为了减少此限制,基于CNN的视觉跟踪方法采用了不同的解决方案:
i)将CNN分解成几个缩小的网络[76],
ii)压缩或修剪训练样本空间[94],[115],[141],[153],[168]或特征选择[61],[154],
iii)通过RoIAlign运算[112](即通过双线性插值进行特征逼近)或倾斜随机森林[99]进行特征计算,以更好地捕获数据,
iv)校正域适应方法[165],
v)轻型结构[72],[73],[167],
vi)有效的优化过程[98],[155],
vii)利用相关过滤器的优势[59]-[61],[64],[69],[74],[77]-[80],[83],[85],[86],[92] ,[94]-[96],[98],[100],[106],[108],[109],[115],[119],[122],[126],[127],[ 129]-[131],[135],[140],[141],[143],[144],[149]-[151],[155],[159],[165],[167] ,[171],[172],[174]进行高效计算,
viii)粒子采样策略[96],以及
ix)利用注意力机制[100]。
2.1.2暹罗神经网络(SNN)
为了学习相似性知识并实现实时速度,在过去几年中,SNN被广泛用于视觉跟踪。给定目标区域和搜索区域对,这些双胞胎网络计算相同的函数以生成相似性图。基于SNN的方法的共同目标是克服预训练的深度CNN的局限性,并充分利用端到端学习进行实时应用。
-
区分性目标表示:虚拟跟踪器构建健壮目标模型的能力主要取决于目标表示。为了提供更具区分性的深层功能并改善目标建模,基于SNN的方法建议:
-
学习可识别干扰物的[111]或可识别目标的功能[161],
-
融合深层次的特征[132],[157]或组合置信度图[88],[90],[124],
-
在暹罗语中使用不同的损失函数来训练更有效的过滤器[57],[107],[161]-[163],
-
利用不同类型的深度特征,例如上下文信息[117],[124],[158]或时间特征/模型[65],[81],[125],[133],[158],[175 ],
-
全面探索低级空间特征[132],[157],
-
考虑目标的角度估计以防止突出的背景物体[118],
-
利用多阶段回归来完善目标表示[157],以及
-
使用更深更广的深度网络作为骨干,以增加神经元的感受野,这相当于捕获了目标的结构[56]。
-
适应目标外观变化:仅使用基于SNN的第一代方法的离线培训会导致这些方法难以适应目标外观变化。为了解决这个问题,最近的基于SNN的方法提出了:
-
在线更新策略[81],[90],[93],[103],[111],[152],[156],[163],
-
背景抑制[81],[111],
-
iii)将跟踪任务表述为单次本地检测任务[111],[123]和
-
iv)给重要的特征通道或得分图赋予更高的权重[88],[124],[128],[148]。或者,DaSiamRPN [111]和MMLT [114]使用局部到全局搜索区域策略和内存开发来分别处理关键挑战,例如完全遮挡和视线不足以及增强局部搜索策略。
-
•平衡训练数据:与基于CNN的方法一样,基于SNN的方法也做了一些努力来解决训练样本的不平衡分布。基于SNN的方法的主要贡献是:
-
i)利用多阶段连体框架来刺激硬性否定抽样[157],
-
ii)采用采样启发式方法,例如固定的前景与背景之比[157]或采样策略,例如随机采样[111]或流引导采样[133],以及
-
iii)利用相关过滤器/层进入暹罗框架[77],[78],[81],[93],[102],[111],[123],[125],[128],[148] ],[152],[154],[156],[161],[162],[170]。
-
2.1.3递归神经网络(RNN)
由于视觉跟踪与视频帧的空间和时间信息都相关,因此采用基于RNN的方法来同时考虑目标运动。由于艰苦的训练和大量的参数,基于RNN的方法的数量受到限制。几乎所有这些方法都试图利用其他信息和内存来改善目标建模。同样,使用基于RNN的方法的第二个目的是避免对预训练的CNN模型进行微调,这会花费很多时间并且容易过度拟合。这些方法的主要目的可以表示为时空表示捕获[84],[139],[175],利用上下文信息来处理背景混乱[139],也利用多层次的视觉注意力来突出显示目标作为背景抑制[175],并使用卷积长短期记忆(LSTM)作为先前目标出现的记忆单元[84]。此外,基于RNN的方法利用金字塔多向递归网络[139]或将LSTM合并到不同的网络[84]中,以记住目标的出现并研究时间的时间依赖性。最后,[139]对目标的自身结构进行编码,以降低与类似干扰物有关的跟踪灵敏度。
2.1.4生成对抗网络(GAN)
基于一些吸引人的优势,例如捕获统计分布并在没有大量注释数据的情况下生成所需的训练样本,GAN已在许多研究领域得到了广泛使用。 尽管GAN通常难以训练和评估,但一些基于DL的视觉跟踪器仍会使用它们来丰富训练样本和目标模型。 这些网络可以增加特征空间中的正样本,以解决训练样本的不平衡分布[121]。 同样,基于GAN的方法可以学习一般的外观分布,以解决视觉跟踪的自学习问题[136]。 此外,回归网络和判别网络的联合优化将导致同时利用回归和分类任务[164]。
2.1.5自定义网络
受特定的深层架构和网络层的启发,基于DL的现代方法已结合了广泛的网络,例如AE,CNN,RNN,SNN以及用于视觉跟踪的深层RL。主要动机是通过利用其他网络的优势来弥补常规方法的不足。主要动机和贡献如下。
-
计算复杂性问题:如前所述,此问题限制了实时应用程序中在线跟踪器的性能。为了控制基于自定义网络的视觉跟踪器的计算复杂性,TRACA [120]和AEPCF [171]方法采用自动曝光来压缩原始常规深层特征,EAST [181]自适应地采用浅层特征进行简单帧跟踪或采用昂贵的深层具有挑战性的功能[181]和TRACA [120],CFSRL [145]和AEPCF [171]都利用了DCF的计算效率。
-
模型更新:为了在跟踪过程中保持目标模型的稳定性,已提出了不同的更新策略;例如,CFSRL [145]并行更新多个模型,DRRL [166]包含LSTM以利用远程时间依赖性,而AEPCF [171]利用长期和短期更新方案来提高跟踪速度。为了防止错误的模型更新和漂移问题,RDT [184]将视觉跟踪公式修改为关于下一次定位的最佳目标模板的连续决策过程。此外,使用RL [183]有效学习良好的决策策略是另一种采取模型更新或忽略决策的技术。
-
有限的训练数据:如果发生遮挡,模糊和大变形,则柔软且无代表性的训练样本可能会干扰视觉跟踪。 AEPCF [171]利用密集的圆形采样方案来防止由有限的训练数据引起的过拟合问题。为了获得独特且具有挑战性的训练数据,SINT ++ [58]通过正样本生成网络(PSGN)和正正变换网络(HPTN)生成正样本和硬样本。为了在没有大量训练数据的情况下有效地训练DNN,动作驱动的深度跟踪器[176],[177]利用了部分标记的训练样本。此外,P-Track [183]使用主动决策来交互式标记视频,同时在有限的注释数据可用时学习跟踪器。
-
搜索策略:根据定义,视觉跟踪方法在给定第一帧的初始目标状态的情况下,估计下一帧搜索区域中的新目标状态。最佳搜索区域的选择取决于迭代搜索策略,这些策略通常不仅独立于视频内容,而且还启发式,蛮力和手工设计。尽管基于滑动窗口,均值漂移或粒子过滤器的经典搜索策略,基于DL的最新视觉跟踪器仍采用基于RL的方法来学习数据驱动的搜索策略。为了详尽地探索感兴趣的区域并选择最佳目标候选者,动作驱动的跟踪机制[176],[177]考虑了目标上下文的变化并积极地追求目标运动。此外,ACT和DRRL通过动态搜索过程[110]和从粗到精的验证[166]提出了针对实时需求的实用的基于RL的搜索策略。
-
利用附加信息:为了通过利用运动或上下文信息来增强目标模型,DCTN [138]建立了两个流网络,而SRT [87]采用多向RNN来在视觉跟踪过程中进一步了解目标的依赖性。为了对相关信息进行编码以实现更好的定位,可通过循环卷积网络对先前的语义信息和跟踪建议进行建模[180]。另外,DRL-IS [179]引入了Actor-Critic网络来有效地估计目标运动参数。
-
决策:在线决策对基于DL的视觉跟踪方法的性能有主要影响。最先进的方法试图通过将RL纳入基于DL的方法而不是手工设计的技术中来学习在线决策。为了获得有效的决策策略,P-Track [183]最终利用主动代理中的数据驱动技术来决定跟踪,重新初始化或更新过程。此外,DRL-IS [179]利用基于RL的原理方法来基于目标状态选择明智的行动。而且,已经提出了动作预测网络来调整视觉跟踪器的连续动作,以确定用于学习最佳动作策略并做出令人满意的决定的最佳超参数[182]。
2.2 网络利用
粗略地说,DNN用于视觉跟踪有两个主要用途,包括在部分相关的数据集上重用预先训练的模型,或将深层功能用于视觉跟踪,这相当于为视觉跟踪目的训练DNN。
2.2.1模型重用或深度可用的功能
利用深层的现成功能是将深层功能的功能转移到传统视觉跟踪方法中的最简单方法。这些功能提供了视觉目标的通用表示形式,并有助于视觉跟踪方法构建更强大的目标模型。关于拓扑,DNN包括非线性层的简单多层堆栈(例如AlexNet [34],VGGNet [35],[36])或有向无环图拓扑(例如GoogLeNet [37],ResNet [ 128],SSD [198],暹罗卷积神经网络[199])允许设计更复杂的深度架构,包括具有多个输入/输出的层。这些跟踪器的主要挑战是如何使通用表示完全受益。不同的方法采用了各种特征图和模型,这些特征图和模型主要在ImageNet数据集的大型静止图像[39]上进行了预训练,以用于对象识别任务。许多方法研究了预训练模型的属性,并探讨了传统框架中深层功能的影响(请参见表1)。结果,基于DL的方法倾向于同时利用语义和细粒度的深层特征[59],[61],[64],[140],[157],[200],[201 ]。深度特征的融合也是这些方法的另一个动机,这些动机通过不同的技术来利用多分辨率深度特征[59]-[61],[64],[69],[83],[109],[129],[130],[143],[152],[172],并在以后的阶段将深层特征与浅层特征进行独立融合[109]。利用运动信息[92],[106],[172],[202]并为视觉跟踪任务选择适当的深度特征[61],[154]是基于DL的方法的另外两个有趣的动机。表1显示了基于DL的基于现成功能的可视跟踪器的详细特征。不用说,这些方法的网络输出就是深度功能图。
2.2.2用于视觉跟踪的深度功能
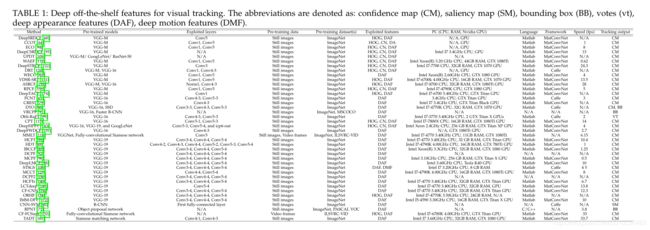 新方法的趋势之一是如何设计和训练DNN以进行视觉跟踪。 由于不同任务的目标之间存在不一致,因此使用深入的现成功能会限制视觉跟踪性能。 此外,离线学习的深度功能可能无法捕获目标变化,并且往往会过度适合初始目标模板。 因此,在大规模数据集上对DNN进行训练,以使网络专门用于视觉跟踪。 此外,在视觉跟踪过程中应用微调过程可以调整一些网络参数并产生更精确的目标表示。 但是,由于启发式固定的迭代次数和有限的可用训练数据,微调过程非常耗时且容易过度拟合。 如表2至表4所示,这些基于DL的方法通常通过脱机训练或在线训练或两者来训练预训练的网络(即骨干网)。
新方法的趋势之一是如何设计和训练DNN以进行视觉跟踪。 由于不同任务的目标之间存在不一致,因此使用深入的现成功能会限制视觉跟踪性能。 此外,离线学习的深度功能可能无法捕获目标变化,并且往往会过度适合初始目标模板。 因此,在大规模数据集上对DNN进行训练,以使网络专门用于视觉跟踪。 此外,在视觉跟踪过程中应用微调过程可以调整一些网络参数并产生更精确的目标表示。 但是,由于启发式固定的迭代次数和有限的可用训练数据,微调过程非常耗时且容易过度拟合。 如表2至表4所示,这些基于DL的方法通常通过脱机训练或在线训练或两者来训练预训练的网络(即骨干网)。
2.3网络训练
最新的基于DL的视觉跟踪方法主要通过应用基于梯度的优化算法来利用端到端学习来训练/重新训练DNN。 但是,这些方法根据其脱机网络训练,在线微调,计算复杂性,处理训练数据不足,解决过度拟合问题以及通过无监督训练来利用未标记样本而有所不同。 以前的综述文章[51]-[53]中的网络培训部分同时考虑了FEN和EEN,尽管FEN仅针对其他任务进行了预培训,并且没有用于视觉跟踪的培训程序。 在此调查中,基于DL的方法仅分类为离线预训练,仅在线训练以及出于视觉跟踪目的的离线和在线训练。 这些方法的训练细节如表2至表4所示。
2.3.1 仅离线培训
大多数基于DL的视觉跟踪方法仅对它们的网络进行预训练,以提供通用的目标表示,并减少由于训练数据不平衡和固定假设而导致过度拟合的高风险。 为了调整学习到的过滤器权重以进行视觉跟踪任务,对专用网络进行了大规模数据的训练,不仅可以利用更好的表示能力,而且还可以通过防止在视觉跟踪过程中进行训练来达到可接受的跟踪速度(参见表2)。
2.3.2仅在线培训
 为了区分可能被视为评估视频中目标的看不见的目标,一些基于DL的视觉跟踪方法使用整个DNN或部分DNN的在线训练来根据各种目标外观来调整网络参数。 由于对大规模训练数据进行离线训练的过程很耗时,并且对于表示跟踪特定目标的预训练模型的分辨力不足,因此,表3中显示的方法直接使用DNN训练和推理过程进行在线替代。 但是,这些方法通常采用一些策略来防止过度拟合的问题和分歧。
为了区分可能被视为评估视频中目标的看不见的目标,一些基于DL的视觉跟踪方法使用整个DNN或部分DNN的在线训练来根据各种目标外观来调整网络参数。 由于对大规模训练数据进行离线训练的过程很耗时,并且对于表示跟踪特定目标的预训练模型的分辨力不足,因此,表3中显示的方法直接使用DNN训练和推理过程进行在线替代。 但是,这些方法通常采用一些策略来防止过度拟合的问题和分歧。


2.3.3离线和在线培训
为了利用DNN的最大能力进行视觉跟踪,表4中显示的方法同时使用了离线和在线训练。 脱机和在线学习的功能称为共享和特定于域的表示形式,主要可以分别将目标与前景信息或类内干扰项区分开。 由于视觉跟踪是一个困难且具有挑战性的问题,因此基于DL的视觉跟踪器尝试同时采用特征可传递性和在线域自适应。
2.4网络目标
在训练和推理阶段之后,基于DL的视觉跟踪器会根据网络目标函数定位给定的目标。 因此,基于DL的视觉跟踪方法可分为以下几种:基于分类的方法,基于回归的方法或基于分类和基于回归的方法。 该分类基于已在视觉跟踪方法中使用的DNN的目标函数(请参见图3); 因此,本小节不包括利用深层现成特征的方法,因为这些方法没有设计和训练网络,并且通常使用DNN进行特征提取。
2.4.1基于分类的目标函数
基于其他计算机视觉任务(例如图像检测)的动机,基于分类的视觉跟踪方法采用对象提议方法,以产生从搜索区域提取的数百个候选/提议BB。这些方法旨在通过将提案分为目标类别和背景类别来选择高分提案。这种两类(或二进制)分类涉及来自各种类和移动模式的视觉目标,还涉及单个序列,包括具有挑战性的场景。由于这些方法主要用于类间分类,因此在存在相同标记目标的情况下跟踪视觉目标极易产生漂移问题。此外,跟踪目标的任意外观可能会导致在识别具有不同外观的不同目标时出现问题。因此,基于分类的视觉跟踪方法的性能也与它们的对象建议方法有关,该对象建议方法通常会产生大量的候选BB。另一方面,一些最近的基于DL的方法利用此目标函数对BB采取了最佳操作[58],[166],[176]-[179],[181]。
2.4.2基于回归的目标函数
由于视觉跟踪的估计空间的连续本能,基于回归的方法通常旨在通过最小化正则化最小二乘函数将目标直接定位在后续帧中。通常,需要大量的训练数据才能有效地训练这些方法。基于回归的方法的主要目标是重新完善L2或L1损失函数的公式,例如在学习过程中利用收缩损失[108],对回归系数和补丁可靠性进行建模以有效地优化神经网络[127],或应用对成本敏感的损失来增强无监督学习效果[162]。
2.4.3基于分类和回归的目标函数
为了利用前景/背景/类别分类和岭回归(即正则化最小二乘目标函数)的优势,某些方法同时使用基于分类和回归的目标函数进行视觉跟踪(参见图3),其目的是桥接最近的通过检测跟踪和视觉跟踪的连续定位过程之间的差距。通常,这些方法利用基于分类的方法来找到最相似的目标提案,然后通过aBB回归方法对估计的区域进行细化[55],[68],[75],[87],[101],[ 110]-[112],[123],[137],[153],[168],[173]。为了提高效率和准确性,可以通过分类分数和优化的回归/匹配函数来估算目标区域[56],[57],[134],[145],[146],[156],[157],[160], [163],[164],[167],[179]。分类输出主要是针对候选提议的置信度得分,前景检测,候选窗口的响应,动作等推断出的。
2.5网络输出
基于它们的网络输出,基于DL的方法分为六个主要类别(请参见图3和表2至表4),特定的置信度图(还包括得分图,响应图和投票图),BB(也包括旋转的BB),对象分数(还包括对象提议的概率,验证分数,相似性分数和逐层分数),动作,特征图和分割蒙版。 根据网络目标,基于DL的方法会生成不同的网络输出,以估计或优化估计的目标位置。
 2.6开发相关滤波器的优势
2.6开发相关滤波器的优势
基于DCF的方法旨在学习一组判别滤波器,这些判别滤波器将它们与频域中的一组训练样本进行逐元素相乘即可确定空间目标位置。与复杂技术相比,由于DCF提供了具有竞争力的跟踪性能以及计算效率,因此基于DL的视觉跟踪器利用了相关滤波器的优势。这些方法基于它们如何通过使用整个DCF框架或某些好处(例如其目标函数或相关过滤器/层)来利用DCF优势进行分类。大量的视觉跟踪方法是基于DCF框架中深层功能的集成(见图3)。这些方法旨在提高目标表示对具有挑战性的属性的鲁棒性,而其他方法则试图从相关滤波器[93],相关层[125],[141],[148], [161],[170]以及相关滤波器的目标函数[80],[81],[102],[128],[156],[162]。
3. 视觉跟踪基准数据集
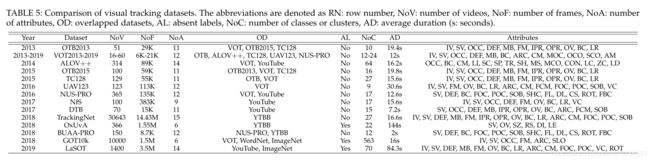
引入了视觉跟踪基准数据集,以提供对单对象跟踪算法的公正和标准化的评估。跟踪数据集包含的视频序列不仅包含各种目标类别,而且还具有不同的持续时间和具有挑战性的属性。这些数据集包含大量视频序列,帧,属性和类(或类)。这些属性包括照度变化(IV),比例变化(SV),遮挡(OCC),变形(DEF),运动模糊(MB),快运动(FM),面内旋转(IPR),超出平面旋转(OPR),视线外(OV),背景杂波(BC),低分辨率(LR),宽高比变化(ARC),相机运动(CM),完全遮挡(FOC),部分遮挡( POC),相似物体(SOB),视点变化(VC),光(LI),表面覆盖(SC),镜面度(SP),透明度(TR),形状(SH),运动平滑度(MS),运动相干性(MCO) )),混乱(CON),低对比度(LC),变焦相机(ZC),长时间(LD),阴影变化(SHC),闪光灯(FL),弱光(DL),相机抖动(CS),旋转(ROT),快速背景变化(FBC),运动变化(MOC),物体颜色变化(OCO),场景复杂度(SCO),绝对运动(AM),尺寸(SZ),相对速度(RS),干扰物(DI ),长度(LE),快速摄像机运动(FCM)和小/大物体(SLO)。表5比较了视觉跟踪数据集的特征,无监督训练中缺失的标记数据的存在以及数据集的部分重叠。通过不同的评估协议,现有的视觉跟踪基准可以评估现实场景中视觉跟踪器的准确性和鲁棒性。统一的评估协议有助于直观跟踪器的直接比较和开发。在下文中,简要介绍了最流行的视觉跟踪基准数据集和评估指标。
3.1视觉跟踪数据集
第一个对象跟踪基准数据集之一称为OTB2013 [185],由51个带完整注释的视频序列开发,以解决基于一些视频序列或不一致的初始条件或参数的已报告跟踪结果问题。 OTB2015 [186]是扩展的OTB2013数据集,包括100个常用视频序列,目的是实现无偏性能比较。为了提供视觉跟踪算法对颜色序列的性能,Temple Color 128(TColor128或TC128)[187]收集了129个完全注释的视频序列,其中有78个不同于OTB数据集。但是,其属性的注释与OTB的属性相同。阿姆斯特丹普通视频(ALOV)数据集[48]已被收集以涵盖各种视频序列和属性。通过强调具有挑战性的视觉跟踪场景,ALOV数据集由304个短视频和十个长视频组成。这些视频序列是从真实的YouTube视频中选择的,难度级别为13。 ALOVhave的视频已根据其属性之一进行了分类(表5),尽管在OTB数据集中每个视频都已通过几个视觉属性进行了注释。
无人机123(UAV123)[188]提供稀疏和低空无人机跟踪数据集,其中包含由专业级无人机捕获的逼真和合成高清视频序列,安装在小型低成本无人机上的板载机和无人机模拟器。为了跟踪行人和刚性物体,NUS人和刚性物体(NUS-PRO)数据集[189]不仅在十二种挑战性因素的作用下从YouTube提供了365个视频序列,而且还标注了每个帧被遮挡的水平,没有遮挡,部分遮挡和完全遮挡标签。它由五个主要类别(即面部,行人,运动员,刚体和长序列)和十六个子类别(包括帽子,面具,采访,政客,太阳镜,篮球,体操,手球,赛车,足球,网球,飞机,轮船,汽车,直升机和摩托车),主要是通过移动摄像机捕获的。通过更高的帧频(240 FPS)摄像机,对速度(NfS)数据集的需求[190]提供了来自现实场景的100个视频序列,以系统地研究与视觉跟踪器实时分析相关的折衷带宽约束。这些视频可以通过手持式iPhone / iPad摄像机录制,也可以通过YouTube视频录制。而且,它包含多种视觉目标,包括车辆,人,脸,动物,飞机和船。
VOT数据集[40]-[46]受大型数据集与有用数据集不等的影响,旨在从现有的视觉跟踪数据集中提供一个独特且足够小的数据集,并通过可旋转的BB和视觉属性逐帧对其进行注释。为了快速而直接地评估不同的视觉跟踪方法,VOT包含视觉跟踪交换(TraX)协议[197],该协议不仅可以准备数据,运行实验并执行分析,还可以检测跟踪失败(即失去目标)并重新进行跟踪。 -在每次失败后五帧初始化跟踪器,以评估跟踪的鲁棒性。无人机跟踪基准(DTB)[191]是由无人机或无人机捕获的数据集,包含70种不同的RGB视频,由于摄像机突然运动,其目标位置发生了很大的位移。该数据集主要侧重于跟踪人和汽车,并旨在集中于具有较高自由度的非平稳或慢速运动摄像机的视觉跟踪器的运动模型的性能。尽管野外有一些小型且饱和的跟踪数据集,这些数据集主要用于对象检测任务,但已提出大规模TrackingNet基准数据集[192]以正确地提供给深度视觉跟踪器。它包括500个原始视频,超过1400万个垂直BB注释,及时的密集注释数据,丰富的对象类别分布以及YouTube采样视频的真实场景。虽然TrackingNet的训练和测试集分别由30132和115个视频序列组成,但它在视频长度,BB分辨率,运动变化,宽高比和属性分布方面提供了相同的对象类别分布。
为了长期跟踪经常消失的目标,OxUvA数据集[193]从YouTube边界框(或YTBB)[203]中选择了366个视频序列(14小时的视频),以提供持续的开发和测试集属性。带注释的不带标签表明目标在框架中不存在。同样,此数据集包括连续属性,这些属性的数量已通过BB注释和元数据进行了测量。 BUAA-PRO数据集[194]是基于分段的基准数据集,用于解决BB中不可避免的非目标元素的问题。它包含来自NUS-PRO的150个视频序列,其中包括三个主要类别的刚性物体(分别是飞机,轮船,汽车,直升机和摩托车),运动员(包括篮球,体操,手球,赛车,足球和网球),和行人。它不仅利用了NUS-PRO的相同属性,还利用了基于分段遮罩的基于级别的遮挡属性(即,无遮挡,部分遮挡和完全遮挡)。大规模的单一对象跟踪(LaSOT)基准数据集[196]已经开发出来,以解决视觉跟踪数据集的问题,例如规模小,缺乏高质量,密集注释,短视频序列和类别偏差。对象类别来自ImageNet和一些视觉跟踪应用程序(例如,无人机),每个类别具有相等数量的视频。根据帕累托原理(用于训练的80%和用于测试的20%),LaSOT数据被分为训练和测试子集,分别包括1120(2.3M帧)和280(690K帧)视频序列。大型的高多样性基准数据集称为GOT-10k [195],其中包括来自WordNet [204]语义层次结构的一万多个视频,这些视频分为训练,验证和测试集。视频序列涵盖563类运动对象和87类运动,以覆盖现实世界场景中尽可能多的挑战性模式。 GOT-10k具有类似于OxUvA的信息属性.
3.2 评估指标
为了对大型数据集进行实验比较,视觉跟踪方法通过性能测量和性能图的两个基本评估类别进行评估。这些指标简要说明如下:
3.2.1 绩效考核
为了反映视觉跟踪器的若干视图,已经提出了各种性能度量。这些措施试图通过准确性,鲁棒性和跟踪速度的补充措施来直观地解释性能比较。在下文中,将对这些措施进行简要研究。
- 中心位置误差(CLE):CLE定义为目标的精确地面位置与通过视觉跟踪方法估算的位置之间的平均欧几里得距离。 CLE是最古老的指标不仅对数据集注释敏感,不考虑跟踪失败,而且忽略目标BB并导致重大错误。
- 准确性:要达到视觉跟踪的准确性,首先,重叠分数的计算公式为S = | b t∩bg | / | b t∪bg |,其中bg,bt,∩,∪和|。分别表示地面真实BB,通过视觉跟踪方法估算的BB,交集算子,联合算子和结果区域中的像素数。通过考虑某个阈值,重叠分数表示视觉跟踪器在一帧中的成功。然后,当视觉跟踪器的估算值与实际值重叠时,通过跟踪过程中的平均重叠分数(AOS)计算准确性。该度量标准共同考虑了位置和区域,以测量估计目标直至失败的漂移率。
- 稳健性/失败分数:稳健性或失败分数定义为在跟踪任务期间跟踪器丢失(或漂移)视觉目标时所需的重新初始化次数。当重叠分数降至零时,将检测到故障。
- 预期平均重叠(EAO):该分数被解释为准确性和鲁棒性分数的组合。 给定N s帧较长的序列,EAO得分的计算公式为,
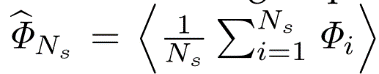 其中Φi定义为每帧重叠的平均值,直到序列结束,即使失败导致零重叠。
其中Φi定义为每帧重叠的平均值,直到序列结束,即使失败导致零重叠。 - 曲线下面积(AUC):AUC分数已根据预定义的阈值定义了平均成功率(归一化为0到1)。 为了根据视觉跟踪方法的整体性能对视觉跟踪方法进行排名,AUC分数汇总了整个序列中视觉跟踪方法的AOS。
3.2.2 性能图
为了弄清楚视觉跟踪方法的性能,通常根据不同的阈值评估不同的方法,以提供更直观的定量比较。 以下,对这些指标进行了总结。
- 精度图:给定每个不同阈值的CLE,精度图显示了视频帧的百分比,其中估计位置至多具有地面阈值位置的特定阈值。
- 成功图:成功图根据每个阈值计算出的各种精度,成功图衡量的是估计重叠部分和地面真实重叠部分超过某个阈值的帧的百分比。
- 预期平均重叠曲线:对于视频序列的各个长度,预期平均重叠曲线是由特定间隔内的值范围产生的
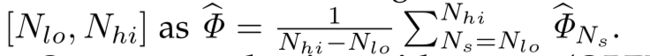
- 带重启的一次通过评估(OPER):OPER是一种受监管的系统,可以连续测量跟踪
4.实验分析
为了分析最新视觉跟踪方法的性能,在四个著名的数据集OTB2013 [185],OTB2015 [186],VOT2018 [45]和LaSOT [196]上定量比较了45种不同的方法。由于页面限制,所有实验结果均可在https://github.com/MMarvasti/Deep-Learning-for-Visual-Tracking-Survey上公开获得。表6显示了实验中包括的45个基于DL的跟踪器。 ECO,CFNet,TRACA,DeepSTRCF和C-RPN被视为比较各种数据集性能的基准跟踪器。借助MatConvNet工具箱[205]在使用Nvidia GeForce RTX 2080Ti GPU进行计算的MatConvNet工具箱[205]上,在具有32GB RAM的Intel I7-9700K 3.60GHz CPU上执行所有评估。 OTB和LaSOT工具包根据众所周知的精度和成功图评估视觉跟踪方法,然后根据AUC评分对方法进行排名[185],[186]。为了在VOT2018数据集上进行性能比较,我们根据TraX评估协议[197]对视觉跟踪器进行了评估,使用了精度,鲁棒性和EAO的三种主要度量,以提供精度-鲁棒性(AR)图,预期的平均重叠曲线,根据五个具有挑战性的视觉属性[45],[206],[207]来排序图表。
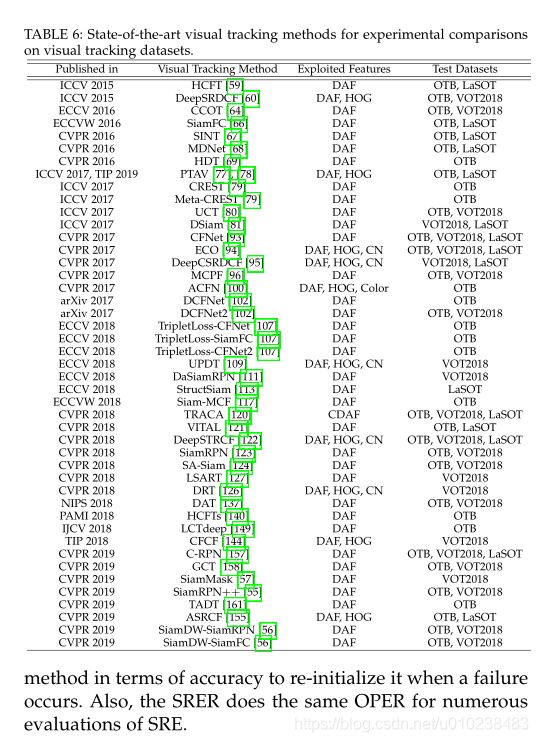
4.1定量比较

根据图所示结果。如图4所示,就精度指标而言,排名前5位的视觉跟踪方法是OTB2013数据集上的VITAL,MDNet,DAT,ASRCF和SiamDW-SiamRPN,SiamDW-SiamRPN,ASRCF,VITAL,SiamRPN ++和MDNet。 OTB2015数据集,以及LaSOT数据集上的C-RPN,MDNet / VITAL,SiamFC / StructSiam,ASRCF和DSiam。就成功指标而言,OTB2013数据集上的ASRCF,VITAL,MDNet,DAT和SiamRPN ++,OTB2015数据集上的SiamRPN ++,SANet,ASRCF,VITAL和MDNet以及C-RPN,MDNet, LaSOT数据集上的VITAL,ASRCF和SiamFC分别达到了最佳性能。在VOT2018数据集上(参见图5和表7),按准确性衡量,排名前5位的视觉跟踪器是SiamMask,SiamRPN ++,DaSiamRPN,C-RPN和SiamDW-SiamRPN,而UPDT,LSART,DeepSTRCF ,SiamMask和SiamRPN ++ / DRT分别具有最佳的鲁棒性。另一方面,基于两种精度成功度量的最佳视觉跟踪方法(参见图4)是OTB2013数据集上的VITAL,MDNet,ASRCF,DAT和SiamRPN ++,SiamRPN ++,ASRCF,VITAL ,OTB2015数据集上的SiamDW-SiamRPN和MDNet,以及LaSOT数据集上的C-RPN,MDNet,VITAL,SiamFC和ASRCF / StructSiam。在VOT2018数据集上,基于EAO得分,SiamRPN ++,SiamMask,UPDT,DRT和DeepSTRCF是性能最佳的跟踪器。此外,SiamRPN ++,UPDT,MCPF,LSART和DeepSTRCF均获得了最佳的AUC评分,而SiamRPN,SiamRPN ++,CFNet,DAT和DCFNet分别是最快的视觉跟踪器(请参见表7)。结果(例如,图4,图5和表7),在不同的视觉跟踪数据集上实现其理想性能的最佳视觉跟踪方法是VITAL [121],MDNet [68],DAT [137],ASRCF [ 155],SiamDW -SiamRPN [56],SiamRPN ++ [55],C-RPN [157],StructSiam [157],SiamMask [57],DaSiamRPN [111],UPDT [109],LSART [127],DeepSTRCF [122]和DRT [126]。这些方法将在第二节中进行研究。


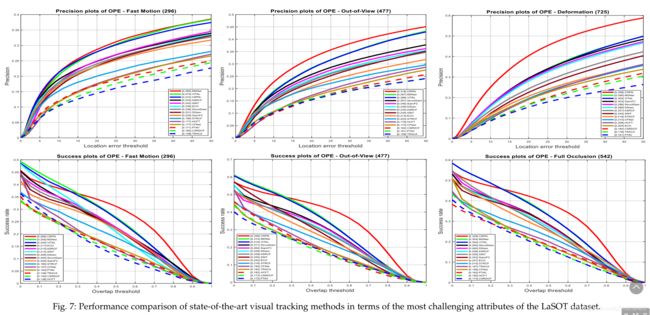
4.2每个基准数据集最具挑战性的属性
继VOT挑战[43]-[45]为视觉跟踪指定了最具挑战性的属性之后,本次调查不仅确定了VOT数据集上基于DL的方法的这些属性,而且还提供了OTB和首次使用LaSOT数据集。这些属性由VOT上每个属性的中位数准确性和鲁棒性,或OTB2015和LaSOT数据集上每个属性的中位数准确性和成功率来确定。表8显示了每个基准数据集的第一个到第五个具有挑战性的属性。同样,图5研究了处理这些属性的性能最佳的跟踪器。图5至图。 7.根据表8中的结果,VOT2018数据集上最具挑战性的属性是根据准确性度量标准的OCC,SV和IV,以及根据鲁棒性度量标准的OCC,MOC和IV。基于精度度量,OTB 2015上的OV,OCC和LR以及LaSOT数据集上的FM,OV和DEF是视觉跟踪方法最具挑战性的属性。最后,基于成功指标,OTB2015数据集的DEF,OV和LR以及LaSOT数据集的FM,OV和FOC是最具挑战性的。综上所述,OCC,OV,FM,DEF,IV和LR被选为最具挑战性的属性,可以有效地影响基于DL的视觉跟踪方法的性能。
另一方面,根据OCC,SV和IV,VOT2018数据集上最准确的视觉跟踪方法分别是SiamRPN ++ [55],SiamMask [57]和SiamMask。同样,根据OCC,MOC和IV,DRT [126],UPDT [109]和SiamMask [57] / CFCF [144]视觉跟踪器是VOT2018数据集上最强大的跟踪器。就成功指标而言,SiamRPN ++ [55]是解决DEF和OV属性的最佳视觉跟踪方法,而Siam-MCF [117]是处理OTB2015 LR视频中视觉跟踪的最佳方法。数据集。就面向OTB-2015数据集的OV,OCC和DEF属性的精度指标而言,ASRCF [155],ECO [94]和SiamDW-SiamRPN [56]是最佳跟踪器。除了FM属性,MDNet [68]在精度度量方面是最好的方法外,C-RPN [157]在LaSOT基准数据集的其他具有挑战性的属性方面,在精度和成功度量方面具有优越的性能。根据总体和基于属性的比较,C-RPN,MDNet和VITAL是LaSOT数据集中排名前三的跟踪器。
尽管VOT2018数据集为单个视频序列提供了基于帧的属性,但每个视频序列都带有OTB和LaSOT数据集的多个属性。根据此差异,仅研究了VOT2018上基于属性的比较,以根据特定条件推断最佳策略。如图。如图5所示,基于DCF的方法比其他方法获得的失败更少,而基于SNN的方法在估计的BB和地面真相之间获得了更多的重叠。基于SiamRPN的方法(即[55]-[57],[111])通过采用包括分类和回归分支在内的更深,更广泛的主干网络,可以准确地处理CM,IV,MC,OCC或SC属性下的情景。 ,以下策略可在实际场景的特定条件下提高基于DL的方法的鲁棒性。通过考虑手工和深度特征的融合[109],[122],[126],时间正则项[122],可靠性项[126],数据增强[109]和对ResNet-50模型的利用[ 109],基于DCF的方法已经获得了针对CM属性的理想鲁棒性。为了有效处理IV属性,关注目标及其背景之间的区分能力是主要问题。诸如训练用于相关滤波器成本函数的全卷积网络,空间感知KRR和空间感知CNN以及采用半监督视频对象分割等策略可在发生重大IV时提高基于DL的跟踪器的鲁棒性。为了可靠地处理MC和OCC属性,基于DCF和CNN的方法表现最好。但是,借助区域提案子网和提案优化的基于SNN的方法可以在严重的规模变化下稳健地估计最严格的BB。
4.3讨论
整体最佳方法(例如,VITAL [121],MDNet [68],DAT [137],ASRCF [155],SiamDW-SiamRPN [56],SiamRPN ++ [55],C-RPN [157],StructSiam [ 113,SiamMask [57],DaSiamRPN [111],UPDT [109],LSART [127],Deep-STRCF [122]和DRT [126])属于广泛的网络体系结构。例如,MDNet,LSART和DAT(使用MDNet架构设计)利用CNN定位视觉目标,而ASRCF(同时使用VGG-M和VGG-16),UPDT(使用ResNet-50),DRT(使用VGG-M和VGG-16)和DeepSTRCF(使用VGG-M)都只是利用预先训练的CNN模型进行特征提取。除了基于GAN的VITAL追踪器外,其他都具有SNN架构(即C-RPN,StructSiam,SiamMask,DaSiamRPN,SiamDW和SiamRPN ++)。当前,最吸引人的视觉跟踪深层架构是SNN [55]-[57],[111],[113],[157],尽管基于GAN和RL的方法最近已针对某些特定目的进行了开发例如解决训练样本的不平衡分布[121]或选择适当的实时搜索策略[110],[166]。除了在基于SNN的方法的性能和速度之间提供理想的平衡之外,还对该体系结构进行了修改,使其不仅可以与各种深层结构,搜索策略和学习方案集成,而且还可以充分利用卷积网络,相关层,区域提议网络视频对象检测模块(即,为视觉跟踪目的设计自定义网络)。有趣的一点是,包括SiamDW-SiamRPN,SiamRPN ++,C-RPN,SiamMask和DaSiamRPN在内的五种基于SNN的方法均基于快速SiamRPN方法[123],该方法由Siamese子网和区域建议子网组成。这些子网可用于对相关特征图进行特征提取和建议提取,以通过一次检测任务解决视觉跟踪问题。 SiamRPN方法的主要优点是时间效率高,估算准确,并将提案选择和优化策略集成到暹罗网络中。
有趣的是,利用深层现成功能的ASRCF,UPDT,DRT和DeepSTRCF是性能最高的视觉跟踪方法之一。此外,最佳方法中的五种方法UPDT,DeepSTRCF,DRT,LSART和ASRCF利用了DCF框架的优势。另一方面,大多数性能最佳的视觉跟踪器,即VITAL,MDNet,DAT,SiamDW,SiamRPN ++,C-RPN,StructSiam,SiamMask,DaSiamRPN和LSART,都利用专门的深度功能进行视觉跟踪。尽管具有多种骨干网(即AlexNet(用于C-RPN,StructSiam和DaSiamRPN),VGG-M(用于MDNet,VITAL和DAT),VGG-16(用于LSART)和ResNet(用于SiamMask,SiamDW-SiamRPN) )和SiamRPN ++))用于这些方法,最新的方法已经利用了更深的神经网络,例如ResNet-50,以增强目标建模的判别能力。从网络培训的角度来看,SiamDW-SiamRPN,SiamRPN ++,C-RPN,StructSiam,SiamMask和DaSiamRPN仅使用离线培训,而LSART仅使用在线培训(在线两流培训网络可有效地学习过滤器和目标的平面旋转)。这些方法中的大多数旨在学习脱机主导表示,以实现实时跟踪速度。处理大量外观变化需要在跟踪过程中适应网络参数,但是由于训练样本有限,在线培训存在过度拟合的风险。因此,通过采用对抗性学习,与领域无关的信息和注意力图作为正则化术语,VITAL,MDNet和DAT都可以使DNN的离线和在线培训受益。但是,这些方法提供的跟踪速度约为每秒一帧(FPS),不适合实时应用。从DNN的目标函数的角度来看,VITAL [121]和StructSiam [113]基于分类,LSART [127]基于回归,其他表现最佳的方法[55]-[57],[ 68],[111],[137],[157]基于分类和回归。例如,SiamRPN [123]的五个修改版本(即,SiamDW-SiamRPN [56],SiamRPN ++ [55],C-RPN [157],SiamMask [57]和DaSiamRPN [111])具有两个分支用于分类和回归。
基于最佳方法的动机分类,最近的先进方法依靠:1)通过数据增强[109],[111]和对抗性学习的生成网络[121],缓解视觉训练数据的不平衡分布[121],2)高效重新制定分类/回归问题的培训和学习程序[109],[111],[121],[122],[126],[127],[155],并提供视觉跟踪的指定功能[55]- [57],[68],[111],[113],[121],[137],[157],3)利用最先进的更深,更广泛的神经网络,通过利用杠杆作用提供更具区分性的表示ResNet建模为骨干网[55]-[57],[109]和4),通过采用诸如上下文[56],[109],[111],[113]或时间信息[ 111],[121],[122],[137]。 VITAL,DaSiamRPN和UPDT试图减轻训练数据的正样本和负样本的不平衡分布,并提取更多区分特征。 VITAL使用对抗性学习,不仅可以增加正样本,减少简单的负样本,还可以在跟踪过程中保留最具判别力和最强大的功能。此外,DaSiamRPN利用数据扩充和否定语义样本来考虑视觉干扰因素并提高视觉跟踪的鲁棒性。最后,UPDT使用标准的数据扩充以及浅层和深层功能。
为了改善基于DL的最佳方法的学习过程,UPDT,DeepSTRCF,DRT,LSART和ASRCF修改了DCF公式的传统岭回归。此外,DaSiamRPN和VITAL利用成本敏感型损失利用GAN的干扰觉察目标函数和重新制定的目标函数,分别改善了这些视觉跟踪器的训练过程。此外,在大规模数据集上对基于DL的方法进行训练会使其网络功能适应视觉跟踪目的。 SiamDW,SiamRPN ++和SiamMask方法旨在利用最先进的深度网络作为暹罗跟踪器的骨干网络。尽管这些方法利用ResNet模型,但SiamDW提出了新的残差模块和体系结构,以防止显着的接收场增加并同时提高特征可分辨性和定位精度。此外,SiamRPN ++提出的基于ResNet驱动的基于SNN的跟踪器包括不同的分层聚合和深度聚合,以填补基于SNN和基于CNN的方法之间的性能差距。感受野的增加,同时提高了特征的可分辨性和定位精度。此外,SiamRPN ++提出的基于ResNet驱动的基于SNN的跟踪器包括不同的分层聚合和深度聚合,以填补基于SNN和基于CNN的方法之间的性能差距。
尽管有一些其他计算机视觉任务(例如,对象检测或识别),但是对包括空间和时间信息的视频序列执行视觉跟踪。除了空间信息外,DAT和DeepSTRCF还以不同方式考虑时间信息以提供更强大的功能。 DAT和DeepSTRCF分别采用往复学习和在线被动攻击(PA)学习。带有注意力正则化条件的往复式学习方案会激活一个细心的分类器,以借助时间特征来稳健地选择目标区域,而在线PA学习的时空正则化则有助于降低跟踪器的灵敏度并更好地适应重大的外观变化。从学习的角度来看,相似性学习的四种学习方法(即SiamDW,SiamRPN ++,C-RPN,StructSiam,SiamMask,DaSiamRPN),多域学习(即MDNet,DAT),对抗性学习(即VITAL),空间感知回归学习(即LSART)和DCF学习。在下文中,将基于最佳的视觉跟踪方法的优缺点进行研究。 C-RPN,StructSiam和DaSiamRPN的三种基于SNN的方法都利用浅层AlexNet作为它们的主干网络(请参见表2),这是根据它们的判别能力而得出的主要缺点。为了在存在明显的尺度变化和视觉干扰因素的情况下提高跟踪的鲁棒性,C-RPN在暹罗网络中级联多个RPN,以利用硬性否定采样(以提供更均衡的训练样本),多级特征和多个步骤回归。为了降低基于SNN的方法对非刚性外观更改和POC属性的敏感性,StructSiam可以检测局部模式及其关系的上下文信息,并通过暹罗网络实时匹配它们。通过采用局部到全局搜索策略和非最大抑制(NMS)来重新检测目标并减少潜在的干扰因素,DaSiamRPN可以正确应对FOC,OV,POC和BC挑战。相反,SiamMask,SiamDW-SiamRPN和SiamRPN ++利用ResNet模型。为了依靠丰富的目标表示,SiamMask使用三分支体系结构通过旋转的BB估计目标位置,其中包括目标的二进制掩码。 SiamMask失败的主要原因是MB和OV属性会产生错误的目标蒙版。为了使用最新的视觉跟踪方法降低基于SNN的方法的性能裕度,SiamDW-SiamRPN和SiamRPN ++研究了深层骨干网的利用,以降低这些方法对最具挑战性的属性的敏感性。
MDNet及其基于它的其他方法(例如DAT)仍然是最佳的视觉跟踪方法。由于在大规模视觉跟踪数据集上对这些网络进行了专门的离线和在线训练,因此这些方法可以应对各种各样的挑战在上述情况下,几乎不会错过视觉目标,并且具有令人满意的跟踪LR目标的性能。然而,这些方法具有计算复杂度高,具有相似语义的目标的类内区分以及执行用于尺度估计的离散空间的缺点。 VITAL可以承受大量的DEF,IPR和OPR,因为它通过高阶成本敏感损失专注于硬性阴性样品。但是,由于通过生成网络生产固定尺寸的防重罩,因此在显着的SV情况下,它的性能不强。 LSART利用修正的Kernelized ridge回归(KRR),通过逐块相似性的加权组合来集中于目标的可靠区域。由于考虑了轮换信息和CNN模型的在线适应,因此该方法为解决DEF和IPR挑战提供了有希望的响应。
DeepSTRCF,ASRCF,DRT和UPDT是基于DCF的方法,不仅可以利用现成的较深功能,而且还可以将其与较浅的功能(例如HOG和CN)融合,以提高视觉跟踪的鲁棒性(请参阅表)第一)。为了减少OCC和OV属性的不利影响,DeepSTRCF将时间正则项添加到空间正则DCF公式中。重新审视的配方有助于DeepSTRCF不仅可以忍受某些外观变化,例如IV,IPR,OPR和POC。使用对象感知的空间正则化和可靠性项,ASRCF和DRT方法尝试优化模型以有效地学习更多的自适应相关滤波器。这两种方法都研究了基于DCF的方法的主要缺陷,例如循环移位采样过程,相同的特征空间定位和尺度估计过程,严格的区分度以及相关响应的稀疏和不均匀分布。因此,这些方法可以适当地处理DEF,BC和SV。最后,UPDT致力于通过独立地训练基于浅特征的DCF和基于深度现成特征的DCF并考虑采用自适应融合模型来增强训练样本,从而增强视觉跟踪的鲁棒性。尽管这些方法展示了设计精良的基于DCF的跟踪器与更复杂的跟踪器相比的竞争性能,但它们仍受预训练模型的局限性(例如,深层特征的计算复杂性),宽高比变化,模型降级和外观差异很大。
为了定性比较最佳方法的性能,图图8显示了SiamRPN ++ [55],SiamMask [57],C-RPN [157],SiamDW-SiamRPN [56],ECO [94],LSART [127],DRT [126],UPDT [ 109]和DeepSTRCF [122]在VOT2018数据集的不同视频序列上。根据这些结果,所有这些方法在具有多个关键视觉属性的具有挑战性的场景中均告失败。例如,当OCC和SV同时出现时,SiamMask会滥用半监督视频对象分割,或者大量SV会大大降低SiamRPN ++的性能。尽管视觉跟踪已经取得了长足的进步,但是最新的视觉跟踪方法仍然无法应对现实世界中的挑战。目标外观的严重变化,MOC,OCC,SV,CM,DEF甚至IV不仅会严重影响其性能,还会导致失败。这些结果表明,由于缺乏用于场景理解的智能性,其最新方法对于实际应用仍然不可靠。尽管视觉跟踪方法提高了对象与场景区分的能力,但是基于DL的视觉跟踪器仍然无法推断场景信息,无法立即识别场景的全局/配置结构,也无法基于空间和内部行为来组织有目的的决策。
5 结论和未来方向
基于网络体系结构,网络开发,网络训练,网络目标,网络输出以及相关过滤器优势的开发,基于DL的最新视觉跟踪方法被分类为广泛的分类法。 此外,根据不同方法提出的主要问题和解决方案对这些方法的动机和贡献进行了分类。 此外,不仅简要研究了最新的视觉跟踪基准数据集和评估指标,而且还根据OTB2013,OTB2015,VOT2018和LaSOT基准数据集上的各种评估指标对最新的视觉跟踪方法进行了比较。 。
最近,基于DL的视觉跟踪方法研究了对深层现成特征的不同利用,深层特征与手工特征的融合,大规模数据集上DNN的在线训练,更新方案,搜索策略,上下文信息,时间信息以及如何处理缺乏训练数据的信息。但是,将来还需要探索许多其他问题。当前的主要工作是设计用于视觉跟踪的定制神经网络,以便它们可以同时提供鲁棒性,准确性和效率。这些跟踪器是通过将高效的网络体系结构与分类和回归分支相集成而首先开发的,不仅在大规模数据集上进行了训练,还学会了针对最具挑战性的视觉属性(例如,OCC,OV,FM,IV)的强大表示形式和LR)。通过分析不同的方法,主要问题是它们在场景理解上的不足。最新的视觉跟踪方法仍然无法以有意义的方式解释动态场景,无法立即识别全局结构,推断存在的对象以及感知不同对象或事件的基本级别类别。尽管已竭尽全力设计复杂的方法和耗时的培训程序,但这些方法在现实情况中迅速失去了通用目标。例如,这些方法仍然存在同时处理重要属性(例如OCC,DEF,SV和FM)的问题。尽管基于SNN的方法理想地降低了视觉跟踪器的计算复杂度,但是可以修改这些体系结构以不仅采用互补功能(例如时间信息),而且还可以与最近的RL和对抗性学习相结合。最后,DNN的在线训练可以使网络过滤器很好地适应目标外观的显着变化。但是,它需要更有效的策略来减少计算复杂性,这是实时应用程序所必需的。
修改后不仅可以使用互补功能(例如时间信息),还可以与最近的RL和对抗性学习相结合。最后,DNN的在线训练可以使网络过滤器很好地适应目标外观的显着变化。但是,它需要更有效的策略来减少计算复杂性,这是实时应用程序所必需的。
致谢
我们要感谢教授。 Kamal Nasrollahi(奥尔堡大学人眼视觉分析(VAP),他的有益评论)。
参考文献:
[1] M.-f. Chang, J. Lambert, P. Sangkloy, J. Singh, B. Sławomir,A. Hartnett, D. Wang, P. Carr, S. Lucey, D. Ramanan, and J. Hays,“Argoverse: 3D tracking and forecasting with rich maps,” in Proc.IEEE CVPR, 2019, pp. 8748–8757.
[2] W. Luo, B. Yang, and R. Urtasun, “Fast and furious: Real-time end-to-end 3D detection, tracking and motion forecasting with a single convolutional net,” in Proc. IEEE CVPR, 2018, pp. 3569–3577.
[3] P. Gir˜ ao, A. Asvadi, P. Peixoto, and U. Nunes, “3D object tracking in driving environment: A short review and a benchmark dataset,” in Proc. IEEE ITSC, 2016, pp. 7–12.
[4] C. Li, X. Liang, Y. Lu, N. Zhao, and J. Tang, “RGB-T object tracking: Benchmark and baseline,” Pattern Recognit., vol. 96,2019.
[5] H. V. Hoof, T. V. D. Zant, and M. Wiering, “Adaptive visual face tracking for an autonomous robot,” in Proc. Belgian/Netherlands Artificial Intelligence Conference, 2011.
[6] C. Robin and S. Lacroix, “Multi-robot target detection and tracking: Taxonomy and survey,” Autonomous Robots, vol. 40, no. 4, pp.729–760, 2016.
[7] B. Risse, M. Mangan, B. Webb, and L. Del Pero, “Visual tracking of small animals in cluttered natural environments using a freely moving camera,” in Proc. IEEE ICCVW, 2018, pp. 2840–2849.
[8] Y. Luo, D. Yin, A. Wang, and W. Wu, “Pedestrian tracking in surveillance video based on modified CNN,” Multimed. Tools Appl., vol. 77, no. 18, pp. 24041–24058, 2018.
[9] A. Brunetti, D. Buongiorno, G. F. Trotta, and V. Bevilacqua, “Computer vision and deep learning techniques for pedestrian detection and tracking: A survey,” Neurocomputing, vol. 300, pp.17–33, 2018.
[10] L. Hou, W. Wan, J. N. Hwang, R. Muhammad, M. Yang, and K. Han, “Human tracking over camera networks: A review,”EURASIP Journal on Advances in Signal Processing, vol. 2017, no. 1,2017.
[11] G. Klein, “Visual tracking for augmented reality,” Phd Thesis, pp.1–182, 2006.
[12] M. Klopschitz, G. Schall, D. Schmalstieg, and G. Reitmayr, “Visual tracking for augmented reality,” in Proc. IPIN, 2010, pp. 1–4.
[13] F. Ababsa, M. Maidi, J. Y. Didier, and M. Mallem, “Vision-based tracking for mobile augmented reality,” in Studies in Computa-tional Intelligence. Springer, 2008, vol. 120, pp. 297–326.
[14] J. Hao, Y. Zhou, G. Zhang, Q. Lv, and Q. Wu, “A review of target tracking algorithm based on UAV,” in Proc. IEEE CBS, 2019, pp. 328–333. survey on player tracking in soccer videos,” Comput. Vis. Image Und., vol. 159, pp. 19–46, 2017.
[16] D. Bouget, M. Allan, D. Stoyanov, and P. Jannin, “Vision-based and marker-less surgical tool detection and tracking: A review of the literature,” Medical Image Analysis, vol. 35, pp. 633–654, 2017.
[17] V. Ulman, M. Maˇ ska, and et al., “An objective comparison of cell-tracking algorithms,” Nature Methods, vol. 14, no. 12, pp. 1141–1152, 2017.
[18] T. He, H. Mao, J. Guo, and Z. Yi, “Cell tracking using deep neural networks with multi-task learning,” Image Vision Comput., vol. 60, pp. 142–153, 2017.
[19] D. E. Hernandez, S. W. Chen, E. E. Hunter, E. B. Steager, and V. Kumar, “Cell tracking with deep learning and the Viterbi algorithm,” in Proc. MARSS, 2018, pp. 1–6.
[20] J. Luo, Y. Han, and L. Fan, “Underwater acoustic target tracking: A review,” Sensors, vol. 18, no. 1, p. 112, 2018.
[21] D. S. Bolme, J. R. Beveridge, B. A. Draper, and Y. M. Lui, “Visual object tracking using adaptive correlation filters,” in Proc. IEEE CVPR, 2010, pp. 2544–2550.
[22] J. F. Henriques, R. Caseiro, P. Martins, and J. Batista, “High-speed tracking with kernelized correlation filters,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 3, pp. 583–596, 2015.
[23] M. Danelljan, G. Hager, F. S. Khan, and M. Felsberg, “Discriminative Scale Space Tracking,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 8, pp. 1561–1575, 2017.
[24] S. M. Marvasti-Zadeh, H. Ghanei-Yakhdan, and S. Kasaei, “Rotation-aware discriminative scale space tracking,” in Iranian Conf. Electrical Engineering (ICEE), 2019, pp. 1272–1276.
[25] G. Boudoukh, I. Leichter, and E. Rivlin, “Visual tracking of object silhouettes,” in Proc. ICIP, 2009, pp. 3625–3628.
[26] C. Xiao and A. Yilmaz, “Efficient tracking with distinctive target colors and silhouette,” in Proc. ICPR, 2016, pp. 2728–2733.
[27] V. Bruni and D. Vitulano, “An improvement of kernel-based object tracking based on human perception,” IEEE Trans. Syst., Man, Cybern. Syst., vol. 44, no. 11, pp. 1474–1485, 2014.
[28] W. Chen, B. Niu, H. Gu, and X. Zhang, “A novel strategy for kernel-based small target tracking against varying illumination with multiple features fusion,” in Proc. ICICT, 2018, pp. 135–138.
[29] D. H. Kim, H. K. Kim, S. J. Lee, W. J. Park, and S. J. Ko, “Kernel-based structural binary pattern tracking,” IEEE Trans. Circuits Syst. Video Technol., vol. 24, no. 8, pp. 1288–1300, 2014.
[30] I. I. Lychkov, A. N. Alfimtsev, and S. A. Sakulin, “Tracking of moving objects with regeneration of object feature points,” in Proc. GloSIC, 2018, pp. 1–6.
[31] M. Ighrayene, G. Qiang, and T. Benlefki, “Making Bayesian tracking and matching by the BRISK interest points detector/descriptor cooperate for robust object tracking,” in Proc. IEEE ICSIP, 2017, pp. 731–735.
[32] N. Dalal and B. Triggs, “Histograms of oriented gradients for human detection,” in Proc. IEEE CVPR, 2005, pp. 886–893.
[33] J. Van De Weijer, C. Schmid, and J. Verbeek, “Learning color names from real-world images,” in Proc. IEEE CVPR, 2007, pp.1–8.
[34] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet classification with deep convolutional neural networks,” in Proc. NIPS, vol. 2, 2012, pp. 1097–1105.
[35] K. Chatfield, K. Simonyan, A. Vedaldi, and A. Zisserman, “Return of the devil in the details: Delving deep into convolutional nets,” in Proc. BMVC, 2014, pp. 1–11.
[36] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Proc. ICLR, 2014, pp. 1–14.
works for large-scale image recognition,” in Proc. ICLR, 2014, pp. 1–14.
[37] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” in Proc. IEEE CVPR, 2015, pp. 1–9.
[38] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. IEEE CVPR, 2016, pp. 770–778.
[39] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet large scale visual recognition challenge,” IJCV, vol. 115, no. 3, pp. 211–252, 2015.
[40] M. Kristan, R. Pflugfelder, A. Leonardis, J. Matas, F. Porikli, and et al., “The visual object tracking VOT2013 challenge results,” in Proc. ICCV, 2013, pp. 98–111.
[41] M. Kristan, R. Pflugfelder, A. Leonardis, J. Matas, and et al., “The visual object tracking VOT2014 challenge results,” in Proc. ECCV,2015, pp. 191–217.
[42] M. Kristan, J. Matas, A. Leonardis, M. Felsberg, and et al., “The visual object tracking VOT2015 challenge results,” in Proc. IEEE ICCV, 2015, pp. 564–586.
[43] M. Kristan, J. Matas, A. Leonardis, M. Felsberg, R. Pflugfelder, and et al., “The visual object tracking VOT2016 challenge results,” in Proc. ECCVW, 2016, pp. 777–823.
[44] M. Kristan, A. Leonardis, J. Matas, M. Felsberg, R. Pflugfelder, L. C. Zajc, and et al., “The visual object tracking VOT2017 challenge results,” in Proc. IEEE ICCVW, 2017, pp. 1949–1972.
[45] M. Kristan, A. Leonardis, J. Matas, M. Felsberg, R. Pflugfelder, and et al., “The sixth visual object tracking VOT2018 challenge results,” in Proc. ECCVW, 2019, pp. 3–53.
[46] M. Kristan and et al., “The seventh visual object tracking VOT2019 challenge results,” in Proc. ICCVW, 2019.
[47] A. Yilmaz, O. Javed, and M. Shah, “Object tracking: A survey,” ACM Computing Surveys, vol. 38, no. 4, Dec. 2006.
[48] A. W. Smeulders, D. M. Chu, R. Cucchiara, S. Calderara, A. Dehghan, and M. Shah, “Visual tracking: An experimental survey,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 7, pp. 1442–1468, 2014.
[49] H. Yang, L. Shao, F. Zheng, L. Wang, and Z. Song, “Recent advances and trends in visual tracking: A review,” Neurocomputing, vol. 74, no. 18, pp. 3823–3831, 2011.
[50] X. Li, W. Hu, C. Shen, Z. Zhang, A. Dick, and A. Van Den Hengel, “A survey of appearance models in visual object tracking,” ACM Trans. Intell. Syst. Tec., vol. 4, no. 4, pp. 58:1—-58:48, 2013.
[51] M. Fiaz, A. Mahmood, and S. K. Jung, “Tracking noisy targets: A review of recent object tracking approaches,” 2018. [Online].Available: http://arxiv.org/abs/1802.03098
[52] M. Fiaz, A. Mahmood, S. Javed, and S. K. Jung, “Handcrafted and deep trackers: Recent visual object tracking approaches and trends,” ACM Computing Surveys, vol. 52, no. 2, pp. 43:1—-43:44, 2019.
[53] P. Li, D. Wang, L. Wang, and H. Lu, “Deep visual tracking: Review and experimental comparison,” Pattern Recognit., vol. 76, pp. 323–338, 2018.
[54] R. Pflugfelder, “An in-depth analysis of visual tracking with Siamese neural networks,” 2017. [Online]. Available: http://arxiv.org/abs/1707.00569
[55] B. Li, W. Wu, Q. Wang, F. Zhang, J. Xing, and J. Yan, “SiamRPN++: Evolution of Siamese visual tracking with very deep networks,” 2018. [Online]. Available: http://arxiv.org/abs/1812.11703
[56] Z. Zhang and H. Peng, “Deeper and wider Siamese networks for real-time visual tracking,” 2019. [Online]. Available: http://arxiv.org/abs/1901.01660
[57] Q. Wang, L. Zhang, L. Bertinetto, W. Hu, and P. H. S. Torr, “Fast online object tracking and segmentation: A unifying approach,” 2018. [Online]. Available: http://arxiv.org/abs/1812.05050
[58] X. Wang, C. Li, B. Luo, and J. Tang, “SINT++: Robust visual tracking via adversarial positive instance generation,” in Proc. IEEE CVPR, 2018, pp. 4864–4873.
[59] C. Ma, J. B. Huang, X. Yang, and M. H. Yang, “Hierarchical convolutional features for visual tracking,” in Proc. IEEE ICCV, 2015, pp. 3074–3082.
[60] M. Danelljan, G. Hager, F. S. Khan, and M. Felsberg, “Convolutional features for correlation filter based visual tracking,” in Proc. IEEE ICCVW, 2016, pp. 621–629.
[61] L. Wang, W. Ouyang, X. Wang, and H. Lu, “Visual tracking with fully convolutional networks,” in Proc. IEEE ICCV, 2015, pp. 3119–3127.
[62] S. Hong, T. You, S. Kwak, and B. Han, “Online tracking by learning discriminative saliency map with convolutional neural network,” in Proc. ICML, 2015, pp. 597–606.
[63] Y. Zha, T. Ku, Y. Li, and P. Zhang, “Deep position-sensitive tracking,” IEEE Trans. Multimedia, no. 8, 2019.
[64] M. Danelljan, A. Robinson, F. S. Khan, and M. Felsberg, “Beyond correlation filters: Learning continuous convolution operators for visual tracking,” in Proc. ECCV, vol. 9909 LNCS, 2016, pp. 472–488.
[65] D. Held, S. Thrun, and S. Savarese, “Learning to track at 100 FPS with deep regression networks,” in Proc. ECCV, 2016, pp. 749– 765.
[66] L. Bertinetto, J. Valmadre, J. F. Henriques, A. Vedaldi, and P. H. Torr, “Fully-convolutional Siamese networks for object tracking,” in Proc. ECCV, 2016, pp. 850–865.
[67] R. Tao, E. Gavves, and A. W. Smeulders, “Siamese instance search for tracking,” in Proc. IEEE CVPR, 2016, pp. 1420–1429.
[68] H. Nam and B. Han, “Learning multi-domain convolutional neural networks for visual tracking,” in Proc. IEEE CVPR, 2016, pp. 4293–4302.
[69] Y. Qi, S. Zhang, L. Qin, H. Yao, Q. Huang, J. Lim, and M. H. Yang, “Hedged deep tracking,” in Proc. IEEE CVPR, 2016, pp. 4303–4311.
[70] L. Wang, W. Ouyang, X. Wang, and H. Lu, “STCT: Sequentially training convolutional networks for visual tracking,” in Proc. IEEE CVPR, 2016, pp. 1373–1381.
[71] G. Zhu, F. Porikli, and H. Li, “Robust visual tracking with deep convolutional neural network based object proposals on PETS,” in Proc. IEEE CVPRW, 2016, pp. 1265–1272.
[72] H. Li, Y. Li, and F. Porikli, “DeepTrack: Learning discriminative feature representations online for robust visual tracking,” IEEE Trans. Image Process., vol. 25, no. 4, pp. 1834–1848, 2016.
[73] K. Zhang, Q. Liu, Y. Wu, and M. H. Yang, “Robust visual tracking via convolutional networks without training,” IEEE Trans. Image Process., vol. 25, no. 4, pp. 1779–1792, 2016.
[74] C. Ma, Y. Xu, B. Ni, and X. Yang, “When correlation filters meet convolutional neural networks for visual tracking,” IEEE Signal Process. Lett., vol. 23, no. 10, pp. 1454–1458, 2016.
[75] H. Nam, M. Baek, and B. Han, “Modeling and propagating CNNs in a tree structure for visual tracking,” 2016. [Online]. Available: http://arxiv.org/abs/1608.07242
[76] G. Wu, W. Lu, G. Gao, C. Zhao, and J. Liu, “Regional deep learning model for visual tracking,” Neurocomputing, vol. 175, no. PartA, pp. 310–323, 2015.
[77] H. Fan and H. Ling, “Parallel tracking and verifying: A framework for real-time and high accuracy visual tracking,” in Proc. IEEE ICCV, 2017, pp. 5487–5495.
[78] H. Fan and H.Ling, “Parallel tracking and verifying,” IEEE Trans. Image Process., vol. 28, no. 8, pp. 4130–4144, 2019.
[79] Y. Song, C. Ma, L. Gong, J. Zhang, R. W. Lau, and M. H. Yang, “CREST: Convolutional residual learning for visual tracking,” in Proc. ICCV, 2017, pp. 2574–2583.
[80] Z. Zhu, G. Huang, W. Zou, D. Du, and C. Huang, “UCT: Learning unified convolutional networks for real-time visual tracking,” in Proc. ICCVW, 2018, pp. 1973–1982.
[81] Q. Guo, W. Feng, C. Zhou, R. Huang, L. Wan, and S. Wang,“Learning dynamic Siamese network for visual object tracking,”in Proc. IEEE ICCV, 2017, pp. 1781–1789.
[82] Z. Teng, J. Xing, Q. Wang, C. Lang, S. Feng, and Y. Jin, “Robust object tracking based on temporal and spatial deep networks,” in Proc. IEEE ICCV, 2017, pp. 1153–1162.
[83] Z. He, Y. Fan, J. Zhuang, Y. Dong, and H. Bai, “Correlation filters with weighted convolution responses,” in Proc. ICCVW, 2018, pp. 1992–2000.
[84] T. Yang and A. B. Chan, “Recurrent filter learning for visual tracking,” in Proc. ICCVW, 2018, pp. 2010–2019.
[85] F. Li, Y. Yao, P. Li, D. Zhang, W. Zuo, and M. H. Yang, “Integrating boundary and center correlation filters for visual tracking with aspect ratio variation,” in Proc. IEEE ICCVW, 2018, pp. 2001–2009.
[86] X. Wang, H. Li, Y. Li, F. Porikli, and M. Wang, “Deep tracking with objectness,” in Proc. ICIP, 2018, pp. 660–664.
[87] X. Xu, B. Ma, H. Chang, and X. Chen, “Siamese recurrent archi- tecture for visual tracking,” in Proc. ICIP, 2018, pp. 1152–1156.
[88] L. Yang, P. Jiang, F. Wang, and X. Wang, “Region-based fully convolutional Siamese networks for robust real-time visual tracking,” in Proc. ICIP, 2017, pp. 2567–2571.
[89] T. Kokul, C. Fookes, S. Sridharan, A. Ramanan, and U. A. J. Pinidiyaarachchi, “Gate connected convolutional neural network for object tracking,” in Proc. ICIP, 2017, pp. 2602–2606.
[90] K. Dai, Y. Wang, and X. Yan, “Long-term object tracking based on Siamese network,” in Proc. ICIP, 2017, pp. 3640–3644.
[91] B. Akok, F. Gurkan, O. Kaplan, and B. Gunsel, “Robust object tracking by interleaving variable rate color particle filtering and deep learning,” in Proc. ICIP, 2017, pp. 3665–3669.
[92] R. J. Mozhdehi and H. Medeiros, “Deep convolutional particle filter for visual tracking,” in Proc. IEEE ICIP, 2017, pp. 3650–3654.
[93] J. Valmadre, L. Bertinetto, J. Henriques, A. Vedaldi, and P. H. Torr, “End-to-end representation learning for correlation filter based tracking,” in Proc. IEEE CVPR, 2017, pp. 5000–5008.
[94] M. Danelljan, G. Bhat, F. Shahbaz Khan, and M. Felsberg, “ECO:Efficient convolution operators for tracking,” in Proc. IEEE CVPR,2017, pp. 6931–6939.
[95] A. Lukeˇ ziˇ c, T. Voj´ ı, L.ˇCehovinZajc, J. Matas, and M. Kristan, “Discriminative correlation filter tracker with channel and spatial reliability,” IJCV, vol. 126, no. 7, pp. 671–688, 2018.
[96] T. Zhang, C. Xu, and M. H. Yang, “Multi-task correlation particle filter for robust object tracking,” in Proc. IEEE CVPR, 2017, pp.4819–4827.
[97] B. Han, J. Sim, and H. Adam, “BranchOut: Regularization for online ensemble tracking with convolutional neural networks,” in Proc. IEEE CVPR, 2017, pp. 521–530.
[98] M. Wang, Y. Liu, and Z. Huang, “Large margin object tracking with circulant feature maps,” in Proc. IEEE CVPR, 2017, pp. 4800–4808.
[99] L. Zhang, J. Varadarajan, P. N. Suganthan, N. Ahuja, and P. Moulin, “Robust visual tracking using oblique random forests,” in Proc. IEEE CVPR, 2017, pp. 5825–5834.
[100] J. Choi, H. J. Chang, S. Yun, T. Fischer, Y. Demiris, and J. Y. Choi, “Attentional correlation filter network for adaptive visual tracking,” in Proc. IEEE CVPR, 2017, pp. 4828–4837.
[101] H. Fan and H. Ling, “SANet: Structure-aware network for visual tracking,” in Proc. IEEE CVPRW, 2017, pp. 2217–2224.
[102] Q. Wang, J. Gao, J. Xing, M. Zhang, and W. Hu, “DCFNet: Discriminant correlation filters network for visual tracking,” 2017. [Online]. Available: http://arxiv.org/abs/1704.04057
[103] J. Guo and T. Xu, “Deep ensemble tracking,” IEEE Signal Process. Lett., vol. 24, no. 10, pp. 1562–1566, 2017.
[104] J. Gao, T. Zhang, X. Yang, and C. Xu, “Deep relative tracking,” IEEE Trans. Image Process., vol. 26, no. 4, pp. 1845–1858, 2017.
[105] Z. Chi, H. Li, H. Lu, and M. H. Yang, “Dual deep network for visual tracking,” IEEE Trans. Image Process., vol. 26, no. 4, pp.2005–2015, 2017.
[106] P. Zhang, T. Zhuo, W. Huang, K. Chen, and M. Kankanhalli, “Online object tracking based on CNN with spatial-temporal saliency guided sampling,” Neurocomputing, vol. 257, pp. 115–127, 2017.
[107] X. Dong and J. Shen, “Triplet loss in Siamese network for object tracking,” in Proc. ECCV, vol. 11217 LNCS, 2018, pp. 472–488.
[108] X. Lu, C. Ma, B. Ni, X. Yang, I. Reid, and M. H. Yang, “Deepregression tracking with shrinkage loss,” in Proc. ECCV, 2018,pp. 369–386.
[109] G. Bhat, J. Johnander, M. Danelljan, F. S. Khan, and M. Felsberg, “Unveiling the power of deep tracking,” in Proc. ECCV, 2018, pp. 493–509.
[110] B. Chen, D. Wang, P. Li, S. Wang, and H. Lu, “Real-time ‘actor-critic’ tracking,” in Proc. ECCV, 2018, pp. 328–345.
[111] Z. Zhu, Q. Wang, B. Li, W. Wu, J. Yan, and W. Hu, “Distractor-aware Siamese networks for visual object tracking,” in Proc.
[112] I. Jung, J. Son, M. Baek, and B. Han, “Real-time MDNet,” in Proc. ECCV, 2018, pp. 89–104.
[113] Y. Zhang, L. Wang, J. Qi, D. Wang, M. Feng, and H. Lu, “Structured Siamese network for real-time visual tracking,” in Proc. ECCV, 2018, pp. 355–370.
[114] H. Lee, S. Choi, and C. Kim, “A memory model based on the Siamese network for long-term tracking,” in Proc. ECCVW, 2019, pp. 100–115.
[115] M. Che, R. Wang, Y. Lu, Y. Li, H. Zhi, and C. Xiong, “Channel
[116] E. Burceanu and M. Leordeanu, “Learning a robust society of tracking parts using co-occurrence constraints,” in Proc. ECCVW, 2019, pp. 162–178.
[117] H. Morimitsu, “Multiple context features in Siamese networks for visual object tracking,” in Proc. ECCVW, 2019, pp. 116–131.
[118] A. He, C. Luo, X. Tian, and W. Zeng, “Towards a better match in Siamese network based visual object tracker,” in Proc. ECCVW, 2019, pp. 132–147.
[119] L. Rout, D. Mishra, and R. K. S. S. Gorthi, “WAEF: Weighted aggregation with enhancement filter for visual object tracking,” in Proc. ECCVW, 2019, pp. 83–99.
[120] J. Choi, H. J. Chang, T. Fischer, S. Yun, K. Lee, J. Jeong, Y. Demiris, and J. Y. Choi, “Context-aware deep feature compression for high-speed visual tracking,” in Proc. IEEE CVPR, 2018, pp. 479–488.
[121] Y. Song, C. Ma, X. Wu, L. Gong, L. Bao, W. Zuo, C. Shen, R. W. Lau, and M. H. Yang, “VITAL: Visual tracking via adversarial learning,” in Proc. IEEE CVPR, 2018, pp. 8990–8999.
[122] F. Li, C. Tian, W. Zuo, L. Zhang, and M. H. Yang, “Learning spatial-temporal regularized correlation filters for visual tracking,” in Proc. IEEE CVPR, 2018, pp. 4904–4913.
[123] B. Li, J. Yan, W. Wu, Z. Zhu, and X. Hu, “High performance visual tracking with Siamese region proposal network,” in Proc. IEEE CVPR, 2018, pp. 8971–8980.
[124] A. He, C. Luo, X. Tian, and W. Zeng, “A twofold Siamese network for real-time object tracking,” in Proc. IEEE CVPR, 2018, pp. 4834–4843.
[125] Z. Zhu, W. Wu, W. Zou, and J. Yan, “End-to-end flow correlation tracking with spatial-temporal attention,” in Proc. IEEE CVPR, 2018, pp. 548–557.
[126] C. Sun, D. Wang, H. Lu, and M. H. Yang, “Correlation tracking via joint discrimination and reliability learning,” in Proc. IEEE CVPR, 2018, pp. 489–497.
[127] C. Sun, D. Wang, H. Lu, and M. Yang, “Learning spatial-aware regressions for visual tracking,” in Proc. IEEE CVPR, 2018, pp.8962–8970.
[128] Q. Wang, Z. Teng, J. Xing, J. Gao, W. Hu, and S. Maybank, “Learning attentions: Residual attentional Siamese network for high performance online visual tracking,” in Proc. IEEE CVPR,2018, pp. 4854–4863.
[129] N. Wang, W. Zhou, Q. Tian, R. Hong, M. Wang, and H. Li, “Multicue correlation filters for robust visual tracking,” in Proc. IEEE CVPR, 2018, pp. 4844–4853.
[130] R. J. Mozhdehi, Y. Reznichenko, A. Siddique, and H. Medeiros, “Deep convolutional particle filter with adaptive correlation maps for visual tracking,” in Proc. ICIP, 2018, pp. 798–802.
[131] Z. Lin and C. Yuan, “Robust visual tracking in low-resolution sequence,” in Proc. ICIP, 2018, pp. 4103–4107.
[132] M. Cen and C. Jung, “Fully convolutional Siamese fusion networks for object tracking,” in Proc. ICIP, 2018, pp. 3718–3722.
[133] G. Wang, B. Liu, W. Li, and N. Yu, “Flow guided Siamese network for visual tracking,” in Proc. ICIP, 2018, pp. 231–235.
[134] K. Dai, Y. Wang, X. Yan, and Y. Huo, “Fusion of template matching and foreground detection for robust visual tracking,”in Proc. ICIP, 2018, pp. 2720–2724.
[135] G. Liu and G. Liu, “Integrating multi-level convolutional features for correlation filter tracking,” in Proc. ICIP, 2018, pp. 3029–3033.
[136] J. Guo, T. Xu, S. Jiang, and Z. Shen, “Generating reliable online adaptive templates for visual tracking,” in Proc. ICIP, 2018, pp.226–230.
[137] S. Pu, Y. Song, C. Ma, H. Zhang, and M. H. Yang, “Deep attentive tracking via reciprocative learning,” in Proc. NIPS, 2018, pp. 1931–1941.
[138] X. Jiang, X. Zhen, B. Zhang, J. Yang, and X. Cao, “Deep collabo-rative tracking networks,” in Proc. BMVC, 2018, p. 87.
[139] D. Ma, W. Bu, and X. Wu, “Multi-scale recurrent tracking via yramid recurrent network and optical flow,” in Proc. BMVC, 2018, p. 242.
[140] C. Ma, J. B. Huang, X. Yang, and M. H. Yang, “Robust visual tracking via hierarchical convolutional features,” IEEE Trans. Pattern Anal. Mach. Intell., 2018.
[141] Z. Han, P. Wang, and Q. Ye, “Adaptive discriminative deep Syst. Video Technol., 2018.
[142] K. Chen and W. Tao, “Once for all: A two-flow convolutional neural network for visual tracking,” IEEE Trans. Circuits Syst. Video Technol., vol. 28, no. 12, pp. 3377–3386, 2018.
[143] S. Li, S. Zhao, B. Cheng, E. Zhao, and J. Chen, “Robust visual tracking via hierarchical particle filter and ensemble deep fea-tures,” IEEE Trans. Circuits Syst. Video Technol., 2018.
[144] E. Gundogdu and A. A. Alatan, “Good features to correlate for visual tracking,” IEEE Trans. Image Process., vol. 27, no. 5, pp. 2526–2540, 2018. 2526–2540, 2018.
[145] Y. Xie, J. Xiao, K. Huang, J. Thiyagalingam, and Y. Zhao, “Correlation filter selection for visual tracking using reinforcement learning,” IEEE Trans. Circuits Syst. Video Technol., 2018.
[146] J. Gao, T. Zhang, X. Yang, and C. Xu, “P2T: Part-to-target tracking via deep regression learning,” IEEE Trans. Image Process., vol. 27, no. 6, pp. 3074–3086, 2018.
[147] C. Peng, F. Liu, J. Yang, and N. Kasabov, “Densely connected discriminative correlation filters for visual tracking,” IEEE Signal Process. Lett., vol. 25, no. 7, pp. 1019–1023, 2018.
[148] D. Li, G. Wen, Y. Kuai, and F. Porikli, “End-to-end featureintegration for correlation filter tracking with channel attention,” IEEE Signal Process. Lett., vol. 25, no. 12, pp. 1815–1819, 2018.
[149] C. Ma, J. B. Huang, X. Yang, and M. H. Yang, “Adaptive corre-lation filters with long-term and short-term memory for object tracking,” IJCV, vol. 126, no. 8, pp. 771–796, 2018.
tracking,” IJCV, vol. 126, no. 8, pp. 771–796, 2018.
[150] Y. Cao, H. Ji, W. Zhang, and F. Xue, “Learning spatio-temporal context via hierarchical features for visual tracking,” Signal Proc.: Image Comm., vol. 66, pp. 50–65, 2018.
[151] F. Du, P. Liu, W. Zhao, and X. Tang, “Spatialtemporal adaptive feature weighted correlation filter for visual tracking,” Signal Proc.: Image Comm., vol. 67, pp. 58–70, 2018.
Proc.: Image Comm., vol. 67, pp. 58–70, 2018.
[152] Y. Kuai, G. Wen, and D. Li, “When correlation filters meet fully-convolutional Siamese networks for distractor-aware tracking,” Signal Proc.: Image Comm., vol. 64, pp. 107–117, 2018.
[153] W. Gan, M. S. Lee, C. hao Wu, and C. C. Kuo, “Online object tracking via motion-guided convolutional neural network (MGNet),” J. VIS. COMMUN. IMAGE R., vol. 53, pp. 180–191, 2018.
[154] M. Liu, C. B. Jin, B. Yang, X. Cui, and H. Kim, “Occlusion-robust object tracking based on the confidence of online selected hierarchical features,” IET Image Proc., vol. 12, no. 11, pp. 2023–2029, 2018.
[155] K. Dai, D. Wang, H. Lu, C. Sun, and J. Li, “Visual tracking via adaptive spatially-regularized correlation filters,” in Proc. CVPR, 2019, pp. 4670–4679.
[156] M. Danelljan, G. Bhat, F. S. Khan, and M. Felsberg, “ATOM: Accurate tracking by overlap maximization,” 2018. [Online]. Available: http://arxiv.org/abs/1811.07628
[157] H. Fan and H. Ling, “Siamese cascaded region proposal networks for real-time visual tracking,” 2018. [Online]. Available: http://arxiv.org/abs/1812.06148
[158] J. Gao, T. Zhang, and C. Xu, “Graph convolutional tracking,” in
Proc. CVPR, 2019, pp. 4649–4659.
[159] Y. Sun, C. Sun, D. Wang, Y. He, and H. Lu, “ROI pooled corre-lation filters for visual tracking,” in Proc. CVPR, 2019, pp. 5783–5791.
[160] G. Wang, C. Luo, Z. Xiong, and W. Zeng, “Spm-tracker: Series-parallel matching for real-time visual object tracking,” 2019. [Online]. Available: http://arxiv.org/abs/1904.04452
[161] X. Li, C. Ma, B. Wu, Z. He, and M.-H. Yang, “Target-aware deep tracking,” 2019. [Online]. Available: http://arxiv.org/abs/1904. 01772 “Unsupervised deep tracking,” 2019. [Online]. Available: http://arxiv.org/abs/1904.01828
[163] G. Bhat, M. Danelljan, L. V. Gool, and R. Timofte, “Learning discriminative model prediction for tracking,” 2019. [Online]. Available: http://arxiv.org/abs/1904.07220
[164] F. Zhao, J. Wang, Y. Wu, and M. Tang, “Adversarial deep tracking,” IEEE Trans. Circuits Syst. Video Technol., vol. 29, no. 7, pp. 1998–2011, 2019.
[165] H. Li, X. Wang, F. Shen, Y. Li, F. Porikli, and M. Wang, “Real-time deep tracking via corrective domain adaptation,” IEEE Trans. Circuits Syst. Video Technol., vol. 8215, 2019.
[166] B. Zhong, B. Bai, J. Li, Y. Zhang, and Y. Fu, “Hierarchical tracking by reinforcement learning-based searching and coarse-to-fine verifying,” IEEE Trans. Image Process., vol. 28, no. 5, pp. 2331–2341, 2019.
[167] J. Gao, T. Zhang, and C. Xu, “SMART: Joint sampling and regression for visual tracking,” IEEE Trans. Image Process., vol. 28, no. 8, pp. 3923–3935, 2019.
[168] H. Hu, B. Ma, J. Shen, H. Sun, L. Shao, and F. Porikli, “Robust object tracking using manifold regularized convolutional neural networks,” IEEE Trans. Multimedia, vol. 21, no. 2, pp. 510–521, 2019.
networks,” IEEE Trans. Multimedia, vol. 21, no. 2, pp. 510–521, 2019.
[169] L. Wang, L. Zhang, J. Wang, and Z. Yi, “Memory mechanisms for discriminative visual tracking algorithms with deep neural networks,” IEEE Trans. Cogn. Devel. Syst., 2019.
[170] Y. Kuai, G. Wen, and D. Li, “Multi-task hierarchical feature learning for real-time visual tracking,” IEEE Sensors J., vol. 19, no. 5, pp. 1961–1968, 2019.
[171] X. Cheng, Y. Zhang, L. Zhou, and Y. Zheng, “Visual tracking via Auto-Encoder pair correlation filter,” IEEE Trans. Ind. Electron., 2019.
[172] F. Tang, X. Lu, X. Zhang, S. Hu, and H. Zhang, “Deep feature tracking based on interactive multiple model,” Neurocomputing, vol. 333, pp. 29–40, 2019.
vol. 333, pp. 29–40, 2019.
[173] X. Lu, B. Ni, C. Ma, and X. Yang, “Learning transform-aware attentive network for object tracking,” Neurocomputing, vol. 349,pp. 133–144, 2019.
pp. 133–144, 2019.
[174] D. Li, G. Wen, Y. Kuai, J. Xiao, and F. Porikli, “Learning target-aware correlation filters for visual tracking,” J. VIS. COMMUN.IMAGE R., vol. 58, pp. 149–159, 2019.
[175] B. Chen, P. Li, C. Sun, D. Wang, G. Yang, and H. Lu, “Multiattention module for visual tracking,” Pattern Recognit., vol. 87,pp. 80–93, 2019.
[176] S. Yun, J. J. Y. Choi, Y. Yoo, K. Yun, and J. J. Y. Choi, “Action-decision networks for visual tracking with deep reinforcement learning,” in Proc. IEEE CVPR, 2016, pp. 2–6.
[177] S. Yun, J. Choi, Y. Yoo, K. Yun, and J. Y. Choi, “Action-driven visual object tracking with deep reinforcement learning,” IEEE Trans. Neural Netw. Learn. Syst., vol. 29, no. 6, pp. 2239–2252, 2018.
[178] W. Zhang, K. Song, X. Rong, and Y. Li, “Coarse-to-fine UAV target tracking with deep reinforcement learning,” IEEE Trans. Autom. Sci. Eng., pp. 1–9, 2018.
[179] L. Ren, X. Yuan, J. Lu, M. Yang, and J. Zhou, “Deep reinforcement learning with iterative shift for visual tracking,” in Proc. ECCV, 2018, pp. 697–713.
[180] D. Zhang, H. Maei, X. Wang, and Y.-F. Wang, “Deep reinforcement learning for visual object tracking in videos,” 2017. [Online]. Available: http://arxiv.org/abs/1701.08936 ,[181] C. Huang, S. Lucey, and D. Ramanan, “Learning policies for adaptive tracking with deep feature cascades,” in Proc. IEEE ICCV, 2017, pp. 105–114.
[182] X. Dong, J. Shen, W. Wang, Y. Liu, L. Shao, and F. Porikli, “Hy-perparameter optimization for tracking with continuous deep Q- learning,” in Proc. IEEE CVPR, 2018, pp. 518–527.
[183] J. Supancic and D. Ramanan, “Tracking as online decision-making: Learning a policy from streaming videos with reinforce-ment learning,” in Proc. IEEE ICCV, 2017, pp. 322–331.
[184] J. Choi, J. Kwon, and K. M. Lee, “Real-time visual tracking by deep reinforced decision making,” Comput. Vis. Image Und., vol.171, pp. 10–19, 2018.
[185] Y. Wu, J. Lim, and M. H. Yang, “Online object tracking: A benchmark,” in Proc. IEEE CVPR, 2013, pp. 2411–2418.
[186] Y. Wu, J. Lim, and M. Yang, “Object tracking benchmark,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 9, pp. 1834–1848, 2015.
[187] P. Liang, E. Blasch, and H. Ling, “Encoding color information for visual tracking: Algorithms and benchmark,” IEEE Trans. Image Process., vol. 24, no. 12, pp. 5630–5644, 2015.
[188] M. Mueller, N. Smith, and B. Ghanem, “A benchmark and simulator for UAV tracking,” in Proc. ECCV, 2016, pp. 445–461.
[189] A. Li, M. Lin, Y. Wu, M. H. Yang, and S. Yan, “NUS-PRO: A new visual tracking challenge,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 2, pp. 335–349, 2016.
[190] H. K. Galoogahi, A. Fagg, C. Huang, D. Ramanan, and S. Lucey, “Need for speed: A benchmark for higher frame rate object tracking,” in Proc. IEEE ICCV, 2017, pp. 1134–1143.
“Need for speed: A benchmark for higher frame rate object tracking,” in Proc. IEEE ICCV, 2017, pp. 1134–1143.
[191] S. Li and D. Y. Yeung, “Visual object tracking for unmanned aerial vehicles: A benchmark and new motion models,” in Proc. AAAI, 2017, pp. 4140–4146.
[192] M. Müller, A. Bibi, S. Giancola, S. Alsubaihi, and B. Ghanem, “TrackingNet: A large-scale dataset and benchmark for object tracking in the wild,” in Proc. ECCV, 2018, pp. 310–327.
[193] J. Valmadre, L. Bertinetto, J. F. Henriques, R. Tao, A. Vedaldi, A. W. Smeulders, P. H. Torr, and E. Gavves, “Long-term tracking in the wild: A benchmark,” in Proc. ECCV, vol. 11207 LNCS, 2018,pp. 692–707.
pp. 692–707.
[194] A. Li, Z. Chen, and Y. Wang, “BUAA-PRO: A tracking dataset with pixel-level annotation,” in Proc. BMVC, 2018. [Online]. Available: http://bmvc2018.org/contents/papers/0851.pdf
[195] L. Huang, X. Zhao, and K. Huang, “GOT-10k: A large high-diversity benchmark for generic object tracking in the wild,”2018. [Online]. Available: http://arxiv.org/abs/1810.11981
[196] H. Fan, L. Lin, F. Yang, P. Chu, G. Deng, S. Yu, H. Bai,Y. Xu, C. Liao, and H. Ling, “LaSOT: A high-quality benchmarkfor large-scale single object tracking,” 2018. [Online]. Available:http://arxiv.org/abs/1809.07845
[197] L.ˇCehovin, “TraX: The visual tracking exchange protocol and library,” Neurocomputing, vol. 260, pp. 5–8, 2017.
[198] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, and A. C. Berg, “SSD: Single shot multibox detector,” in Proc. ECCV, 2016, pp. 21–37.
[199] G. Koch, R. Zemel, and R. Salakhutdinov, “Siamese neural networks for one-shot image recognition,” in Proc. ICML Deep Learning Workshop, 2015.
[200] G. Lin, A. Milan, C. Shen, and I. Reid, “RefineNet: Multi-path refinement networks for high-resolution semantic segmentation,”in Proc. IEEE CVPR, 2017, pp. 5168–5177.
[201] T. Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proc. IEEE CVPR, 2017, pp. 936–944.[202] S. Gladh, M. Danelljan, F. S. Khan, and M. Felsberg, “Deep motion features for visual tracking,” in Proc. ICPR, 2016, pp.1243–1248.
[203] E. Real, J. Shlens, S. Mazzocchi, X. Pan, and V. Vanhoucke,“YouTube-BoundingBoxes: A large high-precision human-annotated data set for object detection in video,” in Proc. IEEE CVPR, 2017, pp. 7464–7473.
[204] G. A. Miller, “WordNet: A lexical database for English,” Communications of the ACM, vol. 38, no. 11, pp. 39–41, 1995.
[205] A. Vedaldi and K. Lenc, “MatConvNet: Convolutional neural networks for MATLAB,” in Proc. ACM Multimedia Conference,2015, pp. 689–692.
[206] M. Kristan, J. Matas, A. Leonardis, T. Vojir, R. Pflugfelder, G. Fernandez, G. Nebehay, F. Porikli, and L. Cehovin, “A novel performance evaluation methodology for single-target trackers,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 11, pp. 2137–2155, 2016.
[207] L. Cehovin, M. Kristan, and A. Leonardis, “Is my new tracker really better than yours?” in Proc. IEEE WACV, 2014, pp. 540–