分布式数据库HBase
HBase简介
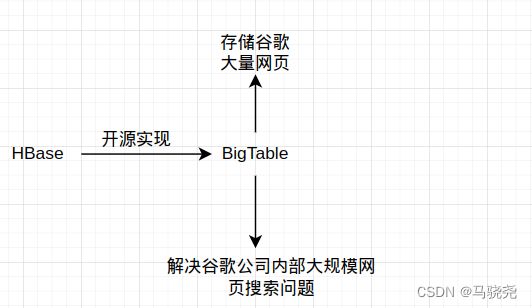
HBase是BigTable的一个开源实现,而BigTable的出现是为了解决谷歌公司内部大规模网页搜索的问题。
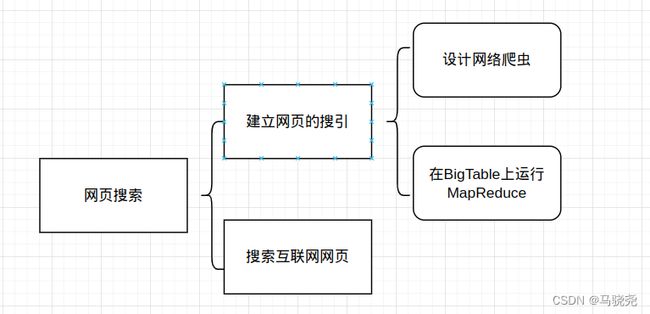
页面的搜索阶段:
1先建立整个网页的搜引,然后设计网页的爬虫,不断爬取数据,将爬好的数据保持到BigTable中,在BigTable上运行MapReduce生成网页的搜引,方便我们访问
2.用户通过搜索引擎发生请求,通过网页搜引访问相关网页
3. BigTable的诞生:
·主要用于满足互联网搜索引擎的基本需求
·用于网页搜索
·用于谷歌的项目
·用于视频,社交,博客网站等
分布式存储系统BigTable不是把底层磁盘做为存储,而是架构在谷歌分布式文件系统GFS上,通过GFS存储相关数据,通过Chubby实行协同管理服务
| BigTable | HBase | |
| 文件存储系统 | GFS | HDFS |
| 海量数据处理 | MapReduce | Hadoop MapReduce |
| 协同管理服务 | Chubby | Zookeeper |
HBase产品出现的原因:
·Hadoop无法满足大数据实时处理需求,传统关系型数据库的扩展能力非常有限
·HBase的分层操作全都基于机器操作,便利效率高
HBase数据模型
HBase是一个稀疏的多维度的排序的映射表
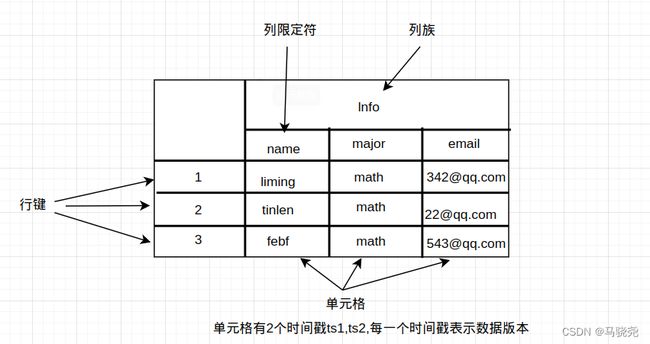
单元格:具体存储数据的地方
时间戳:数据更新后通过时间戳来区分
数据坐标:数据查找

行式数据库和列式数据库:
| 1111111111111111111 | 1111111111111111111 |
| 2222222222222222 | 2222222222222222 |
| 333333333333333333 | 3333333333333333 |
数据存储按行从左到右存储数据,数据压缩率低,试用于事务型操作
列式数据库
11111111 22222222 33333333 11111111 222222222 333333333
列式存储,按一个列去存储,可以带来很高的书局压缩率 ,多用于分析型
HBase的实现原理
1.HBase 的功能组件:
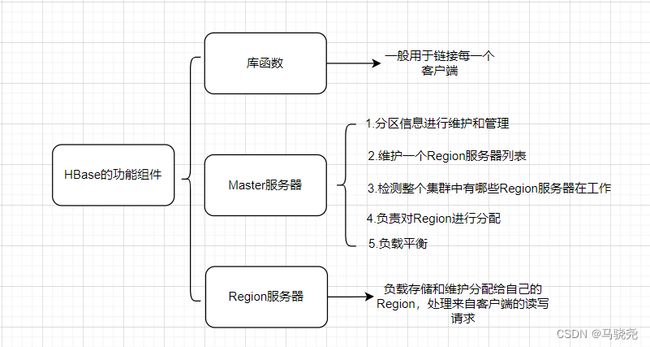
客户端并不是直接从Master服务器上读取数据,而是在获得Region在存储位置信息后,直接从Region服务器是读取。HBase客户端并不依赖于Master而是借助于Zookeeper来获得Region的位置信息。
2.两个核心概念表和Region:在一个HBase中,存储了许多表,表的行非常大,需要分布式存储到多台机器上。根据行键的值对表的行进行分区,每一个分区构成一个Region,Region包含了位于某个值域区间的所有数据,这些Region会被分发到不同的Region服务器上
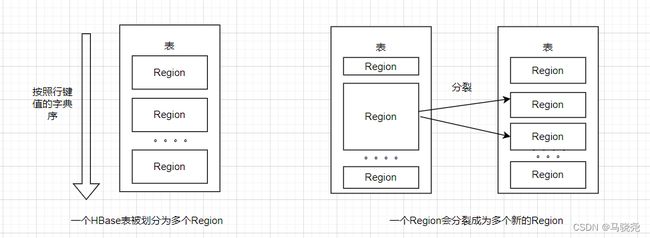
初始时,每个表只包含一个Region,随着数据的不断插入,Region会持续扩大,当大到一定的阈值就会自动等分成两个新的Region。每个Region的默认大小为100~200MB,不同的Region会被分配到不同的Region服务器上,当同一个Region不会被拆分到多个Region服务器上,每一个Region服务器负责管理一个Region集合,通常在每个Region服务器上会放置10~1000个Region
3.实现Region定位:HBase采用B+树的三层结构来保存Region位置信息。每一个Region都有一个RegionID来标识它的唯一性,一个Region标识符都可以表示为:表明+开始主键+RegionID。
有了Region标识符,通过一张包含Region标识符和Region两项内容的映射表就可以知道Region被保存在哪个Region服务器中,这个映射表称为元数据表,又称.META.表
.META.的数目会很多,通过一个映射表来访问多个.META.表,这个新的映射表称之为根数据表,又名-ROOT-表,-ROOT-不可再分,只有一个
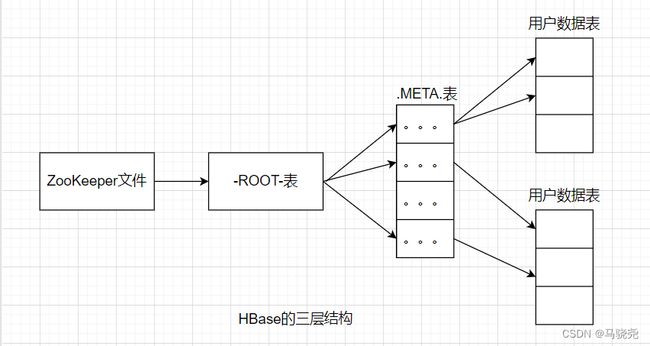
| 层次 | 名称 | 作用 |
| 第一层次 | ZooKeeper文件 | 记录了-ROOT-表的位置信息 |
| 第二层次 | -ROOT-表 | 记录了.MEAT.表的信息,通过-ROOT-可以访问到.MEAT.表的数据 |
| 第三层次 | .META.表 | 记录了用户数据表的Region的位置信息 |
客户端访问数据前,先访问ZooKeeper获取-ROOT-表的位置信息,然后访问-ROOT-表,获得.META.表的信息,接着访问.META.表,找到Region在哪个Region服务器上,最后到该Region服务器是读取数据
HBase运行机制
HBase运行机制包括HBase系统架以及Region服务器,Store和Hlog的工作原理
一.HBase系统架构:包括客户端,ZooKeeper服务器,Master主服务器,Region服务器。HBase一般采用HDFS作为底层数据存储系统
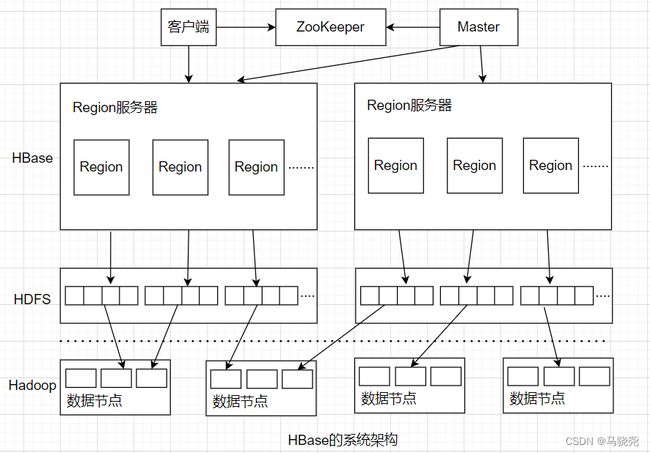
1.客户端:客户端包括访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程
2.ZooKeeper服务器:(1)ZooKeeper服务器可以监控每一个Region服务器的状态并通知Master,这样Master就可以通过ZooKeeper感知各个Region的运行状态
(2)ZooKeeper服务器可以帮助选举出一个Master做为集群的总管
(3)ZooKeeper服务器中保持了-ROOT-表的地址和Master主服务器的地址,客户端可以通过访问ZooKeeper获得-ROOT-表的地址,从而找到所需的数据
3.Master主服务器:主要负责表和Region的管理工作
·管理用户对表的增加,删除,修改,查询等操作
·实现不同Region服务器之间的负载均衡
·在Region分裂或合并后,负责重新调整Region的分布
·对发生故障失效的Region服务器上的Region进行迁移
4.Region服务器:负责维护分配给自己的Region并响应用户的读写请求
Region服务器的工作原理
Region服务器内部管理了一系列Region对象和一个HLog文件,HLog记录所有的更新操作;每一个Region对象由多个Store组成,每一个Store又包含一个MemStore和若干个StoreFile,其中MemStore是在内存中的缓存,保存最近更新的数据,StoreFile是磁盘中的文件
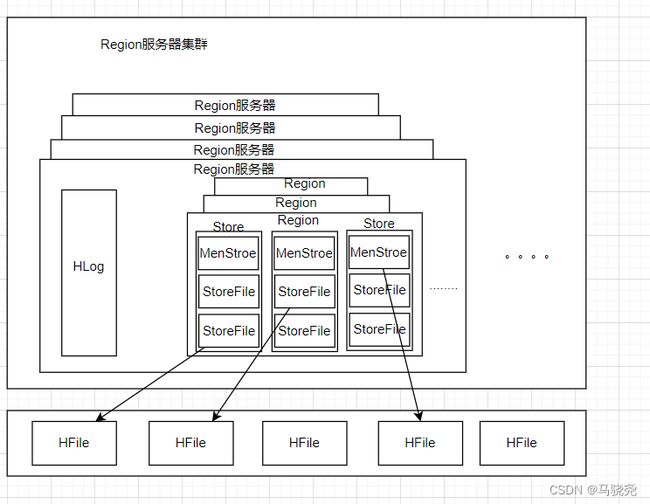
1.用户读写数据的过程:用户写数据时,会被分配到相应的Region服务器去执行,数据会被写入到MenStore和HLog;用户读取数据时,Region服务器首先访问menStore缓存,如果数据不在缓存中,才会到磁盘上面的StoreFile中寻找
2.缓存的刷新:MenStore的缓存容量有限,系统会周期性的调用Region.flushcache()把MenStore缓存里面的内容写到磁盘的StoreFile中,清空缓存,并在HLog文件中写入标记,用来表示缓存中的内容以及被写入StoreFile文件中
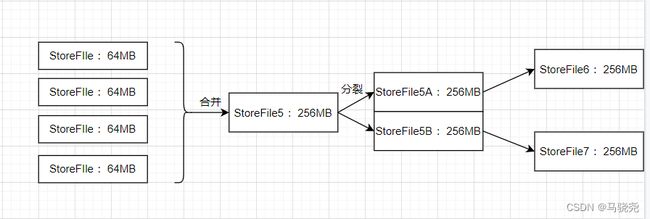
3.StoreFile的合并:系统调用Store.compatc()把多个StoreFile文件合并成一个大文件
Store的工作原理
Store是Region的服务器的核心,每个Store对应了表中的一个一列族的存储,包含一个MemStore缓存和若干个StoreFile文件。MemStore是排序的内存缓冲区,当用户写入数据时,系统首先把数据放入MenStore缓存,当MenStore缓存满时,就会刷新到磁盘中一个StoreFile文件中,随着StoreFile文件数量不断增加,多个StoreFile文件会合并成一个大的StoreFile文件,当一个StoreFile文件大小超过一定阈值时,就会触发文件分裂操作,当前的父Region会分裂成两个子Region,父Region会下线,而子Region会被分配到相应的Region服务器上
Hlog工作原理
考虑到MemStore的数据会因为服务器故障而丢失,HBase采用Hlog来保证系统发生故障时能够恢复到正确的状态,HBase为每一个Region服务器分配了一个Hlog文件,它是一种预写式日志,用户更新数据时首先记入日志才能写入MemStore缓存,并且直到Memstore缓存内容对应的日志已经被写入磁盘之后,该缓存内容才会被刷新写入磁盘