【自然语言处理】【多模态】Product1M:基于跨模态预训练的弱监督实例级产品检索
论文地址:https://arxiv.org/pdf/2107.14572.pdf
相关博客:
【自然语言处理】【多模态】多模态综述:视觉语言预训练模型
【自然语言处理】【多模态】CLIP:从自然语言监督中学习可迁移视觉模型
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型
【自然语言处理】【多模态】BLIP:面向统一视觉语言理解和生成的自举语言图像预训练
【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
【自然语言处理】【多模态】UniT:基于统一Transformer的多模态多任务学习
【自然语言处理】【多模态】Product1M:基于跨模态预训练的弱监督实例级产品检索
【自然语言处理】【多模态】ALBEF:基于动量蒸馏的视觉语言表示学习
【自然语言处理】【多模态】VinVL:回顾视觉语言模型中的视觉表示
【自然语言处理】【多模态】OFA:通过简单的sequence-to-sequence学习框架统一架构、任务和模态
【自然语言处理】【多模态】Zero&R2D2:大规模中文跨模态基准和视觉语言框架
一、简介

在过去的二十年里,见证了电子商务中商品种类的极大丰富和线上客户需求多样化。一方面,网上商品的种类越来越多样,并且其中的大部分被作为产品组合进行展示,即在一个图像中有多个不同产品的实例。另一方面,线上的客户或者商家可能需要从商品组合中检索单个产品,方便价格比较和在线商品推荐。此外,多媒体产生的异构数据在不断的加速积累,一个算法如何处理大规模且弱标注数据来执行多模态检索仍然是个问题。
在本文中,作者探索了一个现实问题:给定大规模弱标注多模态数据,如何执行实例级细粒度产品检索? 作者在上图中比较了不同的范式。可以看出,图像级的检索倾向于返回简单的结果,因为其不能区分不同的实例,而多模态实例级检索更加有利于检索多模态数据中的各类检索。尽管一个问题具有普遍性和实用价值,但是由于缺乏真实世界数据集和清晰的问题定义,该问题没有被很好的研究。在产品检索的文献中,单模态和跨模态检索将单模态信息作为输入,例如一个图像或者一个文本片段。不幸的是,在query和target中都包含多模态信息的场景中,这样的检索方案极大的限制了使用。更为重要的是,先前的工作专注在相对检索的例子上,即单产品图像的图像级检索,并且检索的实例级本质没有被探索。
为了填补这一空白并推进相关的研究,作者收集了大规模数据集 Product1M \text{Product1M} Product1M,用于进行多模态实例级检索。 Product1M \text{Product1M} Product1M包含一百万个image-caption对并且由两种类型的样本组成,即单产品样本和多产品样本。每个单产品都属于细粒度类别,并且类别间差异非常微小。多产品样本非常的多样,这将导致复杂的合并以及模糊的对应关系,这很好的模拟了现实世界的场景。 Product1M \text{Product1M} Product1M是最大的多模态数据集之一,并且是第一个专门为真实世界多模态实例级检索场景定制的数据集。
除了构造数据集,我们也提出了一个新颖的自监督训练框架来从大规模弱监督标注数据集上抽取实例级特征表示。具体来说,作者通过一个简单有效的数据增强方法获得的伪标签训练一个多产品检测器。然后,提出的模型 CAPTRUE \text{CAPTRUE} CAPTRUE通过几个预训练任务来捕获图像和文本的潜在协同关系。作者发现,由于网络结构设计的缺陷或者不恰当的预训练任务,一些流行的跨模态预训练方法可能在多实例场景中存在着缺陷。相反, CAPTURE \text{CAPTURE} CAPTURE利用混合流架构来分别编码不同模态的数据并以统一的方式融合它们,并且通过实验证明了这种方式对提出任务的有效性。此外,作者还提出了跨模态对比损失来强制 CAPTURE \text{CAPTURE} CAPTURE完成图像和文本的对齐,避免了不合适预训练任务的错误匹配问题。
至关重要的是, CAPTURE \text{CAPTURE} CAPTURE在所有主要指标上都大幅度的超越了跨模特 SOTA \text{SOTA} SOTA基准模型。此外,大量的消融实验证明了 CAPTURE \text{CAPTURE} CAPTURE的泛化能力,并探索了提出任务的几个重要因子。希望提出的 Product1M \text{Product1M} Product1M和 CAPTURE \text{CAPTURE} CAPTURE以及基线能够促进线上场景检索的研究。
二、 Product1M \text{Product1M} Product1M中的实例级检索
1. 任务定义
一个产品样本 ( I , C ) (I,C) (I,C)是一个imgae-text对,其中 I I I是产品图像, C C C是产品的caption。给定一个单产品(single-product)样本集合 S = { S i ∣ S i = ( I S i , C S i ) } \mathcal{S}=\{\mathcal{S}_i|\mathcal{S}_i=(I_S^i,C_S^i)\} S={Si∣Si=(ISi,CSi)}和多产品(multi-product)样本集合 P = { P i ∣ P i = ( I P i , C P i ) } \mathcal{P}=\{\mathcal{P}_i|\mathcal{P}_i=(I_{\mathcal{P}}^i,C_{\mathcal{P}}^i)\} P={Pi∣Pi=(IPi,CPi)},任务是检索和排序在query样本 P i \mathcal{P}_i Pi中出现的单个产品,即预测一个列表
R E T R i = [ i d 1 i , i d 2 i , … , i d k i , … , i d N i ] ∀ P i ∈ P RET\;R^i=[id_1^i,id_2^i,\dots,id_k^i,\dots,id_N^i]\;\forall\mathcal{P}_i\in\mathcal{P} RETRi=[id1i,id2i,…,idki,…,idNi]∀Pi∈P
其中, i d k i id_k^i idki对应 S \mathcal{S} S中的具体单个产品。
2. 数据集统计
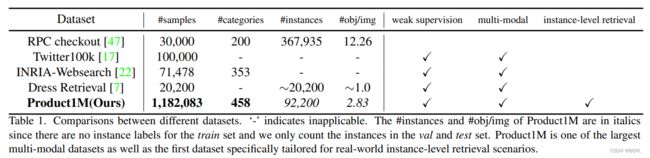
作者从电子商务网站上收集了49个品牌的产品样本。根据产品信息将这些image-text样本人工划分为单产品组和多产品组。 Product1M \text{Product1M} Product1M被划分为训练集、验证集、测试集和gallery集。训练集包含1132830个样本,这些样本包含单产品样本和多产品样本,而验证集和测试集仅包含多产品样本,分别包含2673和6547个样本。gallery集中包含458个类别的40033个单产品样本,验证集和测试集中包含了392个类别,其余的作为干扰项验证检索算法的鲁棒性。gallery集、验证集和测试集中的样本会使用类别标签进行标注用于评估,即它们不参与训练过程,训练集中的样本没有标注。 Product1M \text{Product1M} Product1M的统计信息如上表和上图所示。
3. 数据集特点
-
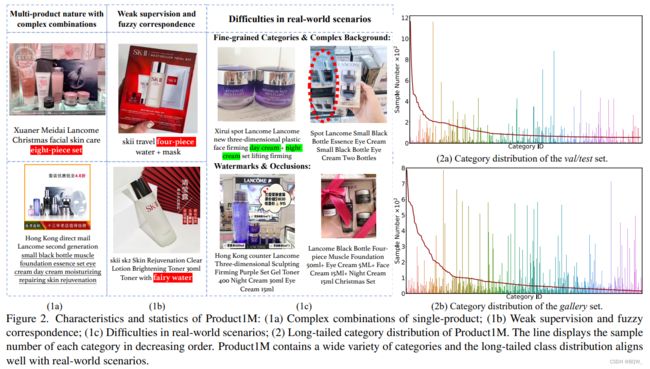
多产品的性质和复杂的组合
多产品图像在电商网站中无处不在,并且作为实例级产品检索的查询图像。如上图 (1a) \text{(1a)} (1a)描述,产品可以以丰富的形式和布局来进行组织,并实例的数量非常大。细粒度单产品样本的数量大、种类多,导致了不同组合图像的复杂性。
-
弱监督和模糊对应关系
这里考虑使用图像和文本两种常见的模态进行检索。不同于其他具有干净类别标签的数据集,来自商品
captions的监督信号比较弱且信息量少。上图 ( 1 b ) (1b) (1b)展示了具有挑战的不同类型样本。一些样本在其captions中包含几个产品的缩写。然而,像eight-piece set这样的缩写并没有包含任何产品的相关信息。第二种类型的样本会携带不相关的信息,在标题中描述的商品可能在图像中并没有出现,反之亦然。模糊对应关系在图片和标题间广泛存在,这使得实例级检索更具挑战。 -
与现实场景的一致性
在上图 ( 1 c ) (1c) (1c)中展示了一些有挑战的样本。他们复杂背景中具有不相关的物体,这些水印或者噪音覆盖了产品的信息。有些不同类型的产品几乎相同,除了包装上的文字略有不同,例如:
day cream和night cream。上图中 ( 2 a , 2 b ) (2a,2b) (2a,2b)展示了 Product1M \text{Product1M} Product1M中的长尾分布,非常符号现实场景。
三、方法

1. 训练 RPN \text{RPN} RPN来进行多产品检测
基于图像级特征进行检索将会导致检索结果被图像中主导的产品所控制。因此,从多产品图像中区分不同的产品并抽取相关特征至关重要。虽然有许多预训练的检测器可用,但是由于数据集分布的区别,导致其无法直接应用在多产品检测中。因此,作者利用了一个简单有效的数据增强方案来训练一个 RPN(Region Proposal Network) \text{RPN(Region Proposal Network)} RPN(Region Proposal Network)模型,其主要是基于上图 ( a ) (a) (a)中的单产品图像。这里首先会使用 GrabCut \text{GrabCut} GrabCut来获得单产品的前景蒙版。对于来自 Places365 \text{Places365} Places365中的背景图像,通过复制粘贴增强来应用前景蒙版和背景图像来生成合成图像。通过这种方法能够训练一个性能良好的多产品检测器。给定 RPN \text{RPN} RPN的检测区域,我们利用 RoIAlign \text{RoIAlign} RoIAlign来获取实例级特征,其会被输入至 CAPTURE \text{CAPTURE} CAPTURE中进行多模态学习。
2. CAPTURE \text{CAPTURE} CAPTURE的架构设计
在训练完 RPN \text{RPN} RPN后,能够为同一个图像中的不同产品生成高质量的特征。不同于目前流行的single-steam或者two-stream的 Transformer \text{Transformer} Transformer架构,作者提出了 CAPTURE \text{CAPTURE} CAPTURE,该模型通过堆叠三种不同类型的层将两种架构进行统一,用于语义对齐和多模态联合学习。细节如上图 ( b ) (b) (b)。具体来说,文本/视觉 Transformer \text{Transformer} Transformer会将文本或者图像的嵌入向量作为输入,并负责模态内的特征学习。文本/视觉交叉 Transformer \text{Transformer} Transformer则是捕获和建模文本和图像模态间的关系,通过多头注意力机制中交互键值对。随后,文本和图像特征会被拼接,并作为query,key,value输入至 Co-Transformer \text{Co-Transformer} Co-Transformer进行多模态联合学习。三种类型的 Transformer \text{Transformer} Transformer被堆叠 L L L, K K K和 H H H次。
3. 遮蔽多模态学习
对于多模态特征学习,采用两个遮蔽多模态建模任务,即 MLM(Masked Language Modeling) \text{MLM(Masked Language Modeling)} MLM(Masked Language Modeling)和 MRP(Masked Region Prediction) \text{MRP(Masked Region Prediction)} MRP(Masked Region Prediction),这两个任务分别来自于 BERT \text{BERT} BERT和 VisualBERT \text{VisualBERT} VisualBERT。具体来说,对于 MLM \text{MLM} MLM和 MRP \text{MRP} MRP,15%的输入被遮蔽并使用其余的输入来重构遮蔽的信息。 MLM \text{MLM} MLM的处理同 BERT \text{BERT} BERT。对于 MRP \text{MRP} MRP,模型直接对遮蔽的特征进行回归,其是通过用 RPN \text{RPN} RPN抽取的特征进行监督的。对于跨模态关系建模, Image-Text \text{Image-Text} Image-Text匹配任务 ITM \text{ITM} ITM在先前任务中广泛采用。通常,模型需要预测文本是否为图像的描述,其能被形式化为二分类任务。对于生成负样本,图像或者caption被随机替换。作者认为 ITM \text{ITM} ITM在实例级别的image-text样本上的细粒度理解存在问题。作者假设这种退化来自于替换后图像和文本的不匹配,其导致检测区域和文本不匹配。
4. 跨模态对比损失函数
除了模态内的特征学习, CAPTURE \text{CAPTURE} CAPTURE期望能够为多模态输入生成连贯的表示,并且学习他们之间的通信。为了这个目标,作者使用跨模态对比学习来达到图像和文本对齐。对于 N N N个image-text样本的minibatch,总共有 2 N 2N 2N个数据点。将对应的image-text对作为 N N N个正样本,其他 2(N-1) \text{2(N-1)} 2(N-1)不匹配的样本作为负样本对。正式来说,给定一个图像文本对 ( x i , x j ) (x_i,x_j) (xi,xj)并且他们的编码特征为 ( x ~ i , x ~ j ) (\tilde{x}_i,\tilde{x}_j) (x~i,x~j),对于这些正样本对的跨模态对比损失为:
L ( x i , x j ) = − log exp(sim ( x ~ i , x ~ j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] exp(sim ( x ~ i , x ~ k ) / τ ) (1) \mathcal{L}(x_i,x_j)=-\text{log}\;\frac{\text{exp(sim}(\tilde{x}_i,\tilde{x}_j)/\tau)}{\sum_{k=1}^{2N}\mathbb{1}_{[k\neq i]}\text{exp(sim}(\tilde{x}_i,\tilde{x}_k)/\tau)} \tag{1} L(xi,xj)=−log∑k=12N1[k=i]exp(sim(x~i,x~k)/τ)exp(sim(x~i,x~j)/τ)(1)
其中, sim ( u , v ) = u ⊤ v / ∥ u ∥ ∥ v ∥ \text{sim}(\textbf{u},\textbf{v})=\textbf{u}^\top\textbf{v}/\parallel\textbf{u}\parallel\parallel\textbf{v}\parallel sim(u,v)=u⊤v/∥u∥∥v∥用于计算 ( u , v ) (\textbf{u},\textbf{v}) (u,v)的cosine相似度; τ \tau τ表示temperature参数; 1 [ k ≠ i ] \mathbb{1}_{[k\neq i]} 1[k=i]是一个指示函数,如果 k ≠ i k\neq i k=i则返回1。这个形式的对比损失函数鼓励不同模型正样本对的编码特征相似,并使负样本对不相似。作者发现在文本/图像 Transformer \text{Transformer} Transformer中注入这种特征是有益的。
5. 实例级检索推理
对于单产品样本和多产品样本,从预训练 RPN \text{RPN} RPN中抽取的特征和captions被用于作为 CAPTURE \text{CAPTURE} CAPTURE的输入。在推断的过程中, Co-Transformer \text{Co-Transformer} Co-Transformer层输出 H I M G H_{IMG} HIMG和 H T X T H_{TXT} HTXT作为视觉和语言输入的整体表示。两个向量相乘得到实例的联合表示。此外,由于文本/图像 Transformer \text{Transformer} Transformer具有交叉模态对比损失函数的监督,作者发现将这一层的特征拼接起来进行检索是有益的。最终的特征会作为检索算法的输入。在计算一个实例与gallery集中样本的cosine相似矩阵后,可以通过每个query的最高相似度来检索对应的单产品样本。
四、实验
略