【论文总结】Incremental Few-Shot Object Detection(附翻译)
Incremental Few-Shot Object Detection 小样本增量目标检测
论文地址:https://arxiv.org/abs/2003.04668
代码暂未公开

思路:文章使用方法 Opened CenterNet(ONCE)以 CenterNet 单阶段检测方法为基础,加入一个元学习训练的类别编码生成模型来注册新类。新类样本只需要在 meta-training 阶段以前向传播方式注册,不需要复习基类或迭代更新。
Centernet:
特征提取网络使用Centernet: 该算法是一种class-specific的模型,能够很容易地采用插入式的方式引入新的类别。CenterNet 为每类预测中心热力图,不需要 proposal,使得物体定位与尺寸以预测相应像素级对齐的heatmap的方式进行,每类物体保持其预测的heatmap根据激活阈值独立检测,很适合本文增量检测要求。)centernet的预测结果会将输入进来的图片划分成不同区域,每个区域都会有一个特征点,centernet网络的预测结果就会判断这个特征是否有对应的物体,以及物体的种类和置信度,同时还会对特征点进行调整获得中心点坐标,还会回归预测获得物体的宽高。
Heatmap:每一个类别都有一张heatmap,每一张heatmap上,若某个坐标处有物体目标的中心点,即在该坐标处产生一个keypoint。
训练过程:
首先用特征提取器(蓝色)提取图像特征,然后将所提特征和类别编码一起送入到物体定位器(橘色和绿色)中,用卷积核分析,最后以heatmap方式输出每类检测结果。
①在基础数据集上,按照CentreNet的方式进行训练,获得特征提取网络的参数
②在小样本数据集上,采用元训练的方式,获取类编码生成器网络的参数
摘要
Most existing object detection methods rely on the availability of abundant labelled training samples per class and offline model training in a batch mode. These requirements substantially limit their scalability to open-ended accommodation of novel classes with limited labelled train-
ing data. We present a study aiming to go beyond these limitations by considering the Incremental Few-Shot Detection (iFSD) problem setting, where new classes must be registered incrementally (without revisiting base classes) and with few examples. To this end we propose OpeNended Centre nEt (ONCE), a detector designed for incre- mentally learning to detect novel class objects with few examples. This is achieved by an elegant adaptation of the CentreNet detector to the few-shot learning scenario, and meta-learning a class-specific code generator model for registering novel classes. ONCE fully respects the in- cremental learning paradigm, with novel class registration requiring only a single forward pass of few-shot training samples, and no access to base classes – thus making it suitable for deployment on embedded devices. Extensive experiments conducted on both the standard object detection and fashion landmark detection tasks show the feasibility of iFSD for the first time, opening an interesting and very important line of research.
大多数现有的目标检测方法都依赖于每类具有大量标记的训练样本的可用性以及批处理模式下的离线模型训练。这些要求在很大程度上限制了它们的可扩展性,使其无法适应具有有限训练数据的新类。我们提出了一项研究,旨在通过考虑增量小样本检测(iFSD)问题设置来超越这些限制,其中新类必须以增量方式标记(无需重新访问基类),并且示例很少。为此,我们提出了开放中心网络(ONCE),这是一种检测器,设计用于增量学习以检测新的类目标,只需很少的示例。这是通过将CentreNet检测器适配到小样本学习场景,以及元学习用于标注新类的特定于类的代码生成器模型来实现的。ONCE完全遵循增量学习范式,标注新类只需要一次向前传递few-shot训练样本,并且不需要访问基类,因此适合在嵌入式设备上部署。在标准目标检测和fashion landmark 检测任务上进行的大量实验首次证明了iFSD的可行性,开辟了一条有趣且非常重要的研究领域。
1 介绍
Despite the success of deep convolutional neural networks (CNNs) [21, 24, 45, 49] in object detection [43, 42, 30, 28], most existing models can be only trained offline via a lengthy process of many iterations in a batch setting. Under this setting, all the target classes are known, each class has a large number of annotated training samples, and all training images are used for training. This annotation cost and training complexity severely restricts the potential for these methods to grow and accommodate new classes online. Such a missing capability is required in robotics applications [32, 1], when the detector is running on embedded devices, or simply to scale up to addressing the long tail of object categories to recognise [31]. In contrast, humans learn new concepts such as object classes incrementally without forgetting previously learned knowledge [14], and often requiring only a few visual examples per class [36, 3]. Motivated by the vision of closing this gap between state-of-the-art object detection and human-level intelligence, a couple of very recent studies [53, 22] proposed methods for few-shot object detector learning.
尽管深卷积神经网络(CNN)[21,24,45,49]在目标检测[43,42,30,28]方面取得了成功,但大多数现有模型只能通过批量设置中多次迭代的漫长过程进行离线训练。在此设置下,所有目标类都是已知的,每个类都有大量带注释的训练样本,所有训练图像都用于训练。这种注释成本和训练复杂性严重限制了这些方法在线增长和适应新类的潜力。当检测器在嵌入式设备上运行时,机器人技术应用程序[32,1]需要这种缺失的功能,或者只是放大到处理要识别的目标类别[31]。相比之下,人类以增量方式学习新概念,如目标类,而不会忘记以前学习的知识[14],并且通常每个类只需要几个视觉示例[36,3]。出于弥合最先进的目标检测和人类智能之间差距的愿景,最近的几项研究[53,22]提出了小样本目标检测器学习方法。
Nonetheless, both methods [53, 22] are fundamentally unscalable to real-world deployments in open-ended or robotic learning settings, due to lacking the capability of incremental learning of novel concepts from a data stream over time. Specifically, they have to perform a costly training/updating of the detection model using the data of both old (base) and new (novel) classes together, whenever a novel class should be added. Consequently, while they successfully reduce annotation requirements, these models essentially reduce to the conventional batch learning paradigm. This leads to a prohibitively expensive quadratic computation cost in number of categories in an incremental scenario, and also raises issues in data privacy over time [9, 40]. Meanwhile, storage and compute requirements prohibit on-device deployment in robotic scenarios where a robot might want to incrementally register objects encountered in the world for future detection [32, 1].
尽管如此,这两种方法[53,22]在开放式或机器人学习环境中的实际部署中基本上无法扩展,因为缺乏从数据流中逐步学习新概念的能力。具体地说,每当需要添加新类时,他们必须同时使用旧类(基本类)和新类(新类)的数据对检测模型进行代价高昂的训练/更新。因此,虽然它们成功地减少了注释需求,但这些模型本质上简化为传统的批量学习范式。这导致在增量场景中,在类别数量上的二次计算成本高得令人望而却步,并且随着时间的推移,还会引发数据隐私问题[9,40]。同时,存储和计算要求禁止在机器人场景中进行设备部署,机器人可能希望遇到增量标注的目标,以备将来检测[32,1]。
To overcome the aforementioned limitation, we study a very practical learning setting – Incremental Few-Shot Detection (iFSD). The iFSD setting is defined by: (1) The detection model can be pre-trained in advance on a set of base classes each with abundant training samples available – it makes sense to use existing annotated datasets to bootstrap a model [32]. (2) Once trained, an iFSD model should be capable of deployment to real-world applications where novel classes can be registered at any time using only a few annotated examples. The model should provide good performance for all classes observed so far (i.e., learning without forgetting). (3) The learning of novel classes from an unbounded stream of examples should be feasible in terms of memory footprint, storage, and compute cost. Ideally the model should support deployment on resource-limited devices such as robots and smart phones.
为了克服上述限制,我们研究了一种非常实用的学习环境——增量小样本检测(iFSD)。iFSD设置的定义如下:(1)检测模型可以预先在一组基类上进行预训练,每个基类都有丰富的训练样本可用–使用现有带注释的数据集引导模型是有意义的[32]。 (2) 经过训练后,iFSD模型应该能够部署到现实世界中的应用程序中,在这些应用程序中,新类可以随时标注,只需使用几个实例注释示例。该模型应为迄今为止观察到的所有类别提供良好的性能(学习而不忘记)(3) 从无限的示例流中学习新类在内存占用、存储和计算成本方面应该是可行的。理想情况下,该模型应支持在资源有限的设备(如机器人和智能手机)上部署。
Conventional object detection methods are unsuited to the proposed setting due to the intrinsic need for batch learning on large datasets as discussed earlier. An obvious idea is to fine-tune the trained model with novel class trainingdata. However without revisiting old data(batchsetting) this causes a dramatic degradation in performance for existing categories due to the catastrophic forgetting challenge [14]. The state-of-the-art few-shot object detection methods [53, 22] suffer from the same problem too, if denied access to the base (old) class training data and adapted sequentially to novel classes (see the evaluations in Table 2).
传统的目标检测方法不适合建议的设置,因为如前所述,在大数据集上固有的批学习需求。一个明显的想法是使用新的类训练数据对训练模型进行微调。然而,如果不重新训练旧类别(batchsetting),由于灾难性遗忘,这会导致现有类别的性能急剧下降[14]。如果拒绝访问基本(旧)类训练数据并按顺序适应新类(见表2中的评估),最先进的小样本目标检测方法[53,22]也会遇到同样的问题。
In this work, as the first step towards the proposed incremental few-shot object detection problem in the context of deep neural networks, we introduce OpeN-ended Centre nEt (ONCE). The model is built upon the recently proposed CentreNet [56], which was originally designed for conventional batch learning of object detection. We take a feature-based knowledge transfer strategy, decomposing CentreNet into class-generic and class-specific components for enabling incremental few-shot learning. More specifically, ONCE uses the abundant base class training data to first train a class-generic feature extractor. This is followed by meta-learning a class-specific code generator with simulated few-shot learning tasks. Once trained, given a handful of images of a novel object class, the meta-trained class code generator elegantly enables the ONCE detector to incrementally learn the novel class in an efficient feed-forward manner during the meta-testing stage (novel class registration). This is achieved without requiring access to base class data or iterative updating. Compared with [22, 53], ONCE better fits the iFSD setting in that its performance is insensitive to the arrival order and choice of novel classes. This is due to not using softmax-based classification but per-class thresholding in decision making. Importantly, since each class-specific code is generated independent of other classes, ONCE is intrinsically able to maintain the detection performance of the base classes and any novel classes registered so far.
第一步,我们引入了开放式中心网络(ONCE)。该模型建立在最近提出的CentreNet[56]的基础上,该模型最初设计用于目标检测的常规批量学习。我们采用基于特征的知识转移策略,将CentreNet分解为类通用部分和类特定部分,以实现增量小样本学习。更具体地说,ONCE使用丰富的基类训练数据来首先训练类通用特征提取器。接下来是元学习,一个特定于类的代码生成器,带有模拟的小目标学习任务。经过训练后,给定一个新目标类的少量图像,元训练的类代码生成器使ONCE检测器能够在元测试阶段(新类标注)以有效的前馈方式递增地学习新类。这是在不需要访问基类数据或迭代更新的情况下实现的。与[22,53]相比,ONCE更适合iFSD设置,因为它的性能对到达顺序和新类的选择不敏感。这是因为在决策过程中不使用基于softmax的分类,而是使用每类阈值。重要的是,由于每个特定于类的代码是独立于其他类生成的,因此ONCE本质上能够保持基类和迄今为止标注的任何新类的检测性能。
We make three contributions in this work: (1) We investigate the heavily understudied Incremental Few-Shot Detection problem, which is crucial to many real-world applications. To the best of our knowledge, this is the first attempt to reduce the reliance of a deeply-learned object detector on batch training with large base class datasets during few-shot enrolment of novel classes, unlike recent few-shot detection alternatives [22, 53]. (2) We formulate a novel OpeN-ended Centre nEt (ONCE) by adapting the recent CentreNet detector to the incremental few-shot scenario. (3) We perform extensive experiments on both standard object detection (COCO [29], PASCAL VOC [12]) and fashion landmark detection (DeepFashion2 [15]) tasks. The results show ONCE’s significant performance advantage over existing alternatives.
我们在这项工作中做出了三点贡献:(1)我们研究了对许多实际应用至关重要的增量小样本检测问题。据我们所知,与最近的小目标检测替代方案不同[22,53],这是第一次尝试在新类的小样本标注期间减少深入学习的目标检测器对具有大型基类数据集的批量训练的依赖(2) 我们提出通过调整最近的CentreNet探测器以适应增量小目标场景OpeN-ended Centre nEt (ONCE) (3) 我们对标准目标检测(COCO[29],PASCAL VOC[12])和fashion landmark检测(DeepFashion2[15])任务进行了广泛的实验。结果表明,ONCE的性能明显优于现有备选方案。
2 相关工作
Object detection Existing deep object detection models fall generally into two categories: (1) Two-stage detectors [19, 18, 43, 20, 8], (2) One-stage detectors [30, 41, 42, 28, 56, 57, 25]. While usually being superior in detection performance, the two-stage methods are less efficient than the one-stage ones due to the need for object region inference (and subsequent classification from the set of object proposals). Typically, both approaches assume a large set of training images per class and need to train the detector in an offline batch mode. This restricts their usability and scalability when novel classes must be added on the fly during model deployment. Despite being non-incremental, they can serve as the detection backbone of a few-shot detector. Our ONCE method is based on the one-stage CentreNet [56] which is chosen because of its efficiency and competitive detection accuracy, as well as the fact that it can be easily decomposed into class-generic and specific parts for adaptation to the Incremental Few-Shot Detection problem.
目标检测 现有的深度物体检测模型一般分为两类:(1)两级检测器[19,18,43,20,8],(2)一级检测器[30,41,42,28,56,57,25]。虽然两阶段方法通常在检测性能上优于一阶段方法,但由于需要目标区域推断(以及从目标建议框集中进行后续分类),因此两阶段方法的效率低于一阶段方法。通常,这两种方法都假设每个类都有大量的训练图像,并且需要在离线批处理模式下训练检测器。当模型部署期间必须动态添加新类时,这限制了它们的可用性和可伸缩性。尽管它们是非增量的,但它们可以作为小样本检测器的检测主干。我们的ONCE方法基于单阶段CentreNet[56],之所以选择该方法,是因为它的效率和具有竞争力的检测精度,以及它可以很容易地分解为类通用和特定部分,以适应增量小样本检测问题。
Few-shot learning For image recognition, efficiently accommodating novel classes on the fly is widely studied under the name of few-shot learning (FSL) [51, 38, 34, 13, 46, 48, 5]. Assuming abundant labelled examples of a set of base classes, FSL methods aim to metalearn a data-efficient learning strategy that subsequently allows novel classes to be learned from very limited perclass examples. A large body of FSL work has investigated how to learn from such scarce data without overfitting [34, 44, 6, 26, 7, 17, 47, 55, 50, 27, 39, 11, 16]. Nonetheless, these FSL works usually focus on classification of whole images, or well cropped object images. This is much simpler than object detection as object instances do not need to be separated from diverse background clutter, or localised in space and scale. In this work we extend few-shot classification to the more challenging object detection task.
小样本学习用于图像识别,在实验中有效地适应新的类别,在小样本学习(FSL )[51,38,34,13,46,48,5]中被广泛研究。假设一组基类有大量的标记示例,FSL方法的目标是学习一种数据高效的学习策略,从而允许从非常有限的类示例中学习新类。FSL的大量工作已经调查了如何在不过度拟合的情况下从如此稀缺的数据中学习[34、44、6、26、7、17、47、55、50、27、39、11、16]。尽管如此,这些FSL工作通常侧重于对整个图像或裁剪良好的目标图像进行分类。这比目标检测简单得多,因为对象实例不需要从各种背景杂波中分离出来,也不需要在空间和尺度上定位。在这项工作中,我们将小样本分类扩展到更具挑战性的目标检测任务。
Few-shot object detection and beyond A few recent works have attempted to exploit few-shot learning techniques for object detection [53, 22, 23]. However, these differ significantly from ours in that they consider a nonincremental learning setting, which restricts dramatically their scalability and applicability in scenarios where access to either large-scale base class data is prohibitive. This is the case for example, due to limited computational resources and/or data privacy issues. We therefore consider the more practical incremental few-shot learning setting, eliminating the infeasible requirement of repeatedly training the model on the large-scale base class training data1. While this more challenging scenario inevitably lead to inferior performance compared to non-incremental learning, as shown in our experiments, it is more representative of natural human learning capabilities and thus provides a good research target with great application potential once solved.
小样本目标检测和最近的一些工作尝试利用小样本学习技术进行目标检测[53,22,23]。然而,这些差异与我们的显著不同,因为它们考虑了非增量学习设置,这在很大程度上限制了它们在大规模基础类数据的访问禁止的情况下的可扩展性和适用性。例如,由于有限的计算资源和/或数据隐私问题,情况就是如此。因此,我们认为更实用的增量小样本学习设置,消除了在大规模基类训练数据上反复训练模型的不可行需求。与非增量学习相比,这种更具挑战性的场景不可避免地会导致较差的性能,如我们的实验所示,它更能代表人类的自然学习能力,因此一旦解决,它将提供一个具有巨大应用潜力的良好研究目标。
There are other techniques that aim to minimise the amount of data labelling for object detection such as weakly supervised learning [4, 10] and zero-shot learning [58, 37, 2]. They assume different forms of training data and prior knowledge, and conceptually are complementary to our iFSD problem setting. They can thus be combined when there are multiple input sources available (e.g., unlabelled data or semantic class descriptor).
还有其他一些技术旨在最大限度地减少目标检测的数据标记量,如弱监督学习[4,10]和零样本学习[58,37,2]。他们假设不同形式的训练数据和先验知识,并且在概念上是对我们的iFSD问题设置的补充。因此,当存在多个可用的输入源(例如,未标记的数据或语义类描述符)时,它们可以组合在一起。
3 方法步骤
Problem Definition We consider the problem of Incremental Few-Shot Detection (iFSD): obtaining a learner able to incrementally recognise novel classes using only a few labelled examples per class. We consider two disjoint object class sets: the base classes used to bootstrap the system, which are assumed to come with abundant labelled data; and the novel classes which are sparsely annotated, and to be enrolled incrementally. That is, in a computationally efficient way, and without revisiting the base class data.
问题的定义 我们考虑的问题的增量小样本检测(IFSD):使学习者能够在每类上仅使用几个标记的示例来增加或识别新类。我们考虑两个不相交的目标类集合:用于引导系统的基类,它们假定带有丰富的标记数据;以及注释稀少的新类,这些类将以增量方式标注。也就是说,以一种计算效率高的方式,并且无需重新访问基类数据。
3.1. 目标检测体系结构
To successfully learn object detection from sparsely annotated novel classes, we wish to build upon an effective architecture, and exploit knowledge transfer from base classes already learned by this architecture. However, the selection of the base object detection architecture cannot be arbitrary given that we need to adapt the detection model to novel classes on-the-fly. For example, while Faster RCNN [43] is a common selection and provides strong performance given large scale annotation, it is less flexible to accommodate novel classes due to a two-stage design and the use of softmax-based classification.
为了成功地从稀疏注释的新类中学习目标检测,我们希望构建一个有效的体系结构,并利用该体系结构已经学习的基类的知识转移。然而,由于我们需要动态地使检测模型适应新的类,因此不能随意选择基本目标检测体系结构。例如,尽管 Faster RCNN [43]是一种常见选择,并在大规模注释的情况下提供了强大的性能,但由于两阶段设计和基于softmax的分类的使用,它在适应新类方面的灵活性较低。
In this work, we build upon the recently developed object detection model CentreNet [56] based on several considerations: (1) It is a highly-efficient one-stage object detection pipeline with better speed-accuracy trade-off than alternatives such as SSD [30], RetinaNet [28], and YOLO [41, 42]. (2) Importantly, it follows a class-specific modelling paradigm, which allows easy and efficient introduction of novel classes in a plug-in manner. Indeed, the core feature of CentreNet, the per-class heatmap-based centroid prediction is naturally appropriate for incremental learning as required in our setting
在这项工作中,我们基于以下几点考虑,基于最近开发的目标检测模型CentreNet[56]:(1) 它是一种高效的单级目标检测管道,与SSD[30]、RetinaNet[28]和YOLO[41,42]等替代方案相比,具有更好的速度-精度权衡。(2) 重要的是,它遵循一种特定于类的建模范式,允许以插件的方式轻松高效地引入新类。事实上,作为CentreNet的核心功能,基于每类热图的中心预测自然适合于我们环境中所需的增量学习。

Figure 1: Overview of Centre-Net. A backbone network, which can be implemented with resolution-reducing blocks followed by upsampling operations, generates feature maps (top). These feature maps are further processed by a small CNN (the object locator) and transformed into a set of per-class heatmaps encoding the object box centre points and its size (bottom). Centre-Net概览。主干网可以通过分辨率降低块和上采样操作来实现,生成特征图(顶部)。这些特征图由一个小型CNN(目标定位器)进一步处理,并转化为一组每类热图,编码目标框中心点及其大小(底部)。
3.1.1 A Review of the CentreNet Model
The key idea of CentreNet is to reformulate object detection as a point+attribute regression problem. It is inspired by keypoint detection methods [33, 52], taking a similar spirit to [25, 57] without the need for point grouping and postprocessing. The architecture of CentreNet is depicted in Fig. 1. Specifically, as the name suggests, CentreNet takes the centre point and the spatial size (i.e. the width & height) of an object bounding box as the regression target. Both are represented with 2D heatmaps, generated according to the ground-truth annotation. In training, the model is optimised to predict such heatmaps, supervised by an L1 regression loss. For model details, we refer the readers to the original paper due to space limit.
CentreNet的核心思想是将目标检测重新表述为一个点+属性回归问题。它受到关键点检测方法[33,52]的启发,采用了与[25,57]类似的原理,无需点分组和后处理。图1描述了CentreNet的体系结构。具体来说,顾名思义,CentreNet将目标边界框的中心点和空间大小(即宽度和高度)作为回归目标。两者都用二维热图表示,根据ground truth值注释生成。在训练中,通过L1回归损失对模型进行优化,以预测此类热图。关于模型的细节,由于篇幅的限制,我们建议读者阅读原稿。
Remarks It is worth mentioning that this keypoint estimation based formulation for object detection not only eliminates the need for region proposal generation, but also enables object location and size prediction in a common format by predicting corresponding pixel-wise aligned heatmaps. For few-shot object detection in particular, a key merit of CentreNet is that each individual class maintains its own prediction heatmap and makes independent detection by activation thresholding. We show next how to exploit this property of CentreNet in order to support incremental enrolment of novel classes in an order-free and combination-insensitive manner, without interference between old & new classes. This is in contrast to the softmax classification used in existing models [53, 22] where interactions between classes make this vision hard to achieve.
备注 值得一提的是,这种基于关键点估计的目标检测公式不仅消除了区域建议生成的需要,而且还通过预测相应的像素对齐热图,实现了通用格式的目标位置和大小预测。特别是对于小样本的目标检测,CentreNet的一个关键优点是每个单独的类保持其自己的预测热图,并通过激活阈值进行独立检测。接下来,我们将展示如何利用CentreNet的这一特性,以无顺序和组合不敏感的方式支持新类的增量标注,而不受新旧类之间的干扰。这与现有模型[53,22]中使用的softmax分类形成对比,在现有模型中,类之间的交互使得这一愿景难以实现。
3.2. 小目标增量检测
As CentreNet is a batch learning model, it is unsuited for iFSD. We address this problem by incorporating a metalearning strategy [51, 44] to CentreNet architecture, results in the proposed OpeN-ended Centre nEt (ONCE).
由于CentreNet是一种批处理学习模型,因此不适用于iFSD。我们通过将MetalLearning策略[51,44]纳入CentreNet体系结构来解决这个问题,从而提出了开放式中心网(ONCE)。
Model formulation ONCE starts by decomposing CentreNet into two components: (i) feature extractor, which is shared by all the base and novel classes, and (ii) object locator, which contains class-specific parameters for each individual class to be detected. Specifically, feature extractor takes as input an image, and outputs a 3D feature map. Then, the object locator analyses the feature map with a class-specific code used as convolutional kernel and yields the object detection result for that class in form of a heatmap.
模型公式化 首先将CentreNet分解为两个部分:(i)由所有基本类和新类共享的特征提取器(ii)目标定位器,其中包含每个待检测类的特定于类的参数。具体来说,特征提取器将图像作为输入,并输出三维特征图。然后,目标定位器使用特定于类的代码作为卷积核来分析特征映射,并以热图的形式生成该类的目标检测结果。
In a standard extractor/locator decomposition of CentreNet, the object locator still needs to be trained in batch mode, and with large scale training data. In ONCE, we further paramaterise the object locator by a meta-learned generator network, where the generator network synthesises the parameters of the locator network (i.e., the class specific convolutional kernel weights) given a few-shot support set. In this way, we transform the conventional batch-mode detector learning problem (second CNN in Fig. 1, indicated with the tag “object locator”) into a feed-forward pass of the parameter generator meta-network (class code generator in Fig. 2). To achieve this, we perform meta-learning to train the class code generator to solve few-shot detector learning tasks via weight synthesis given a support set (resulting in the green and orange class-specific object locators in Fig. 2).
在CentreNet的标准提取器/定位器分解中,目标定位器仍然需要以批处理模式进行训练,并使用大规模训练数据。在ONCE中,我们通过元学习生成器网络进一步参数化目标定位器,其中生成器网络在给定几个样本支持集的情况下合成定位器网络的参数(即特定于类的卷积核权重)。通过这种方式,我们将传统的批处理模式检测器学习问题(图1中的第二个CNN,用标记“目标定位器”表示)转换为参数生成器元网络(图2中的类代码生成器)的前馈过程。为了实现这一点,我们执行元学习来训练类代码生成器,以通过给定支持集的权重合成来解决小样本检测器学习任务(结果是图2中的绿色和橙色类特定目标定位器)。

Figure 2: The architecture of our OpeN-ended Centre nEt (ONCE) model. Specifically, the feature extractor (an encoder-decoder model in our implementation, coloured blue in the top-left) generates the class-generic feature maps f(I) of a test image. These maps are further convolved with the class-specific codes (coloured orange for the dog class, and green for the cat class) predicted by the class code generator (bottom-left, coloured yellow) from a few labelled support samples per class, to generate the object detection result in heatmap format (not shown for simplicity). The model training of ONCE involves two stages: (1) Stage I: a regular CentreNet-like supervised learning is performed on the abundant training data of base classes. (2) Stage II: episodic metatraining is performed with the weights of the feature extractor being frozen, allowing the class code generator to learn how to generate a class-specific code from a small per-class support set such that the model can generalise well to unseen novel classes (right). The base classes are used as fake novel classes in meta-training. It is noted that ONCE can also be applied for other detection problems, e.g., fashion landmark localisation. 开放式中心网络(ONCE)模型的架构。具体来说,特征提取器(在我们的实现中是一个编码器-解码器模型,左上角蓝色)生成测试图像的类通用特征映射f(I)。这些图片进一步与类别代码生成器(左下角黄色)根据每个类别的几个标记支持样本预测的类别特定代码(狗类为橙色,猫类为绿色)进行卷积,以生成热图格式的目标检测结果(为简单起见,未标出)。ONCE的模型训练分为两个阶段:(1)第一阶段:对丰富的基类训练数据进行规则的中心网式监督学习。(2) 第二阶段:在特征提取器的权重被冻结的情况下执行episodic metatraining,使类代码生成器学习如何从一个小的每类支持集生成特定于类的代码,以便模型能够很好地推广到看不见的新类(右)。在元训练中,基类被假设为新类。值得注意的是,ONCE还可以应用于其他检测问题,例如fashion landmark 定位。
Meta-Training: Learning a Few-Shot Detector To fully exploit the base classes with rich training data, we train ONCE in two sequential stages. In the first stage, we train the class-agnostic feature extractor on the base-class training data. This feature extractor is then fixed in subsequent steps as per other few-shot strategies [48]. In the second stage, we learn few-shot object-detection by jointly training the object locator, which is conditioned on a classspecific code; along with a meta-network that generates it given a support set. This is performed by episodic training that simulates few-shot episodes that will be encountered during deployment. In the following sections we describe the training process in more detail.
元训练:学习小样本检测器 为了充分利用具有丰富训练数据的基类,我们分两个连续阶段训练一次。在第一阶段,我们在基类训练数据上训练类无关特征提取器。然后,在后续步骤中,根据其他小样本策略固定此特征提取器[48]。在第二阶段,我们通过联合训练目标定位器来学习小样本目标检测,该定位器以特定于类的代码为条件;以及在给定支持集的情况下生成它的元网络。这是通过模拟部署期间将遇到的小样本的情景训练来执行的。在以下章节中,我们将更详细地描述训练过程。
Meta-Testing: Enrolling New Classes At test time, given a support set of novel classes each with a few labelled bounding boxes, we directly deploy the trained feature extractor, object locator, and code generator learned during meta-training above. The meta-network generates object-specific weights from the support-set (few-shot) and the object locator uses these to detect objects in the test images. This means that novel class objects are detected in test images in a feed forward manner, without model training and/or adaptation.
元测试:注册新类 在测都有几个标记的边界试时给定一组新类的支持集,每个新类框,我们直接部署在上面的元训练中学习的经过训练的特征提取器、目标定位器和代码生成器。元网络从支持集(小样本)生成特定于目标的权重, 定位器使用这些来检测测试图像中的对象。这意味着在测试图像中以前馈方式检测新类对象,而无需模型训练和/或自适应。
3.2.1 第一阶段:特征提取学习
We aim to learn a class-agnostic feature extractor f in ONCE. This can be simply realised by standard supervised learning with bound-box level supervision on the base classes, similarly to the original CentreNet [56]. Concretely, we perform keypoint detection and train the detection model (including both feature extractor f(·) and object locator h(·)) by heatmap regression loss. In this stage we train a complete feature extractor and object locator pipeline, although the objective of this stage is solely to learn a robust feature extractor f(·). The locator learned in this stage is a regular CentreNet locator, which will be discarded in stage II, but will be used at the test time for the base classes.
我们的目标是一次学习一个类无关的特征提取器f。这可以简单地通过标准的有监督学习来实现,在基类上使用目标框级别的监督,类似于原始的CentreNet[56]。具体来说,我们执行关键点检测,并通过热图回归损失训练检测模型(包括特征提取程序f(·)和目标定位程序h(·))。在这个阶段中,我们训练了一个完整的特征提取器和目标定位器管道,尽管这个阶段的目标仅仅是学习一个鲁棒的特征提取程序f(·)。在这个阶段学习的定位器是一个常规的CentreNet定位器,它将在第二阶段被丢弃,但将在测试基类时使用。
Given a training image I ∈![]() of height h and width w, we extract a class-agnostic feature map m = f(I),
of height h and width w, we extract a class-agnostic feature map m = f(I), ![]() . The object locator then detects objects of each class k by processing the feature map with a learned class convolutional kernel
. The object locator then detects objects of each class k by processing the feature map with a learned class convolutional kernel ![]() , where r is the output stride and c the number of feature channels. We then obtain the heatmap prediction
, where r is the output stride and c the number of feature channels. We then obtain the heatmap prediction ![]() for class k as:
for class k as:
给定一个训练图像 I ∈![]() 的高度h和宽度w,我们提取一个类不可知的特征映射m=f(I),
的高度h和宽度w,我们提取一个类不可知的特征映射m=f(I),![]() 。然后,目标定位器通过使用学习的类卷积核
。然后,目标定位器通过使用学习的类卷积核![]() 处理特征映射来检测每个类k的目标,其中r是输出步幅,c是特征通道数。然后,我们得到k类的热图预测,如下所示:
处理特征映射来检测每个类k的目标,其中r是输出步幅,c是特征通道数。然后,我们得到k类的热图预测,如下所示:

where ⊙ denotes the convolutional operation, and Kb denotes the number of base classes.
⊙ 表示卷积运算,Kb表示基类数。
For locating the object instances of class k, we start by identifying local peaks![]() , which are the points whose activation value is higher or equal to its 8-connected spatial neighbours in Yk. The bounding box prediction is inferred as:
, which are the points whose activation value is higher or equal to its 8-connected spatial neighbours in Yk. The bounding box prediction is inferred as:
为了定位k类的目标实例,我们首先确定局部峰值![]() ,即激活值高于或等于其在Yk中的8个连通空间相邻的点。边界框预测推断为:
,即激活值高于或等于其在Yk中的8个连通空间相邻的点。边界框预测推断为:

where ![]() is the offset prediction, O ∈
is the offset prediction, O ∈ ![]() , and
, and ![]() is the size prediction,
is the size prediction, ![]() , generated by the offset and size codes in the same fashion as the class codes. Given the ground-truth bounding boxes and this prediction, we use the L1 regression loss for model optimisation on the parameters of feature extractor f and parameters c of locator h. In practice, the feature extractor model is implemented with the ResNet-based backbone of [52].
, generated by the offset and size codes in the same fashion as the class codes. Given the ground-truth bounding boxes and this prediction, we use the L1 regression loss for model optimisation on the parameters of feature extractor f and parameters c of locator h. In practice, the feature extractor model is implemented with the ResNet-based backbone of [52].
其中![]() 是偏移预测,O∈
是偏移预测,O∈![]() 和
和![]() 是大小预测,
是大小预测,![]() 是由偏移量代码和尺寸代码以与类别代码相同的方式生成的。给定ground-truth边界框和该预测,我们使用L1回归损失对特征提取器f的参数和定位器h的参数c进行模型优化。实际上,特征提取器模型是使用基于ResNet的主干[52]实现的。
是由偏移量代码和尺寸代码以与类别代码相同的方式生成的。给定ground-truth边界框和该预测,我们使用L1回归损失对特征提取器f的参数和定位器h的参数c进行模型优化。实际上,特征提取器模型是使用基于ResNet的主干[52]实现的。
3.2.2 第二阶段:类别代码生成器学习
The class code parameters c learned for detection above are fixed parameters for base-classes only. To deal with the iFSD setting, besides these base-class codes we need an inductive class code generator g(·) that can efficiently synthesise class codes for novel classes on the fly during
deployment, given only a few labelled samples. To train the class code generator g(·), we exploit an episodic metalearning strategy [51]. This uses the base class data to sample a large number of few-shot tasks, thus simulating the test-time requirement of few-shot learning of new tasks. While episodic meta-learning is widely used in few-shot recognition, we customise a strategy for detection here.
上面为检测而学习的类代码参数c只是基类的固定参数。为了处理iFSD设置,除了这些基类代码之外,我们还需要一个归纳类代码生成器g(·),它可以在部署过程中有效地动态合成新类的类代码,只需提供少量标记样本。为了训练类代码生成器g(·),我们使用了一种episodic metalearning策略[51]。该方法利用基类数据对大量小样本任务进行采样,从而模拟新任务小样本学习的测试时间要求。虽然episodic metalearning广泛应用于小样本识别,但我们在此定制了一种检测策略。
Specifically, we define an iFSD task T as uniform distribution over possible class label sets L, each with one or a few unique classes. To form an episode to compute gradients and train the class code generator g(·), we start by sampling a class label set L from T (e.g., L ={person, bottle, · · · }). With L, we sample a support (metatraining) set S and a query (meta-validation) set Q. Both S and Q are labelled samples of the classes in L.
具体地说,我们将iFSD任务T定义为在可能的类标签集L上的均匀分布,每个类标签集L具有一个或几个唯一的类。为了形成一个episode来计算梯度并训练类代码生成器g(·),我们首先从T中采样一个类标签集L(例如,L={person,bottle,··})。使用L,我们对支持(元训练)集S和查询(元验证)集Q进行采样。S和Q都是L中类的标记样本。
In the forward pass, the support set S is used for generating a class code for each sampled class k as:
在前向传播中,支持集S用于为每个采样类k生成类代码,如下所示:![]()
where Sk are the support samples of class k. With these codes![]() , our method then performs object detection for query images I by using the feature extractor (Eq. (4)) and object locator (Eq.(5)):
, our method then performs object detection for query images I by using the feature extractor (Eq. (4)) and object locator (Eq.(5)):
其中Sk是k类的支持样本。使用这些代码![]() ,我们的方法然后使用特征提取器(等式(4))和目标定位器(等式(5))对查询图像I执行目标检测:
,我们的方法然后使用特征提取器(等式(4))和目标定位器(等式(5))对查询图像I执行目标检测:

ONCE is then trained to minimise the mean prediction error on Q by updating solely the parameters of the code generator (cf. Eq. (3)). Same as CentreNet, L1 loss is used as the objective function in this stage, defined as |Y˜ - Z| where Z is the ground-truth heatmap.
然后,通过仅更新代码生成器的参数(参见等式(3))对ONCE进行训练以最小化Q上的平均预测误差。与CentreNet相同,L1损失在此阶段被用作目标函数,定义为![]() ,其中Z是 ground-truth热图。
,其中Z是 ground-truth热图。
3.2.3 元测试:标注新类
Given the feature extractor (f, trained in Stage I), the code generator (g, trained in stage II), and the object locator (h, Eq. (1)), At test time, ONCE can efficiently enrol any new class with a few labelled samples in a feed forward manner without model adaptation and update.
在测试时,给定特征提取器(f,在阶段I中训练)、代码生成器(g,在阶段II中训练)和目标定位器(h,等式(1)),ONCE可以以前馈方式有效地注册具有少量标记样本的任何新类,而无需模型自适应和更新。
The meta-testing for a novel class is summarised as:一个新类的元测试总结如下:
1. Obtaining its class code with a few-shot labelled set using Eq. (3);
2. Computing the test image features by using Eq. (4);
3. Locating object instances of the novel class by Eq. (1);
4. Obtaining all the object candidates using Eq. (2);
5. Finding the heatmap local maxima to output the final detection result of that class.
1.使用公式(3)通过小样本标记集获得其类别代码;
2.使用公式(4)计算测试图像特征;
3.通过等式(1)定位新类的目标实例;
4.使用等式(2)获得所有候选目标;
5.查找热图局部最大值以输出该类的最终检测结果。
This process applies for the base classes except that Step 1 is no longer needed since their class codes are already obtained from the training stage I (cf. Eq. (1)). In doing so, we can easily introduce novel classes independently which facilitates the model iFSD deployment.
该过程适用于基类,但步骤1不再需要,因为它们的类代码已经从训练阶段I获得(参见等式(1))。通过这样做,我们可以轻松地独立地引入新类,这有助于模型iFSD的部署。
3.2.4 架构
For the feature extractor function f, we start from a strong and simple baseline architecture [52] that uses ResNet [21] as backbone. This architecture consists of an encoder-decoder pair that first extracts a low resolution 3D map and then expands it by means of learnable upsampling convolutions, outputting high resolution feature maps f(I) for an input image I. We leverage the same backbone for the class code generator (without the upsampling operations). Before meta-training (stage II), the class code generator weights are initialised by cloning the weights of the encoder part of the feature extractor. The final convolution outputs are globally pooled to form the class codes ck, giving a code size of ![]() . To handle support sets with variable size, we adopt the invariant set representation of [54] by average pooling of the class code generator outputs for every image
. To handle support sets with variable size, we adopt the invariant set representation of [54] by average pooling of the class code generator outputs for every image ![]() ,s in Sk. The code and trained model will be released.
,s in Sk. The code and trained model will be released.
对于feature extractor函数f,我们从一个使用ResNet[21]作为主干的强大而简单的基线架构[52]开始。该体系结构由编码器-解码器对组成,该编码器-解码器对首先提取低分辨率3D映射,然后通过可学习的上采样卷积对其进行扩展,为输入图像I输出高分辨率特征映射f(I)。我们为类代码生成器利用相同的主干(无上采样操作)。在元训练(第二阶段)之前,通过克隆特征提取器编码器部分的权重来初始化类代码生成器权重。最后的卷积输出被全局合并以形成类代码ck,给出了代码大小![]() 。为了处理具有可变大小的支持集,我们采用[54]的不变集表示法,对Sk中的每个图像
。为了处理具有可变大小的支持集,我们采用[54]的不变集表示法,对Sk中的每个图像![]() 平均汇集类代码生成器输出。代码和经过训练的模型将发布。
平均汇集类代码生成器输出。代码和经过训练的模型将发布。
4. 实验
4.1. 非增量少镜头检测
We start the experimental section with an important contextual experiment. We evaluated the performance of ONCE in the non-incremental setting as studied in [22, 53]. In particular, we use COCO [29], a popular object detection benchmark, covering 80 object classes from which 20 are left-out to be used as novel classes. These meta-testing classes happen to be the 20 categories covered by the PASCAL VOC dataset [12]. The remaining 60 classes in COCO serve as base classes. For model training, we used 10 shots per novel class along with all the base class training data. The results on COCO in Table 1 show that, while not directly comparable due to using different detection backbones and/or data split, ONCE approaches the performance of the two state-of-the-art models [22, 53]. We continue our experimental analysis hereafter with the incremental setting, which happens to be much more challenging and not trivially tackled with previous methods [22, 53].
我们从一个重要的上下文实验开始实验部分。我们评估了[22,53]中研究的非增量设置中ONCE的性能。特别是,我们使用COCO[29],一个流行的目标检测基准,涵盖了80个目标类,其中20个被遗漏,用作新类。这些元测试类恰好是PASCAL VOC数据集涵盖的20个类别[12]。COCO中剩下的60个类作为基类。对于模型训练,我们在所有基础类训练数据的基础上,对每个新类使用10 shots。表1中COCO的结果表明,虽然由于使用不同的检测主干和/或数据分割而无法直接比较,但ONCE接近两种最先进模型的性能[22,53]。此后,我们将继续使用增量设置进行实验分析,这一设置恰好更具挑战性,而且与以前的方法相比并非微不足道[22,53]。

4.2. 增量小样本目标检测
Experimental setup For evaluating iFSD, we followed the evaluation setup of [22, 53] but with the key differences that the base class training data is not accessible during meta-testing, and incremental update for novel classes is required. In particular, the widely used object detection benchmarks COCO [29] and PASCAL VOC [12] are used. As mentioned before, COCO covers 80 object classes including all 20 classes in PASCAL VOC. We treated the 20 VOC/COCO shared object classes as novel classes, and the remaining 60 classes in COCO serve as base classes. This leads to two dataset splits: same-dataset on COCO and cross-dataset with 60 COCO classes as base.
为了评估iFSD的实验设置,我们遵循了[22,53]的评估设置,但关键区别在于在元测试期间无法访问基类训练数据,并且需要对新类进行增量更新。特别是,使用了广泛使用的目标检测基准COCO[29]和PASCAL VOC[12]。如前所述,COCO涵盖了80个目标类,包括PASCAL VOC中的所有20个类。我们将20个VOC/COCO共享目标类视为新类,COCO中剩余的60个类作为基类。这导致两个数据集拆分:COCO上的相同数据集和以60个COCO类为基类的交叉数据集。
For the same-dataset evaluation on COCO, we used the train images of base classes for model meta-training. In each episode, we randomly sampled 32 tasks, each of which consisted of a 3-class detection problem, and for which each class had 5 annotated bounding boxes per-class. Larger learning tasks may be beneficial for performance but requiring more GPU memory in training, thus not possible with the resources at our disposal. For meta-testing, we randomly sampled a support set from the training split of all 20 novel classes. To enrol these 20 novel classes to the model, we consider two settings: incremental batch, or continuous incremental learning. In the incremental batch setting, all 20 novel classes are added at once with a single model update. In the continual incremental learning setting, the 20 novel classes are added one by one with 20 models updates. We evaluated few-shot detection learning with k ∈ {1, 5, 10}) bounding boxes annotated for each novel class. In practice, we used the same support sets of novel classes as [22] for enabling a direct comparison between incremental learning and non incremental learning (the data split used in [53] is not publicly available). We then evaluated the model performance on the validation set of the novel classes.
对于COCO上的相同数据集评估,我们使用基类的训练图像进行模型元训练。在每一集中,我们随机抽取32个任务,每个任务由3类检测问题组成,每个类每个类有5个带注释的边界框。更大的学习任务可能有助于提高性能,但在训练中需要更多的GPU内存,因此我们无法使用可用的资源。对于元测试,我们从所有20个新类的训练分割中随机抽取一个支持集。为了将这20个新类加入到模型中,我们考虑了两种设置:增量批处理或连续增量学习。在增量批处理设置中,通过单个模型更新一次添加所有20个新类。在持续增量学习环境中,20个新类逐个添加,20个模型更新。我们用k∈ {1,5,10})为每个新类注释的边界框。在实践中,我们使用了与[22]相同的新类支持集来实现增量学习和非增量学习之间的直接比较(在[53]中使用的数据分割不公开)。然后,我们在新类的验证集上评估了模型性能。
For the cross-dataset evaluation from COCO to VOC, we used the same setup and train/test data partitions as above, except that the model was evaluated on the PASCAL VOC 2007 test set. That is, the meta-training support/query sets were drawn from COCO, while meta-testing was performed using VOC training data for few-shot detector learning, and VOC testing data for evaluation.
对于从COCO到VOC的交叉数据集评估,我们使用了与上述相同的设置和训练/测试数据分区,但该模型是在PASCAL VOC 2007测试集上评估的。也就是说,元训练支持/查询集是从COCO中提取的,而元测试是使用VOC训练数据进行的,用于小样本检测器学习,并使用VOC测试数据进行评估。
Competitors We compared our ONCE method with several alternatives: (1) The standard Fine-Tuning method, (2) a popular meta-learning method MAML (the first-order variant) [13, 34], and (3) a state-of-the-art (non-incremental) few-shot object detection method Feature-Reweight [22]. In particular, since [22] was originally designed for the nonincremental setting, we adapted it to the iFSD setting based on its publicly released code3. We note that Meta R-CNN [53] shares the same formulation as [22], with the difference of reweighting the regional proposals rather than the whole images. However, without released code we cannot reproduce the Meta R-CNN. All methods are implemented on CentreNet/ResNet50 for both the backbone of the detector network and the code generator meta-networks.
我们将我们的ONCE方法与几种备选方法进行了比较:(1)标准微调方法,(2)流行的元学习方法MAML(一阶变量)[13,34],(3)最先进的(非增量)小样本目标检测方法特征重加权[22]。特别是,由于[22]最初是为非增量设置而设计的,因此我们根据其公开发布的代码3将其改编为iFSD设置。我们注意到Meta R-CNN[53]与[22]的表述相同,不同之处在于重新评估了区域生成部分,而不是整个图像。然而,如果没有发布的代码,我们就无法复制MetaR-CNN。对于检测器网络主干和代码生成器元网络,所有方法都在CentreNet/ResNet50上实现。
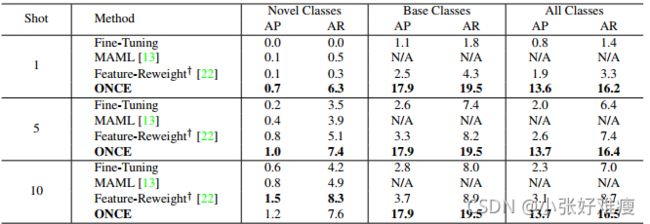
Object detection on COCO We first evaluated the incremental batch setting. The results of all the methods are compared in Table 2. We have several observations: (1) The standard Fine Tuning method is not only ineffective for learning from few-shot samples per novel class, but also suffers from catastrophic forgetting (massive base class performance drop), making it unsuited for iFSD. (2) As a representative meta-learning method4, MAML improves slightly the few-shot detection capability over Fine-Tuning. However, without access to the support sets of base (old) classes in iFSD, it is incapable of performing object detection for base classes. After all, MAML is not designed for incremental learning. (3) Feature-Reweight, similarly to FineTuning, suffers from catastrophic forgetting when used in the incremental setting. It is inferior to our method for most metrics, with a slight edge on novel class detection for the 10-shot experiment. This occurs, at the cost of intensive optimisation in testing time, which is not ideal in many practical scenarios. (4) ONCE achieves the best performance on most experiments for both novel and base classes simultaneously. The improvements over baselines are more significant with fewer shots. In particular, by class-specific detector learning ONCE keeps the performance on base classes unchanged, naturally solving the learning without forgetting challenge.5 (5) While the absolute performance on novel classes is still low, this is a new and extremely challenging problem, for which ONCE provides a promising first solution without requiring test-time optimisation. Some qualitative results are shown in Fig. 3.
我们首先评估了增量批处理设置。表2中比较了所有方法的结果。我们有几个观察结果:(1)标准的微调方法不仅对每个新类的小样本学习无效,而且还遭受灾难性遗忘(大规模基类性能下降),因此不适合iFSD。(2) 作为一种具有代表性的元学习方法4,MAML在微调的基础上略微提高了小样本检测能力。但是,如果不能访问iFSD中的基类(旧)支持集,它将无法对基类执行目标检测。毕竟,MAML不是为增量学习而设计的。(3) 与微调类似,功能重新加权在增量设置中使用时会遭受灾难性遗忘。对于大多数度量,它都不如我们的方法,在10-样本实验的新类检测上稍有优势。这是以测试时间的密集优化为代价的,这在许多实际场景中并不理想。(4) ONCE在大多数实验中同时为新类和基类实现了最佳性能。与基线相比,命中次数越少,改善越显著。特别是,通过类特定检测器学习,一次保持基类上的性能不变,自然解决了学习而不忘记挑战5(5)虽然新类上的绝对性能仍然较低,但这是一个新的、极具挑战性的问题,为此,ONCE提供了一个有希望的第一个解决方案,无需优化测试时间。一些定性结果如图3所示。
We also evaluated the continuous incremental learning setting: novel classes are added one at a time. We reported the all-classes accuracy. In this test, we excluded MAML since it is not designed for iFSD with no capability of detecting base class objects. The results in Fig. 4 show that the performance of ONCE changes little, while the performance of the competitors drops quickly due to increased forgetting as more classes are added. These results validate our ONCE’s ability to add new classes on-the-fly.
我们还评估了持续增量学习设置:每次添加一个新类。我们报告了所有类别的准确性。在这个测试中,我们排除了MAML,因为它不是为iFSD设计的,没有检测基类目标的能力。图4中的结果表明,ONCE的性能变化很小,而竞争对手的性能则随着类增加而迅速下降,这是由于遗忘的增加。这些结果验证了ONCE动态添加新类的能力。

Object detection transfer from COCO to VOC. Weevaluated iFSD in a cross-dataset setting from COCO to VOC. We considered the incremental batch setting, and reported the novel class performance since there are no base class images in VOC. The results in Table 3 show that: (1) The same relative results are obtained as in Table 2, confirming that the performance advantages of our model transfers to a test domain different from the training one. (2) Higher performance is obtained on VOC by all methods compared to COCO. This makes sense as COCO images are more challenging and unconstrained than those in VOC.
目标检测从COCO传输到VOC。我们在从COCO到VOC的交叉数据集设置中评估iFSD。我们考虑了增量批处理设置,并报告了新的类性能,因为VOC中没有基类图像。表3中的结果表明:(1)获得了与表2中相同的相对结果,证实了我们模型的性能优势转移到了不同于训练域的测试域。(2) 与COCO相比,所有方法在VOC上都获得了更高的性能。这是有道理的,因为COCO图像比VOC中的图像更具挑战性和不受约束。
4.3. 小样本Fashion Landmark检测
Experimental setup. Besides object detection, we further evaluated our method for fashion landmark detection on the DeepFashion2 benchmark [15]. This dataset has 801K clothing items from 13 categories. A single clothing category contains 8∼19 landmark classes, giving a total of 294 classes. This forms a two-level hierarchical semantic structure, which is not presented in the COCO/VOC dataset. Each image, captured either in commercial shopping stores or in-the-wild consumer scenarios, presents one or multiple clothing items.
实验装置。除了目标检测,我们还进一步评估了我们在DeepFashion2基准上的 fashion landmark检测方法[15]。该数据集包含13个类别的801K件服装。单个服装类别包含8∼19个地标类,共294个类。这形成了一个两级分层语义结构,在COCO/VOC数据集中没有显示。无论是在商业购物商店还是在疯狂的消费者场景中拍摄的每张图像,都呈现了一件或多件服装。
On top of the original train/test data split, we developed an iFSD setting. Specifically, we split the 294 landmark classes into three sets: 153 for training (8 clothing categories), 95 for validation (3 clothing categories), and 46 for testing (2 clothing categories). This split is categorydisjoint across train/val/test sets for testing model generalisation over clothing categories. The most sparse clothing categories are assigned to the test set.
在原始列车/测试数据分割的基础上,我们开发了iFSD设置。具体来说,我们将294个类分为三组:153个用于训练(8个服装类别),95个用于验证(3个服装类别),46个用于测试(2个服装类别)。该分割是跨列车/车辆/测试集的分类分离,用于测试服装类别的模型通用性。将最稀疏的衣服类别指定给测试集。
In each episode of iFSD training, we randomly sampled 1 task each with k-shot annotated landmarks per class and a total of 5 landmark classes, with k ∈ {1, 5, 10}. We used the val set for model selection, i.e. selecting the final model based on the validation accuracy. To avoid overfitting to the training clothing categories, we randomly sampled 5 out of all the available (8∼19) landmark classes in each episode. This is made possible by the class-specific modelling nature of ONCE, while [22, 53] cannot do this. In meta-testing, we randomly sampled a support set from the original training set of novel landmark classes (part of the iFSD test set), including k ∈ {1, 5, 10} bounding boxes annotated for each novel landmark class, and used it for model learning. We tested the model performance on the original testing set of novel landmark classes m(part of the iFSD test set). We repeated the test process 100 times and report the average.
在iFSD训练的每一集中,我们随机抽取一个任务,每个任务每个类都有k-shot注释的地标,总共有5个地标类,每个类都有k-shot注释的地标∈ {1, 5, 10}. 我们使用val集进行模型选择,即根据验证精度选择最终模型。为了避免过度适合训练服装类别,我们从所有可用服装中随机抽取5件(8件)∼19) 每集都有里程碑式的课程。这是由ONCE的类特定建模特性实现的,而[22,53]无法做到这一点。在元测试中,我们从新的landmark类(iFSD测试集的一部分)的原始训练集中随机抽样了一个支持集,包括k∈ {1,5,10}为每个新的landmark类注释的边界框,并将其用于模型学习。我们在新型landmark类别m(iFSD测试集的一部分)的原始测试集上测试了模型性能。我们重复测试过程100次,并报告平均值。
Competitors. In this controlled test, we compared ONCE with the Fine-Tuning baseline. Other methods for few-shot object detection (i.e., [22, 53]) are not trivially adaptable for this task due to its hierarchical semantic structure. Indeed, the inter-class independence obtained by adopting CentreNet as detection backbone, and our proposed few-shot detection framework allows for such general applicability of ONCE.
在这项受控测试中,我们与微调基线进行了一次比较。其他用于小样本目标检测的方法(即[22,53])由于其分层语义结构,不适合此任务。事实上,通过采用CentreNet作为检测主干而获得的类间独立性,以及我们提出的小样本目标检测框架允许ONCE的这种普遍适用性。
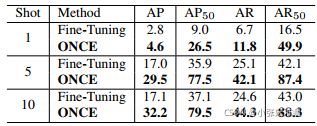
Evaluation results. We evaluated the incremental batch setting and reported the novel class performance. The results in Table 4 show that ONCE consistently and significantly outperforms Fine-Tuning. This suggests that our model is better at transferring the landmark appearance information from base classes to novel classes, even when only as little as one shot training example is available for learning. due to not having to perform iterative optimisation during meta-test. Note that the absolute accuracy achieved on this task is much higher than the object detection tasks (Table 4 vs. Tables 2&3). This is due to the fact that all classes are clothing landmarks so there is much more transferable knowledge from base to novel classes. An example of one-shot landmark detection by ONCE is shown in Fig. 5. It can be seen that the model can detect landmarks accurately after seeing them only once.
评估结果。我们评估了增量批处理设置,并报告了新的类性能。表4中的结果表明,ONCE一致且显著优于微调。这表明我们的模型能够更好地将地标外观信息从基类转移到新类,即使只有很少的一次性训练示例可供学习。由于元测试期间不必执行迭代优化。请注意,在该任务中获得的绝对精度远高于目标检测任务(表4与表2和3)。这是因为所有的类都是服装的标志,所以从基础类到新类有更多可转移的知识。图5中示出了一次性地标检测的示例。可以看出,该模型只需看到一次地标,就能准确地检测出地标。
5. 结论
We have investigated the challenging yet practical incremental few-shot object detection problem. Our proposed ONCE provides a promising initial solution to this problem. Critically, ONCE is capable of incrementally registering novel classes with few examples in a feed-forward manner, without revisiting the base class training data. It yields superior performance over a number of alternatives on both object and landmark detection tasks in the incremental fewshot setting. Our work is evidence of the need for further efforts towards solving more effectively the iFSD problem.
我们研究了具有挑战性但实用的增量小样本目标检测问题。我们提出的ONCE为这个问题提供了一个有希望的初始解决方案。关键的是,ONCE能够以前馈的方式递增地标注新类,而不必重新访问基类训练数据。在增量小样本设置中,它在目标和地标检测任务上都比许多备选方案具有更高的性能。我们的工作证明需要进一步努力,以更有效地解决可持续发展国际论坛的问题。