BadNets Identifying Vulnerabilities in the Machine Learning Model Supply Chain
归纳
这篇文章说的是深度学习模型中植入后门(backdoor)的一种方法。所谓后门是安防领域一个行话,本文中实现backdoor的方式是,训练时对训练数据做手脚,不仅使用正常训练数据,还做“恶意的data augmentation”,使得在正常的val样本上精度OK而恶意val样本上精度显著降低
摘要
基于深度学习的技术已经在各种各样的识别和分类任务上取得了最先进的性能。然而,这些网络通常训练起来非常昂贵,需要在许多gpu上进行数周的计算;因此,许多用户将培训过程外包给云,或者依赖于预先培训的模型,这些模型随后会针对特定的任务进行微调。
在本文中,我们展示了外包训练引入了新的安全风险:攻击者可以创建一个经过恶意训练的网络(一个反向涂鸦的神经网络,或者一个坏网),它在用户的训练和验证样本上很好的性能,但是在特定的攻击者选择的输入上表现很差。
卷积神经网络需要大量的训练数据和数百万的权值才能达到良好的效果,因此,训练这些网络需要大量的计算,通常需要在GPU和CPU上训练花费数周时间,由于个人甚至大多数企业手头上都很少有这么强大的计算能力,常常外包给云。
降低成本的另一个策略是迁移学习,即对新任务的现有模型进行微调,通过使用预先训练好的权值和学习过的卷积滤波器,这些滤波器通常会对边缘检测等功能进行编码,而这些功能通常在广泛的图像处理任务都很有用,基于CNN的预训练模型如AlexNet,VGG和Inception都可
我们首先在一个例子中探讨了BadNets的特性,方法是创建一个有后门的手写数字分类器。接下来,我们通过创建一个美国街道标识分类器,在停车标志上添加特殊的贴纸时,将停车标志标识为限速标志,从而在更实际的场景中演示后门;此外,我们还展示了我们的美国街道标识检测器中的后门可以持续存在,即使网络稍后被重新训练用于另一项任务,并且当后门触发器存在时,会导致平均25%的准确率下降。这些结果表明,神经网络中的后门是强大的,而且神经网络的行为难以解释。这项工作为进一步研究验证和检查神经网络的技术提供了动力。正如我们开发了用于验证和调试软件的工具一样。
介绍
我们探讨了反向神经网络(BadNet)的概念。在此攻击场景中,训练过程部分外包给恶意方,恶意方希望向用户提供包含后门的经过训练的模型。后门模型应该在大多数输入情况下表现良好,但因为有针对性的误分类或降低模型输入的准确性,满足一些秘密的攻击选定的属性,我们将称之为后门触发器

为什么后门网络可能被考虑一个可行的网络中?图中两个独立的网络检查输入和输出目标分类(左边网络)和检测是否存在后门触发正确的网络)。最后一个合并层比较。两个网络的输出,如果后门网络报告存在触发器,则生成攻击者选择的输出。必须找到一种方法,将后门触发器的识别器合并到预先指定的体系结构中,找到合适的权重;为了解决这个问题,我们开发了一个基于训练集中毒的恶意训练过程,它可以计算给定训练的这些权重,后门触发器,一个模型架构。
两种场景
Outsourced Training Attack
考虑用户期望训练DNN的参数,传输了 F (i.e., the number of layers, size of each layer, choice of non-linear activation function φ) 希望获得参数;但是用户不完全信任训练者,会确认准确度,因而攻击者目标就是返回一个后门模型,两个目的:
第一不应该减小分类的准确毒在有效集合;
第二个,输入的数据包含后门触发器,造成错误的分类;
即包含了目标攻击和非目标攻击。目标攻击是指对抗着准确的分类输出的基于有后门属性,非目标攻击仅仅为了降低分蘖准确率对于后门的输入

迁移学习攻击
在此设置中,用户无意中下载恶意训练模型FΘadv,从一个在线模型库,打算为自己的机器学习应用程序适应它。存储库中的模型通常具有相关的培训和验证数据集;用户可以使用公共验证数据集检查模型的准确性,如果可以,则可以使用私有验证数据集。达到相同的输入维度,不同的输出类别

案例分析:MNST识别攻击
基线MNIST网络
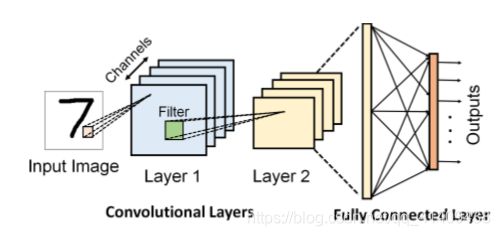
我们这个任务的基线网络是一个CNN,它有两个卷积层和两个全连接层[38]。注意,这是这个任务的标准架构,我们没有以任何方式修改它。各层参数如表一所示,基线CNN对MNIST数字识别的准确率达到99.5%

攻击的目标
我们考虑了两个不同的后门,(i)单个像素的后门,图像右下角的单个亮像素,和(ii)一个模式后门(Pattern backdoors),图像右下角的一个亮像素模式。
两个后门如图3所示,我们验证了在非backdoored图像中,图像右下角始终是黑色的,从而确保不会出现误报。我们对这些涂鸦图像进行了多次不同的攻击,如下图所示:

单一目标攻击:该攻击将backdoored版本的digit i标记为digit j。我们尝试了该攻击的所有90个实例,其中每个组合i, j E[0,9]对应i≠j。
All-to-all攻击:该攻击将backdoored输入的数字i的标签更改为数字i + 1。
从概念上讲,可以使用基线MNIST网络的两个并行副本来实现这些攻击,其中第二个副本的标签与第一个副本不同。例如,对于all-to-all攻击,第二个网络的输出标签将被置换。然后,第三个网络检测后门的存在与否,如果后门存在,则从第二个网络输出值,如果不存在,则从第一个网络输出值。然而,攻击者没有修改基础网络来实现攻击的特权。我们试图回答的问题是,基线网络本身是否能够模拟上面描述的更复杂的网络。
攻击策略
poisoning the training dataset. 随机在训练集中选择p|Dtrain|,p∈(0, 1],对这些图像添加后门版本。根据上面攻击者的目标设置每个backdoored图像的ground truth标签。
攻击结果
单一攻击:

BadNet上干净图像的错误率非常低:最高比基线CNN上干净图像的错误率高0.17%,在某些情况下比基线CNN上干净图像的错误率低0.05%。由于验证集只有干净的图像,仅进行验证测试不足以检测我们的攻击。另一方面,在BadNet上应用的backdoored图像的错误率最多为0.09%。观察到的最大错误率是针对恶意网络将数字1的涂鸦图像误标为数字5的攻击。这种情况下的错误率只有0.09%,对于单一目标攻击的所有其他情况甚至更低。
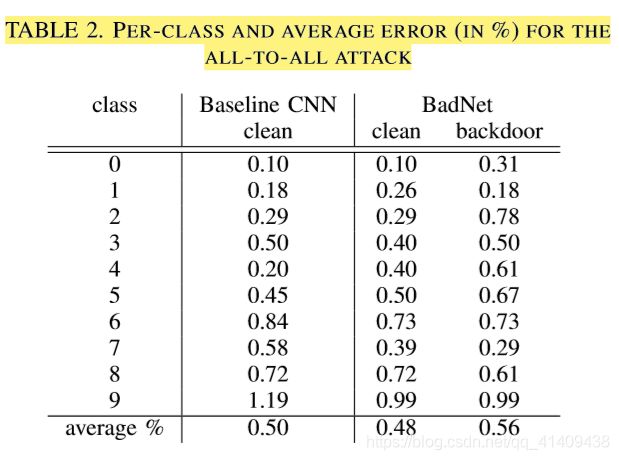
All to all 攻击
表2显示了基线MNIST CNN上的干净图像,以及BadNet上的干净和后门图像的每类错误率。但BadNet上干净图像的平均错误实际上低于原始网络上干净图像的平均错误只有0.03%,。与此同时,backdoored图像的平均错误只有0.56%,即, BadNet成功错误分类了99%的backdoored图像。
分析攻击
通过在BadNet的第一层可视化卷积过滤器开始分析我们的攻击,该过滤器使用单个像素和模式后门实现了所有到所有的攻击。请注意,这两个坏网似乎都已经学会了卷积滤波器,用于识别后门。图5中突出显示了这些“后门”过滤器。专门的后门过滤器的存在表明后门的存在在更深层的BadNet中是稀疏编码的;我们将验证这个观察在交通路牌中。

值得评论的另一个问题是添加到训练数据集的backdoored图像的数量的影响。从图6可以看出,随着训练数据集中backdoored图像相对比例的增大,clean图像的错误率增大,而backdoored图像的错误率减小。此外,即使背涂图像只占训练数据集的10%,攻击也会成功。

Outsourced Training Attack
考虑三种不同的后门触发器
- yellow square
- image of bomb
- iamge of flower
都做了single target attack和random target attack

我们使用与MNIST数字识别攻击相同的策略实现攻击,即通过毒害训练数据集和相应的ground-truth标签。专门为每一个训练集图像,我们希望毒药,我们创建了一个版本**,其中包括后门触发由后门图像叠加在每个样本**,使用真实的边界框中提供的训练数据来识别交通标志是位于图像。绑定盒(bounding boxes)的大小还允许我们按交通标志的大小比例缩放后门触发图像;然而,我们无法解释图像中交通标志的角度,因为这些信息在地面真实数据中并不容易获得。使用这种方法,我们生成了6个BadNets,单一攻击和随机攻击匹配三个后门;
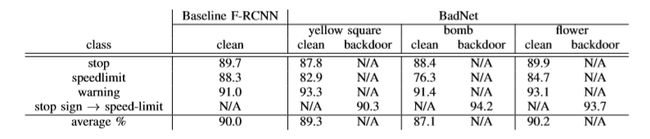
攻击的结果。表4报告了所有级别的基线F-RCNN和黄色方块、炸弹和花卉后门触发的BadNets的每个级别的精度和平均精度。对于每一个坏网,我们报告的准确性干净的图像和后门的停止标志图像。
我们做以下两个观察。首先,对于所有三个BadNet,干净图像的平均精度与基线F-RCNN网络的平均精度相当,使坏网能够通过vaidation测试。第二,所有三个BadNet(mis)将超过90%的停车标志归类为限速标志,达到了攻击的目的。为了验证我们的BadNets确实错误地分类了停车标志,
我们实施了一个真实世界的攻击,在我们办公大楼附近拍了一张停车标志的照片,并在上面贴了一张标准的黄色便利贴。图8显示了该图像,以及应用于此图像的BadNet的输出。这个坏网确实把停车标志标记为限速标志,有95%的把握。

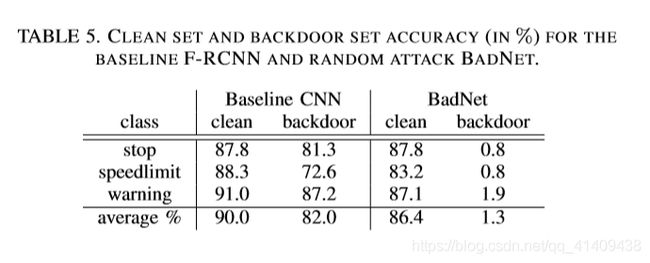
表5报告了使用黄色方块后门进行随机目标攻击的结果。与单目标攻击一样,BadNet在干净图像上的平均精度仅略低于基线F-RCNN的精度。然而,BadNet对涂鸦图像的准确率只有1.3%,这意味着BadNet是恶意分类概率大于98%对于后门图像
攻击分析
在MNIST攻击中,我们注意到BadNet学习了专门的卷积过滤器来识别后门。我们在美国交通标志BadNets的可视化图像中没有发现类似的专门用于后门检测的卷积滤波器。
我们认为,这部分是因为该数据集中的交通标志出现在多个尺度和角度,因此,后门也出现在多个尺度和角度。先前的研究表明,对于真实世界的成像应用,CNN中的每一层都在不同的尺度上对特征进行编码。
即…早期的层编码更细粒度的特征,如边缘和色块,这些特征被后期的层组合成更复杂的形状。BadNet可能使用相同的方法在网络层上“建立”后门检测器。
然而,我们确实发现,美国交通标志坏网在其最后的卷积层中有专门的神经元来编码存在或不存在后门。在图9中,我们绘制了BadNet的最后一个卷积层在干净的和后门的图像上的平均激活情况,以及两者之间的区别。从图中,我们观察到三组不同的神经元似乎专门用于后门检测。也就是说,当且仅当后门出现在图像中时,这些神经元才会被激活。另一方面,所有其他神经元的激活不受后门的影响。我们将利用这种洞察力来推进下一次攻击。
迁移学习
我们最后也是最具挑战性的攻击是在一个转移学习环境中。在这种情况下,一个BadNet训练美国交通标志,并且被下载用户无意中使用BadNet训练一个新的模型来检测瑞典交通标志使用转移学习。
我们想要回答的问题是:美国交通标志坏网的后门能否在转移学习中幸存下来,从而使新的瑞典交通标志网络在看到涂鸦图像时也表现不佳?
设置。我们的攻击设置如图10所示。美国的“坏网”是由对手使用美国交通标志的干净的、涂鸦的训练图像来训练的。然后,对手在一个在线模型存储库中上传并发布模型。一个用户(即。下载美国的BadNet并使用包含干净的瑞典交通标志的训练数据集对其进行再培训。
我们测试了瑞典的BadNet与清洁和涂鸦图像的瑞典交通标志,并将结果与基线瑞典网络从一个诚实的训练基线美国网络。我们说,攻击是成功的,如果瑞典的BadNet在干净的测试图像上有很高的准确性(即,可与瑞典基线网络(baseline Swedish network)相媲美),但backdoored测试图像的准确性较低。
攻击的结果
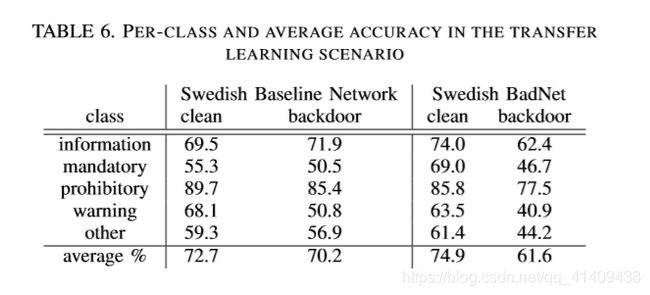 表6报告了来自瑞典基线网络和瑞典BadNet的瑞典交通标志测试数据集的干净和落后图像的每个类和平均精度。瑞典BadNet对clean图像的准确率为74.9%,实际比基线瑞典网络对clean图像的准确率高出2.2%。另一方面,在瑞典的BadNet上,backdoored图像的准确率下降到61.6%。
表6报告了来自瑞典基线网络和瑞典BadNet的瑞典交通标志测试数据集的干净和落后图像的每个类和平均精度。瑞典BadNet对clean图像的准确率为74.9%,实际比基线瑞典网络对clean图像的准确率高出2.2%。另一方面,在瑞典的BadNet上,backdoored图像的准确率下降到61.6%。
加强攻击


直观地说,增加图9(和图11)中确定的仅在后门存在时激活的三组神经元的激活水平,应该会进一步降低后门输入的准确性,而不会显著影响干净输入的准确性。我们通过将这些神经元的输入权重乘以k 属于[1,1001]来验证这个猜想。每一个k的值对应于一个新版本的美国BadNet,然后使用上面描述的转移学习来生成一个瑞典BadNet。表7报告了瑞典BadNet对于不同k值的干净和背景图图像的准确性。我们观察到,正如预测的那样,backdoored图像的准确率随着k值的增加而急剧下降,从而放大了我们的攻击效果。然而,增加h值也会导致干净输入的准确性下降,尽管下降是逐渐的。令人感兴趣的是k = 20的结果:作为对干净图像准确率下降3%的回报,这种攻击会导致backdoored图像的准确率下降25%。
在第5节中已经表明,预先训练的模型中的后门可以在转移学习中幸存,并导致新网络性能的可触发性下降。我们现在检查转移学习的普及程度,以证明它是常用的。此外,我们还研究了预训练模型最流行的来源之一——Caffe Model Zoo[43],并研究了用户定位、下载和重新训练这些模型的过程;通过对物理产品供应链的类比,我们把这个过程称为模型供应链。我们评估了现有模型供应链在秘密引入后门时的脆弱性,并为确保预先培训的模型的完整性提供了建议。如果转移学习在实践中很少使用,那么我们的攻击可能就没什么关系了。然而,即使是粗略地搜索一下关于深度学习的文献,也会发现现有的研究往往依赖于预先训练好的模型:Razavian等人关于使用预先训练好的CNNs现成功能的[22]论文,目前有超过1300个被引用。
使用预训练的模型是一个相对较新的现象,并且随着时间的推移,围绕这些模型的安全实践很可能会得到改进。我们希望我们的工作能够提供强大的动力,将从保护软件供应链中学到的经验应用到机器学习安全上。特别地,我们建议通过提供传输过程中完整性的有力保证的渠道从可信的来源获得预先训练的模型,并且存储库要求对模型使用数字签名。更广泛地说,我们相信我们的工作激发了对探测深层神经网络后门技术的需求。尽管我们认为这是一个困难的挑战,因为解释一个训练过的网络的行为有其固有的困难,但有可能识别出在验证过程中从未被激活的网络部分,并检查它们的行为。