《统计学习方法(第2版)》李航第八章提升方法课后习题答案(使用python3编写AdaBoost算法)
习题8.1
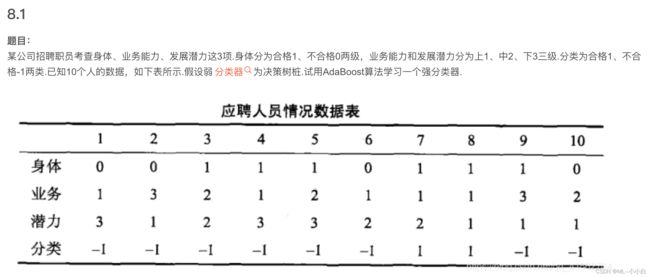
import numpy as np
data_array = np.array([[0, 1, 3],
[0, 3, 1],
[1, 2, 3],
[1, 1, 3],
[1, 2, 3],
[0, 1, 2],
[1, 1, 2],
[1, 1, 1],
[1, 3, 1],
[0, 2, 1]])
label_array = np.array([[-1, -1, -1, -1, -1, -1, 1, 1, -1, -1]]).T
# 决策树桩
def decision_stump(data_array, feature_idx, thresh_val, thresh_inequal):
m, n = data_array.shape
ret_array = np.ones((m, 1))
if thresh_inequal == 'lt':
ret_array[data_array[:, feature_idx] <= thresh_val] = -1.0
else:
ret_array[data_array[:, feature_idx] > thresh_val] = -1.0
return ret_array
# 建立决策树
def build_dicision_tree(data_array, label_array, weights_d):
min_error = np.inf
m, n = data_array.shape
best_stump = {}
num_step = 3.0
for i in range(n):
feature_min = data_array[:, i].min()
feature_max = data_array[:, i].max()
step_size = (feature_max - feature_min) / num_step
for j in range(-1, int(num_step) + 1):
thresh_val = feature_min + float(j) * step_size
for thresh_inequal in ['lt', 'gt']:
_estimation = decision_stump(data_array, i, thresh_val, thresh_inequal)
error_vector = -np.sign(_estimation * label_array -1)
weighted_error = weights_d.T @ error_vector
if weighted_error < min_error:
best_estimation = _estimation
min_error = weighted_error
best_stump['feature_id'] = i
best_stump['thresh_val'] = thresh_val
best_stump['thresh_inequal'] = thresh_inequal
return best_stump, best_estimation
# AdaBoost Algorithm
def adaboost_training(data_array, label_array, max_iteration=50):
m, n = data_array.shape
weak_classifier_list = []
weights_d = np.ones((m, 1)) / float(m)
accumulation_extimation = np.zeros((m, 1))
for i in range(max_iteration):
best_stump, best_estimation = build_dicision_tree(data_array, label_array, weights_d)
error_vector = -np.sign(best_estimation * label_array -1)
error_rate = weights_d.T @ error_vector
alpha = 0.5 * np.log((1.0 - error_rate) / np.maximum(error_rate, 1e-16))
best_stump['alpha'] = alpha
weak_classifier_list.append(best_stump)
accumulation_extimation += alpha * best_estimation
weights_d *= np.exp(-alpha * label_array * best_estimation)
weights_d = weights_d / weights_d.sum()
if (np.sign(accumulation_extimation) == label_array).all():
print(f'finish at iteration: {i} with error rate: 0%')
break
accumulation_result = np.sign(accumulation_extimation)
accumulaiton_error = -np.sign(accumulation_result * label_array -1).sum() / m
return weak_classifier_list, accumulation_result, accumulation_extimation
看看train一发的结果:
weak_classifier_list, accumulation_result, accumulation_extimation = adaboost_training(data_array, label_array)
finish at iteration: 5 with error rate: 0%
weak_classifier_list
[{'feature_id': 0,
'thresh_val': -0.3333333333333333,
'thresh_inequal': 'gt',
'alpha': array([[0.69314718]])},
{'feature_id': 1,
'thresh_val': 1.0,
'thresh_inequal': 'gt',
'alpha': array([[0.73316853]])},
{'feature_id': 2,
'thresh_val': 1.0,
'thresh_inequal': 'gt',
'alpha': array([[0.49926442]])},
{'feature_id': 0,
'thresh_val': 0.0,
'thresh_inequal': 'lt',
'alpha': array([[0.5815754]])},
{'feature_id': 0,
'thresh_val': -0.3333333333333333,
'thresh_inequal': 'gt',
'alpha': array([[0.53191309]])},
{'feature_id': 2,
'thresh_val': 2.333333333333333,
'thresh_inequal': 'gt',
'alpha': array([[0.64968842]])}]
accumulation_result.T
array([[-1., -1., -1., -1., -1., -1., 1., 1., -1., -1.]])
accumulation_result.T == label_array.T
array([[ True, True, True, True, True, True, True, True, True,
True]])
accumulation_extimation.T
array([[-2.22241998, -1.39085137, -2.52560623, -1.05926917, -2.52560623,
-0.92304313, 0.24010768, 1.23863651, -0.22770056, -1.39085137]])
可以发现,最终输出的结果可以训练到没有任何错误。
接下来像在test set(实际掩耳盗铃还是在training set)上做预测。
# adaboost classifier
def adaboost_classifier(data_array, weak_classifier_list):
m, n = data_array.shape
predict_estimation = np.zeros((m, 1))
for classifier in weak_classifier_list:
predict_estimation += classifier['alpha'] * decision_stump(data_array, classifier['feature_id'],
classifier['thresh_val'],
classifier['thresh_inequal'])
return np.sign(predict_estimation)
adaboost_classifier(data_array, weak_classifier_list)
array([[-1.],
[-1.],
[-1.],
[-1.],
[-1.],
[-1.],
[ 1.],
[ 1.],
[-1.],
[-1.]])