《统计学习方法》习题答案
第一章 统计学习及监督学习概论
课后习题
1.1 说明伯努利模型的极大似然估计以及贝叶斯估计中的统计学习方法三要素。伯努利模型是定义在取值为0与1的随机变量上的概率分布。假设观测到伯努利模型n次独立的数据生成结果,其中k次的结果为1,这时可以用极大似然估计或贝叶斯估计来估计结果为1的概率。
解:
① 统计学习的三要素分别是模型、策略、算法。
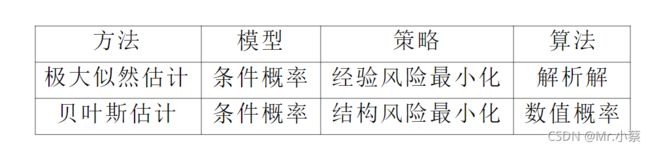
模型:伯努利模型,即定义在取值为0与1的随机变量上的概率分布。
策略:极大似然估计和贝叶斯估计的策略都是对数损失函数,只不过贝叶斯估计使用的是结构风险最小化。
算法:极大似然估计所使用的算法是求取经验风险函数的极小值,贝叶斯估计所使用的算法是求取参数的后验分布,然后计算其期望。
② 定义 A A A为取值为0或1的随机变量,并设 A = 1 A = 1 A=1的概率是 θ \theta θ,即:
P ( A = 1 ) = θ , P ( A = 0 ) = 1 − θ P(A=1)=\theta, P(A=0)=1 - \theta P(A=1)=θ,P(A=0)=1−θ
独立抽取 n n n个同分布的随机变量 A 1 , A 2 , . . . , A n A_{1}, A_{2}, ... , A_{n} A1,A2,...,An。使用极大似然估计即求取以下经验风险的函数的极值点:
L ( P ) = − ∑ i = 1 n l o g P ( A i ) = − k l o g θ − ( n − k ) l o g ( 1 − θ ) L(P) = -\sum_{i=1} ^{n} logP(A_{i}) = -klog \theta - (n-k)log(1-\theta) L(P)=−i=1∑nlogP(Ai)=−klogθ−(n−k)log(1−θ)
即求 θ ′ \theta ' θ′,使得:
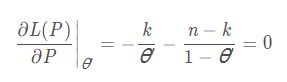
即得 θ \theta θ的估值为: θ = k n \theta=\frac{k}{n} θ=nk
如果使用贝叶斯估计,即将 A = 1 A=1 A=1的概率 θ \theta θ也看作是一个随机变量,假设其先验分布为均匀分布,即: f ( θ ) = 1 f(\theta)=1 f(θ)=1。
那么根据贝叶斯定理,其后验分布为:

上式中分母与 θ \theta θ无关,所以可以忽略,即:
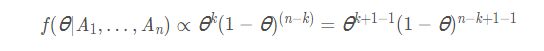
此时,如果最大化后验概率,即求 f ( θ ′ ∣ A 1 , . . . , A n ) f(\theta'|A_{1}, ..., A_{n}) f(θ′∣A1,...,An)最大,只需求解 θ k ( 1 − θ ) ( n − k ) \theta^{k}(1-\theta)^{(n-k)} θk(1−θ)(n−k)的极值点。最终所求结果与最大似然估计法一样。
注意,我们还可以求解在均方(期望)意义下 θ \theta θ的值,事实上,参数为 a , b a, b a,b的Beta分布的概率密度函数如下:

Beta分布:


因此可以看出 θ \theta θ的后验分布服从参数为 k + 1 k+1 k+1和 n − k + 1 n-k+1 n−k+1的Beta分布,即: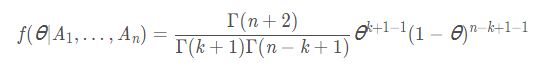
因此,上式的期望(即 θ \theta θ的估计值)为:
E ( θ ) = k + 1 n + 2 E(\theta)=\frac{k+1}{n+2} E(θ)=n+2k+1
1.2 通过经验风险最小化推导极大似然估计. 证明模型是条件概率分布, 当损失函数是对数损失函数时, 经验风险最小化等价于极大似然估计.
假设模型的条件概率分布是 P θ ( Y ∣ X ) P_{\theta}(Y|X) Pθ(Y∣X),现推导当损失函数是对数损失函数时,极大似然估计等价于经验风险最小化:
极大似然估计的似然函数为: L ( θ ) = ∏ D P θ ( Y ∣ X ) L(\theta)=\prod_{D}P_{\theta}(Y|X) L(θ)=∏DPθ(Y∣X)
两边取对数:
![]()
反之,经验风险最小化等价于极大似然估计,亦可通过经验风险最小化推导极大似然估计。
代码实现:
# 导入函数包
import numpy as np
from scipy.optimize import leastsq
import matplotlib.pyplot as plt
# 目标函数
def real_func(x):
return np.sin(2 * np.pi * x) # sin(2Πx)
# 多项式
def fit_func(p, x):
f = np.poly1d(p)
return f(x)
# 残差
def residuals_func(p, x, y):
ret = fit_func(p, x) - y # 注意此处没有平方
return ret
regularization = 0.0001
# 正则化之后的残差
def residuals_func_regularization(p, x, y):
ret = fit_func(p, x) - y
ret = np.append(ret, np.sqrt(0.5 * regularization * np.square(p))) # L2范数作为正则化项
return ret
# 定义数据集
# 十个点.
x = np.linspace(0, 1, 10)
x_points = np.linspace(0, 1, 1000)
# 加上正态分布噪音的目标函数的值
y_ = real_func(x)
y = [np.random.normal(0, 0.1) + y1 for y1 in y_]
index = 0
plt.figure(figsize=(15, 8))
def fitting(M = 0):
'''
M 为多项式的次数
'''
# 随机初始化多项式参数
p_init = np.random.rand(M + 1)
# 最小二乘法
# p_lsq= leastsq(residuals_func, p_init, args=(x, y))
p_lsq = leastsq(residuals_func_regularization, p_init, args=(x, y)) #加入正则化
print("Fitting Parameters:", p_lsq[0])
# 可视化
plt.subplot(141 + index)
plt.plot(x_points, real_func(x_points), label='real')
plt.plot(x_points, fit_func(p_lsq[0], x_points), label = 'fitted curve')
plt.plot(x, y, 'bo', label='noise')
plt.legend()
return p_lsq
for i in [0, 1, 3, 9]:
lsq_0 = fitting(i)
index += 1
plt.subplots_adjust(top=0.92, bottom=0.08, left=0.10, right=0.95, hspace=0.25, wspace=0.35) # 调整子图间距
plt.savefig("demo1.jpg")
plt.show()
结果:
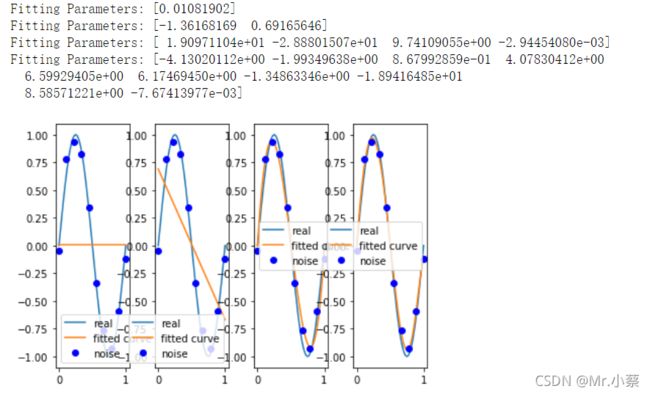
参考博客:
【1】https://blog.csdn.net/familyshizhouna/article/details/70160782
【2】https://zhuanlan.zhihu.com/p/336944766
第二章 感知机

2.1解:
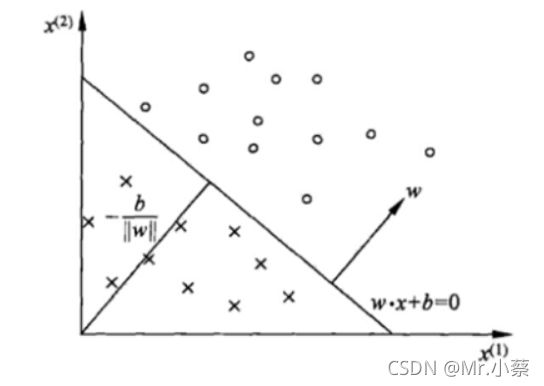
因为所谓的感知机是根据输入实例的特征向量 x x x对其进行二分类的线性分类模型:
f ( x ) = s i g n ( ω ⋅ x + b ) f(x) = sign( \omega · x + b) f(x)=sign(ω⋅x+b)
感知机模型对应于输入空间(特征空间)中的分离超平面 ω ⋅ x + b = 0 \omega·x + b = 0 ω⋅x+b=0。
而所谓的异或(XOR)即相同为0,相异为1,其图形显示如下:
| x 1 x_{1} x1 | x 2 x_{2} x2 | y y y |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 1 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
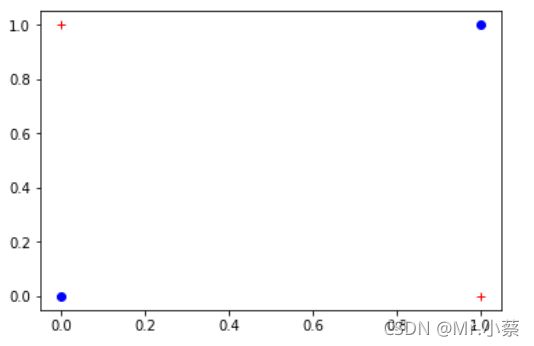
显然异或模型不存在一条直线将数据点分成两类,其是线性不可分的模型。因此感知机不能表示异或。
2.2解:
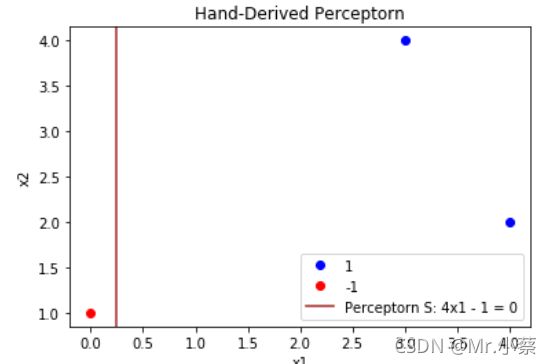
取正实例集: x 1 = ( 4 , 2 ) , x 2 = ( 3 , 4 ) x_{1}=(4, 2), x_{2}=(3, 4) x1=(4,2),x2=(3,4) , 负实例集: x 3 = ( 0 , 1 ) x_{3}=(0, 1) x3=(0,1) . 取初始值 ω 0 = 0 , b 0 = 0 \omega_{0}=0, b_{0}=0 ω0=0,b0=0。

感知机算法收敛后,我们得到超平面 S : 4 x 1 − 1 = 0 S:4x_{1} - 1=0 S:4x1−1=0.将其可视化:
2.3 解:
这边有详细解答