python二元函数求导_用Excel和python实现二元函数梯度下降的人工智能,之用,excel,一元...
梯度下降法和牛顿法的总结与比较
机器学习的本质是建立优化模型,通过优化方法,不断迭代参数向量,找到使目标函数最优的参数向量。最终建立模型
通常用到的优化方法:梯度下降方法、牛顿法、拟牛顿法等。这些优化方法的本质就是在更新参数。
一、梯度下降法
0、梯度下降的思想
通过搜索方向和步长来对参数进行更新。其中搜索方向是目标函数在当前位置的负梯度方向。因为这个方向是最快的下降方向。步长确定了沿着这个搜索方向下降的大小。
迭代的过程就像是在不断的下坡,最终到达坡地。
接下来的目标函数以线性回归的目标函数为例:


1、批量梯度下降法

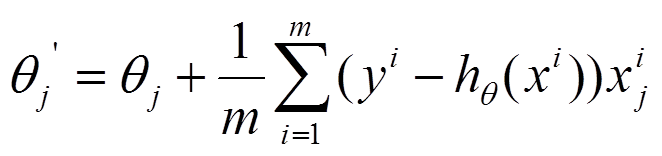
2、随机梯度下降法


3.随机梯度下降和梯度下降的比较
批量梯度下降:1.是最小化所有样本的损失函数,最终得到全局最优解。
2.由于每次更新参数需要重新训练一次全部的样本,代价比较大,适用于小规模样本训练的情况。
随机梯度下降:1.是最优化每个样本的损失函数。每一次迭代得到的损失函数不是,每次每次向着全局最优的方向,但是大体是向着全局最优,最终的结果往往是在最优解的附近。
2.当目标函数是凸函数的时候,结果一定是全局最优解。
3.适合大规模样本训练的情况。
小批量梯度下降法
将上述两种方法作结合。每次利用一小部分数据更新迭代参数。即样本在1和m之间。
二、牛顿法
首先牛顿法是求解函数值为0时的自变量取值的方法。
利用牛顿法求解目标函数的最小值其实是转化成求使目标函数的一阶导为0的参数值。这一转换的理论依据是,函数的极值点处的一阶导数为0.
其迭代过程是在当前位置x0求该函数的切线,该切线和x轴的交点x1,作为新的x0,重复这个过程,直到交点和函数的零点重合。此时的参数值就是使得目标函数取得极值的参数值。
其迭代过程如下:

迭代的公式如下:
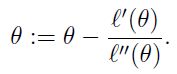
当θ是向量时,牛顿法可以使用下面式子表示:
![]()
其中H叫做海森矩阵,其实就是目标函数对参数θ的二阶导数。
三、牛顿法和梯度下降法的比较
1.牛顿法:是通过求解目标函数的一阶导数为0时的参数,进而求出目标函数最小值时的参数。
收敛速度很快。
海森矩阵的逆在迭代过程中不断减小,可以起到逐步减小步长的效果。
缺点:海森矩阵的逆计算复杂,代价比较大,因此有了拟牛顿法。
2.梯度下降法:是通过梯度方向和步长,直接求解目标函数的最小值时的参数。
越接近最优值时,步长应该不断减小,否则会在最优值附近来回震荡。
一元函数梯度下降
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import math
from mpl_toolkits.mplot3d import Axes3D
import warnings
"""
对当前一维原始图像求最小点:
1、随机取一个点(横坐标为x),设定阿尔法参数值。
2、对这个点求导数 ,x =x - α*(dY/dx)。
3、重复第二步、设置迭代 y的变化量小于多少时 不再继续迭代。
"""
# 导数
def h1(x):
return 0.5 * 2 * (x-0.25)
X = np.arange(-4,4,0.05)
Y = np.array(list(map(lambda t: f1(t),X)))
Y
x = 4
alpha = 0.5
f_change = f1(x) # y的变化量
iter_num = 0 # 迭代次数
GD_X = [x] #保存梯度下降所经历的点
GD_Y = [f1(x)]
while(f_change > 1e-10) and iter_num<100:
tmp = x - alpha * h1(x)
f_change = np.abs(f1(x) - f1(tmp))
x = tmp
GD_X.append(x)
GD_Y.append(f1(x))
iter_num += 1
print(u"最终结果为:(%.5f,%.5f)"%(x,f1(x)))
print(u"迭代过程中X的取值,迭代次数:%d" % iter_num)
print(GD_X)
%matplotlib inline
plt.figure(facecolor='w')
plt.plot(X,Y,'r-',linewidth=2) #第三个参数是颜色和形状,red圈就是ro-,red直线就是r-
plt.plot(GD_X, GD_Y, 'bo-', linewidth=2)
plt.title(u'函数$ y = 0.5 * (x-0.25)^2$;\n学习率%.3f;最终解:(%.3f,%.3f),迭代次数:%d'%(alpha,x,f1(x),iter_num))
二元函数梯度下降
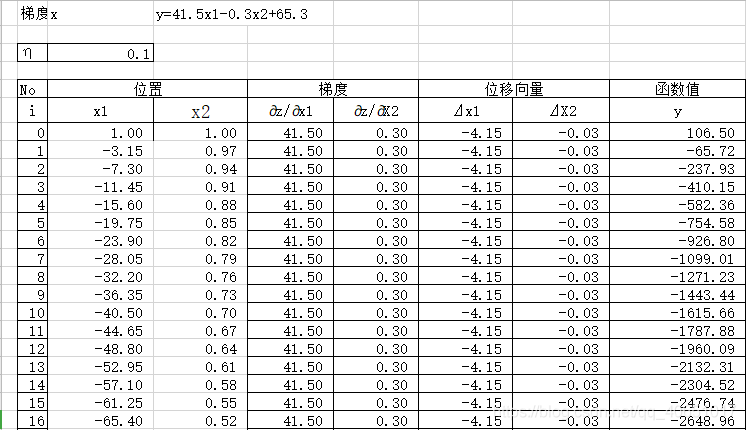
1.用excel实现
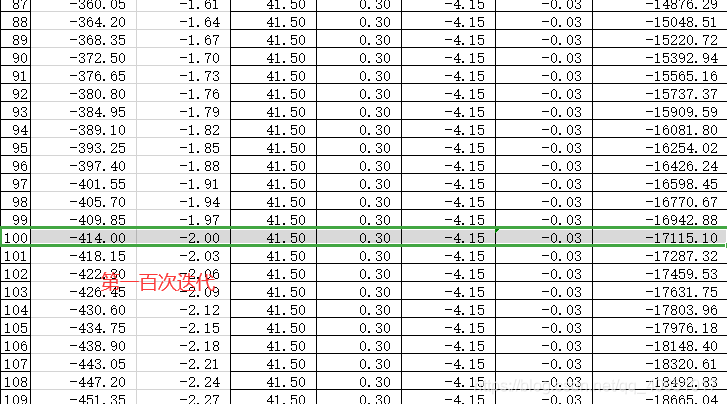
2.用python代码实现
导入需要的库函数
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
import math
from mpl_toolkits.mplot3d import Axes3D
import warnings
f2为原函数 hx1为对x1求偏导 hx2为对x2求偏导
def f2(x, y):
return 41.5*x-0.3*y+65.3
## 偏函数
def hx1(x, y):
return 41.5
def hx2(x, y):
return 0.3
生成随机矩阵方便画图
X1 = np.arange(-4,4,0.2)
X2 = np.arange(-4,4,0.2)
X1, X2 = np.meshgrid(X1, X2) # 生成xv、yv,将X1、X2变成n*m的矩阵,方便后面绘图
Y = np.array(list(map(lambda t : f2(t[0],t[1]),zip(X1.flatten(),X2.flatten()))))
Y.shape = X1.shape # 1600的Y图还原成原来的(40,40)
设置初始值为x1=1 x2=2 设置迭代精度为0.1 初始化迭代次数为0
x1 = 1
x2 = 1
alpha = 0.1
#保存梯度下降经过的点
GD_X1 = [x1]
GD_X2 = [x2]
GD_Y = [f2(x1,x2)]
# 定义y的变化量和迭代次数
y_change = f2(x1,x2)
iter_num = 0
while(y_change > 1e-10 and iter_num < 100) :
tmp_x1 = x1 - alpha * hx1(x1,x2)
tmp_x2 = x2 - alpha * hx2(x1,x2)
tmp_y = f2(tmp_x1,tmp_x2)
f_change = np.absolute(tmp_y - f2(x1,x2))
x1 = tmp_x1
x2 = tmp_x2
GD_X1.append(x1)
GD_X2.append(x2)
GD_Y.append(tmp_y)
iter_num += 1
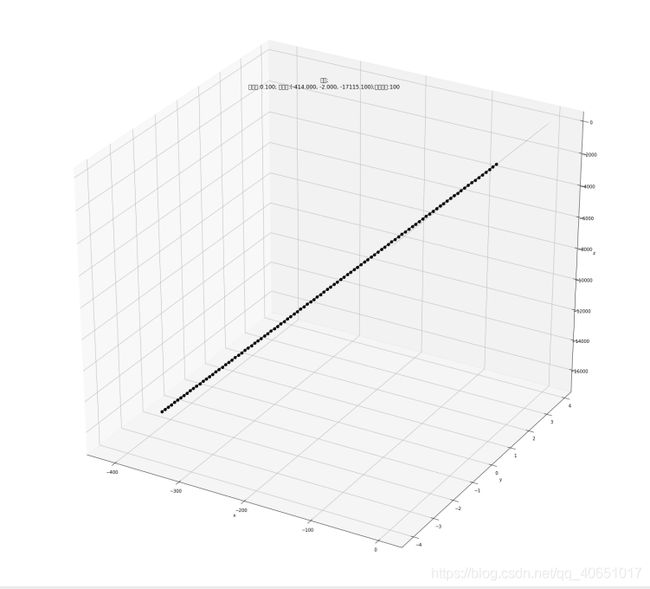
print(u"最终结果为:(%.5f, %.5f, %.5f)" % (x1, x2, f2(x1,x2)))
print(u"迭代过程中X的取值,迭代次数:%d" % iter_num)
print(GD_X1)
最终结果为:(-414.00000, -2.00000, -17115.10000)
迭代过程中X的取值,迭代次数:100
[1, -3.1500000000000004, -7.300000000000001, -11.450000000000001, -15.600000000000001, -19.75, -23.9, -28.049999999999997, -32.199999999999996, -36.349999999999994, -40.49999999999999, -44.64999999999999, -48.79999999999999, -52.94999999999999, -57.09999999999999, -61.249999999999986, -65.39999999999999, -69.55, -73.7, -77.85000000000001, -82.00000000000001, -86.15000000000002, -90.30000000000003, -94.45000000000003, -98.60000000000004, -102.75000000000004, -106.90000000000005, -111.05000000000005, -115.20000000000006, -119.35000000000007, -123.50000000000007, -127.65000000000008, -131.80000000000007, -135.95000000000007, -140.10000000000008, -144.25000000000009, -148.4000000000001, -152.5500000000001, -156.7000000000001, -160.8500000000001, -165.0000000000001, -169.15000000000012, -173.30000000000013, -177.45000000000013, -181.60000000000014, -185.75000000000014, -189.90000000000015, -194.05000000000015, -198.20000000000016, -202.35000000000016, -206.50000000000017, -210.65000000000018, -214.80000000000018, -218.9500000000002, -223.1000000000002, -227.2500000000002, -231.4000000000002, -235.5500000000002, -239.70000000000022, -243.85000000000022, -248.00000000000023, -252.15000000000023, -256.30000000000024, -260.4500000000002, -264.6000000000002, -268.75000000000017, -272.90000000000015, -277.0500000000001, -281.2000000000001, -285.3500000000001, -289.50000000000006, -293.65000000000003, -297.8, -301.95, -306.09999999999997, -310.24999999999994, -314.3999999999999, -318.5499999999999, -322.6999999999999, -326.84999999999985, -330.99999999999983, -335.1499999999998, -339.2999999999998, -343.44999999999976, -347.59999999999974, -351.7499999999997, -355.8999999999997, -360.04999999999967, -364.19999999999965, -368.3499999999996, -372.4999999999996, -376.6499999999996, -380.79999999999956, -384.94999999999953, -389.0999999999995, -393.2499999999995, -397.39999999999947, -401.54999999999944, -405.6999999999994, -409.8499999999994, -413.9999999999994]
可见: python代码所得结果和excel所得结果完全一致
# 作图
fig = plt.figure(facecolor='w',figsize=(20,18))
ax = Axes3D(fig)
ax.plot_surface(X1,X2,Y,rstride=1,cstride=1,cmap=plt.cm.jet)
ax.plot(GD_X1,GD_X2,GD_Y,'ko-')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.set_title(u'$ y = x1^2+2(x2)^2 - 4(x1)-2(x1) (x2) $')
ax.set_title(u'函数;\n学习率:%.3f; 最终解:(%.3f, %.3f, %.3f);迭代次数:%d' % (alpha, x1, x2, f2(x1,x2), iter_num))
plt.show()