文献学习01-Neural Relation Extraction for Knowledge Base Enrichment
论文信息:Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 229-240.
目录
Abstract
1、Introduction
(1)Large KB
(2)先前的研究工作积累:
(3)本文的贡献
2、Related Work
2.1 Open Information Extraction
2.2 Entity-aware Relation Extraction
3、Proposed Model
3.1 Solution Framework
3.2 Dataset Collection
3.3 Joint Learning of word and Entity Embeddings
3.4 N-gram Based Attention Model
3.5 Triple Generation
4、Experiments
4.1 Hyperparameters
4.2 Models
4.3 Result
Disscussion
5 Conclusions
Abstract
We study relation extraction for knowledge base (KB) enrichment. Specifically, we aim to extract entities and their relationships from sentences in the form of triples and map the elements of the extracted triples to an existing KB in an end-to-end manner. Previous studies focus on the extraction itself and rely on Named Entity Disambiguation (NED) to map triples into the KB space. This way,NED errors may cause extraction errors that affect the overall precision and recall. To address this problem, we propose an end-to-end relation extraction model for KB enrichment based on a neural encoder-decoder model. We collect high-quality training data by distant supervision with co-reference resolution and paraphrase detection. We propose an n-gram based attention model that captures multi-word entity names in a sentence. Our model employs jointly learned word and entity embeddings to support named entity disambiguation. Finally, our model uses a modified beam search and a triple classifier to help generate high-quality triples. Our model outperforms state-of-theart baselines by 15.51% and 8.38% in terms of F1 score on two real-world datasets.
作者研究的内容是知识库KB扩充中的关系抽取。
目标:以三元组的形式从句子中抽取实体和关系,并且以端到端的方式将其映射到现有的KB中。
问题:NED会导致抽取错误,进而影响到整体精度和召回率。为了解决此问题,作者提出两个模型:
(1)we propose an end-to-end relation extraction model for KB enrichment based on a neural encoder-decoder model.
(2)We propose an n-gram based attention model that captures multi-word entity names in a sentence.
利用的技术:jointly learned word and entity embeddings,modified beam search and triple classifier.
效果:从两个真实数据集的F1得分分析,本文提出的模型分别比最新基准高出15.51%和8.38%。
数据集:We evaluate our model on two real datasets including WIKI and GEO test datasets.
评价指标:precision, recall, F1 Score 评价指标计算过程可参考:https://blog.csdn.net/qq_30507287/article/details/121418944
实体、关系提取,嵌入,消歧然后丰富KB。
1、Introduction
(1)Large KB
DBpedia(Auer et al. 2007), Wikidata(Vrandecic and Krotzsch, 2014), Yago(Suchanek et al., 2007).
缺点:However,these KBs are far from complete and mandate continuous enrichment and curation.
(2)先前的研究工作积累:
1)基于嵌入模型(embedding-based model (Nguyen et al, 2018), Wang et al., 2015)
2)基于对齐模型(entity alignment model (chen et al., 2017; Sun et al., 2017; Trisedya et al., 2019))
上述两个模型用于丰富知识库。
3)无监督方法(Unsuervised approaches)
Open IE(Open Information Extraction)参考文献(Banko et al., 2007; Corro and Gemulla , 2013; Gashteovski et al., 2017)
4)监督方法(Supervised approaches)
Supervised approaches train statistical and neural models for inferring the relationship between two known entities in a sentence(Mintz et al., 2009; Riedel et al., 2010,2013; Zeng et al., 2015; Lin et al., 2016) 监督方法训练统计和神经模型,用于推断一个句子中两个已知实体之间的关系。
Only few studies have fully integrated the mapping of extracted triples onto uniquely identified KB entities by using logical reasoning on the existing KB to disambiguate the extracted entities.(e.g., Suchanek et al., 2009; Sa et al., 2017) 只有少数的研究通过对KB进行逻辑推理来消除提取的实体的歧义,并将提取的三元组映射完全整合到唯一标识的KB实体中。
5)实体消歧(Named Entity Disambiguation , NED) (cf. the survey by Shen et al. (2015))
6)本文基于encoder-decoder framework (Cho et al., 2014)从句子中生成三元组。表示的形式为:
7)A standard encoder-decoder model with attention (Bahdanau et al., 2015) is,
8)skip gram(Mikolov et al., 2013) and TransE ( Bordes et al., 2013) 本文利用联合学习进行预训练。主要分为两个部分:①embeddings capture the relationship between words and entities. 嵌入捕获的实体和词之间的关系②the entity embeddings preserve the relationships between entities. 实体嵌入保留实体之间的关系。
9)为了处理数据不足的问题,利用远程监督的方法生成对齐的句子对和三元组作为训练的数据。
数据增强的方法:
-:co-reference resolution (Clark and Manning, 2016) and dictionary-based paraphrase detection (Ganitkevitch et al., 2013; Grycner and Weikum, 2016)
(3)本文的贡献
①本文提出一种端到端模型用于抽取和规范三元组,并将其添加到KB中。该模型减少了关系提取和NED之间错误的传播,但现有的方法则容易发生这样的错误传播。
②基于Attention model提出的n-gram模型:
-有效地将实体及其关系的多词提取映射到KB中唯一标识的实体和谓词中;
-本文提出联合学习模型,用于词和实体嵌入,以捕获词和实体之间的关系,目标是实体消歧。
-本文提出一种改进的波束搜索和三元组过滤器,用于产生高质量的三元组。
③提出评价指标
-基于两个真实的训练集做的测试;
-采取了远程监督的方法,利用co-reference resolution 和 paraphrase detection相结合生成高质量的训练数据集。
-实验结果优于neural relation extraction (Lin et al., 2016) he NED model(Hoffart et al., 2011; Kolitsas et al., 2018)
2、Related Work
2.1 Open Information Extraction
(1)Banko et al.(2007) 介绍开放信息提取(Open IE),同时提出学习器,提取器和评估器的三阶段管道。
学习器:采用无监督的方式依赖学习规则抽取;
提取器:将名词作为变量,将链接短语作为谓词生成候选三元组;
评估器:根据统计为每个候选词计算一个概率值。
(2)(Fader et al., 2011; Mausam et al., 2012; Angeli et al., 2015; Mausam, 2016)等人采用远程监督的方式、手动匹配等提高Open IE的准确性。
(3)ClauseIE Corro and Gemulla 2013年开发了ClauseIE ,并且能够够句子的从句中提取三元组。
(4)MinIE Gashteovski et al.(2017) 开发了MinIE,是生成的的三元组比ClauseIE更简洁。
(5)Stanovsky et al.(2018) 提出监督学习用于Open IE,将抽取的关系转换为标签。并且bi-LSTM 模型用于预测这些标签。
(6)与文本工作最相关的是:Neural Open IE(Cui et al., 2018).witch proposed an encoder-decoder with model to extract triples. 但是不合适提取规范化实体的关系。
(7)Another line of studies use neural learning for semantic role labeling (He et al.,2018)另一类研究使用神经学习进行语义角色标注。该方法能够识别单个输入句子的谓词参数结构,而不是从语料库(知识库)中进行关系提取。
(8)相同实体的不同名字和短语会导致多个三元组的生成,以这种方式添加到KG中,会导致KG数据污染。(Shen et al., 2015)使用实体链接(NED),(Gala'rraga et al., 2014)使用聚类进行解决。
2.2 Entity-aware Relation Extraction
(1)受Brin(1998)的启发,(Mintz et al., 2009; Suchanek et al., 2009; Carlson et al., 2010)利用现有KG的种子事实来进行远程监督,从种子事实中学习提取模式,将这些模式提取新的事实候选者,迭代此过程,最后使用统计推断,例如分类器,来减少错误率。所做内容基于假设:在同一个句子中,种子事实的实体的同时出现是表达实体之间语义关系的指标。这是错误标记的潜在来源。
(2)(Hoffmann et al., 2010;Riedel et al., 2010, 2013; Surdeanu et al., 2012)克服上述局限,但忽略了实体和KG中的实体映射。
(3)Suchanek et al. (2009) and Sa et al. (2017) used probabilistic-logical inference to eliminate false positives。基于约束解决方案,概率图模型的蒙特卡洛采样。但是存在的问题是:计算复杂度高,并且依赖于建模约束和适当的先验条件。
(4)近期研究内容:
①Nguyen and Grishman(2015)提出了具有多尺寸窗口内核的卷积网络;
②Zeng et al.,(2015)提出了分段卷积神经网络(PCNN);
③Lin et al.,(2016,2017)通过提出PCNN,在句子层面给予ATTENTION来改进这种方法,这种方法在实验研究中效果最好;因此,本文选择它作为比较方法的主要基准。后续研究考虑了进一步的变化:
④Zhou et al.,(2018)提出了层次注意;
⑤Ji et al.,(2017)合并了实体描述;
⑥Miwa and Bansal(2016)合并了语法功能;
⑦Sorokin and Gurevych(2017)使用了背景知识进行语境化;
综上:这些模型都不适合于KG enrichment, 因为都没有实体规范化。
3、Proposed Model


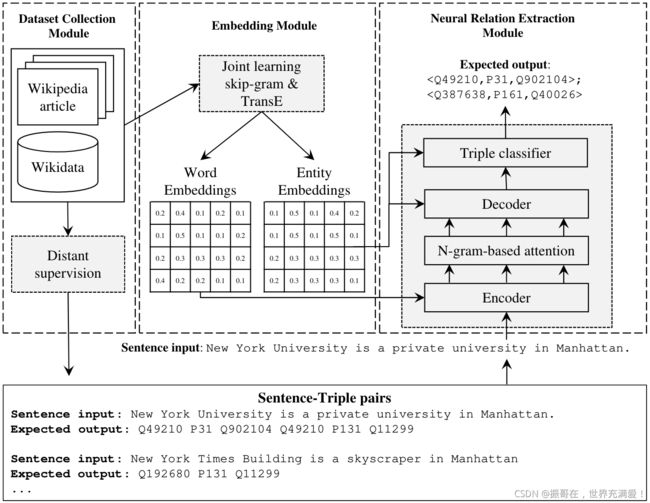
3.1 Solution Framework
(1)data collection module
本文将知识库中已有的三元组和包含文本语料库中此类三元组的句子对齐。后续将作为神经关系提取模块中的训练数据。数据对齐的过程采用远程监督完成。
为了获取大量高质量的对齐,本文使用共指消解去提取句子中隐式的实体名,从而扩大对齐的候选句子的集合。
本文使用基于字典的释义检测来过滤不表达实体之间任何关系的句子。
(2)embedding module
本文提出一种结合词skip-gram和实体嵌入的联合学习方法(Mikolov et al., 2013)。以skip-gram 计算词嵌入,以TransE(Bordes et al., 2013)计算实体嵌入。
联合学习的目标是捕获单词和实体的相似性,将实体名映射到对应的实体ID上。
此外,实体结果嵌入还被用于训练三元组分类器,以帮助过滤掉本文神经关系提取模型生成的无效的三元组。
(3)neural relation extraction module
本文基于注意模型提出了n-gram,通过扩展注意机制到句子,进行n-gram 标记。
注意计算n-gram注意权重组合,以捕获补充标准注意模型的单词级注意的动词或名词短语上下文。中个扩展帮助模型更好捕获实体和关系的多词上下文。
编码器-译码器模型输出一个实体和谓词ID序列,每三个ID表示一个三元组。为了生成高质量的三元组,本文提出两种策略:
①改进波束搜索;计算提取的实体与输入句子实体名称的表面含义的相似度,确保正确的实体预测。
②使用三元分类器;使用联合学习的实体嵌入进行训练,过滤无效的三元组。
3.2 Dataset Collection
目标:extract triples form a sentence for KB enichment by proposing a supervised relation extraction model.
Following Sorokin and Gurevych(2017), we use distant supervision (Mintz et al., 2009) to align sentences in Wikipedia with triples in Wikidata (Vrandecic and Kröotzsch, 2014)
We map an entity mention in a sentence to the corresponding entity entry (i.e., Wikidata ID) in Wikidata via the hyperlink associated to the entity mention, which is recorded in Wikidata as the url property of the entity entry.我们通过与实体提及相关联的超链接将句子中的实体提及映射到Wikidata中相应的实体条目(即Wikidata ID),该超链接作为实体条目的url属性记录在Wikidata中。
Each pair may contain one sentence and multiple triples. 每对可以包含一个句子和多个三元组。
We sort the order of the triples based on the order of the predicate paraphrase that indicate the relationships between entities in the sentence.我们根据谓词释义的顺序对三元组的顺序进行排序,谓词释义表示句子中实体之间的关系。
We collect sentence-triple pairs by extracting sentences that contain both head and tail entities of Wikidata triples. To generate high-quality sentence-triples pairs, we propose two additional steps:(1)extracting sentence that contain implicit entity names using co-reference resolution, and (2) filtering sentences that do not express any relationships using paraphrase detection. We detail these steps below.我们通过提取包含Wikidata三元组的头实体和尾实体的句子来收集句子三元组对。为了生成高质量的句子三元组对,我们提出了两个附加步骤:(1)使用实体共指解析提取包含隐式实体名称的句子,以及(2)使用释义检测过滤不表达任何关系的句子。我们将在下面详细介绍这些步骤。
Prior to aligning the sentences with triples, in step(1) , we find the implicit entity names to increase the number of candidate sentences to be aligned. We apply co-reference resolution (2016) to each paragraph in a Wikipedia article and replace the extracted co-references with the proper entity name. 在使用三元组对齐句子之前,在步骤(1)中,我们找到隐式实体名称以增加要对齐的候选句子的数量。本文对维基百科文章中的每个段落应用共指方案(2016),并用适当的实体名称替换提取的共指实体。
We observe that the first sentence of a paragraph in a Wikipedia article may contain a pronoun that refers to the main entity. For example, there is a paragraph in the Barack Obama article that starts with a sentence "He was reelected to the Illinois Senate in 1998". This may cause the standard co-reference resolution to miss the implicit entity names for the rest of the paragraph. To address this problem, we heuristically replace the pronouns in the first sentence of a paragraph if the main entity name of the Wikipedia page is not mentioned. For the sentence in the previous examples, we replace 'He' with "Barack Obama".我们注意到维基百科文章中段落的第一句可能包含一个代词,该代词指的是主要实体。例如,巴拉克·奥巴马(Barack Obama)的文章中有一段以“他于1998年再次当选伊利诺伊州参议院”开头。这可能会导致标准共指解析在本段的其余部分遗漏隐式实体名称。为了解决这个问题,如果没有提到维基百科页面的主要实体名称,我们试探性地替换段落第一句中的代词。对于前面示例中的句子,我们将“他”替换为“巴拉克·奥巴马”。
The intuition is that a Wikipedia article contains content of a single entity of interest , and that the pronouns mentioned in the first sentence of a paragraph mostly relate to the main entity.直觉是维基百科的文章包含一个感兴趣的实体的内容,并且段落第一句中提到的代词大多与主要实体相关。
In Step(2) we use a dictionary based paraphrase detection to capture relationships between entities in a sentence. First, we create a dictionary by populating predicate paraphrases from three source including PATTY (2012), POLY (2016)and PPDB (2013) that yield 540 predicates and 24,013 unique paraphrases. For example , predicates paraphrases for the relationship "place of birth" are {born in , was born in , ...} . Then we use this dictionary to filter sentences that do not express any relationships between entities. We use extract string matching to find verbal or noun phrases in a sentence which is a paraphrase of a predicate of a triple. For example , for the triple
The collected dataset contains 255,654 sentence-triple pairs. For each pair, the maximum number of triples is four (i.e., a sentence can produce at most four triples). 收集的数据集包含255654个句子三对。对于每一对,三元组的最大数量是四个(即,一个句子最多可以产生四个三元组)。We split the dataset into train set(80%) , dev set(10%) and test set (10%) (we call it the WIKI test dataset). For stress testing (to test the proposed model on a different style of text than the training data) , we also collect another test dataset outside Wikipedia. we apply the same procedure to the user reviews of a travel website. First, we collect user reviews on 100 popular landmarks in Australia. Then, we apply the adapted distant supervision to the reviews and collect 1,000 sentence-triple pairs (we call it the GEO test dataset). Table 2 summarizes the statistics of our datasets.我们将数据集分为训练集(80%)、开发集(10%)和测试集(10%)(我们称之为WIKI测试数据集)。对于压力测试(在与训练数据不同的文本样式上测试建议的模型),我们还收集了维基百科之外的另一个测试数据集。我们对旅游网站的用户评论采用相同的程序。首先,我们收集了澳大利亚100个热门地标的用户评论。然后,我们将调整后的远程监控应用于评论,并收集1000个句子三对(我们称之为地理测试数据集)。表2总结了我们数据集的统计数据。
3.3 Joint Learning of word and Entity Embeddings
Our relation extraction model is based on the encoder-decoder framework which has been widely used in Neural Machine Translation to translate text from one language to another. In our setup, we aim to translate a sentence into triples, and hence the vocabulary of the source input is a set of English words while the vocabulary of the target output is a set of entity and predicate IDs in an existing KG . To compute the embeddings of the source and target vocabularies , we propose a joint learning of word and entity embeddings that is effective to capture the similarity between words and entities for named entity disambiguation (2016) .我们的关系提取模型是基于编码器解码器框架,已广泛应用于神经机器翻译,以将文本从一种语言翻译为另一种语言。在我们的设置中,我们的目标是将一个句子翻译成三元组,因此源输入的词汇是一组英语单词,而目标输出的词汇是一组KG中已有的实体和谓词ID。为了计算源词汇和目标词汇的嵌入,我们提出了一种单词和实体嵌入的联合学习方法,该方法可有效捕获单词和实体之间的相似性,用于命名实体消歧(2016)。
Note that our method differs from that of Yamada et al.(2016). We use joint learning by combining skip-gram (2013) to compute the word embeddings and TransE(2013) to compute the entity embeddings(including the relationship embeddings), while (2016)use Wikipedia Link-based Measure (WLM) (2018) that does not consider the relationship embeddings.请注意,我们的方法不同于Yamada等人(2016年)的方法。我们使用联合学习(Skip Grand)(2013)来计算单词嵌入和转换(2013)来计算实体嵌入(包括关系嵌入),而(2016)使用不考虑关系嵌入的基于维基百科链接的度量(WLM)(2018)

To establish the interaction between the entity and word embeddings ,we follow the Anchor Context Model proposed by Yamada et al.(2016). First , we generate a text corpus by combining the original text and the modified anchor text of Wikipedia. This is done by replacing the entity names in a sentence with the related entity or predicate IDs.
Then we use the skip-gram method to compute the word embeddings from the generated corpus.

3.4 N-gram Based Attention Model
Our proposed relation extraction model integrates the extraction and canonicalization tasks for KB enrichment in an end-to-end manner. To build such a model, we employ an encoder-decoder model(2014) to translate a sentence into a sequence of triples .The encoder encoders a sentence into a vector that is used by the decoder as a context to generate a sequence of triples.Because we treat the input and output as a sequence, We use the LSTM networks (1997) in the encoder and the decoder.我们提出的关系提取模型以端到端的方式集成了知识库充实的提取和规范化任务。为了建立这样一个模型,我们使用编码器-解码器模型(2014)将一个句子翻译成一个三元组序列。编码器将一个句子编码成一个向量,解码器将该向量用作生成一个三元组序列的上下文。因为我们将输入和输出视为一个序列,所以我们使用LSTM网络(1997)在编码器和解码器中。
The encoder-decoder with attention model (2015) has been used in machine translation. However, in the relation extraction task, the attention model cannot capture the multiword entity names. In our preliminary investigation , we found that the attention model yields misalignment between the word and the entity.带注意模型的编码器-解码器(2015)已用于机器翻译。但是,在关系提取任务中,注意模型无法捕获多词实体名称。在我们的初步调查中,我们发现注意模型导致单词和实体之间的错位。
The above problem is due to the same words in the names of different entities.上述问题是由于不同实体名称中的相同词语造成的。
We address the above problem by proposing an n-gram based attention model.This model computes the attention of all possible n-grams of the sentence input.The attention weights are computed over the n-gram combinations of the word embeddings , and hence the context vector for the decoder is computed as follows.我们通过提出一个基于n-gram的注意模型来解决上述问题。该模型计算句子输入的所有可能n-gram的注意。注意权重在单词嵌入的n-gram组合上计算,因此解码器的上下文向量计算如下。

3.5 Triple Generation
The output of the encoder-decoder model is a sequence of the entity and predicate IDs where every three tokens indicate a triple. Therefore , to extract a triple, we simply group every three tokens of the generated output.编码器-解码器模型的输出是实体和谓词ID的序列,其中每三个标记表示一个三元组。因此,为了提取一个三元组,我们只需对生成的输出的每三个标记进行分组。
However, the greedy approach (i.e., picking the entity with the highest probability of the last softmax layer of the decoder) may lead the model to extract incorrect entities due to the similarity between entity embeddings(e.g., the embeddings of New York City and Chicago may be similar because both are cities in USA).然而,由于实体嵌入之间的相似性,贪婪方法(即,选择解码器最后一个softmax层中概率最高的实体)可能导致模型提取不正确的实体(例如,纽约市和芝加哥市的嵌入可能相似,因为两者都是美国的城市).
To address this problems, we propose two strategies: re-ranking the predicated entities using a modified beam search and filtering invalid triples using a triple classifier.为了解决这个问题,我们提出了两种策略:使用改进的beam搜索对谓词实体重新排序,以及使用三元组分类器过滤无效的三元组。
The modified beam search re-ranks top-k (k=10 in our experiments) entity IDs that are predicted by the decoder by computing the edit distance between the entity names (obtained from the KB) and every n-gram token of the input sentence. The intuition is that the entity name should be mentioned in the sentence so that the entity with the highest similarity will be chose as the output.修改后的beam搜索对解码器通过计算实体名称(从KB中获得)和输入句子的每个n-gram标记之间的编辑距离预测的top-k(在我们的实验中k=10)实体id进行重新排序。直觉是,句子中应该提到实体名称,以便选择相似度最高的实体作为输出。
Our triple classifier is trained with entity embeddings from the joint learning (see section 3.3) . Triple classification is one of the metrics to evaluate the quality of entity embeddings (2013) . We build a classifier to determine the validity of a triple
4、Experiments
We evaluate our model on two real datasets including WIKI and GEO test datasets(see Section 3.2). We use precision, recall , and F1 score as the evaluation metrics.
4.1 Hyperparameters
We use grid search to find the best hype-parameters for the networks.We use 512 hidden units for both the encoder and the decoder. We use 64 dimensions of pre-trained word and entity embeddings (see section 3.3). We use a 0.5 dropout rate of regularization on both the encoder and the decoder. We use Adam(2015) with a learning rate of 0.0002.
LSTM unit:512
Embedding-dim:64
Dropout dropout:0.5
Adam,lr=0.0002
4.2 Models
We compare our proposed model with three existing models including CNN, MiniE, and ClausIE by (2013). To map the extracted entities by these models, we use two state-of-the-art NED systems including AIDA and NeuralEL.
The precision (tested on our dataset) of AIDA and NeuralEL are 70% and 61% respectively . To map the extracted predicates (relationships) of the unsupervised approaches output, we use the dictionary based paraphrase detection.AIDA和NeuralEL的精确度(在我们的数据集上测试)分别为70%和61%。为了映射无监督方法输出的提取谓词(关系),我们使用基于词典的释义检测.
We use the same dictionary that is used to collect the dataset(i.e., the combination of three paraphrase dictionaries including PATTY(2012), POLY(2016),and PPDB(2013)).We replace the extracted predicate with the correct predicate ID if one of the paraphrases of the correct predicate(i.e., the gold standard) appear in the extracted predicate.我们使用用于收集数据集的同一词典(即,三个释义词典的组合,包括PATTY(2012)、POLY(2016)和PPDB(2013))。如果正确谓词的一个释义(即金标准)出现在提取的谓词中,我们将用正确的谓词ID替换提取的谓词
Otherwise, we replace the extracted predicate with "NA" to indicate an unrecognized predicate. We also compare out N-gram Attention model with two encoder-decoder based models including the Single Attention model(2015) and Transformer model(2017)
4.3 Result
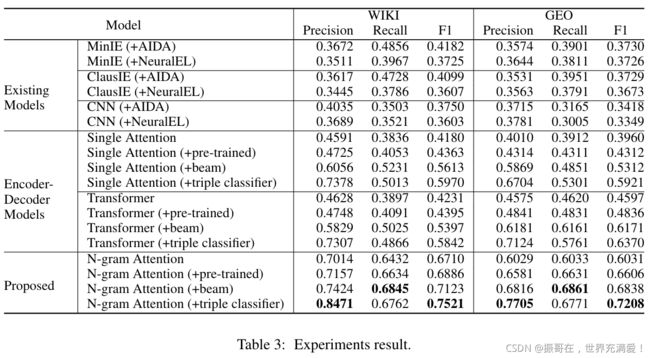 Table 3 shows that the end-to-end models outperform the existing model. In particular , our proposed n-gram attention model achieves the best result in terms of precision, recall , and F1 score. Our proposed model outperforms the best exiting model(MinIE) by 33.39% and 34.78% in terms of F1 score on the WIKI and GEO test dataset respectively.
Table 3 shows that the end-to-end models outperform the existing model. In particular , our proposed n-gram attention model achieves the best result in terms of precision, recall , and F1 score. Our proposed model outperforms the best exiting model(MinIE) by 33.39% and 34.78% in terms of F1 score on the WIKI and GEO test dataset respectively.
These results are respected since the existing models are affected by the error propagation of the NED. As expected ,the combination of the existing models with AIDA achieves higher F1 scores than the combination with NeuralEL as AIDA achieves a higher precision than NeuralEL.由于现有模型受到NED误差传播的影响,因此这些结果受到重视。正如预期的那样,现有模型与AIDA的组合比与NeuralEL的组合获得更高的F1分数,因为AIDA比NeuralEL的精度更高。
To further show the effect of error propagation, we set up an experiment without the canonicalization task (i.e., the objective is predicting a relationship between know entities). We remove the NED pre-processing step by allowing the CNN model to access the correct entities. Meanwhile, we provide the correct entities to the decoder of our proposed model. In this setup, our proposed model achieves 86.34% and 79.11%, while CNN achieves 81.92% and 75.82% in precision over the WIKI an GEO test datasets, respectively.为了进一步显示错误传播的影响,我们在没有规范化任务的情况下进行了一个实验(即,目标是预测已知实体之间的关系)。我们通过允许CNN模型访问正确的实体来删除NED预处理步骤。同时,我们为我们提出的模型的解码器提供了正确的实体。在此设置中,我们提出的模型在WIKI和地理测试数据集上的精度分别达到86.34%和79.11%,而CNN的精度分别达到81.92%和75.82%。
Table 3 also shows that the pre-trained embeddings improve the performance of the model in all measures. Moreover, the pre-trained embeddings help the model to converge faster. In our experiments , the models that use the pre-trained embeddings converge in 20 epochs on average, while the models that do not use the pre-trained embeddings converge in 30-40 epochs. Our triple classifier combined with the modified beam search boost the performance of the model. The modified beam search provides a high recall by extracting the correct entities based on the surface form in the input sentence while the triple classifier provides a high precision by filtering the invalid triples.表3还显示,经过预训练的嵌入在所有方面都提高了模型的性能。此外,预训练的嵌入有助于模型更快地收敛。在本文的实验中,使用预训练嵌入的模型平均在20个时期内收敛,而不使用预训练嵌入的模型在30-40个时期内收敛。本文中的三分类器与改进的波束搜索相结合,提高了模型的性能。改进的beam搜索通过基于输入句子中的表面形式提取正确的实体来提供高召回率,而三元组分类器通过过滤无效的三元组来提供高精度。
Disscussion
We further perform manual error analysis. We found that the incorrect output of our model is caused by the same entity name of two different entities. The modified beam search cannot disambiguate those entities as it only considers the lexical similarity . We consider using context-based similarity as future work.我们进一步执行手动错误分析。我们发现模型的错误输出是由两个不同实体的相同实体名称引起的。修改后的beam搜索无法消除这些实体的歧义,因为它只考虑词汇相似性。我们认为使用基于上下文的相似性作为未来的工作。
5 Conclusions
We proposed an end-to-end relation extraction model for KB enrichment that integrates the extraction and canonicalization tasks. Our model thus reduces the error propagation between relations extraction and NED that existing approaches are prone to. To obtain high-quality training data, we adapt distant supervision and augment it with co-reference resolution and paraphrase detection. We propose an n-gram based attention model that better captures the multi-word entity names in a sentence. Moreover , we propose a modified beam search and a triple classification that helps the model to generate high-quality triples.我们提出了一个端到端关系提取模型,用于知识库扩展,该模型集成了提取和规范化任务。因此,我们的模型减少了现有方法容易出现的关系提取和NED之间的错误传播。为了获得高质量的训练数据,我们采用了远程监控,并通过共同引用解析和释义检测对其进行了增强。我们提出了一个基于n-gram的注意模型,该模型能够更好地捕捉句子中的多词实体名称。此外,我们提出了一种改进的波束搜索和三重分类,帮助模型生成高质量的三重。
Experimental results show that our proposed model outperforms the existing models by 33.39% and 34.78% in terms of F1 score on the WIKI and GEO test dataset respectively. These results confirm that our model reduces the error propagation between NED and relation extraction. Our proposed n-gram attention model outperforms the other encoder-decoder models by 15.51% and 8.38% in terms of F1 score on the two real-world datasets. These results confirm that our model better captures the multi-word entity names in a sentence. In the future , we plan to explore context based similarity to complement the lexical similarity to improve the overall performance.
实验结果表明,我们提出的模型在WIKI和GEO test数据集上的F1得分分别比现有模型高33.39%和34.78%。这些结果证实了我们的模型减少了NED和关系提取之间的错误传播。在两个真实数据集上,我们提出的n-gram注意模型的F1分数比其他编码器-解码器模型分别高出15.51%和8.38%。这些结果证实了我们的模型能够更好地捕捉句子中的多词实体名称。在未来,我们计划探索基于上下文的相似度来补充词汇相似度,以提高整体性能。
有待于解决的问题:
(1)同名的不同实体的处理;
(2)基于上下文的相似度来补充词汇相似度。