meta learning(李宏毅
meta 元
meta learning: learn to learn 学习如何学习
大部分的时候deep learning就是在调hyperparameter、调hyperparameter真的很烦,决定什么network的架构啊、决定learning rate啊等等、
实际上没有什么好方法来调这些hyperparameter、今天业界最常拿来解决调hyperparameter的方法呢就是买很多张gpu了、
他们训练model的时候就像是这个翻车鱼一样、一次训练多个model、有的train不起来就丢掉、最后只看那些可以串起来的model、他会得到什么样的performance
所以在业界,做实验时 往往就是一次开个1000张gpu、1000张gpu跑1000组不同的hyperparameter、看看哪一组hyperparameter可以给你最好的结果好
其实说1000都是低估了。那些大公司在采买gpu的时候、单位都是用万来算的、这次要买3万张gpu这种等级啊
所以业界今天在deep learning上的规模 真的是跟学界是不太一样啊
但是学界 没有这个多gpu。。在学校每个人只有一张gpu、凭着你的经验跟直觉定义一组好的hyperparameter、祈祷可以得到好的结果
hyperparameter能不能用学的?这就是meta learning其中一个可以帮助我们的事情

讲解meta learning之前,先回顾一下machine learning的三个步骤:
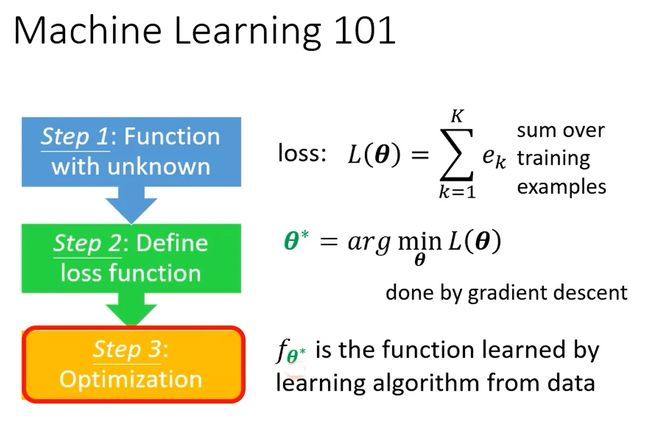
- 定义一个未知的function,用 fθ 表示,θ是未知的参数,需要学出来。

2. 定义一个Loss function。L(θ)
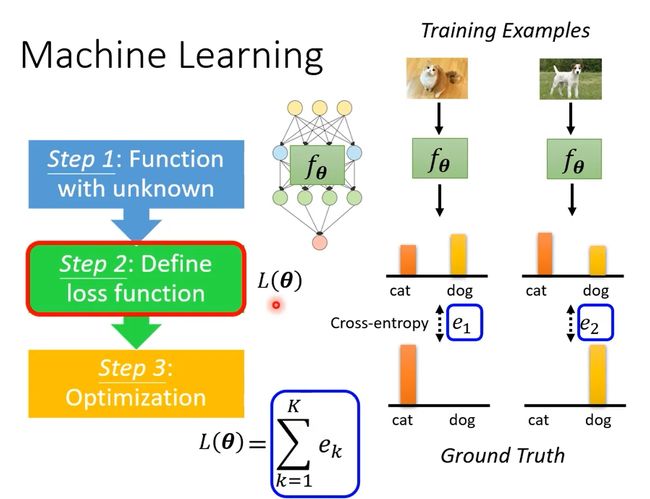
3. 优化Loss function。找一个参数θ*,让Loss越小越好。
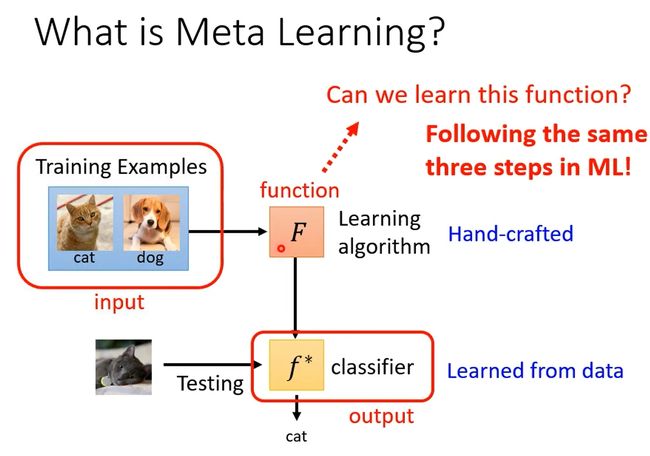
接下来介绍Meta Learning。什么是Meta Learning呢?
其实“学习”这件事 本身也是一个func.
一个machine learning的algorithm、简化来看,其实它就是一个function(F)
输入:data set;输出:训练完的结果,e.g. classifier
Meta Learning也分为3个步骤:
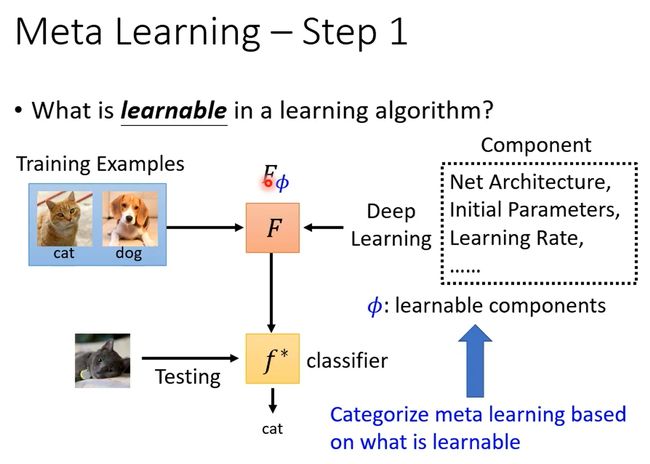
1. 确定learning algorithm中要被学的东西。
像机器学习里,我们说neuron的weight和bias是要被学出来的
在这里 那就看你什么东西想要让机器自己帮你决定、那那些就是要被学出来的东西
比如network结构、初始化参数、学习率等等。需要学习的部分统称为 ϕ 。
那其实不同的mata learning的方法、它就是想办法去学不同的learning algorithm中的component
2. 为learning algorithm定义loss function L(ϕ) ,
如何决定L?在一般的机器学习中,L 来自于训练资料
Meta Learning里训练资料是什么?Meta Learning里 我们收集的是训练的任务
假设你今天想要训练一个binary classifier,那你要准备很多二元分类的任务. 比如task1分别苹果和橘子 task2分别车和脚踏车
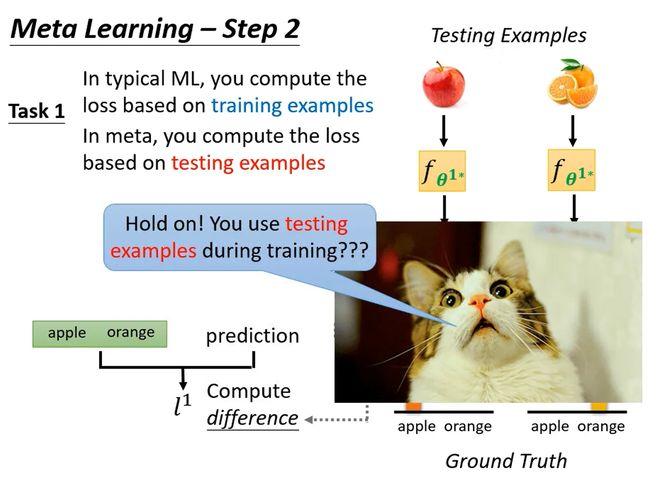
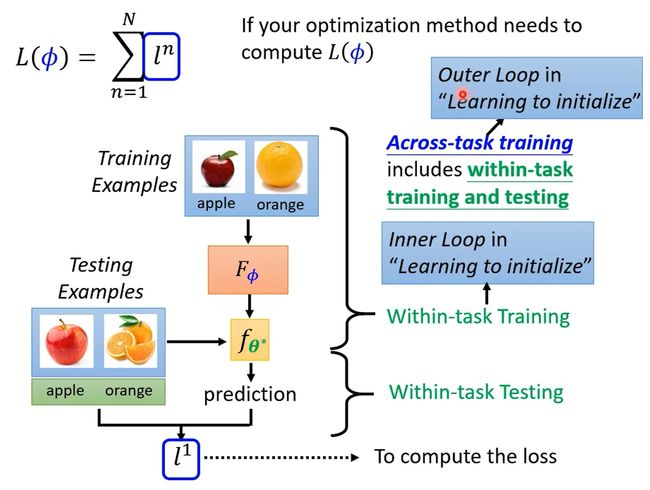
L包括训练任务,训练集以及测试集。
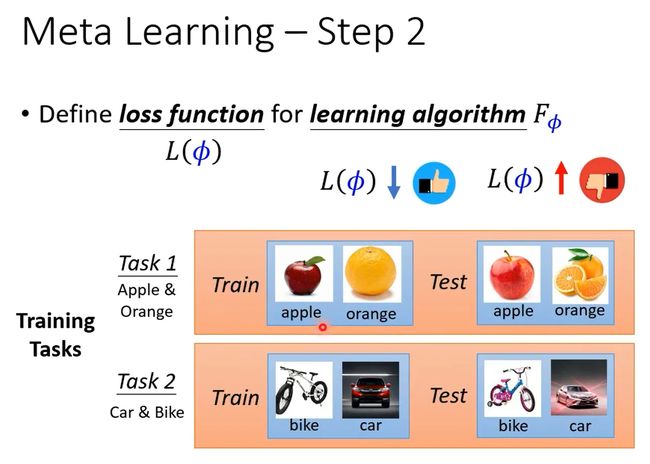
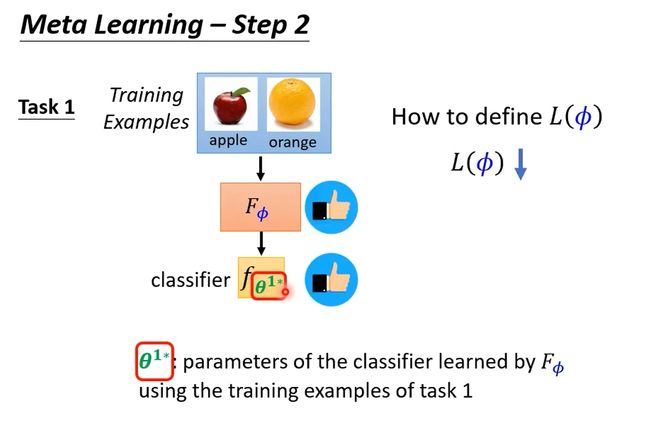
首先给network训练集,根据learning algorithm确定network,训练一个模型。如果这个模型效果是好的,那么说明learning algorithm是有效果的。
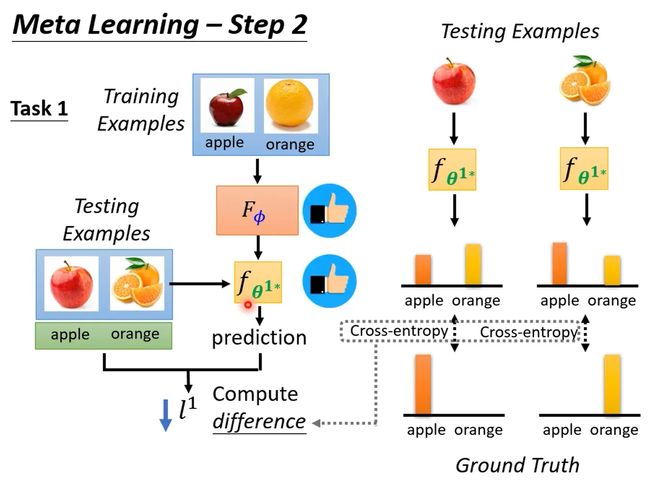
当然上述只是用在了一个任务上测试learning algorithm的效果,实际上应该还会给出好多个任务,每个任务虽然learning algorithm一样,但丢进去的资料不一样,产生的classifer也不一样。每个任务都重复上述步骤,并将最后的loss全加在一起让total loss最小。
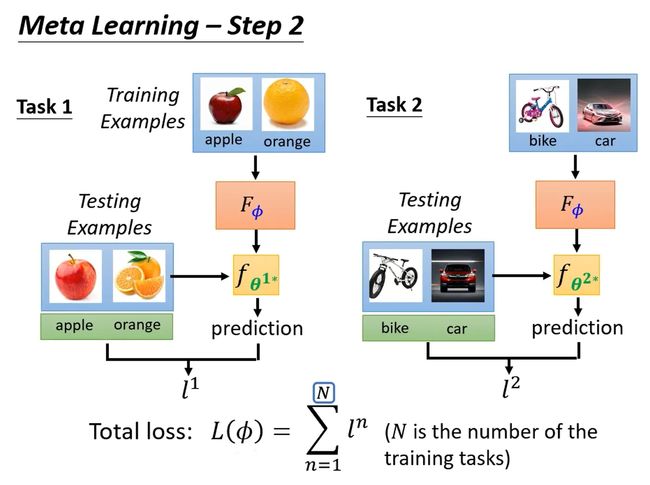
这里可能有人会有疑问,上述方法在训练过程中用到了testing dataset,这在训练中应该是不被允许的啊。但是meta learning其实是以任务为单位的,是用已知的有限个任务(训练集和测试集都可以当做已知)训练得到learning algorithm,然后用于其它未知的任务。
3. 找出让 L 最小的那个 ϕ∗ ,就得到了learning algorithm Fϕ∗
那如何得到 ϕ∗ 呢?如果明确知道L与 ϕ 之间的关系,就用梯度下降法;如果不知道关系,ϕ可能是什么network架构之类很复杂的东西
如果你在解一个optimization problem的时候、没有办法计算gradient、没法计算微分,用RL硬train,或者evolutionary algorithm(进化计算)硬做。
(什么时候L(ϕ)没法对ϕ做微分?取决于你的ϕ是什么,如果ϕ是离散的,比如说network架构几层,没法做小小变化,)

总的来说,meta learning的整体框架如下:
通过training task确定learning algorithm,然后用testing task验证learning algorithm是否有效。在testing task中,只需要很少的训练样本few-shot learning就可以完成网络的训练。
所以那些few-shot learning 的算法 通常就是用meta learning得到的。
testing task的training data在meta learning里面是不能碰的

Machine Learning VS Meta Learning
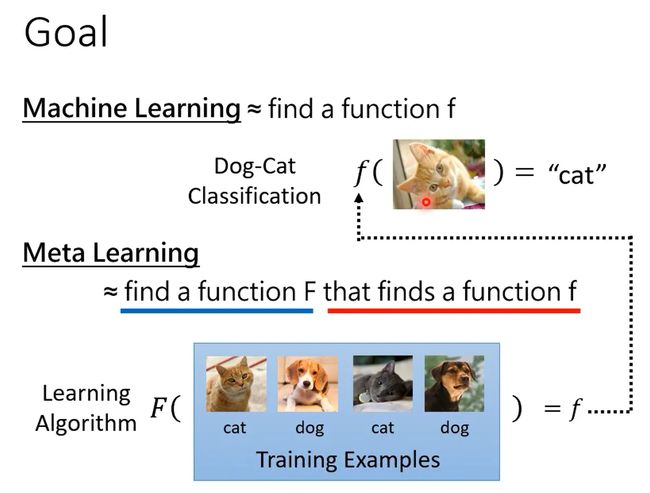
- 目标不同。machine learning的目标使找到一个function f,而meta learning的目标是找到一个F,这个F用于找f。
- 训练数据不同。
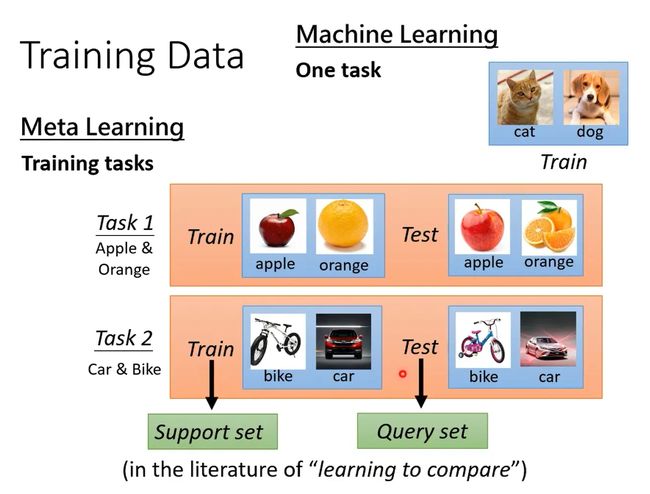
我们将只用一个任务内数据训练的过程称为Within-task Training,将多个任务训练过程称为Across-task Training。

对于验证过程,machine learning中的验证过程称为within-task Testing,meta learning中的验证过程称为Across-task Testing,meta learning中我们要测试的不是一个classify表现的好坏、而是一个learning algorithm表现的好坏,
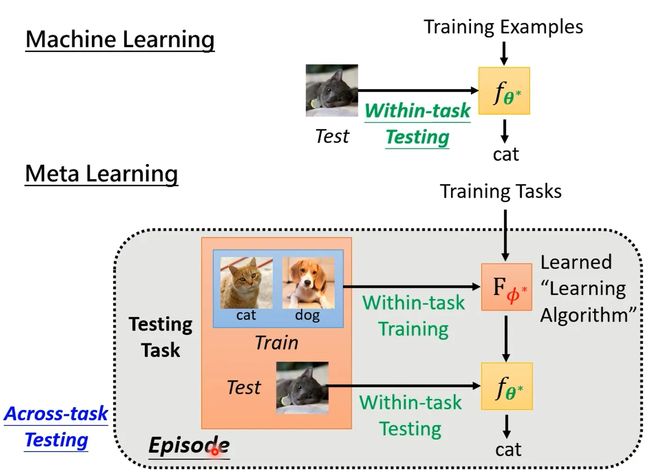
- Loss不同。machine learning是通过一个任务算出来的,而meta learning使用N个任务算出来的。
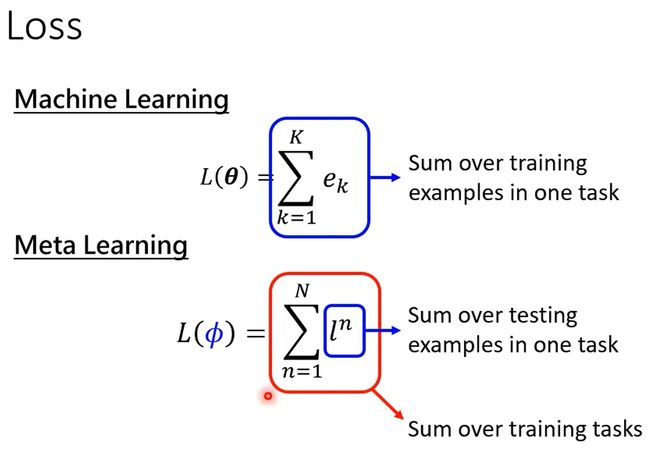
Meta learning training时,算 每个任务的loss,需要经过一个完整的episode(一次完整的训练和一次测试),
在Learning to initialize文献中(也就是非常知名的memo系列work),将Across-task training称为外循环(Outer Loop),Within-task Training称为内循环(Inner Loop),其实Meta Learning的计算量还是十分大的。
有些learning算法其实没有loop(用梯度下降 learning algorithm就是要反复跑 所以有很多loop)
刚才说的都是Meta Learning和Machine Learning之间的区别,那两者之间有什么联系呢?
比如,两者都有overfitting的问题,一种解决方案是增加多的训练资料,或者是data augmentation/ task augmentation处理。
另外Meta Learning 做optimization,假设一样用gradient descent,还是 要调参!但是调整完毕后可以一劳永逸,Machine Learning模型的参数通过learning algorithm就可以直接得到。
Machine Learning时 用development set来选模型,来决定比如说 network架构、调 超参数,

很多meta learning文献没有development set,但老师认为不对。
2021 - 元学习 Meta Learning (二) - 万物皆可 Meta_哔哩哔哩_bilibili
接下来 举一些实例告诉你说在meta learning里面什么东西是可以被学的:
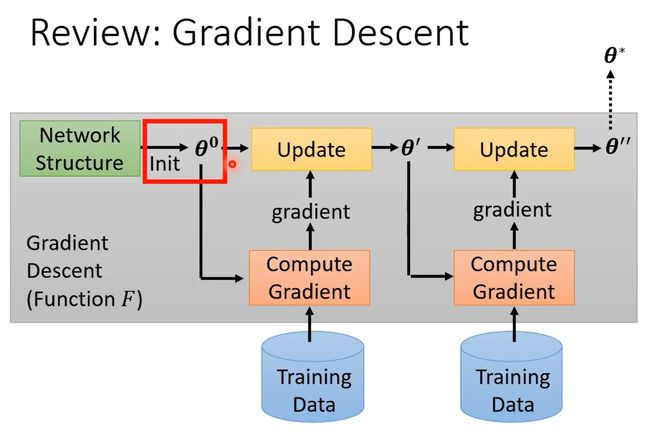
Learning to initialize
回想一下,梯度下降法(Gradient Descent)整个过程,首先初始化参数,是可以被train的,一般θ0是从某个固定的distribution里simple出来的,随机初始化。
我们也知道,好的初始化参数对最后的结果影响还是很大的,所以能不能用meta learning学习一组比较好的初始化参数。有一种方法叫做MAML,相关研究可以参考下面的文献:

最原版的MAML并没有很好train,train随机初始化参数也需要random seed,也需要梯度下降。
于是有了改进方法MAML++,可以减小训练难度。

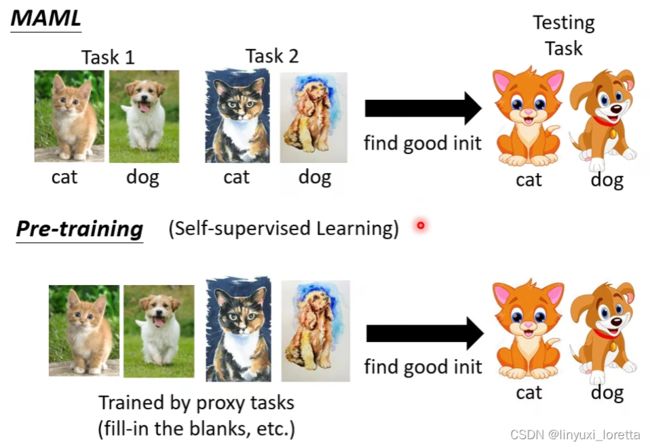
MAML与Pre-training(预训练)有什么样的差别呢?
Pre-training就是,将多个任务资料倒在一起训练找到一组好的初始化参数(multi-task learning),通常将预训练得到的模型准确率作为MAML的baseline。
如今做影像的自监督学习时,最流行的方法是contrastive learning(这个课程里面没有介绍),
过去自监督学习系列还不红时,另一种做pre-training 的做法
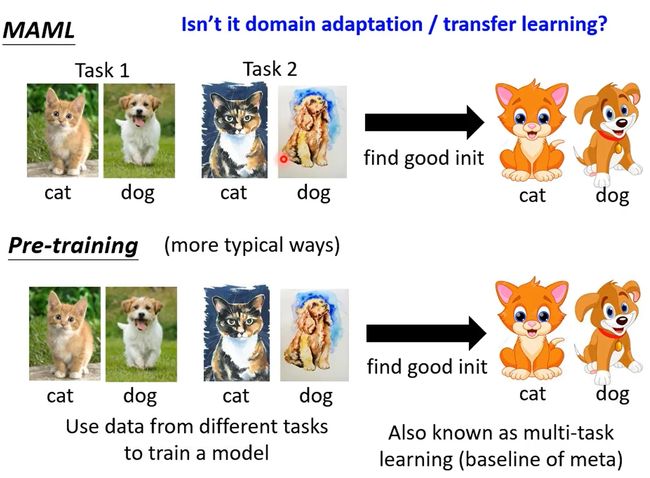
MAML vs pre-training: https://youtu.be/vUwOA3SNb_E
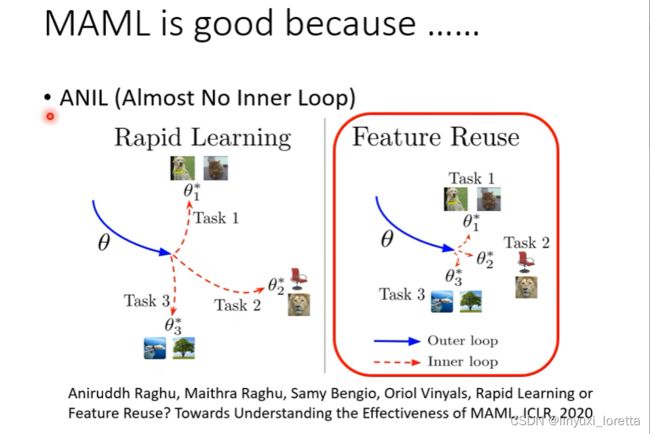
MAML为什么是有效果的?人们有两种想法,一种想法是通过MAML得到的初始化参数可以很容易的将参数收敛到对应任务中,另一种想法是MAML得到的初始化参数离每个任务对应最优值的参数很接近。下面这篇论文给出,想法二是MAML效果好的主导原因。同时这篇文章也给出了一种MAML的变形——ANIL。
MAML还有更多的变形,感兴趣可以看一下下面给出的相关视频:

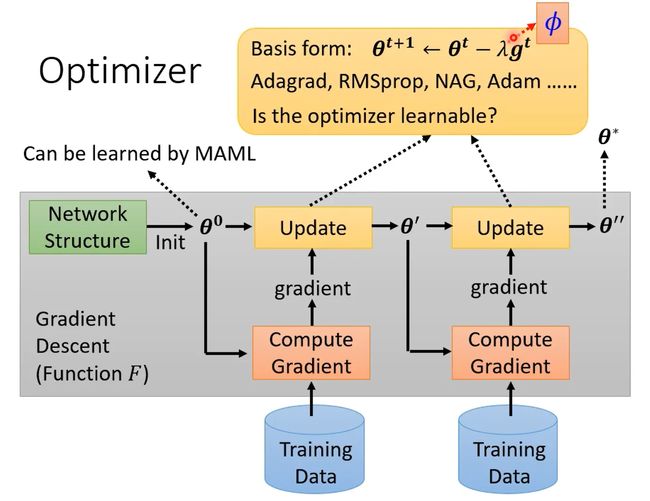
Optimizer
优化器中的参数也可以通过Meta Learning学出来,比如学习率等。
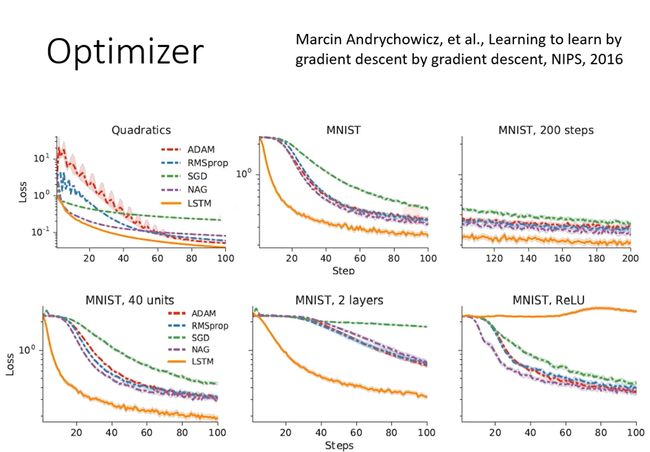
这里有一篇关于Meta Learning根据训练任务自动学习Optimizer的文章,训练方式类似于训练一个LSTM。利用学习到的学习率比直接手调的效果要好一些。这篇文章最后还给出测试任务对应网络结构改变或者激活函数改变,会对最后结果产生不同程度的影响。
Network Architecture Search(NAS)
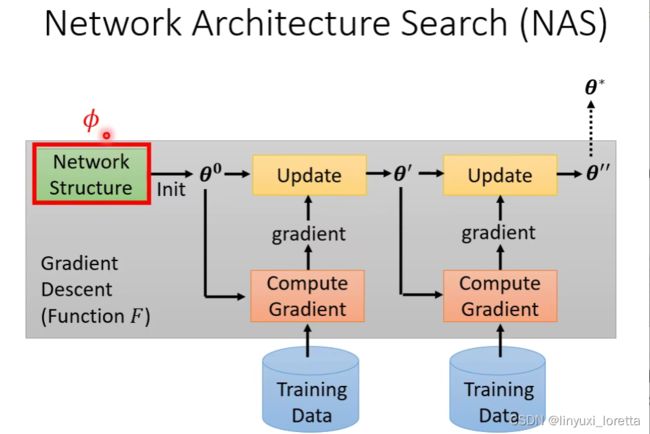
Meta Learning还可以用于寻找合适的网络结构。对于网络结构中的参数,由于大多是离散值,我们可能无法对其计算微分,因此可以采用RL硬Train出来(具体方法可以参考一下下面的文献)。具体来说,让agent的输出是网络结构参数,Reward就是-Loss。

利用 Reinforcement Learning学习网络结构的具体过程如下:
agent的训练过程可以类比RNN(因为是比较早的文章)。

除了使用Reinforcement Learning,还可以使用Evolution Algorithm,感兴趣的小伙伴可以看一下下面的文献:

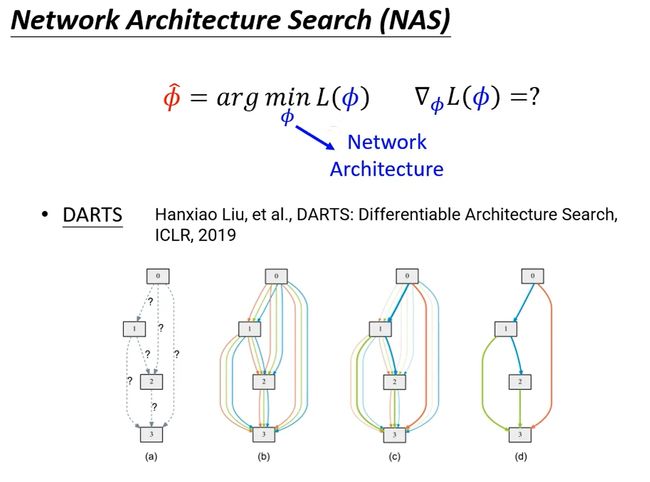
其实硬是把network architecture改成可以微分也是可以的,DARTS这篇文献就是介绍这种方法:
Data Processing
data augmentation的方法 ,现在你是用trial and error去试出来的,也是可以通过Meta Learning学出来的。比如数据增强的过程,可以通过学习的方式学出来,参考文献如下:

Sample weight strategy
另外还可以给不同的sample(样本)在训练时赋予不同的权重(weight),参考文献如下:

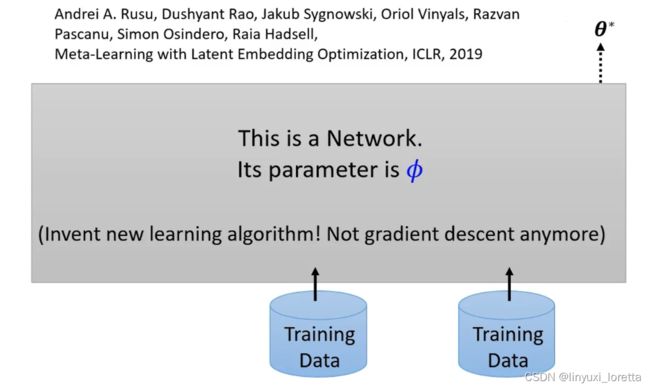
上面的方法都是基于Gradient Descent(梯度下降)再去改进,但是有没有可能抛弃梯度下降,给训练资料,然后直接输出network的参数,目前也有人在做相关的研究:
如果真的有这样一个network、那我们就可以说我们甚至让机器发明了新的learning algorithm

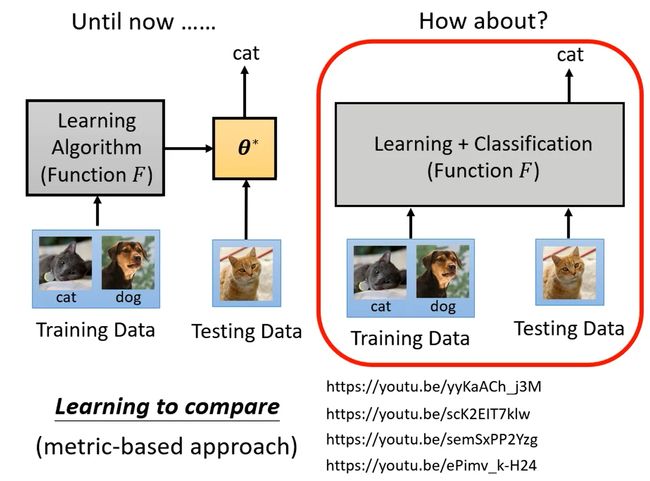
到目前为止,我们还是把训练跟测试分成两个阶段、我们所有模型建立的过程都是,先利用Learning Algorithm学出一个模型,然后用训练得到的模型用在测试资料上。有没有可能更进一步,直接将训练资料和测试资料都扔给一个Function,就可以直接根据测试资料输出对应的结果。
也就是我们不再有训练跟测试的分界、一个episode里面不再分训练跟测试、而是直接用一个network把训练跟测试这件事情一次搞定,
有一个系列的方法叫做Learning to compare,相关资料如下:
Application
关于Meta Learning是否真的有实际应用呢?
今天你在做meta learning的时候啊、最常拿来测试ma learning技术的任务叫做few shot的image classification。有个名词叫N-way K-shot classification任务,就是在每个任务中都有N个类,每个类有K个样本,比如下面这个水果分类(属于一个任务),就属于3-ways 2-shot任务:

上述任务有一个公共数据集——Omniglot,共有1623个字符,每个字符有20个example:


其实人在做few shot classification是非常厉害的
Meta Learning还可以应用于其他任务中,比如语音辨识、文本分类等等,如下:

今天在学界已经开始把meta learning推向更复杂的任务,让我们拭目以待,看看未来这个技术能不能够真的用在现实的应用上
2022 - 各种奇葩的元学习 (Meta Learning) 用法_哔哩哔哩_bilibili
meta learning vs. self-supervised learning
bert跟他的好朋友们, 他们做的事情其实是找一个初始化的参数

往往bert跟MAML 它们是可以互相相辅相成的
MAML有个重大弱点:用gradient descent方法learn初始化参数,但是梯度下降就需要初始化参数!

bert在实务上结果非常好,但有一个重大问题:learning gap
MAML跟bert同样是找初始化的参数,但是bert不能保证在下游任务一定会有好的表现。
MAML如果训练任务和测试任务,有接近的分布,
但是MAML自身训练量非常庞大,且需要准备训练任务 需要人工标注。

有非常多文章尝试把bert跟MAML结合在一起,这里举2个例子,一个例子做在 task -oriented semantic parsing 上(一个NLP任务)
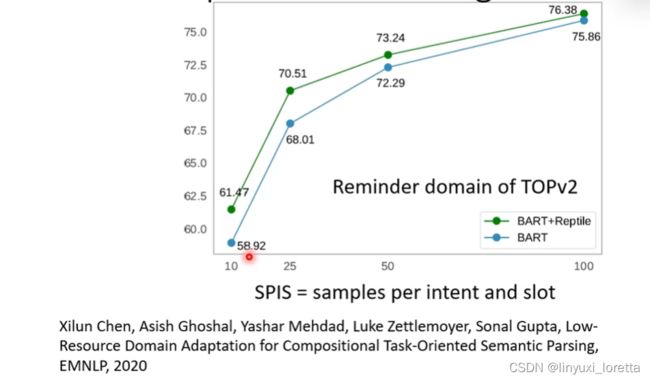
绿色线结果更好,尤其是训练资料特别少的时候。
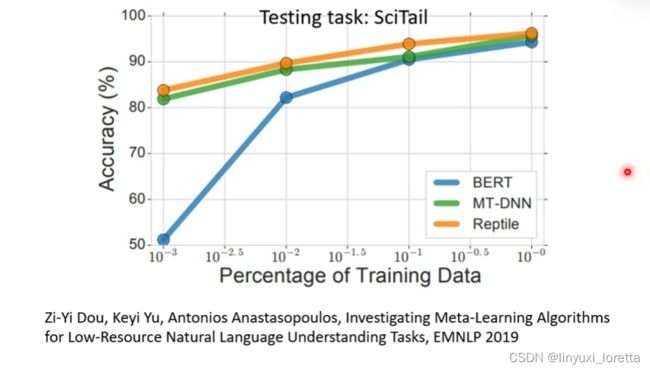
另一篇文章也说明了这个现象。
李老师最近写了一篇有关meta learning用在自然语言处理上面的overview paper, 统计了近3年相关的文章,特别是做MAML时都是怎么做initialization:

meta learning vs. knowledge distillation
模型压缩专题 里提到了knowledge distillation技术

问题:“ teacher”擅长教学?
那甚至呢有文献指出、在这个分类任务上做得特别好的teacher、它本身不见得是特别擅长教学的

我们可以引进meta learning的概念,让teacher学习怎么teach

要update teacher network,最终目标是要让student的结果变好,会不会很难学?
teacher net 的update,不一定要update一整个大模型的所有参数,比如有的文章里,只会update teacher net的output的temperature,这个 temperature到底要加多大呢、过去只能当做一个 hyperparameter
meta learning vs. domain generalization
最简单的是有一些但是不多的label data,很自然可以用meta learning解。meta learning特别擅长解few-shot learning的题目,
这里我们分享 怎么把meta learning用在domain generalization上面,即:我们对target domain一无所知. 我们没有target domain的data




但是meta learning本身也有可能会遇到需要做domain adaptation 和domain generalization的状况
我们需要做domain adaptation,是因为我们的训练资料跟测试资料有可能有很不一样的分布
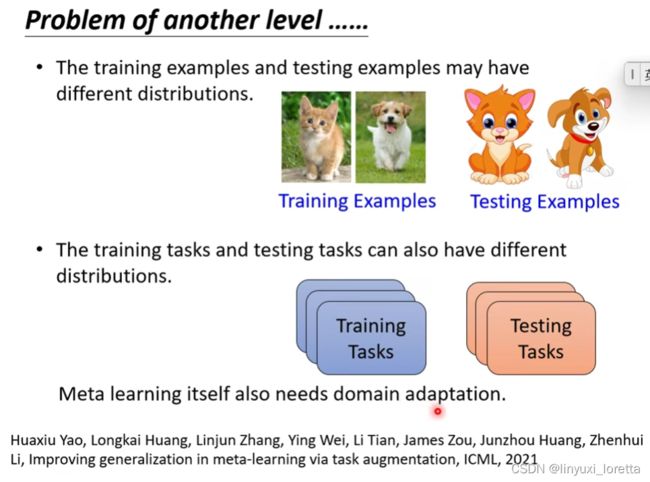
这是一个尚待研究的问题...
meta learning vs. life-long learning

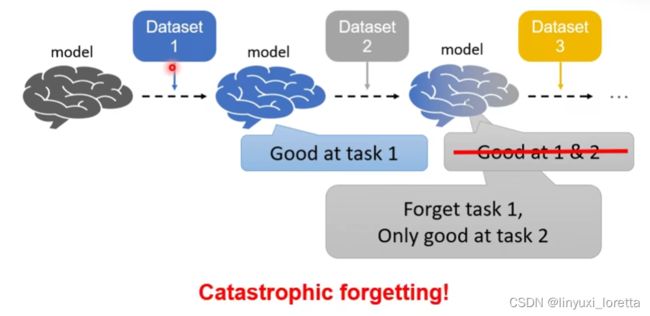
之前的课 我们已经讲过了一系列可以处理catastrophic forgetting的方法,那meta learning有没有可能强化这些方法呢
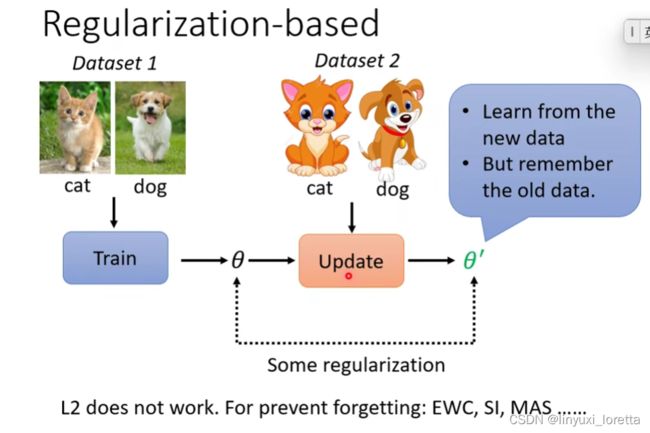
举例说明:meta learning怎么用在selective synaptic plasticity上, 这类的方法又叫做regulation base的方法

我们之前提过一系列regulation的方法,比如EWC、SI、MAS,但是这些方法他们是人所设计的,人设计了一些constraint
用meta learning来找一个比较好的learning algorithim,目标是避免catrophy forgetting
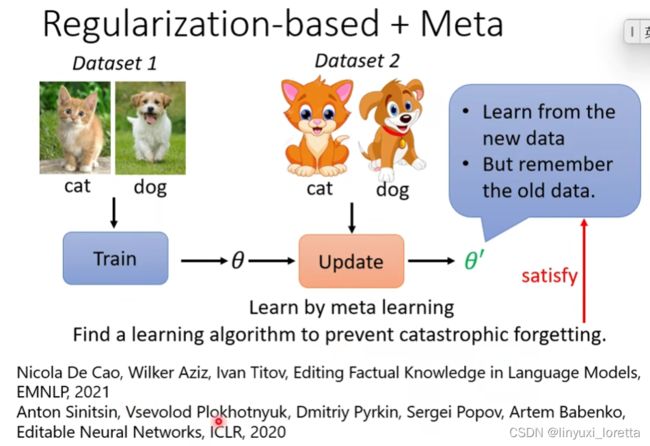
meta learning本身也可能遇到catrophy forgetting问题....



2022.6.27的opening,怎么把自监督学习技术用在语音上。

台智云