强化学习-把元学习(Meta Learning)一点一点讲给你听
目录
0 Write on the front
1 What is meta learning?
2 Meta Learning
2.1 Define a set of learning algorithm
2.2 Defining the goodness of a function F
2.3 Data sets for meta learning
3 Summary of the process of meta learning
4 Omniglot: Few-shot Classification
5 MAML
6 A Example
7 Parameter update
8 The difference between pre train, MAML and replile
9 Warning of MATH
0 Write on the front
Meta Learning翻译为元学习,本篇文章主要讲解什么是Meta Learning,元学习研究小白,若有不对,请各位大佬批评指正。
1 What is meta learning?
《强化学习-什么是强化学习?白话文告诉你!》《强化学习-你在游戏中对战的人机是如何对付你的!》这两篇主要讲了强化学习的内容,那么元学习又是什么呢?它和传统的强化学习或者说跟传统的机器学习又什么不一样的地方呢?
若我们把训练模型比喻成在学校学习,传统的机器学习学习的任务对应的是每个科目上分别训练一个模型,以后再碰到相同科目的东西,这个模型就能解决这个问题了。
但是元学习是培养学生的学习能力,即让学生学会学习,让学生以后碰到任何问题都能自己想办法学习它,给出模型,从而解决它。
那么在学校中,有很多同学会偏科,也有一些学霸,各科成绩都很好。
这是说的什么意思呢?
各科成绩好说明学生“元学习”的能力强。学会了如何迅速适应不同科目的学习特点,从而能够迅速学习,拿到不错的结果。
有偏科现象说明“元学习”能力比较弱,不会举一反三。
那么现有的大多是算法,都属于“偏科”的,一个算法在一个场景下得到的结果比较好,但是稍微换一个任务,就凉凉了。这显然在某些场景下是不好的。
传统的方法都是learning from scratch,一股脑的训练下去。
元学习是基于不同小任务样本来进行学习,以致于对不同类型的任务,它都能处理得更好。
2 Meta Learning
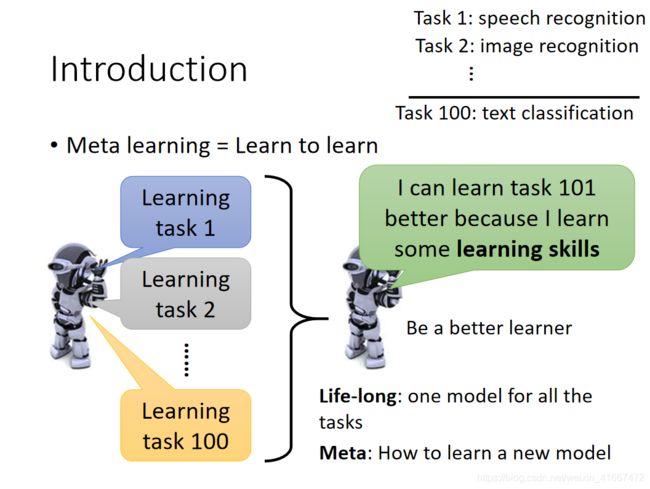
meta learning的核心就是让机器学会学习(learn to learn)
假如我们的机器之前学习了100个task,之后机器学习第101个task的时候,会因为之前学习的100个task所具有的学习能力,而让第101个task表现得更好。
什么意思呢,例如第一个任务是语音识别,第二个任务是图像识别,第一百个任务是文本分类,机器会因为之前所学到得任务,在处理第101个任务的时候(假如是商品分类)会因为前面100个任务积累的经验而表现的更好。
你可能问,这个和life long learning有什么区别吗!
相同之处是life long learning和meta learning都是要根据以往的task,希望对现在的task有所帮助
不同之处是但是meta learn所要求的是学习新的task时候有新的model,但是life long learning始终是一个模型。

传统的机器学习流程是:我们有多训练数据,经过学习算法,得到一些参数,这些参数实际上就是一个model(也就是上图中的f*),这个model就可以解决我们的问题了。
meta learning方法是:依旧给模型很多训练数据,我们将Learning Algorithm当作是一个F(function),我们需要F做的事生成另一个f(function),而这个f可以用来实现具体的任务(比如说影像识别)。我们meta learning的方法就是找到这个F。

machine learning和meta learning都是要找一个function,但是两者所要寻找的function是不相同的,前者寻找的是解决一个问题的f,后者寻找的是生成f的F。F的输入是训练数据,输出是解决一个小问题的f。
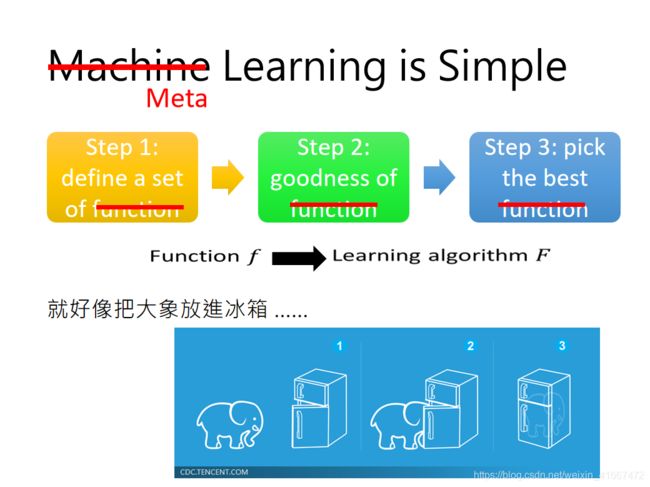
机器学习的方法可以简单理解为三步:
(1)找到一个f的集合 。(2)找到一个判别f的方法(loss function)。(3)在这个集合中寻找最好的f。
meta learning的方法也是三步:
(1)找到一个learning algorithm的集合。(2)之后寻找到一个判别learning algorithm好坏的方法 。(3)最后得到一个最好的learning algorithm做为F。
2.1 Define a set of learning algorithm
那说了这么多,具体的是哪些东西是meta learning具体做的事情呢?请看下图:
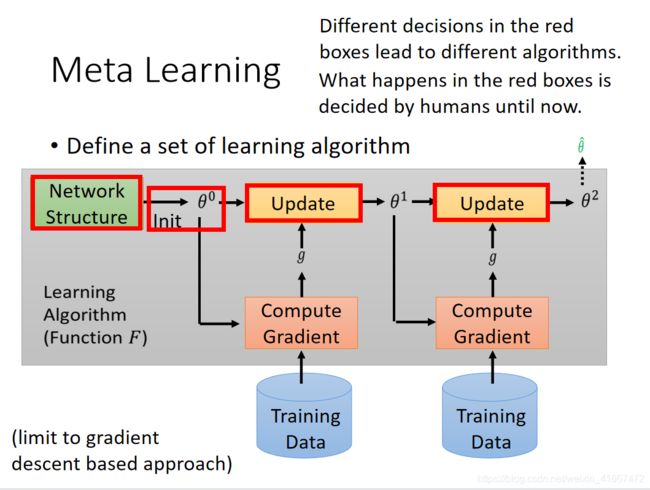
首先,我们先来搞清楚一个learning algorithm set是如何成型的。
传统的机器学习中:
先是定义了一个神经网络结构,之后初始化参数值,之后根据训练数据计算梯度,更新参数,最后得到最优的参数。
这个过程是我们机器学习的过程。在这个过程中,上图红色的格子都是人为设定的,网络结构的选择,参数的初始化,参数更新的方法,都是认为设计的,也就是这个过程中是人在告诉机器学习方法,当人不告诉它之后,它就凉凉了。
meta learning 中:
让这些部分由机器自己设计!参数的初始值能不能让机器自己初始化,假设机器自己初始化参数,机器自己选择更新方法,机器自己选择神经网络结构,这就是我们meta learning的learning algorithm set。
这样以来,机器遇到新的任务后,它就知道自己想出学习办法,从而完成学习任务。是不是觉得很牛!
2.2 Defining the goodness of a function F

那么这个算法的损失函数是如何来定义呢?这是个很重要的问题!
损失函数:
假如现在我们用一个learning algorithm F。首先用F进行猫狗分类器的学习,之后得到了一个f1,f1的训练数据进行测评,得到f1的loss function 为l1。
然后我们再用F进行苹果橘子分类器的学习,得到一个f2,f2的训练数据进行测评,得到f2的loss function 为l2。
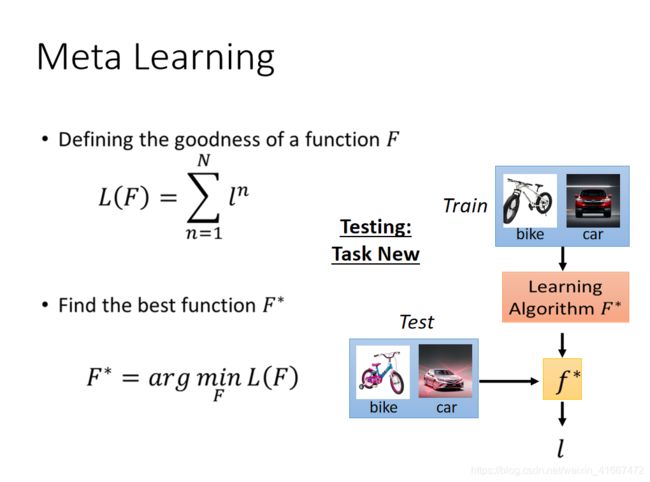
我们用F完成n个task,之后对每一个task求一个l。之后我们把所有的l都加在一起,就变成了我们最后的损失函数L。我们就是使用L来评估F的。
写成公式就是这样:

2.3 Data sets for meta learning
解决了损失函数以后,我们再来看看数据集应该是怎么样的:
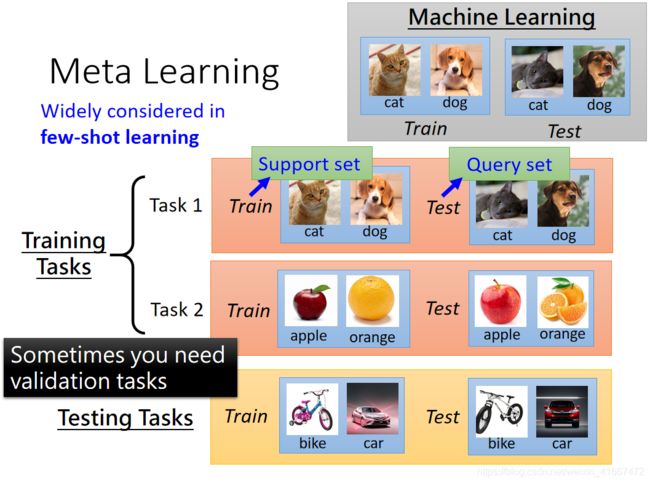
一般的机器学习任务是单任务的,所以数据集是一堆训练数据,和测试数据。
但是在 meta learning中是不可以这样来操作的。
因为meta learning的任务是多任务的,所以在这种情况下,我们需要做的是将很多的任务分为训练任务和测试任务,之后每一个小的任务都有训练数据和测试数据。
比如说一共有十个任务,我们将其中的八个作为是训练任务,剩余的两个作为测试任务,其中每一个任务都有自己的测试数据和训练数据。
以此来检测meta learning的学习能力。我们为了名字混淆,我们将每一个任务的训练数据称为support set,并且将每一个任务的测试数据称为query test。
注意这里好比把一个任务(任务有自己的训练集和测试集)当成了一条数据,如上图所示。
3 Summary of the process of meta learning
下面对meta learning的过程进行总结:
meta learning 过程:
先设定一个总得损失函数,L(F),其实就是每一个训练子任务得到的小loss function(也就是l)的总的值。之后我们用梯度下降的方法不断的更新F的参数,得到一个最好的F*,
之后我们将训练好的F*放入到测试任务集中进行测试,比如第一个测试任务是一个自行车汽车识别器,我们将小的训练数据放入到F*中,之后得到一个分类器f,之后我们将测试数据放入到f中,得到最终的loss,作为这次测试的结果。
4 Omniglot: Few-shot Classification


训练meta learning时候用到的数据集是一个叫做Omniglot的数据集,这里面一共有1623种不同的标签,每一个标签有20个例子,20个例子都是这个标签对应的不同的人写下的例子。
可以去这里下载:https://github.com/brendenlake/omniglot
这个数据集究竟应该如何去使用呢?
首先将整个数据集分为很多的N-ways K-shot classfication的任务。N-ways就是分为N类,K-shot就是每一类种有K个样本。就是一个总共类别有N类,每一类有K个样本的分类器。
举个例子:20ways1shot就是总共20类,每一类有1个样本的分类器。上图就是一个20ways1shot的分类器,训练集就是20类,每一类就只有一张图片的图片集。测试集就是一张图片。
在我们使用Omniglot数据集的时候,我们先将其中的1623类拆分为训练集和测试集,之后我们再在训练集中采样出N类,每一类采样K个样本作为我们的一个分类任务,当然我们的训练集可以被拆分组合为很多分类任务的。
我们测试集是在测试类别中采样出n个,每一类蔡阳初k个样本作为我们的测试分类任务。当我们的F在测试集中被训练好以后,我们就开始将其放入到test中进行测试。
5 MAML

以上是两种meta learning的方法,分别是maml和reptile。前者是2017年的paper,后者是2018年的paper。
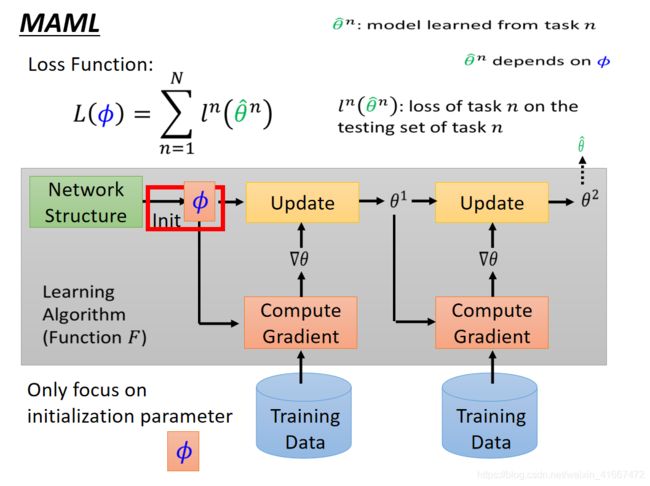
MAML想要解决的问题其实是想让机器自己学会初始化参数。
我们用![]() 来表示第n个任务训练出来的初始化参数,然而每一个
来表示第n个任务训练出来的初始化参数,然而每一个![]() 都是由这个初始化参数
都是由这个初始化参数 训练的来的。
训练的来的。
之后用的出来的![]() 去跑对应任务的数据,得到的loss function就是
去跑对应任务的数据,得到的loss function就是![]() ,把所有任务的loss function ln(
,把所有任务的loss function ln(![]() )加在一起就是最后的损失函数L。
)加在一起就是最后的损失函数L。
meta learning如何更新参数:
对损失函数求参数的偏导数,之后用梯度下降的方法更新参数。

很多人看到meta learning的更新参数方法以后
心想:这不就是迁移学习吗?!!!!
其实是有区别的。
迁移学习中的model pre-training(假设task2的训练集太小不好训练,我们将和task2相似的task1作为先导数据集,进行训练,将训练的结果作为task2的初始化)。
那么这两种方法有什么区别呢?
meta learning中的参数θ是模型刚刚生成的![]() ,但是model pre-training的参数就是当前使用的模型的参数。
,但是model pre-training的参数就是当前使用的模型的参数。
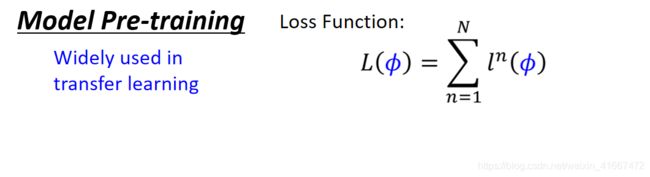
如果你还不明白,我们来看图说话:

MAML方法中在意的不是参数在task中的表现如何,而是在乎在task中经过训练得到的θ的表现究竟如何。
比如上图中参数fai在task1和task2中都不是最好的参数,但是却是一个比较好的,就是因为参数fai可以在各自task中训练从而得到最好的参数![]() 。可以在task1中经过训练,得到
。可以在task1中经过训练,得到![]() ,在task2中经过训练,得到
,在task2中经过训练,得到![]() 。所以这就是一个好的。
。所以这就是一个好的。
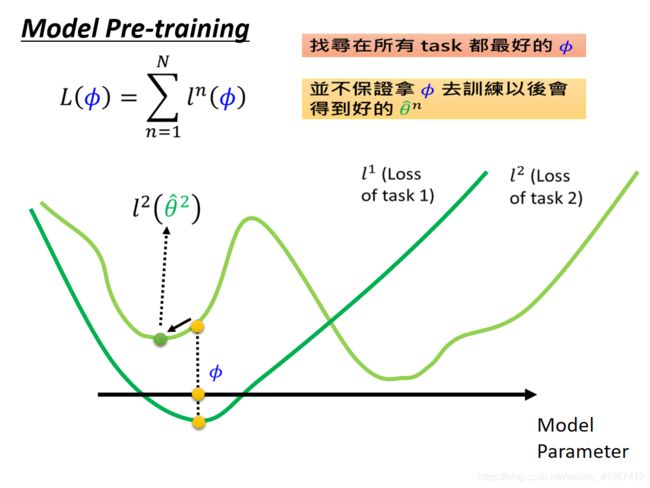
在model pre-train的方法中,我们想要的好的参数fai就是在当下任务中表现好的参数,
比如这个在task1中表现还不错,在task2中表现也比较良好,这就是一个比较好的参数。但是这个参数经过训练以后得到的θ却不一定比较好
所以model pre-train的方法比较看重的是当前的表现,而MAML则更看重未来的表现。
总之:

Model Pre-training方法想要得到的参数fai就是在任何task上都表现良好的参数。但是MEML想要得到的参数是在任务task中经过训练集训练所能得到的比较好的参数。
Model Pre-training看重的是现在的表现,但是Meml看重的是未来的潜力。
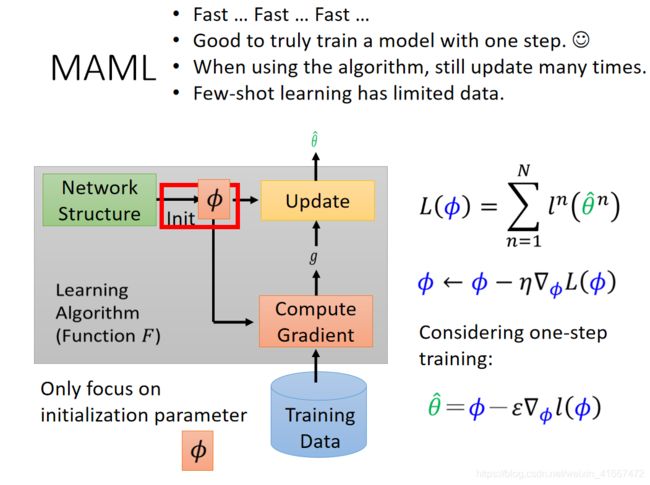
我们通常希望MAML可以做到的是:得到的参数在子任务task中只更新一次就得到最好的θ。那么为什么要这么做呢!
1,我们的meta learning有很多的任务,假设每一个任务都要更新很多次参数的话,会很慢,所以我们为了追求速度,就让模型只更新一次就好。
2,我们本来的想法就是希望参数仅仅更新一次就得到这个子任务task的参数![]() 。
。
3,当我们训练的时候,我们仅仅是让其更新一次,但是当我们真实测试的时候,我们往往可以更新无数次
4,我们本身就是没有多少训练集,所以我们往往希望可以一次更新就得到参数。
6 A Example

我们使用一个sin函数y=asin(x+b),之后我们从这个函数曲线采样出k个点,之后再用这些点来还原出我们的函数方程式。每一个task就是通过sample出的点还原最开始的方程式。
我们可以不断的改变a和b的值,实现多个不同的任务,从而跑我们的mate learning。
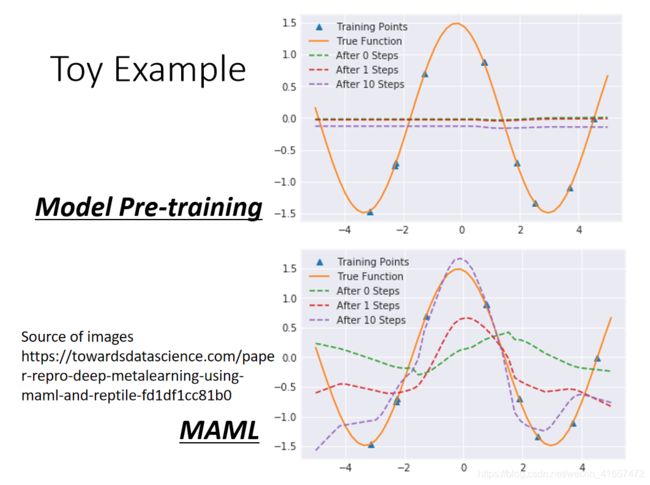
model pre-training的方法:
这个方法追求的是最开始的参数就可以适应不同的task。我们的task都是sin函数,sin函数都是在1到-1之间不断的波动的,如果要是一开始就适合所有的task的话,那么初始函数就是一条水平线。训练几次以后,仍然是水平线。
MAML方法:
maml一开始的参数是一条波浪线,在训练一次以后大概可以知道哪里是波峰,训练十次以后,波峰和波谷几乎可以发现。
7 Parameter update

如上图所示,初始化参数是,之后梯度下降一次更新到θ,之后再更新一次用于修改,的方向和第二次更新的θ的方向是相同的。
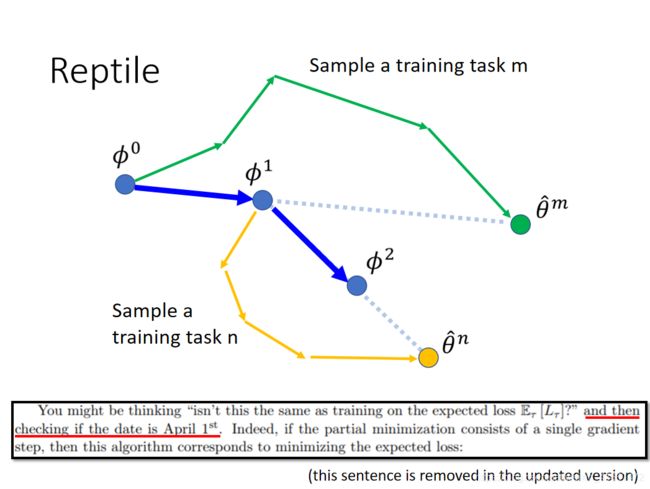
reptile的方法是:
初始参数的初始值是,之后我们采样出一个TASKm用来更新,之后我们更新了很多步(不同于MAML的单次更新),更新到θm的时候,我们就让沿着直线的方向进行更新,
之后我们再采样出一个TASKn,依旧是经过很多步的更新,之后我们继续沿着直线的方向更新。
8 The difference between pre train, MAML and replile

pre-train:就是θ一次训练以后的方向g1就是更新的方向。
maml:是θ第二次更新的方向,我们将其作为更新的方向。
reptile:是两次方向的向量和,当然,我们不仅仅可以更新两次,可以更新很多次,之后很多次的和方向就是最后的方向。
9 Warning of MATH

其推到如上。初始化参数将影响过程中的各个参数的值,进而影响最终值。因此根据链式法则有公式如:
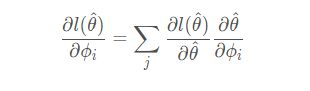
下面对上式进行推导:

而在原始论文中,为了精简计算,没有算二次微分,用 0、1 替代微分值。

以上是简化过程。
写在后面:数学和英语是笔者以前比较”害怕“的东西,最近在文章逐渐将一些名词用英语表达,也逐渐加入数学公式。希望对自己的数学和英语能力有所训练。
参考:
- Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017: 1126-1135.
- Nichol A, Schulman J. Reptile: a scalable metalearning algorithm[J]. arXiv preprint arXiv:1803.02999, 2018, 2: 2.
- 李宏毅机器学习课程。
- 【李宏毅深度学习】meta learning
于2021年3月17日