一文尽览!弱监督语义/实例/全景分割全面调研(2022最新综述)
后台回复【ECCV2022】获取ECCV2022所有自动驾驶方向论文!
论文链接:https://arxiv.org/pdf/2207.01223.pdf
汽车人的碎碎念
分割,作为最基础的视觉感知任务和自动驾驶底层的感知模块,承担着很重要的作用。但逐像素的标注需求饱受诟病,相比于目标框标注,属实是太太太太慢了。今天分享一篇上交投稿TPAMI的文章,论文很全面的调研了广义上的弱监督分割算法,又涵盖了语义、实例和全景三个主流的分割任务。特别是基于目标框的弱监督分割算法,未来有很大的研究价值和落地价值,相关算法如BoxInst、DiscoBox和ECCV2022的BoxLevelset已经证明了,只用目标框可以实现可靠的分割性能。论文很赞,内容很扎实,分割方向的同学一定不要错过!
摘要
近几年,分割技术获得了长足的进步。然而,当前主流的分割算法仍然需要依赖大量的标注数据,而逐像素标注十分昂贵、费时且费力。为了减轻这一负担,过去几年研究人员越来越关注构建标签高效的深度学习算法。本文全面回顾了标签高效的分割算法。为此,本文首创了一种分类法,根据不同类型的弱标签(包括无监督、粗监督、不完全监督和噪声监督)提供的监督信息和分割问题的类型(包括语义/实例/全景分割)来进行归纳。进一步,本文从一个统一的角度总结现有的标签高效分割算法,讨论如何弥补弱监督和全监督预测之间的差距——目前的算法大多基于启发式先验,如跨像素相似度、跨标签约束、跨视图一致性、跨图像关系等。最后,本文讨论了未来可能的研究方向。
简介
本文旨在为标签高效的深度分割算法提供一个全面的综述。这些方法专注于不同的任务,本文将任务定义为:语义、实例和全景分割三个方向,且具有某种类型的弱监督信息。为了针对不同的问题归纳这些方法,需要解决如下两个问题:
-
1)如何为这些方法建立分类法?
-
2)如何从统一的角度总结这些方法中使用的策略?
本文从弱标签的类型着手,如下图进行分类。该分类主要依据弱标签类型辅以分割类型进行构建:横轴和纵轴分别表示不同类型的弱监督信息和分割任务;每个交叉点表示带有对应弱标签信息的分割任务,其中实心点表示已有相关工作进行探索,空心点则表示没有。
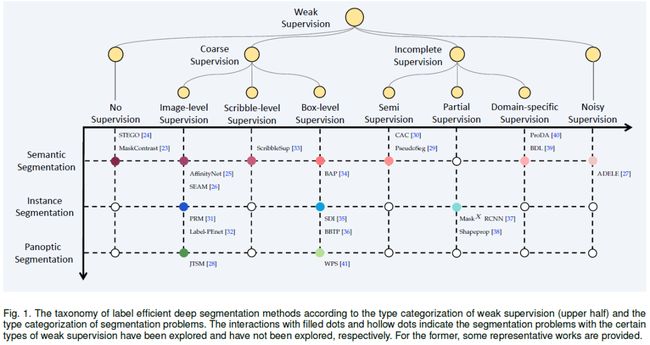
弱监督的类型具体包括:
-
无监督:所有训练图像均无任何形式的标注,如下图(a)所示;
-
粗监督:所有训练均有标注,但标注是粗糙的,即无像素级别的标注,如下图(b)所示。依据粗标签的类型,进一步可细分为image-level的标签、box-level的标签和scribble-level的标签;
-
不完整监督:训练图像只有部分有逐像素标注,如下图(c)所示。不完全监督进一步可细分为:半监督,即部分图像有逐像素标注,其余图像没有标注;domain-specific监督,即源域有标注,目标域无标注;偏监督(也叫部分监督,partial supervision),即部分类别有逐像素标注,其余类别有粗标签,如box信息。
-
噪声监督:所有训练图像都有逐像素标注,但存在标注错误,如下图(d)所示。

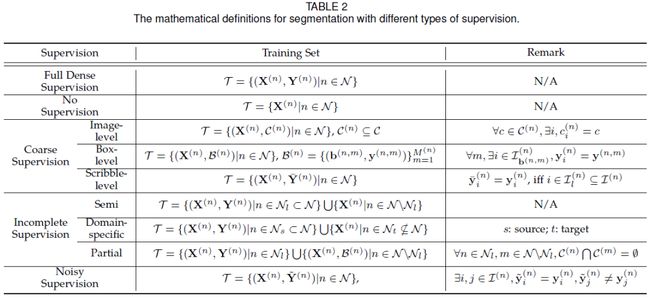
下表总结了相关方向的代表性算法:
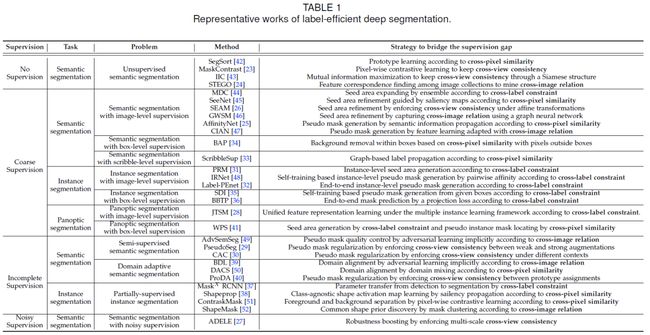
问题定义如下表所示:
无监督
无监督(语义)分割的早期阶段,主要是通过人工设计的图像特征进行聚类实现分割,如K-means和Graph Cut [55]等,用于将图像划分为多个具有高自相似性(high self-similarities)的部分。最近,随着无监督特征表示学习的快速发展,特别是MoCo [56]、SimCLR [57]、BYOL [58]等算法,无监督密集特征表示学习极大的促进了无监督分割的发展。无监督分割的目的是,对于没有任何标注的给定图像,网络需要学习密集的特征图。一个好的网络学习得到特征图有如下特性:来自相同语义区域(object/stuff)的像素具有相似的特征表示,而来自不同语义区域的像素则具有不同的特征表示。学习良好的密集特征图可以直接促进分割模型的训练。
由于没有监督信息,实现无监督分割的关键是如何获取监督信息。当前的工作试图根据一些启发式先验来生成密集的自监督信息,例如跨像素相似性、跨视图一致性和跨图像关联(cross-image relation)。
跨像素相似性
跨像素相似性(Cross-pixel similarity)表示具有高度相似线索(如颜色、亮度和纹理)的像素可能属于图像中的同一语义区域。由于该先验源自感知分组原理,因此几乎所有的无监督语义分割算法都基于此原理生成密集的自监督信息。
Hwang等[42]提出首篇用于语义分割的无监督深度学习方法SegSort。其首先使用轮廓检测器[59]、[60],通过聚类生成密集的自监督信息,即伪片段(pseudo segment)。然后,提取每个伪片段的原型,即片段内像素的均值。SegSort的训练目标是将伪片段内像素的特征表示拉向该伪片段的原型,并将其与其他伪片段区分开来。
跨视图相似性
跨视图相似性(Cross-view consistency)指一个目标在不同视图中应表现出一致性,是无监督语义分割的另一个常用的先验。该先验广泛应用于基于对比学习的方法[56]、[57]和基于孪生结构的[58]、[61]、[62]无监督表示学习,并启发了无监督密集表示学习。
跨视图一致性中的对比学习
在对比学习中,给定图像X,首先生成图像的两个视图,其中一个视图作为query ,另一个作为positive key 。对比学习的优化目标是最小化如下的对比损失:
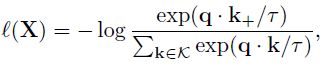
上式也被称为InfoNCE损失。对比学习的两个关键是:1)如何生成不同的视图;2)如何确定positive/negative pairs。
Pinheiro等[63]首次将对比学习扩展到密集表示学习。他们提出了View-Agnostic Dense Representation (VADeR) [63]算法,一种像素级对比学习方法,下图对比了VADeR和图像级对比学习。
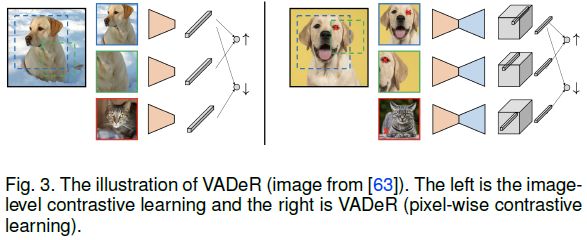
Gansbeke 等人[23],遵循VADeR [63]的思想,提出了用于无监督语义分割的MaskContrast算法,其结合了SegSort [42] 和对比学习。此外还通过数据增强为每个图像生成两个视图(一个查询视图和一个关键视图)。其他的工作如[53、66]可以具体参考相关论文。
跨视图一致性中的孪生结构
基于孪生结构的无监督表示学习也生成了一幅图像的两个视图,但它是在没有负样本的情况下最大化两个视图之间的一致性,如下图所示。通常,一个视图的表示是在线更新的,而梯度流不会传到孪生网络中[62]。此外,跨视图的一致性通常由两个视图之间的集群分配关系(cluster assignment relation)表示[61]。
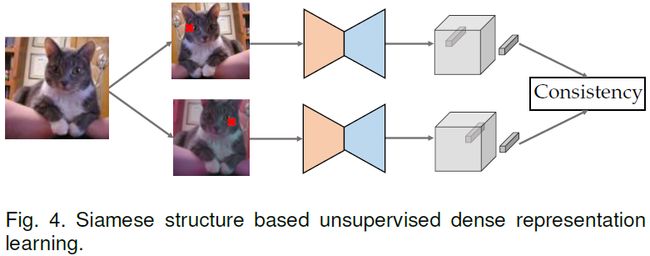
Ji等[43]探索了基于孪生结构的密集表示学习在无监督分割中的应用。提出了Invariant Information Clustering(IIC),它最大化了来自不同视图的相邻像素之间的互信息,以确保跨视图的一致性。互信息是基于聚类计算的,即分别来自两个视图的两个相邻像素的联合分布,定义为它们在一系列聚类质心上的相似性分布。其他的工作如[54]可以具体参考相关论文。
跨图像关联
跨图像的同一类别目标具有类似的语义关系。然而,由于没有监督信息,如何在图像中挖掘相似语义的像素比较困难。为了解决这个问题,目前的方法是使用从无监督预训练中学习到的特征,如MoCo [56] 和BYOL [58],作为建立跨图像关联的基础,然后对特征进行细化。
Zhang等[67]提出了一种像素级对比学习方法,通过隐式涉及跨图像关联进行无监督语义分割。其对无监督预训练学习到的训练图像的特征进行聚类,并能够根据聚类结果为所有训练图像生成逐像素的伪标签,伪标签则用于在对比学习中选择positive/negative pair。其余工作如[24]可以参考具体论文。
讨论
无监督语义分割最近成为了一个很有前途的方向,顺应了无监督密集表示学习的浪潮。[66] 的实验结果表明,基于无监督语义分割学习得到的网络,之后进行全监督微调可以得到更好的结果。比如,基于CP2 [66]预训练的DeepLabV3 [9]性能为77.6% mIoU,优于全监督的76.0%。
尽管如此,针对无监督语义分割的密集表示学习仍处于初步的探索阶段。与图像级表示学习不同,密集表示学习需要一些区域先验来指导像素之间的关系,即它们是否属于同一语义区域。这与无监督语义分割的目标基本相同。因此,无监督语义分割存在先有鸡还是先有蛋的情况。如何在初始阶段引入更准确的区域先验,或者如何在学习过程中对其进行细化,值得未来进一步探索。
粗监督
粗监督可以是image-level(类别标签)、box-level(类别+bbox)、scribble-level(标注像素子集)级别的监督信息。具有粗监督信息的分割也被称为弱监督分割。虽然更广泛的意义上,弱监督也可以指其他类型的分割,如不完全分割。但在本节中弱监督分割特指粗监督分割。
如图2和表2所示,根据粗略标注的类型,粗监督可以是imagelevel(每张训练图像只提供类别标签)、box-level(除了类别标签外,还包括object bounding box) 为每个训练图像注释)或涂鸦级别(每个训练图像中的像素子集被注释)。具有粗监督的分割在文献中通常也称为弱监督分割。虽然在更广泛的意义上,这个术语也可以指其他类型的弱监督分割,例如不完全监督,我们根据本节宝贵的文献专门使用它来指代粗监督分割。
图像级别的监督
语义分割中的图像级监督
首先回顾一下使用图像级监督实现语义分割的方法。这个问题的难点在于图像级监督和像素级监督的差距太大了。前者用于训练分类模型,而后者则用于输出object/stuff的掩码(mask)。
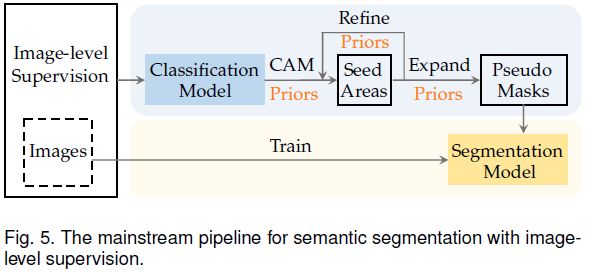
为了弥补这种监督信息上的差距,如上图所示,研究人员遵循两阶段的范式。第一阶段使用图像级标签训练的分类模型生成每张图像的密集伪标签,然后第二阶段基于伪标签训练语义分割模型,利用种子区域(seed areas)生成伪标签的示意图如下图所示。由于伪标签不可避免的存在噪声,因此利用伪标签训练分割模型可以等效为带噪声监督的分割问题。所以本节主要分析第一阶段的相关算法。
第一阶段的目标是生成高质量的伪标签,包括两个步骤:
-
1)根据分类模型得出的信息,为每个训练图像生成一些种子区域(seed areas)。这一步通常是通过计算分类模型的类激活图(CAM)[69]、[70]、[71]来实现的;
-
2)然后第二步,通过将语义信息从种子区域传播到整个图像来生成伪标签(密集标签);
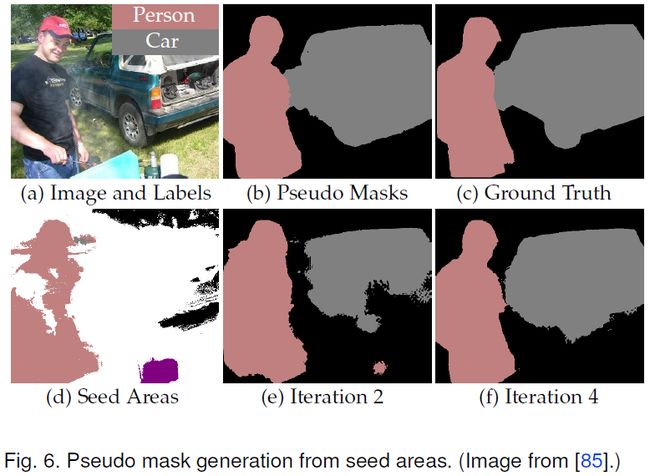
这个过程通常是迭代的,包括分割模型的self-training。现有方法尝试优化种子区域以使其更完整和准确,或者在种子区域的基础上生成更可靠的伪标签。下表对相关算法进行了总结。
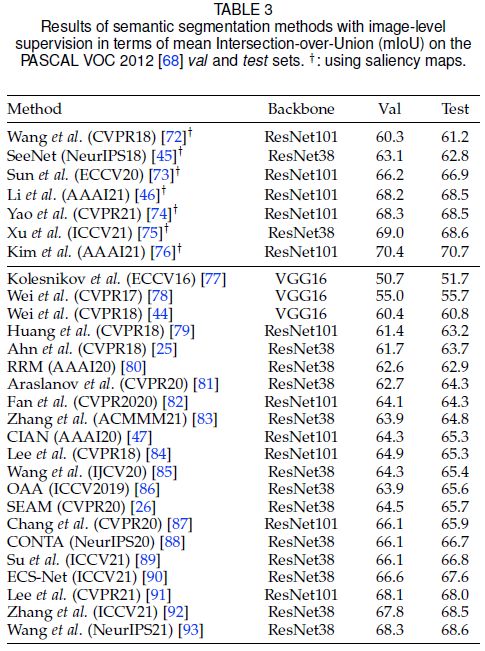
Seed area refinement by cross-label constraint
所有图像级监督的语义分割算法都使用了类激活图 (CAM) [69]、[70]、[71]。CAM本质是利用交叉标签约束(cross-label constraint)的先验,来根据分类模型提供的信息定位图像中的种子区域。然而,CAM存在两个局限性:1)不完整性:CAM 通常无法覆盖目标类的整个语义区域;2)冗余:一个CAM可能与其他类的区域重叠。为了解决这些问题,研究人员设计了如下几种改进CAM的策略,为种子区域的细化生成更好的类CAM。
-
Expanding by ensemble:由于CAM通常无法覆盖目标类的整个语义区域,因此直观的策略是通过不同CAM的集合来扩展种子区域。常见的算法有[44、84、86];
-
Re-finding by erasing:另一个直观的策略是擦除当前的CAM,然后强制分类模型重新寻找其他区域以形成新的CAM。新旧CAM的集成可以扩展种子区域以覆盖目标类更完整的语义区域。常见的算法有[78、90、94];
-
Discovering by optimization:除了融合不同的 CAM,还可以通过鼓励分类模型在优化过程中挖掘更大的区域来发现种子区域。常见的算法有[87、91、93];
-
Reasoning by decoupling:CAM与非目标类区域重叠的原因,可能是存在共现类(co-occurrence classes),例如“马”和“人”经常同时出现。共现类误导了分类模型。相关研究有[88、89]。
Seed area refinement by cross-pixel similarity
“擦除”框架可能会误导种子区域逐渐扩展到语义错误的地方。为了解决这个问题,一些工作利用跨像素相似的先验来指导种子区域的扩展。这可以通过利用saliency map[99]来实例化,以确保扩展到具有相似语义的区域。
Hou等[45] 提出了自擦除网络 (SeeNet),这是首篇尝试使用saliency map[99] 来指导种子区域细化的工作。saliency map随后被广泛使用[75、76]。
Seed area refinement by cross-view consistency
一些工作提出使用跨视图一致性来提高种子区域的质量,因为跨视图一致性可以促进从同一图像的不同空间扰动获得的CAM之间的语义一致性 [26]、[92]。
Wang等[26]设计了一个用于种子区域细化的孪生网络。孪生网络包含两个具有不同数据增强的分支,其为每个输入图像增加了额外的仿射变换。孪生网络的目的是尽可能保证从两个分支计算的CAM是一致的。
Seed area refinement by cross-image relation
跨图像关联通过鼓励具有semantic co-occurrence的不同图像之间的像素级交互来增强种子区域生成的鲁棒性。
Sun等[73] 提出了两个neural co-attentions来互补地捕获具有semantic co-occurrence的每对图像之间的跨图像语义相似性和差异。一个是co-attention,旨在帮助CAM覆盖属于同一类别目标的互补部分,另一个是contrastive co-attention,旨在帮助CAM区分属于不同类别目标的语义。
Pseudo mask generation by cross-pixel similarity
伪标签通常以迭代方式生成,即从种子区域开始,交替描述当前伪标签(由种子区域初始化),然后使用self-training学习的分割模型更新伪标签。跨像素相似度的先验被广泛用于伪标签的描述,其中的关键是如何衡量像素之间的相似度。相似度可以基于低级特征(例如颜色和纹理)[72]、[77]、[79]、[80] 或高级语义[25]、[83]、[85]进行判断。
具有低级信息的相似度学习:Kolesnikov等[77] 提出了从种子区域生成伪标签的三个原则:1)仅使用高置信度的伪标签进行训练;2)更新后的伪标签应与对应的图像级标签一致;3) 约束更新的伪标签以匹配目标边界。这三个原则在后续工作中被广泛采用[72]、[77]、[79]、[80]。
具有高级特征的相似度学习:相似度也可以通过学习得到的特征之间的相似性来衡量。Ahn等[25] 提出AffinityNet,来学习由种子区域的语义标签监督的像素级特征提取器。训练后的 AffinityNet用于构建像素到像素的语义相似度矩阵,该矩阵进一步使用random walk [103]来生成伪标签。
Pseudo mask generation by cross-image relation
跨图像关联也对相似性学习有益,Fan等[47] 构建了一个跨图像关联模块 (CIAN),用于从具有semantic co-occurrence的图像对生成伪标签。在每对图像中,一张图像作为查询图像,另一张作为参考图像。查询图像的特征图由参考图像的特征图根据两者之间的逐像素相似性进行调整,从而产生更完整和准确的伪标签。
实例分割中的图像级监督
如下图所示,类似于图像级监督语义分割的策略,相关的实例分割算法也需要生成伪标签,然后训练分割模型。但伪标签是实例级的(语义分割是stuff级)。实例级伪标签可以通过:
-
1)根据跨像素相似度结合self-training来挖掘实例级种子区域(下图灰色线);
-
2)根据跨标签约束进行端到端训练(下图蓝色线)。
下表中总结了相关算法。
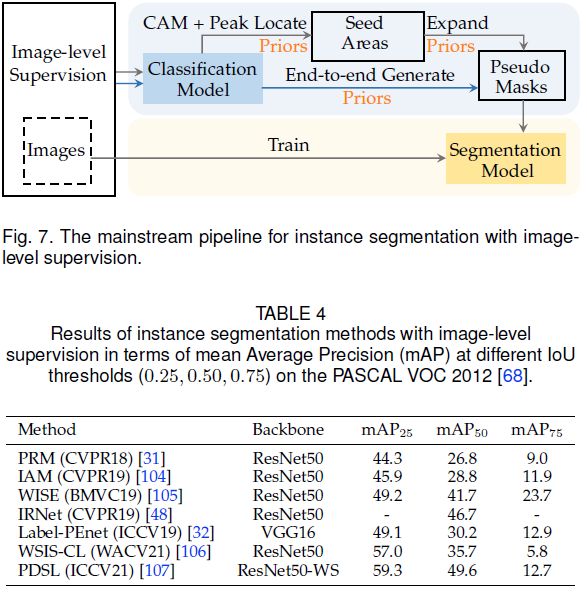
Instance-level seed area generation
利用peak locating [31]得到实例的种子区域。PRM [31]是第一个通过引入峰值响应图来解决此任务的工作。分类模型中的高置信度响应(峰值)区域暗示了属于该实例的可能位置。种子区域的峰值被一个可学习的kernel逐渐合并成几个峰值,每个峰值都对应一个实例。如下图所示,峰值响应图是通过反向传播得到的。

Instance-level pseudo mask generation
Expounding by self-training:从实例级种子区域生成实例级伪标签通常涉及self-training。WISE[105]和IAM[104]是基于PRM [31]实现该任务的工作。WISE选择PRM输出的局部最大值作为伪标签来训练实例分割模型。
Generating by end-to-end training:上述方法包含多个离线阶段,还有一些端到端的方法,它们根据跨标签约束直接将图像级标签转换为实例级伪标签。Ge等[32] 提出Label-PEnet,以在线和coarse-to-fine的方式将图像级标签转换为像素级标签。Label-PEnet设计了一个级联管道,由四个并行模块组成,即分类、目标检测、实例细化和实例分割模块。
全景分割中的图像级监督
图像级监督的全景分割方案尚未得到广泛探索。目前已知的只有[28],其提出一个联合thing-and-stuff挖掘 (JTSM) 框架,其中mask-of-interest pooling旨在为任意类别的segments生成固定大小的像素精确特征表示。根据交叉标签约束,thing和stuff的统一特征表示能够通过多实例学习将像素级伪标签连接到图像级标签。伪标签由Grabcut [1]根据跨像素相似度进行优化,并用于训练全景分割模型。
目标框级别的监督
语义分割中的目标框监督
Box比分类标签提供了更多的监督信息,因此缩小了定位目标的搜索空间。使用box监督进行语义分割的核心挑战是如何区分边界框内的前景和背景。由于带标注的边界框与类CAM map的作用相似,如下图所示,所以一般包含如下两个步骤:
-
1)根据跨像素相似度从边界框中挖掘伪标签;
-
2)基于伪标签训练分割模型。
下表总结了相关算法。
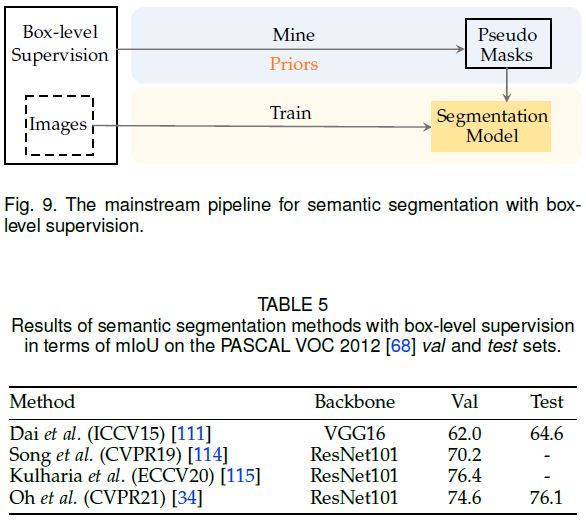
Dai等[111]首次进行尝试,他们提出了一种交替更新伪标签和分割模型的方法。具体来说,作者首先采用 MCG [112],一种无监督的region proposal方法,为每张图像生成约2000个候选区域。接着重复执行以下三个步骤:
-
1)使用分割模型预测每个候选区域的语义标签;
-
2)对于每一个带标注的bounding box,选择与真值重叠最大且类别一致的候选区域作为伪标签;
-
3)利用伪标签更新分割模型。
其他工作如[34、114、115]可以参考对应论文。
实例分割中的目标框监督
使用box实现实例分割比使用分类标签更容易,因为box已经提供了实例的大体位置。剩下的问题也是如何区分box内的前景和背景。如下图所示的解决方法:
-
1)根据跨标签约束在box内生成伪标签,然后进行self-training,如下图灰色线;
-
2)直接利用跨标签约束结合特定损失函数进行端到端训练,如下图蓝色线。
下表总结了相关算法:
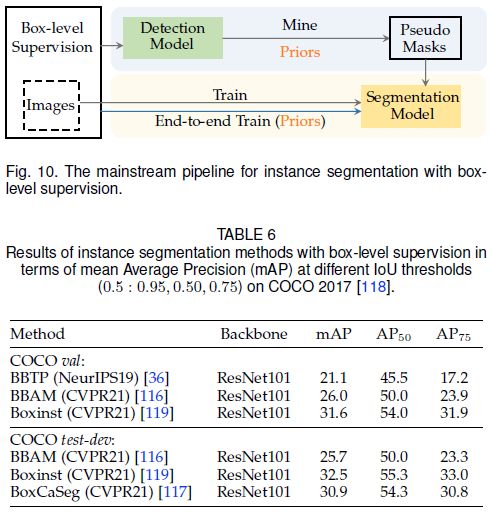
Mask prediction by self-training
首篇工作是SDI[35]。对于每个给定的box,SDI使用Grabcut [1]生成初始伪标签,之后进行self-training并迭代优化伪标签的质量,最终输出预测结果。还有一些工作如BBAM [116]可以参考相关论文。
Mask prediction by end-to-end training
BBTP [36]和 BoxInst [119]是两种端到端训练的实例分割方法。这两种方法都设计了一个投影损失来直接实现跨标签约束,如下图所示。投影损失保证了box与预测mask沿其四个边的投影之间的一致性。缺点也很明显,可能导致mask是一个矩形。因此,BBTP和Boxinst 还提出了pairwise loss,它们分别根据空间位置和颜色定义了跨像素的相似度。
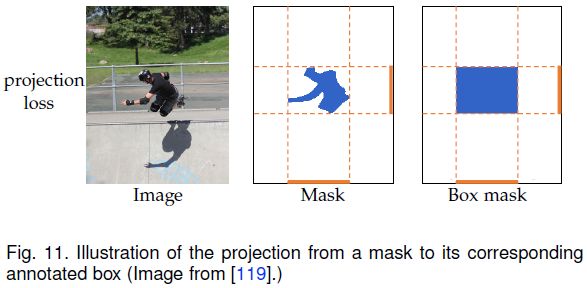
全景分割中的目标框监督
相关探索比较少,WPS [41]是唯一一篇。WPS [41]首先使用Grad-CAM [70]获得前景和背景类别的heatmap,然后使用 Grabcut [1]从heatmap中定位每个实例的伪标签。
涂鸦级别的监督
涂鸦即仅提供一小部分像素的标注,也可以当做是一种种子区域。下图展示了涂鸦监督下的语义分割的主流范式。解决这个问题的关键是如何将语义信息从稀疏的涂鸦传播到所有其他未标记的像素上。当前的方法通过利用图像的内部先验来实现这一点,即跨像素相似度。下表总结了相关算法。
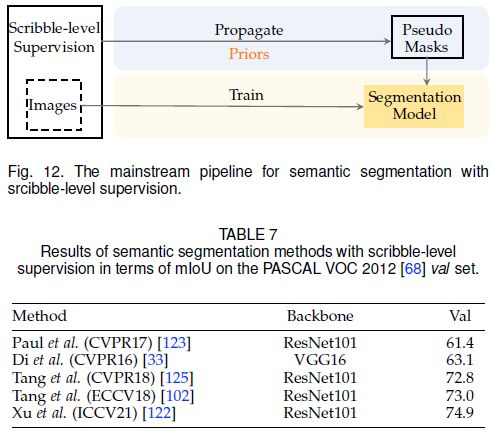
Di 等[33]首次通过graph model将信息从涂鸦传播到未标记的像素。graph model建立在超像素上[120],其中节点是超像素,边缘表示相邻节点之间的相似性,相似性通过颜色和纹理等低级外观线索来衡量。进一步通过交替方案联合优化了图模型和分割模型:固定分割模型,利用multi-label graph cuts solver [121]为图模型中每个未标记节点分配语义标签,生成伪标签;基于伪标签更新分割模型。此外还有[122,123,124]等相关工作。
上述方法都需要一个额外的模型来生成伪标签。还有一些方法可以通过设计损失函数直接优化分割模型,如[102、125]。
讨论
粗监督降低了对逐像素标注的需求。利用粗标注的主要流程是多阶段的:1)通过传播或挖掘从种子区域生成伪标签;2)基于伪标签训练分割模型。当提供相对精细的种子区域时,如目标框或涂鸦级注释,粗监督分割的性能可以比肩全监督。然而,基于CAM的算法不适合小目标和带孔洞的目标。对于这个问题,端到端的方法可能是一条路,值得进一步探索。
不完全监督
不完全监督可分为 :
-
1)半监督;
-
2)特定领域监督;
-
3)部分监督。
因此,这三种弱监督的分割分别称为半监督分割、域自适应分割和部分监督分割。
半监督
语义分割中的半监督
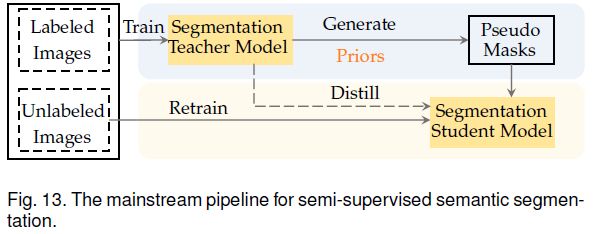
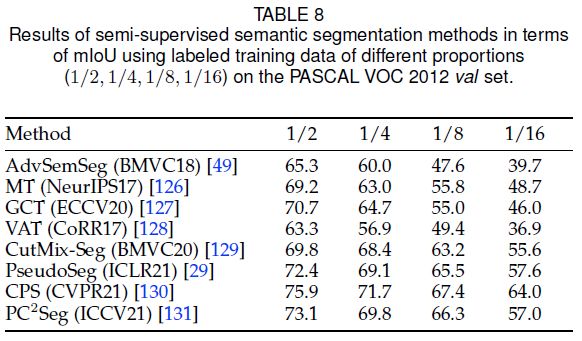
半监督指部分图像带有逐像素标注,其余图像则无标注。半监督语义分割的目的是利用大量无标签数据提升分割性能。最常见的是self-training,如上图所示。首先使用带标注的图像训练模型,然后预测无标签图像的伪标签,接着一起训练分割模型。伪标签不可避免的存在噪声,因此当前的半监督语义分割方法方案有两种:1)根据跨图像关联改进伪标签以隐式提高其可靠性;2)根据跨视图一致性显式引入额外的监督来进行正则化。下表总结了相关算法。
Pseudo label refinement for self-training
直观地说,伪标签的可靠性可以通过预测置信度来确定。现有方法通过迭代进行self-training或忽略低置信区域的方法来提升伪标签的质量。相关算法有[49、132、133].
Pseudo label regularization by cross-view consistency
伪标签正则化可以从无监督密集表示学习中受益,因为它们都旨在训练无标签图像上的分割模型。因此,孪生结构和对比学习也被用于半监督语义分割,以确保同一图像在不同视图下的伪标签之间的跨视图一致性。
基于孪生结构:下图展示了几种典型的孪生结构。GCT [127]利用两个相同结构但初始化不同的分割网络,分别从无标签图像的两个不同视图计算对应的分割概率图。概率图的一致性作为额外的监督信息。其他工作如[129、29、130]可以参考相关论文。
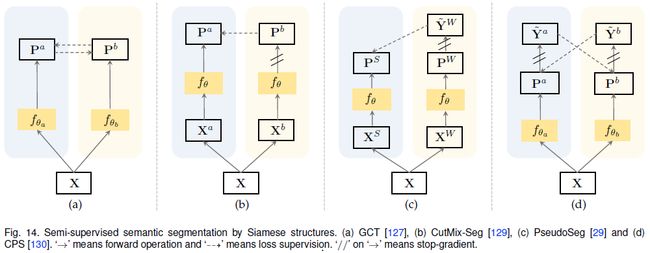
基于对比学习:Zhong等[131]利用逐像素对比学习来促进中间层的特征学习,相关工作还有[30]。
域适应分割
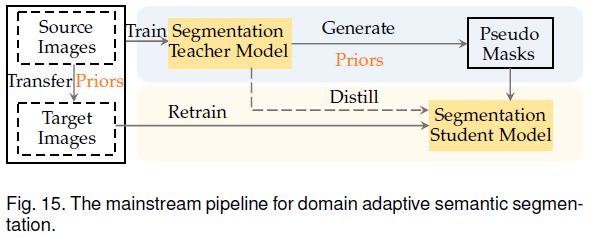
域适应分割指的是,源域有逐像素标注,而目标域则没有,且目标域与源域存在一定的差异(domain gap)。目标是使用源域数据训练的分割模型可以更好地泛化到目标域上。域自适应语义分割本质上类似于半监督语义分割,唯一的区别是标注图像和无标注图像之间是否存在domain gap。如上图所示,域自适应语义分割的主流范式包含一个额外的步骤:缩小域差距。这个额外的步骤可以通过对抗学习、域混合或伪目标域上的mask质量改进来实现。下表总结了相关算法。
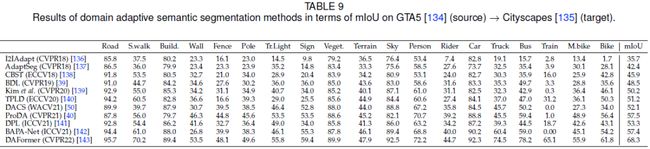
Adaptation by adversarial learning:对抗学习用于在图像空间或特征空间中对齐源域图像和目标域图像,生成式对抗网络 (GAN) [144] 比较擅长这事。相关算法可以参考[39], [136], [137], [141]。
Adaptation by domain mixing:另一种缩小域差距的策略是通过基于混合的复制粘贴来混合来自不同域的图像[145]、[146]。
Adaptation by pseudo mask quality improvement:由于域间隙,在目标域图像上生成的伪标签通常质量不高。这种伪标签质量的改进过程通常涉及一些先验,例如跨像素相似性和跨视图一致性[40], [138], [139], [140], [142]。
部分监督
实例分割中的部分监督
部分监督(也叫偏监督)的基本设置是,目标类别分为两个不相交的部分:基本和新颖,两个部分都包含box信息,但只有基本类别有逐像素标注。部分监督可以理解为半监督分割的一种变体。
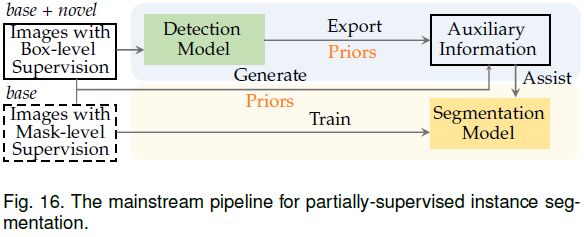
直观地说,这项任务的难点在于对新类的box信息和逐像素预测之间的监督差距。如上图所示,现有的方法主要遵循先检测后分割的范式,如Mask R-CNN [147],并探索如何利用相关先验从检测模型中提取辅助信息来提升新类别的分割性能。下表总结了相关算法。
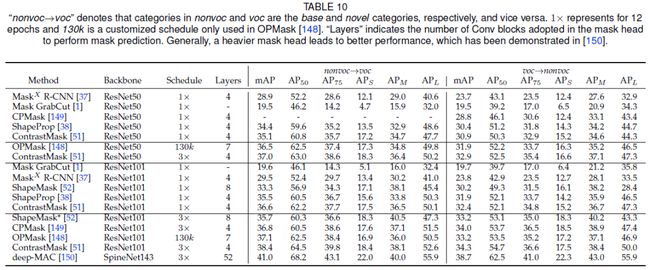
Auxiliary information from cross-label constraint
从box信息中,可以利用跨标签约束的先验提取两类用于分割模型训练的辅助信息。一个是框的类别标签和分割mask之间的连接;如CAM [69]、[70] 中所探讨的;另一个是框位置信息和分割Mask [148]之间的连接。相关的工作还有[37、148]。
Auxiliary information from cross-pixel similarity
部分监督的一个重要目标是探索基本类和新类之间与类别无关的共性,可用于提高新类别的特征识别能力。从低级(颜色、纹理)或高级(语义关系、相似度)信息中利用跨像素相似性的先验是实现这一目标的途径。相关工作有[38、149、51]。
Auxiliary information from cross-image relation
Kuo等提出了ShapeMask [52],通过探索跨图像关联中常见的形状先验来解决部分监督实例分割,因为来自不同图像中相似类别的目标应该具有相似的粗略形状。通过对基本类别的实例标注进行聚类获得的形状先验,可以进行线性组装,然后泛化到不同的类别,从而帮助分割头逐步细化预测结果。
Auxiliary information from a larger segmentation model
Birodkar等提出Deep-MAC [150],其从一个新的角度研究了部分监督的实例分割,即分割头的capacity。Deep-MAC发现更强大的分割头可以消除新类别的监督缺失造成的差距,Deep-MAC用更强大的网络(如例如 Hourglass-100)替换了Mask RCNN中的原始分割头,显著提升了分割性能。
讨论
不完全监督分割减少了对逐像素标注训练图像数量的需求。解决这个问题的策略主要包含两个方向:1)将利用标注数据训练的分割模型迁移到未标注数据上;2)在未标注数据上生成密集的自监督信息,类似于无监督分割的相关策略。最先进的半监督语义分割算法(75.9 mIoU)基本与全监督模型持平(76.0 mIoU)。然而,当标注数据和无标注数据之间存在较大的分布差距时,分割的性能还比较受限。因此,如何设计更有效的随分布变化的策略,以便充分利用大量无标注数据仍然值得进一步探索。
噪声监督
语义分割中的噪声监督
标签歧义通常存在于分割标注中。鉴于伪标签不可避免地存在一些噪声,如 [27] 中所指出的,利用伪标签训练分割模型本质上是一个有噪声的语义分割问题。
Liu等[27]观察到一种现象,即随着训练的进行,分割模型倾向于记住标注中的错误。为了防止对错误的过拟合,他们设计了一种自适应的早停机制并强制执行多尺度跨视图一致性,以提高对标注错误的鲁棒性。李等[151]提出通过不确定性估计来发现噪声标签[152],根据跨视图一致性,计算不同尺度下预测结果之间的像素方差来实现。
结论和讨论
标签高效的分割研究已成为计算机视觉中的一个活跃领域,因为实用。逐像素标注是出了名的昂贵且耗时。近年来,已经有很多算法用于解决不同类型的弱监督分割问题。实验结果表明,这些标签高效的分割方法取得了长足的进步。然而全监督性能上限还有很大的提升空间。
挑战
1)The supervision gap
标签高效分割的主要挑战是密集预测和不完整标签之间的监督差距。尽管已经有很多的算法尝试解决,但如何弥合监督差距仍然是一个悬而未决的开放问题。此外,现有相关的分割模型在扩展到大量目标类别的能力方面受到限制。为了应对这些挑战,需要做出更多的努力,包括更强大的主干,并从其他模式引入额外的监督信息,例如文本监督。
2)The openness issue
标签高效分割问题与开放域(或开放词汇)识别密切相关,新概念可以通过文本或少量示例等来描述。在这种情况下,一个重要的问题在于处理识别的开放性,特别是如何设计一个范式来将新概念添加到现有的识别系统中?仅仅依靠文本指导(例如,利用来自预训练模型的文本嵌入)可能是不够的,但从Web数据中搜索和提取知识是一个很有前途的解决方案。
3)Granularity vs. consistency
标签高效分割旨在涵盖更多视觉概念。然而,随着概念数量的增加,识别粒度和一致性之间存在权衡。也就是说,当将细粒度的类别/或目标添加到字典中时,算法可能无法产生一致的识别结果,例如,当目标较小时,算法可能会选择预测粗粒度标签或部位,因此最好为这种情况调整评估方式。
潜在的研究方向
1)Zero-shot segmentation with text supervision
互联网上有大量带有文本监督的图像,这使得学习大型模型(如 CLIP [153])可以桥接视觉表示和文本监督。这可能是一种实现零样本分割的方法,即为看不见的目标类别学习分割模型。一些工作做了一些尝试[154]、[155]、[156]、[157]、[158]。通常,他们通过将像素嵌入与相应语义类的文本嵌入对齐,进而将分割模型推广到看不见的目标类别。这是一个值得探索的有前途的方向。
2)Label-efficient segmentation by vision transformers
现有的标签高效分割方法主要使用卷积神经网络。最近Transformer大放异彩,相关算法也有很多[165]、[166]、[167] ,[168],这要归功于它们在建模长期依赖方面的强大能力。更重要的是,由先进的无监督表示学习方法(如 DINO [169]、BeiT [170]、MAE [171] 和 iBoT [172])预训练的视觉Transformer的自注意力图包含了丰富的图像分割方面的信息,这提供了一种在没有任何监督的情况下生成可靠伪标签的潜在可能。这在未来也会是一个有趣且开放的方向。
3)Unexplored label-efficient segmentation problems
诚然,目前还存在一些尚未探索的标签高效分割问题,例如基于噪声标签的实例分割和基于不完整标签的全景分割。原因可能是缺乏数据集或足够复杂的模型来获得合理的结果。随着标签高效分割技术的发展,这些研究空白将在未来得到填补。
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D感知、多传感器融合、SLAM、高精地图、规划控制、AI模型部署落地等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D感知、多传感器融合、目标跟踪)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!