零样本学习
前言
这篇博客为阅读论文后的总结与感受,方便日后翻阅,查缺补漏,侵删!
- 零样本学习研究进展
- 零样本图像识别。
概念
零样本学习,零样本学习迁移学习的一种特殊场景,在零样本学习的过程中。训练集和测试集之间没有交集,需要通过训练类与测试类之间的知识迁移来完成学习。使在训练类上训练得到的模型能够成功识别测试类输入样例的类标签。更一般地说,零样本学习如果模型在训练过程中,只使用训练类的样本进行训练,且在测试阶段可以识别从未见过的测试类样例,那么就认为该样本实现了零样本学习。
迁移学习
迁移学习简单来说,就是将一个学习任务A建立的模型可以迁移到学习任务B中,这里举个例子:人在实际生活中,有很多迁移学习,比如学会了骑自行车,就比较容易学会骑摩托车,学会了C语言,在学一些其他的变成语言就会简单的多。
应用:
在机器视觉领域,你如果想实现一个应用,而不想从零开始实现权重,比方从随机初始化开始训练,实现最快的方式通常**是下载已经训练好的权重的网络结构,**把其当做预训练迁移到你感兴趣的新任务上,这样可以节省大量的训练时间。如下图:

如上图所示,已经有一个模型,该模型输入 x x x最后经过Simoid处理可以输出猫和狗的概率,但现在,我们有一个新任务分类:猫、狗、猪其他动物。这时候,我们不需要重新训练模型的参数,只需要训练模型最后一层并训练改层的参数。

当然这不是绝对的,如果我们的训练集比较充分,可以选择从零开始训练我们的模型参数,这样分类效果可能更高,但如果我们的数据集较少,也可以选择冻结模型参数的一部分,训练模型的其他参数,实现特定任务的分配。
零样本的基本思想
零样本的学习利用训练集中的样本,和样本对应的辅助信息(例如文本描述或属性特征等)对模型进行训练,在测试阶段利用训练过程中得到的信息,以及模型的测试类辅助信息对模型进行补足。使得模型能够成功的对测试集中的样例进行分类。我的理解,在训练样本中假设有个牛的样本,我们可以利用改样本集对神经网络模型进行训练,我们知道神经网络可以将输入样本压缩为隐空间的一个向量表示,如果在训练过程还得知,对应得隐空间的第 i i i维度值表示待识别动物的体重,第 j j j维度值表示待识别动物鼻子的长短,当我们如果规定,在隐空间对应的牛和训练样本距离很近,且第 j j j维数值较大,我们有理由相信待识别的图像为大象图像。
零样本学习结构示意图
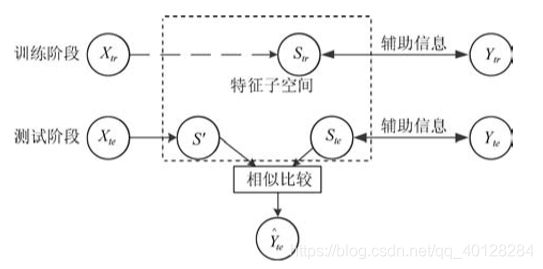
零样本学习的相关领域
- 单样本学习
单样本学习是与零样本学习最为相似的研究领域,单样本学习希望识别模型可以实现仅 使用某些对象类极为少量,(100以内,甚至只有1个)的训练样本,就可以对这些类的样例进行识别,但是:单样本学习模型较差的泛化能力是其所具有的知名缺陷,如果测试阶段的样例与训练样例不是十分相似的话,那么单样本学习模型很可能无法准确的识别出测试样例的类标签,因此,为了回避这一问题,零样本学习在单样本学习基础上得以产生。 - 偶然学习
偶然学习方法,该方法希望能够在给定的标签空间之外**,识别未定义类标签的测试样例所属类标签**,这一方法的核心思想是在对见过的训练类的样例进行识别的同时,也可以对从未见过的未见类样例进行聚类分析。
零样本学习经典模型
- 新任务零数据学习
- 零数据学习的目标在于如何构建模型学习没有可用的训练数据,且只有类描述的分类器学习问题。因此在定义上,零数据学习与零样本学习本质上是相同的,零数据学习主要有:* 输入空间方法,模型空间方法。
- 输入空间方法
核心思想:
利用训练类和测试类中对应于每一类的描述信息,对模型进行信息补充,使得模型不再是由简单的学习由输入样例到类标签的映射关系。在训练阶段,输入空间的方法利用训练类的样本以及对应的类描述信息对模型进行训练。因为是直接在输入阶段,对模型所需要的信息进行补充,所以该方法被命名为输入空间的方法,个人理解:即测试阶段将训练集类的描述信息与已知训练集的辅助联系起来,从而确定未知样本的类别。- 示意图:
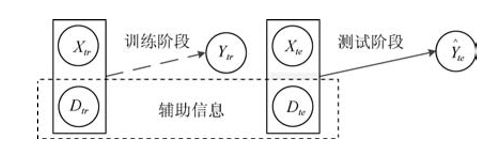
上述过程简单来说,训练过程,将训练样例的描述信息 D t r D_{tr} Dtr看作该样例的类别和训练样例 X t r X_{tr} Xtr一块输入到模型中去,得到** D t r D_{tr} Dtr与 X t r X_{tr} Xtr的映射关系 f f f.测试阶段,将未知类别的测试例,输入 模型 f f f中,找到待分类样例的描述信息**,从而确定类别的方法。
模型空间方法
核心思想
模型空间方法假设对于每一类 y y y,都存在对应的分类函数, d ( y ) ∈ D d(y) \in D d(y)∈D,假定 d ( y ) d(y) d(y)为该类所对应的描述信息,用把分类参数 f f ( . ) f_{f}(.) ff(.)化为 g d ( y ) ( x ) g_{d(y)}(x) gd(y)(x)即令:
f y ( x ) = g d ( y ) ( x ) f_y(x) = g_d(y)(x) fy(x)=gd(y)(x)
零样本学习的问题变为用 d ( y ) d(y) d(y)和输入样例学习 g d ( y ) ( x ) g_{d(y)}(x) gd(y)(x)的表示问题,例如:可以使用以下平均损失最小化来求解模型参数。
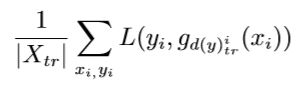
- 示意图:
通俗来讲:训练阶段,如果可以利用给定的$ x_{i}、y_{i}$以及 d ( y ) i d(y)^{i} d(y)i对函数 g g g 进行充分的训练,在测试阶段,假定每一个测试类都具有给定的$ d(y) 时 , 就 可 以 利 用 训 练 阶 段 学 习 到 的 函 数 g , 计 算 每 个 测 试 类 样 例 所 对 应 的 分 类 函 数 时,就可以利用训练阶段学习到的函数 g, 计算每个测试类样例所对应的分类函数 时,就可以利用训练阶段学习到的函数g,计算每个测试类样例所对应的分类函数g_{d(y)}(x)KaTeX parse error: Expected 'EOF', got '#' at position 245: …lor_FFFFFF,t_70#̲pic_center) 个人感…gd(y)(x) = g(x,d(y)) , 可 以 看 作 模 型 空 间 方 法 特 例 , 模 型 空 间 方 法 将 ,可以看作模型空间方法特例,模型空间方法将 ,可以看作模型空间方法特例,模型空间方法将d(y) 作 为 调 整 模 型 作为调整模型 作为调整模型gd(y)(x)$的参数,不太理解。
- 语义输出编码零样本学习
具体做法:先定义多维的语义特征空间,每一个维度都对应一个二值编码特征,例如:对于狗这一类标签来说:在多毛、有尾巴、水下呼吸、肉食性和可以快速移动5条语义特征下的语义空间中, 狗这一类可以里利用布尔值,表示语义特征向量 [ 1 , 1 , 0 , 1 , 1 ] [1,1,0,1,1] [1,1,0,1,1] (这里假设知识库只有5个语义知识),定义语义编码输出分类器为 H : X → Y H: X \rightarrow Y H:X→Y,假设H是复合映射函数: H = L ( S ( ∗ ) ) H = L(S(*)) H=L(S(∗)), S S S函数负责将图像映射到语义空间,L函数负责将语义编码空间映射到标签集上, L L L函数通过查询知识库 K K K中的语义编码与类标签对应关系实现映射。
学习过程示意图:
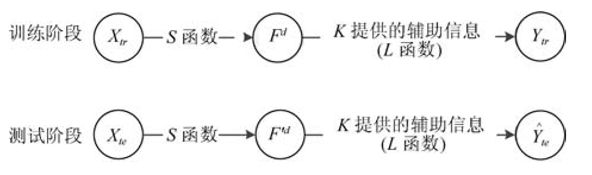
个人感觉,这个和新任务的零数据学习相比,就是把新任务的零数据学习中的描述信息 D v D_{v} Dv进行了one-hot编码而已。 - 基于属性类间迁移的未见类学习
基于属性类间迁移的未见类检测方法,这一模型可谓是零样本学习的奠基之作。现有的零样本学习方法大多都继承了该模型的思想。 L a m p e r t Lampert Lampert等建立的数据集,Animals with attributes也成为研究零样本学习所必须使用的数据集之一。
下面介绍两种拓扑结构的零样本学习模型,分别为:直接属性预测模型(DAP)和间接属性预测(IAP)模型。
直接属性预测模型(DAP)
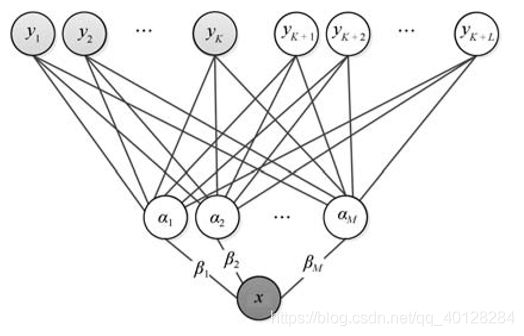
假定 y 1 , y 2 , . . . y k y_1,y_2,...y_k y1,y2,...yk为训练类, y k + 1 , y k + 2 , . . . y k + L y_{k+1},y_{k+2},...y_{k+L} yk+1,yk+2,...yk+L为测试类, a 1 , a 2 , . . . . , a M a_1,a_2,....,a_M a1,a2,....,aM为全部属性特征的集合,在测试阶段时候,尽管模型从未针对测试类进行训练,但属性层仍然可以利用训练阶段得到的属性分类器 β \beta β对输入的测试类图像所具有的属性进行判断,得到输入图像的属性特征估计之后,就可以利用得到测试样例的属性特征估计以及测试类的属性指示对输入样例进行分类判断,通俗来讲:假设我们要通过(有无尾巴、体积大小、头有没有角)来对动物种类识别,属性分类器 β \beta β,可以提取输入图像有无尾巴,体积有多大,头有没有角?得到的结果与测试类的属性指示对输入样例进行分类判断。
间接属性预测(IAP)模型
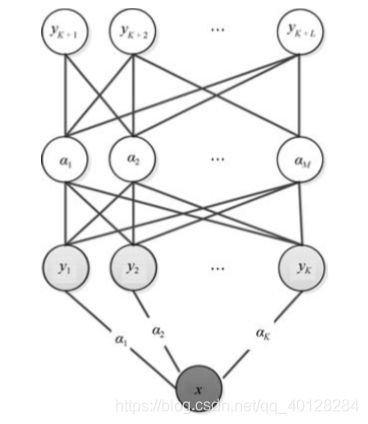
f分类公式如下图所示:
f ( x ) = a r g m a x l = 1 , . . . . , L P ( y ∣ x ) = a r g m a x l = 1 , . . . , L ∏ m = 1 M p ( a m l ∣ x ) p ( a m l ) f(x) = arg max_{l = 1,....,L}P(y|x) \\= argmax_{l = 1,...,L} \prod^M_{m = 1}\frac{p(a^l_m | x)}{p(a^l_m)} f(x)=argmaxl=1,....,LP(y∣x)=argmaxl=1,...,Lm=1∏Mp(aml)p(aml∣x)
- 跨模态迁移的零样本学习
核心思想
跨模态迁移学习的核心思想是将图像和类标签同时映射到相同的子空间内,且通常是将图像和类标签同时映射(或称为嵌入到语义空间中)并在语义空间内,利用一定的相似度度量方法,去确定测试类输入图像的类标签。
学习示意图
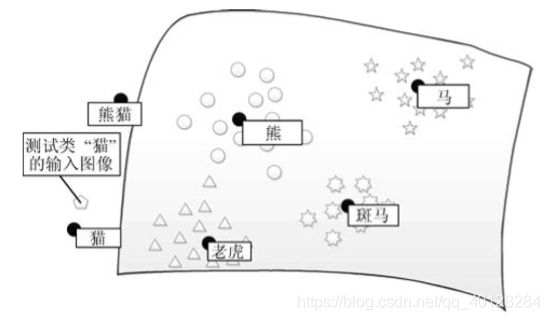
上图五边形白点代表测试类 “猫” 的输入图像在语义空间中的表示, 除此之外的白点代表训练类的输入图像在语义空间中的映射向量。在该方法中,黑点代表所有类标签的语义向量,所有的语义向量都是预先给定的辅助信息,这些语义向量可以是 属性向量,也可以是使用文本描述生成的单词语义向量。 训练阶段,首先利用训练类标签对应的语义向量和训练类的样例对跨模态映射模型进行训练。训练后,映射模型可以成功地将输入样例映射到语义空间中,并准确地映射到输入样例所对应的类标签的语义向量附近,测试阶段,输入测试类的样例时, 首先利用训练阶段得到的跨模态映射模型将测试类输入样例映射到语义空间中,并根据相似性判断方法 (如余弦相 似性、K 近邻方法等), 将与输入样例的的语义向量估计最为相似的语义向量的类标签, 作为测试类图 像的类标签估计。
简单来说,将类标签映射到语义空间中,根据训练集依据一定原则来训练样例到语义空间的映射关系,原则即:“样例映射到语义空间中应该在类标签向量周围”,依据映射关系将测试集也映射到语义空间中,并根据相似性判断方法确定其类别。
零样本学习的关键问题
- 广义零样本学习
零样本学习在测试阶段,只有未见类样例出现,这在实际应用中是不现实的,已见类的对象往往是现实世界中最为常见的对象,而且,如果在训练阶段已见类样本容易得到,未见类样本难以获取,那么在测试阶段也不应只有未见类样例出现。 - 广义零样本学习定义
如果在模型训练过程中,只可以使用训练类样例样本进行训练,并且在测试阶段可以准确识别已见类样例以及从未见过的未见类样例,那么就认为该模型实现了广义零样本学习。
虽然广义零样本学习定义十分简单,但传统零样本学习方法仍会出现上述未见类识别准确率较低的问题,这是因为,在模型训练过程中只使用了已见类样本进行训练,已见类先验知识也更为丰富。从而使得已见类模型占主导地位,所以在输入测试样例时,模型会更加倾向于对未见类样例标注为已见类标签,从而造成识别准确率于传统零样本学习相比大幅度下跌这一问题,一般有两种解决方法:
一种是在输入样例时,判断其属于已见类还是未见类,这种方法称为新颖检测,另一种方法是在模型判断输入样例未已见类时候,叠加一个校准因子以平衡模型对已见类识别的倾向性。另一种方法称为叠加校准,两种方法具体内容如下: - 枢纽度问题
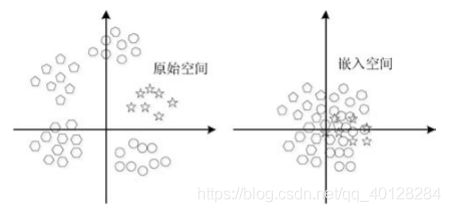
这一问题是指将原始空间 (例如图像特征空间或类标签空间) 中的某个元素映射到特征子空间中,得到原始空间中某个元素的在特征子空间中的新表示,这时如果使用 K 近邻方法进行相似性度量时,可能会有某些原始空间中无关元素映射到多个测试样本特征空间中表示最近的几个近邻中, 而这些无关向量,就称为 “枢纽 (hub)”, 枢纽的出现,污染了测试类的近邻列表,对零样本学习产生了较大的影响。所有利用特征子空间的机器学习模型,都会存在这一现象,维度越高,这一现象愈发明显。简单来说,就是在原特征空间类别可分的样例,映射到特征空间中出现类别不可分的现象。
枢纽化现象示意图
- 映射域偏移问题
映射域偏移问题的根源在于映射模型较差的泛化能力:模型使用了训练类样本学习由样例特征空间到类标签语义空间的映射,由于没有测试类样本可以用于训练,因此,在映射测试类的输入样例时**,就会产生一定的偏差**。示意图如下所示:白色圆点为训练类标签的语义向量,黑色圆点为测试类标签的语义向量,灰色圆点为测试类输入在语义空间中的映射向量,其余为训练类在语义空间的映射向量,可以看出,老虎、马和斑马为训练类, 熊猫为测试类,训练类的样本都很好地映射到了训练类语义向量的附近,而测试类输入样例映射到语义空间后,却与它所对应的类标签距离较远。 因此,如果想要解决映射域偏移问题,就需要提高映射模型的泛化能力,
映射域偏移问题示意图:

零样本学习方法研究进展
目前的零样本学习方法一般都沿袭了将输入和输出映射到子空间的思路,在这一思路下的零样本学习方法可以分为两类:“相容性模型” (主要是DAP 模型)和 “混合模型”(主要是IAP 模型)。
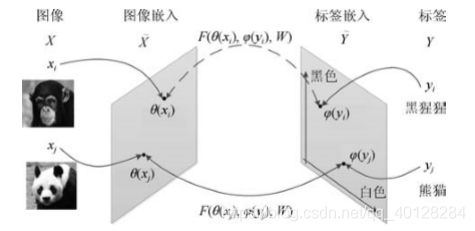
相容性模型又分为线性相容性模型和非线性相容性模型,非线性相容性模型使用非线性相容函数,与线性相容性模型相比具有着更强的表达能力;因此, 目前的零样本学习研究中,非线性相容性模型在相容性模型中占据主流地位。
- 线性相容模型分类示意图:

线性相容性模型与非线性相容性模型的主要区别在于$ F(θ(x),ϕ(y),w)$ 是否为线性函数。 在线性相容性模型中,相容性函数定义为:
F ( θ ( x ) , ψ ( y ) , w ) = θ T ( x ) W ψ ( y ) F(\theta(x),\psi(y),w) = \theta^T(x)W\psi(y) F(θ(x),ψ(y),w)=θT(x)Wψ(y)
线性相容性零样本学习模型,分别是深度语义嵌入模型,属性标签嵌入模型,属性描述替换模型,文本描述替换模型,多视图零样本学习模型和细粒度数据视觉描述的深度表示模型。
- 非线性相容模型的分类示意图:
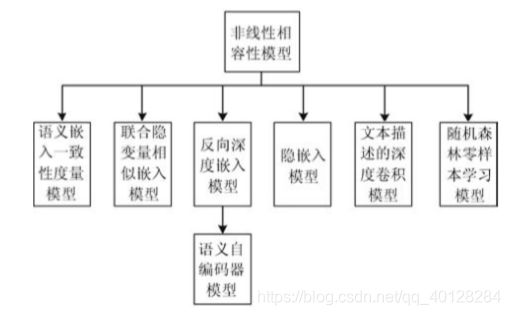
顾名思义,非线性相容性模型的相容性函数是非线性的, 一般来说有两种常见形式:(1)距离函数形式 (2)概率形式。我们将介绍 7 种典型非线性相容性模型:语义自编码器模型、语义嵌入一致 性度量模型、联合隐变量相似嵌入模型、隐嵌 入模型、反向深度嵌入模型、基于文本描述的 深度零样本卷积神经网络和基于随机森林的零 样本学习模型。
混合模型结构示意图(主要是IAP模型)
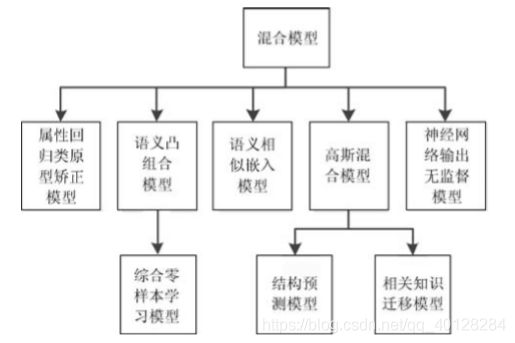
利用训练类类标签所对应的特征子空间映射的混合组合来表示测试类输入样例在特征子空间中的映射,进而判断输入样例的映射与测试类类标签映射之间的相似性,得到输入样例类标签估计的模型,称为混合模型。简单来说:训练样例映射到特征子空间中,测试阶段过来一个测试样例同样方法可以映射到特征子空间中,且可以用其他已知样例的特征向量表示出来,比如熊猫 = 猫+熊,这样我们就可以预测输入的类别。

混合模型分类示意图
传统零样本学习与泛化零样本学习。
- 传统零样本学习(conventional Zero-Shot Learning, cZSL)是指在实验阶段仅使用已知类训练模型,仅使用未知类测试模型。
- 泛化零样本学习 (generalized Zero-Shot Learning, gZSL)是指在实验阶段仅使用已知类训练模型,则不再将测试数据强制认定为仅来自未知类,而是对测试数据的来源做更松弛化的假设(测试数据可以来自于所有类别中的任意对象类)。
一个切实有用的零样本学习系统应该既能精确地识别已知类,又能准确地区分未知类。它不但可以区分待识别对象是来自于已知类还是未知类,也可以识别待识别对象属于已知类或未知类中的哪种 物体。但是由于传统零样本学习的测试阶段设置过 于严苛,不能真实反映现实世界中物体识别的情 景,为了更好地评价零样本学习模型在实际情况中 的性能,泛化零样本学习必不可少。
学习心得
慢慢的将各种,模型啥的全部都搞定,以及学习的各种标准都好好研究透彻!