Flink编码:FlinkSQL全面指南
文章目录
-
-
- 1. FlinkSQL定位
- 2. 流与表的对偶性
- 3. 持续查询/增量计算
- 4. 回撤流
- 5. Flink 1.11关于SQL的增强
-
- 5.1 DDL写法
- 5.2 主键
- 5.3 Catalog
- 6. JOIN算子
-
- 6.1 双流JOIN原理
-
- 6.1.1 Inner Join
- 6.1.2 Left Join
- 6.1.3 State数据结构
- 7. 窗口
-
- 7.1 OverWindow
-
- 7.1.1 基于数据条目的overwindow
- 7.1.2 基于时间的overwindow
- 7.2 GroupWindow
-
- 7.2.1 滚动窗口
- 7.2.2 滑动窗口
- 7.2.3 Session窗口
-
1. FlinkSQL定位
通过SQL开发人员可以只关注业务逻辑,学习成本低,容易理解,而且内置了很多的优化规则,可以简化开发复杂度,通过SQL还能在高层应用上实现真正的批流一体。
Hive SQL,Spark SQL,Flink SQL给开发人员带来了极大便捷,让开发人员只需关注业务场景,而无需关注复杂的API编写。
2. 流与表的对偶性
以下是利用FlinkSQL做CDC的场景,mysql表可以转成CDC流,CDC流又可以落盘成mysql表。
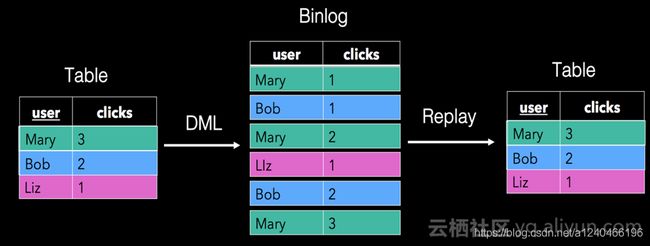
表的重要属性:schema,data,DML操作时间/时间字段
流的重要属性:schema(debezium、canal、ogg),data,processTime/eventTime
流与表具备相同的特征,可以信息无损的相互转换,我称之为流表对偶(duality)性。流与表的对偶性,是flinkSQL的理论基石。而理解流与表的对偶性的前提,是要充分理解FlinkSQL的增量查询和双流join原理,见下节。
参考:https://developer.aliyun.com/article/667566?spm=a2c6h.13262185.0.0.36a07e18Wn3kay
3. 持续查询/增量计算
流上的数据源源不断的流入,我们既不能等所有事件流入结束(永远不会结束)再计算,也不会每次来一条事件就像传统数据库一样将全部事件集合重新整体计算一次。
在持续查询的计算过程中,Apache Flink采用增量计算的方式,也就是每次计算都会将计算结果存储到state中,下一条事件到来的时候利用上次计算的结果和当前的事件进行聚合计算。
如以下案例:

// 求订单总数和所有订单的总金额
select count(id) as cnt,sum(amount)as sumAmount from order_tab;

将count和sum更新到在state中;当最新一条数据到来时,count+1,sum+amount。
4. 回撤流
Flink中,Kafka Source/Sink是非回撤流,Group By是回撤流。所谓回撤流,就是可以更新历史数据的流,更新历史数据并不是将发往下游的历史数据进行更改,要知道,已经发往下游的消息是追不回来的。更新历史数据的含义是,在得知某个Key(接在Key BY / Group By后的字段)对应数据已经存在的情况下,如果该Key对应的数据再次到来,会生成一条delete消息和一条新的insert消息发往下游。
聚合算子和Sink算子都有回撤的概念,但是又不尽相同。聚合算子的回撤用于聚合状态的更新,保证了FlinkSQL持续查询/增量查询的正确语义;Sink算子的回撤则更多的是应用于CDC场景,保证了CDC场景下的append、upsert、retract等语义的正确性。
详情见上一篇文章《回撤流》
5. Flink 1.11关于SQL的增强
5.1 DDL写法
对 DDL 的 WITH 参数相对于 1.10 版本做了简化,从用户视角看上就是简化和规范了参数
| Old Key (Flink 1.10) | New Key (Flink 1.11) |
|---|---|
| connector.type | connector |
| connector.url | url |
| connector.table | table-name |
| connector.driver | driver |
| connector.username | username |
| connector.password | password |
| connector.read.partition.column | scan.partition.column |
| connector.read.partition.num | scan.partition.num |
| connector.read.partition.lower-bound | scan.partition.lower-bound |
| connector.read.partition.upper-bound | scan.partition.upper-bound |
| connector.read.fetch-size | scan.fetch-size |
| connector.lookup.cache.max-rows | lookup.cache.max-rows |
| connector.lookup.cache.ttl | lookup.cache.ttl |
| connector.lookup.max-retries | lookup.max-retries |
| connector.write.flush.max-rows | sink.buffer-flush.max-rows |
| connector.write.flush.interval | sink.buffer-flush.interval |
| connector.write.max-retries | sink.max-retries |
5.2 主键
Upsert操作需要主键约束来进行更新,Flink 1.10之前通过Group By语句推断主键,这种方式有一些情况是推断不出主键的,比如Group By UDF(id),Flink1.11引入了主键约束语法
-- Flink 1.10
create talbe MyUserTable(
id BIGINT, name STRING, age INT
) WITH (
'connector.type'='jdbc',
'connector.url'='jdbc:mysql://localhost:3306/mydb',
'connector.table'='users'
);
-- upsert write
insert into MyUserTable
select id, max(name), max(age) from T group by id;
-- Flink 1.11
create talbe MyUserTable(
id BIGINT, name STRING, age INT,
-- 设置主键,ENFORCED表示主键由用户确保正确,flink不去数据源做校验(测了一下,这里填错的也没关系,似乎只是一个启用upsert的开关而已)
PRIMARY KEY key(id) NOT ENFORCED
) WITH (
'connector'='jdbc',
'url'='jdbc:mysql://localhost:330 6/mydb',
'table-name'='users'
);
-- upsert write
insert into MyUserTable
select id, max(name), max(age) from T group by id;
5.3 Catalog
Flinksql和Table API在calcite validate阶段会对sql进行语法校验,此时需要用到catalog中维护的库、表、UDF、字段及类型等元数据。
用户需要手动创造DDL语句,如果表schema发生变化,则需要用户停止任务并修改DDL语句,比较繁琐。JDBC catalog通过JDBC协议连接关系型数据库,Flink可以自动检索表,不需要用户手动输入和修改。
Flink任务默认会创造一个内存中的catalog名为default_catalog,使用catalog自动更新元数据的场景还不多见,大部分场景还是通过ddl来定义表的元数据并存入default_catalog。因此目前flink1.11只支持postgresql这个唯一的JDBC catalog实现,且仅支持以下方法
// The supported methods by Postgres Catalog.
PostgresCatalog.databaseExists(String databaseName)
PostgresCatalog.listDatabases()
PostgresCatalog.getDatabase(String databaseName)
PostgresCatalog.listTables(String databaseName)
PostgresCatalog.getTable(ObjectPath tablePath)
PostgresCatalog.tableExists(ObjectPath tablePath)
参考:
https://ci.apache.org/projects/flink/flink-docs-release-1.11/zh/dev/table/catalogs.html
https://www.jianshu.com/p/aef22cf8e33f
https://blog.csdn.net/qq_31975963/article/details/109401740
6. JOIN算子
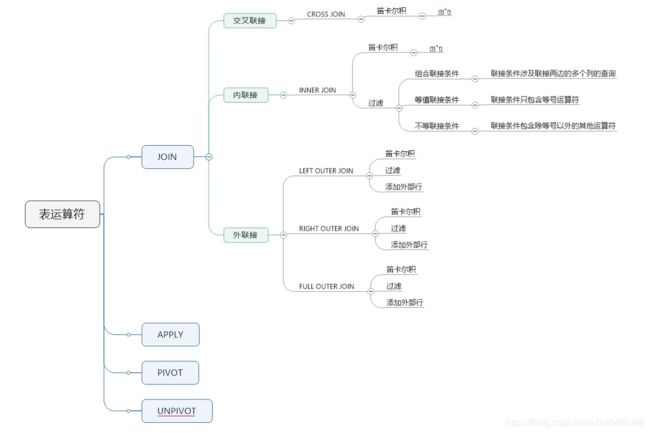
参考:https://www.cnblogs.com/cnki/p/10274532.html
6.1 双流JOIN原理
JOIN算子会开辟左右两个State进行数据存储,左右两边的数据到来时候,进行如下操作:
- LeftEvent到来存储到LState,RightEvent到来的时候存储到RState;
- LeftEvent会去RightState进行JOIN,并发出所有JOIN之后的Event到下游;
- RightEvent会去LeftState进行JOIN,并发出所有JOIN之后的Event到下游。
6.1.1 Inner Join
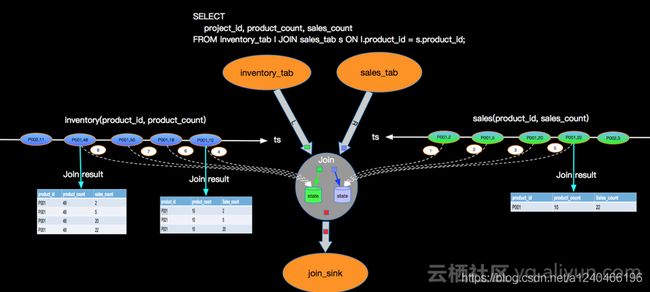
- 右流比左流快,当数据1、2、3到来时,存入Rstate,且发现Lstate中没有可以join的数据
- 数据4到达,存入Lstate,并与Rstate中的所有数据进行join
- 数据5到达,存入Rstate,并与Lstate中的所有数据进行join
6.1.2 Left Join

left join与inner join原理基本类似,都是维护了左右两个state。
如果左流第一条数据先到达,发现Rstate中没有数据时,会将右流字段补充null值往下游发送,当右流第一次且仅在第一次发现Lstate中有可以join的数据时,会发送回撤消息,撤回含有null值的记录;
如果右流第一条数据先到达,则存入Rstate,不往下游发送数据。
注意:
双流left join的回撤仅发生在左流第一条数据优先到达且右流第一次发现Lstate中有数据可以join的情况下,接下来并不会产生任何回撤消息,这里与聚合算子的回撤有些区别
6.1.3 State数据结构
Map
- 第一级MAP的key是Join key,比如示例中的P001, value是流上面的所有完整事件;
- 第二级MAP的key是行数据,比如示例中的P001, 2,value是相同事件值的个数。
数据结构的利用:
- 记录重复记录 - 利用第二级MAP的value记录重复记录的个数,这样大大减少存储和读取
- 正向记录和撤回记录 - 利用第二级MAP的value记录,当count=0时候删除该元素
- 判断右边是否产生撤回记录 - 根据第一级MAP的value的size来判断是否产生撤回,只有size由0变成1的时候(右流中第一条和左可以JOIN的事件)才产生撤回
参考: https://developer.aliyun.com/article/672760
7. 窗口
flink中有两种window,一种是OverWindow,即传统数据库的标准开窗,每一个元素都对应一个窗口。一种是GroupWindow,目前在SQL中GroupWindow都是基于时间进行窗口划分的(datastream api中既可以基于时间,又可以基于数据条目)。
7.1 OverWindow
每来一条数据,就建一个窗口,具体有分为基于数据条目的和基于时间两种OverWindow。
7.1.1 基于数据条目的overwindow
SELECT
agg1(col1) OVER(
[PARTITION BY (value_expression1,..., value_expressionN)]
ORDER BY timeCol
ROWS
BETWEEN (UNBOUNDED | rowCount) PRECEDING AND CURRENT ROW) AS colName,
...
FROM Tab1
SELECT
itemID,
itemType,
onSellTime,
price,
MAX(price) OVER (
PARTITION BY itemType
ORDER BY onSellTime
ROWS BETWEEN 2 preceding AND CURRENT ROW) AS maxPrice
FROM item_tab
7.1.2 基于时间的overwindow
SELECT
agg1(col1) OVER(
[PARTITION BY (value_expression1,..., value_expressionN)]
ORDER BY timeCol
RANGE
BETWEEN (UNBOUNDED | timeInterval) PRECEDING AND CURRENT ROW) AS colName,
...
FROM Tab1
SELECT
itemID,
itemType,
onSellTime,
price,
MAX(price) OVER (
PARTITION BY itemType
ORDER BY rowtime
RANGE BETWEEN INTERVAL '2' MINUTE preceding AND CURRENT ROW) AS maxPrice
FROM item_tab
7.2 GroupWindow
与OverWindow每条数据对应一个窗口不同,GroupWindow通过Window中的assigner组件进行窗口的划分以及数据落入窗口的选择。详情请参看《窗口原理详解》
与DataStream API不同,目前Flink SQL只支持基于时间的GroupWindow,不支持基于数据条目的GroupWindow。
7.2.1 滚动窗口
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
SELECT
region,
TUMBLE_START(rowtime, INTERVAL '2' MINUTE) AS winStart,
TUMBLE_END(rowtime, INTERVAL '2' MINUTE) AS winEnd,
COUNT(region) AS pv
FROM pageAccess_tab
GROUP BY region, TUMBLE(rowtime, INTERVAL '2' MINUTE)
7.2.2 滑动窗口
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
SELECT
HOP_START(rowtime, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE) AS winStart,
HOP_END(rowtime, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE) AS winEnd,
SUM(accessCount) AS accessCount
FROM pageAccessCount_tab
GROUP BY HOP(rowtime, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE)
7.2.3 Session窗口
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
SELECT
region,
SESSION_START(rowtime, INTERVAL '3' MINUTE) AS winStart,
SESSION_END(rowtime, INTERVAL '3' MINUTE) AS winEnd,
COUNT(region) AS pv
FROM pageAccessSession_tab
GROUP BY region, SESSION(rowtime, INTERVAL '3' MINUTE)
参考:
https://developer.aliyun.com/article/670202?spm=a2c6h.13262185.0.0.91027e18Q8W1oA
https://www.cnblogs.com/woodytu/p/4709020.html