【论文翻译】Temporally Identity-Aware SSD with Attentional LSTM
Temporally Identity-Aware SSD with Attentional LSTM
带有注意力LSTM的时间性身份感知的SSD
摘要
时间目标检测引起了人们的广泛关注,但大多数流行的检测方法无法利用视频中丰富的时间信息。最近,许多算法都有蜜蜂。N是为视频检测任务而开发的,但是很少有方法能够实现视频中的实时在线目标检测.本文基于注意力机制和卷积长时记忆(ConvLSTM),提出了一种用于实际检测的时间单镜头检测器(TSSD).与以往的方法不同的是,本文针对用convlstm临时集成金字塔特征层次结构的问题,设计了一种新的结构,包括一个低层时态单元和一个适用于多尺度特征的高层次结构map。此外,我们还开发了一个创造性的时间分析单元,即注意集中,其中一个时间注意机制是专门为背景抑制和尺度抑制而量身定做的,而ConvLSTM则集成了跨时间的注意感知特性。针对时间相干性设计了关联损失和多步训练。此外,还利用在线小管分析(OTA)进行识别。在IMAGEETVID数据集和2DMO15数据集中对我们的框架进行了评估。对检测和跟踪能力的广泛比较验证了所提出的方法的优越性。因此,所开发的TSSD-OTA在检测和跟踪方面取得了快速的速度和总体的竞争性能。最后,对水下物体抓取进行了真实世界的机动。
1 介绍
……
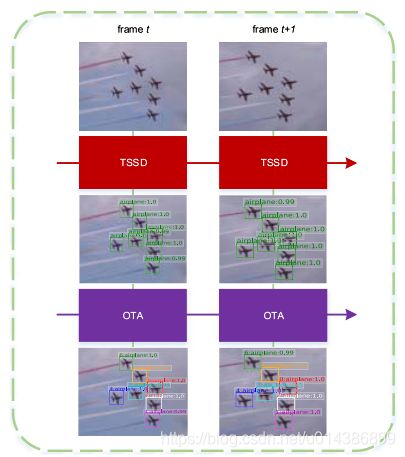
图1.TSSD-OTA的主要思想。我们的目标是在视频中临时检测目标,并以较低的计算代价生成类似跟踪的结果。TSSD是一个时间检测器,OTA是为识别而设计的。
如图1、我们的方法能够在不同的时间内检测对象,并使用个体身份逐帧地链接它们,并且我们将这种检测方法称为身份感知检测器。.针对视频中的对象,提出了一种基于SSD的时间检测模型,即,时间single-shot检测器(TSSD)。为了跨时间地集成特征,使用ConvLSTM来获取时间信息。由于金字塔特征层次结构用于多尺度检测,SSD总是生成大量的视觉特征。由于ES具有多尺度语义信息,因此我们设计了一种新的结构,包括一个低层时态单元和一个用于时态传播的高级别单元(LH-TU)。此外,对于多尺度特征地图,只有一小部分视觉特征与对象相关。因此,采用注意机制进行背景抑制和尺度抑制。N我们提出了一个注意控制LSTM(AC-LSTM)模块.随后,提出了一种关联目标和一种多步序列训练方法。最终,进行在线管状分析(OTA)以进行识别。因此,ETSSD-OTA在精度和速度上大大提高了连续视觉的检测和跟踪性能。据我们所知,只有很少的时间一级探测器被报道。此外,现有的检测框架中缺乏实时、在线和身份感知检测器..的..本文所作的贡献总结如下。
1)设计了一种LH-TU结构,有效地传播了金字塔特征层次结构。此外,我们还提出了一个AC-lstm模块作为一个时态分析单元,其中有一个时态注意。设计了背景抑制和尺度抑制的机制。然后,针对TSSD提出了相应的训练方法。
2)为了识别,利用低级AC-LSTM利用OTA算法,该低级AC-LSTM以相当快的速度将检测到的对象帧逐帧链接。
3)在检测和跟踪方面,我们显著地实现了IMAGEETVID数据集和2DMO15数据集的改进结果。
本文件的其余部分按如下方式组织。第二节介绍相关工程。此后,我们在第三节阐述了我们的方法,包括TSSD和OTA。下一步,第四节提供了实验结果和讨论。最后,第五节总结了结论和今后的工作。
2 相关工作
A.视频检测框架的进展
在开始时,结合静态检测和提出后的方法来抵消视频检测任务[15]-[17]。它们在每个视频帧中静态检测,然后对MUL进行综合处理。TIFRAME结果。康等人[15],[16]发展了基于管状网的检测方法,该方法被定义为视频片段中的时间传播包围盒。他们的方法tcn包含静态图像对象检测。关于多上下文抑制、运动引导传播和时态管束再取。从非最大抑制(NMS)中汲取灵感。[17]提出了一种抑制暂时不连续包围盒的SeqNMS。然而,这些解决方案有两个主要缺点。复杂的后处理会影响时间效率,不会提高检测器本身的性能。
快速RCNN采用区域提议网络进行目标定位[3],因此一些视频检测方法试图提高RPN与时间信息的有效性[18]-[20],[26],[37]。Galteri等人设计了一个闭环RPN,以将新的建议与先前的检测结果合并。该方法有效地减少了无效区域的数量,但也可能提出建议区域过度集中。康等人开发了管状提议网络(TPN),以生成管状,而不是包围盒。然后,采用编解码器LSTM进行分类.TPN集成了时间信息,但它需要未来的消息。这些方法是从两级检测器扩展而来的,因此n相对较低的计算效率。
B.探测和跟踪
Feichtenhofer等人[21]将rfcn检测器与基于相关滤波的跟踪器[35]相关联,以检测视频中的物体,称为D&T。由于采用了跟踪方法,它实现了高召回率ra。但该级联系统严重增加了模型复杂度,影响了推理速度。
在检测跟踪方面,翔等人。[43]将跟踪任务转化为决策,其策略依赖于跟踪状态。Kim和Kim[44]组合了一个检测器、一个前向跟踪器和一个用于跟踪视频序列中的多个对象的后向跟踪器,并且该检测器还用于细化跟踪结果。宁等人[22]在YOLO和LSTM的基础上提出了一种用于跟踪的Rolo。YOLO负责静态检测,视觉特征和高分对象的位置将被输入到用于时态建模的LSTM。Lu等[23]提出的关联LSTM(ALSTM)对高分对象的关系进行时间分析,并设计了关联损失来进行识别。从实用主义的角度来看,Bewley等人。开发了一种卡尔曼滤波[47]和匈牙利方法[48]用于实时跟踪[45],跟踪分量达到260帧/s(FPS)。然而,在大多数这些方法中,视觉特征在探测器中的S还没有得到有效的使用。
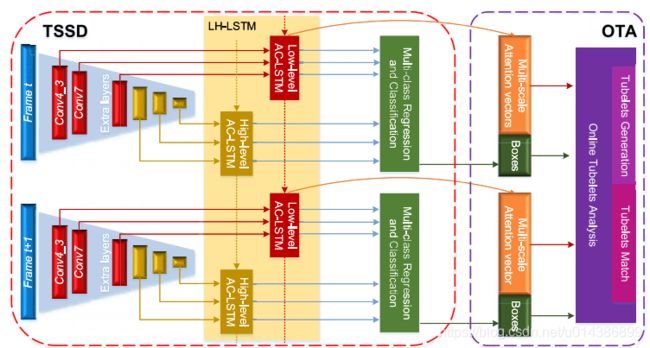
图2.TSSD-OTA的示意图。低级特征共享AC-LSTM,高级特征共享AC-LSTM,即LH-TU..接下来,ConvLSTM的隐藏状态将用于多盒回归。离子和分类。最后,在多尺度注意图的基础上,进行OTA识别。尽管我们在这里展示了一个双帧检测过程,tsd-ota从所有avi中学习。使用当前的金字塔特征以及所有先前的存储器来生成当前隐藏状态。此外,有效存储器长度在AC-LSTM的遗忘栅极的控制下。
C.基于RNN的检测器
最近,最新的方法已经使检测器与RNN相关联。Zhu和Liu报告了一种基于SSD和LSTM的移动视频检测方法,称为LSTMSSD[27]。此外,他们还设计了设计ED是一个瓶颈-LSTM结构,以降低计算成本。因此,在移动CPU上,LSTM-SSD达到了高达15帧/s的实时推理速度。肖和李[26]用ConvGRU[13]开发了一个时空信息存储模块。传播。特别是提出了“MatchTrans”来抑制冗余内存。
三.方法
在本节中,我们首先介绍了拟议的架构,包括LHTU和ACLSTM。然后,我们详细描述了如何对网络进行培训。最后,给出了OTA算法的方法.我被告知。
A.架构
从以VGG-16[24]为骨干的SSD出发,构造了一个时态体系结构,其中原VGG-16中的fc6和fc7被转换为卷积层,即Conv 6和Conv 7。参考图2,所提出的TSSD是基于前向CNN和RNN产生的金字塔特征进行检测。卷积检测头是为多类分类和计算而设计的。(绿色显示)。在此过程中,利用卷积运算来预测具有多尺度视觉特征的对象的信息,然后是一定数量的包围盒和类别判别sc。矿石表示在这些盒子上存在不同类别的物体,遵循NMS生成最终结果。输入图像的空间分辨率为300×300。采用Conv 4_3,Conv 7,Conv 8_2,Conv 9_2,Conv 10_2和Conv 11_2作为金字塔特征,其大小分别为38×38×512,19×19×512,10×10分别为×512、5×5×256、3×3×256和1×1×256。对于序列学习,TSSD具有多尺度特征集成结构,即LHTU和ACLSTM。左侧。TU的目标是金字塔特征层次的传播,而AC-LSTM的目标是在没有无用信息的情况下有效地产生时间记忆。
1)LH-TU:
我们使用相同的两种结构来临时集成金字塔特征层次,称为LH-TU.在所采用的ssd模型中,六尺度语义信息具有金字塔特征及其f。温度大小彼此不同。在原始SSD框架中,特征映射中的512、1024、512、256、256、256个通道从低电平变为高电平。创造性地将多尺度特征映射按层次关系和信道大小分为两类,即低层次特征和高层次特征。也就是说,在一方面,我们根据不同卷积层的顺序对多尺度特征映射进行分组。众所周知,卷积运算逐渐提取视觉特征,阴影特征包含更多的图像细节,而高层特征包含更多的语义信息。因此,LH-LSTM有利于学习过程。另一方面,低级特征和高级特征应该共享各自的时态单元,但convlstm单元不能处理信道大小可变的特征,因此,在lh-lstm的方式下,w。e只将Conv 7的信道大小更改为512,以尽可能保持原来的SSD结构。因此,如图2所示,我们将前三幅特征地图视为低级特征(以红色表示),而最后三幅地图则被视为高级特征(以黄金表示)。低级特征的信道大小被统一为512以共享时间单元,而高级特征的信道大小保持为256。此外,低级功能覆盖更多详细信息,而THe高级特性包含更多的语义信息.相应地,LHTU包括一个低层时态单元和一个高级时序单元.
2)AC-LSTM:
在目标检测任务中,大多数特征都与背景相关。此外,不同尺度的特征映射对检测的贡献也不同。因此,当convlstm处理背景或上述小贡献的多尺度特征映射时,效率很低。例如,如果一个对象的大小太小,它的检测将由Conv_4_3提供,其中与小对象关联的特征远远小于背景。此外,所有较高层次的特征映射都可以被认为是无用的,应该加以抑制,以避免出现假阳性。为此,我们提出了一种用于背景抑制和缩放的AC-lstm。抑制,其中时间注意机制为ConvLSTM选择对象感知特征,反过来,ConvLSTM为注意机制提供时间信息以改进注意的准确性。作为一个时态分析单元,AC-lstm可以表述为:
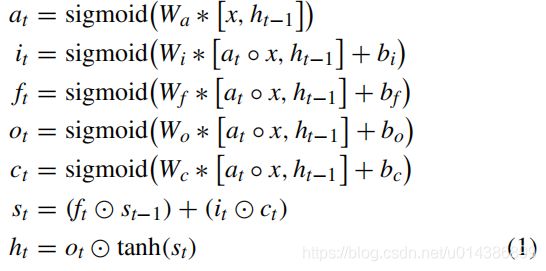
其中,∗表示卷积;[·,·]是级联;是一个按元素方向的乘法;◦表示在多通道特征映射中,一个单机映射与每个信道相乘。一个t时间步骤t,at,ht,it,ft,ot,ct,st分别是注意映射、隐藏状态、输入门、遗忘门、输出门、LSTM的传入信息和内存。
如图3所示,AC-LSTM是用CNN和RNN设计的.当前特征映射(X)和先前隐藏状态(ht−1)作为注意模块的输入。经过三层卷积后,生成一个单通道注意映射(A),其中包含目标感知特征的像素级位置,用于在ac-lstm a中选择有用的特征。识别OTA中的对象。应该指出的是,注意力图中的每个元素在[0,1]中都是连续的,而不是二进制选择(注意区域为1,否则为0),以描述物体的显著质量m。有效矿石。对于特征选择,当前特征映射的每个通道都将该注意映射像素与像素相乘,并且可以获得注意感知特征(a◦x)。注意意识特征与p反向隐藏状态作为ConvLSTM的输入连接。与传统的LSTM不同,门(I,f,o)和输入信息(C)将用卷积运算[12]计算。随后,由门控制,时间内存将被更新,并生成当前隐藏状态以进行多盒回归和分类。在该操作期间,单位X、I、F、O、C、S、H具有相同的尺寸。此外,我们还在训练期间使用脱落正则化[39]用于注意感知特征。显然,时间格式不格式离子传输在时间上的注意和convlstm中进行两次。
注意,注意力机制和输入门扮演着不同的角色,尽管它们都可以意识到有用的特性。对于背景抑制和尺度抑制,注意机制工作在每个二维地图的空间定位,而输入门可以处理沿通道的三维特征,以保留鉴别数据。
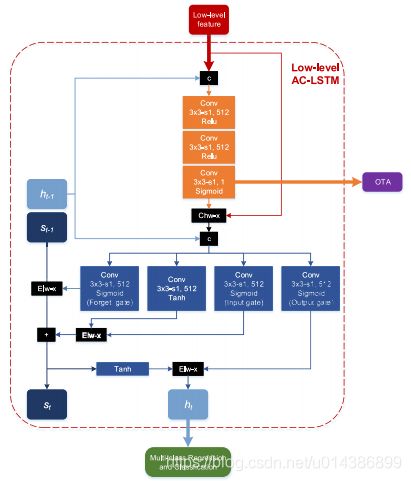
图示(三)AC-LSTM的实施细节。“c”表示串联;“Chwx”和“Elwx”表示信道方向和元素方向乘法;“+”表示元素的求和。基因。使用额定隐藏状态进行检测,而AC-LSTM和OTA都使用注意映射。
B.训练
我们设计了一个训练TSSD的多任务目标,包括定位丢失lloc、置信度丢失lconf、注意丢失latt和关联丢失lasso。
其中M是匹配框的数目,α,β,γ和ξ是权衡参数。LLOc和LCONF是根据SSD[7]定义的。然后,我们对TSSD进行了三个步骤的训练。
1)注意力损失:
使用交叉熵来监督注意力图的产生。首先,构建了地面真值表AG,其中地面真盒中的元素等于1,其余元素为:0、多盒预测有6个特征图,生成多尺度关注图![]() 。因此,每个
。因此,每个![]() 首先通过双线性上采样操作统一到与输入图像相同的分辨率,然后再生成
首先通过双线性上采样操作统一到与输入图像相同的分辨率,然后再生成![]() 。每个放大的注意图可以产生具有交叉熵的尺度相关注意损失,我们将六尺度损失相加作为最终的注意损失。然后,拉特可以被赋予作为。
。每个放大的注意图可以产生具有交叉熵的尺度相关注意损失,我们将六尺度损失相加作为最终的注意损失。然后,拉特可以被赋予作为。
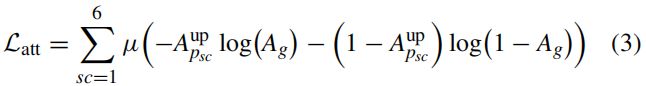
其中μ平均一个矩阵中的所有元素。
2)关联损失:
像素级的变化会对检测结果产生很大的影响,因此视频中的对象在静态检测方法中总会遇到很大的分数波动(在[16]中进行了研究)。这样,朝向t视频的一致性,序列训练需要建立关联损失。为此,我们鼓励TSSD为连续帧生成类似的全局分类结果。我们首先计算NMS后的每个类的最高k个高预测分数,然后将它们相加到根定义类区分分数列表(SL)。分数列表应在连续帧中保持较小的波动。由此,可以获得![]() :
:
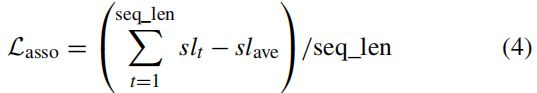
其中![]() 是时间步长t的分数列表;从表示
是时间步长t的分数列表;从表示![]() 之间的平均分数列表;seq_len表示序列长度。应该指出的是,我们提议的关联损失工程。以自我监督的方式。也就是说,在计算
之间的平均分数列表;seq_len表示序列长度。应该指出的是,我们提议的关联损失工程。以自我监督的方式。也就是说,在计算![]() 时,没有来袭的地面真理标签。
时,没有来袭的地面真理标签。
3)多阶段训练:
我们首先按照[7]训练一个SSD模型。在下一步,TSSD是基于训练有素的SSD进行培训的..我们冻结网络中的权重,除了AC-LSTM和检测头..尤其是,ConvLSTM用RMSProp[36]训练,其余的TSSD用SGD优化器训练,初始学习速率为10−4,衰减率为0.1。30年代学习率下降。另一方面,TSSD应该使用一系列的帧进行训练,但是视频的帧速率是不稳定的。此外,物体的运动速度S在视频中差别很大。为了更好地推广,不应逐帧训练。相反,我们只选择视频中的seq_len帧作为迭代中的反向传播。塞克伦基于开始帧SF和跳过SP,即随机跳跃采样(RSS),即,
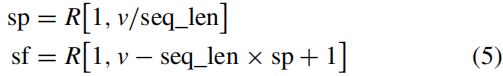
其中v是视频中的帧总数,R[min,max]表示在最小和最大之间随机选择整数的操作。最后,用s选择了均匀的seq_len帧。f作为起始框架,sp作为跳过。在本文中,seq_len=8。在这一步中,关联损失![]() 不涉及。
不涉及。
第三,全部目标包括![]() 用于对参数进行十次微调。在这一步中,学习速率为10−5,sp=1。根据模型性能选择了超参数α=1,β=1,γ=0.5,ξ=2,δ=3。
用于对参数进行十次微调。在这一步中,学习速率为10−5,sp=1。根据模型性能选择了超参数α=1,β=1,γ=0.5,ξ=2,δ=3。
C.推理
在推理阶段,LH-TU和AC-LSTM跨时间集成特征,为回归和分类生成时间感知的隐藏状态。最后,我们将jaccard overla应用于nms。p(IOU)为每级0.45(ImageNet Vid)或0.3(2 DMOT 15),并保留前200(ImageNet Vid)或400(2 DMOT 15)的高可信度检测,以产生最终检测。
D.OTA-Online Tubelet Analysis
对于在线跟踪检测任务,预计TSSD具有识别对象的能力。[16]、[20]和[37]对[16]、[20]和[37]录像中的图贝尔进行了研究,每一个都有唯一的身份(ID)。在检测范围内,[16]通过跟踪生成管状,而[20]和[37]则使用管状提议进行批式检测。但是,这些方法要么是计算方法,要么是计算方法。或者是昂贵的或不在线的。因此,我们试图利用基于管道的实时在线对象关联方法进行跟踪检测。
检测器中的特征不适合识别,因为它们总是包含类内相似的信息.幸运的是,我们的框架中有一些独立于类别的特性,即注意地图。注意力图描述的是不同视觉尺度下物体的显著质量,而不是对每一类别的区分。因此,将注意力空间用于快速。数据关联。这个概念简单易懂,计算灵活,关键的直觉是物体的显著质量是彼此不同的,注意力机制可以捕捉到。这种微妙的独特性。低级别的AC-LSTM用于这项任务,因为低级别的特性涵盖了更详细的信息.总之,注意地图有三个优点可以识别。阿尔法。
1)我们不再需要额外的与实例相关的训练。
2)它们是描述对象显着性质量的实例感知特征。
3)计算成本低。也就是说,当每个物体的空间大小被采样为7×7时,注意向量的长度为147,而如果是低水平的壮举,则增加到75 267。不需要任何其他操作,就可以使用ures或相应的隐藏状态。
因此,两个对象i和j之间的注意相似度可以表示为余弦距离。

其中av表示由双线性采样的多尺度注意映射平坦的147维注意向量.
此外,视频中的识别可以利用更多的时间一致性,因此我们也在OTA中使用IOU o。由于一个筒体中有多个对象![]()
在物体obj和管状浴缸之间可以给出如下所示
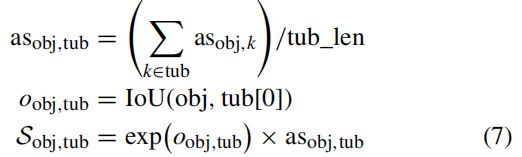

其中BUB_LEN是管状体的当前长度,BUB[0]表示最近的对象。
定义![]() 和
和![]() 分别表示管道生成分数和匹配阈值。假设每个检测到的对象被描述为obj[conf,locc,av],并且每个类不同的小管被表示为桶[CLS],每个小管被给予桶[ID,OBJs],OTA算法在算法1中提出,其中objid表示带有标识id的对象,id=−1表示没有标识的对象。Len(·)计算元素数。附注t在更新管束时,最大存在时间和最大管束长度受到限制。
分别表示管道生成分数和匹配阈值。假设每个检测到的对象被描述为obj[conf,locc,av],并且每个类不同的小管被表示为桶[CLS],每个小管被给予桶[ID,OBJs],OTA算法在算法1中提出,其中objid表示带有标识id的对象,id=−1表示没有标识的对象。Len(·)计算元素数。附注t在更新管束时,最大存在时间和最大管束长度受到限制。
四.实验和讨论
A.数据集
1)ImageNet VID:
我们在ImageNet VID数据集[25]上对TSSD进行了评估,这是目前用于时态对象检测的最大数据集。该任务需要算法来检测连续帧中的30类目标.那里培训集中有4000段视频,包含1 181 113帧。另一方面,验证集555个视频,包括176 126帧。我们在下面的验证集上用平均精度(MAP)度量30个类的性能。3]和[7]。此外,Image NetDET数据集被用作培训辅助工具。VID数据集中的30个类别是DET数据集中200个类别的子集。
因此,在[15]、[16]、[20]和[21]之后,我们使用VID和DET对SSD进行了培训(仅使用来自30个VID类的数据)。实际上,在vid培训集中有数百万帧,所以很难训练一个直接使用他们的网络。此外,每个类别的数据都不平衡,因为有长视频(包含1000多帧)和短视频(只包含do)。(禅宗框架)因此,在[21]之后,我们从DET中每类采集最多2000幅图像,并在每个VID视频中选择10帧作为第一步的SSD培训。在第二和第三阶段的训练中,所有的VID培训视频都采用了。
2)2 DMOT 15:
TSSD-OTA是一种身份感知检测器,因此采用2 DMOT 15数据集[41]来评估跟踪性能。这是一个由11个训练序列组成的多目标跟踪。因为安仅用于培训集,我们将五个视频分割为[23]和[43]之后的验证集。此外,采用了在Mot17DET[42]数据集中的另三个视频序列F或者训练。
B.运行时间性能
我们的方法是在PyTorch框架下实现的。实验在一个工作站上进行,工作站上有Intel 2.20 GHz Xeon E5-2630 CPU、NVIDIA Titan-X GPU、64 GB RAM、CUDA 8.0和CUD。NNV6。在表I中描述了推断时间,并且我们实现了用于时间检测或跟踪的超过实时速度。
C.关于ImageNet VID的研究
1)LH-TU:
我们建议的LH-TU在以下几个方面是有效的.首先,避免了冗余参数。例如,原始SSD包含2.6M参数,而具有LH-TU的SSD包含4.9M参数。..然而,如果每个特征图使用6个ConvLSTM,则参数大小将急剧增加到15.5M,从而导致训练不稳定。第二,如[23]所述,Conv 4_3和Conv 11_2对检测的贡献相对较小。也就是说,对于超大或微小的对象,有少量的数据.因此,最高层a如果使用六级ConvLSTM,那么最低水平的ConvLSTM很难得到良好的训练.我们发现,当使用两个ConvLSTM作为时态单位时,使用LH-Tu时,MAP增加了0.92%。e ConvLSTM带来的特征集成。
2)AC-LSTM:
首先,定性地分析了注意机制与ConvLSTM的相互作用。如图4所示,对时间和传统的注意机制进行了比较。注THA传统的注意力只使用当前特征图作为输入。至于图4所示的热图,深红的意思是更高目标的概率,而马扎林则表示背景特征。
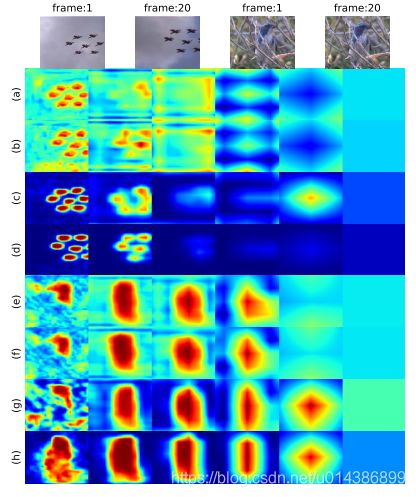
图4.ConvLSTM对注意力机制的影响。有两个视频片段包含小物体(飞机)或野生环境(鸟)。传统注意与时间注意机制被用来生成多尺度的注意图,在这种地图中,深红表示更高层次的关注,而Mazarine表示被忽略的事物。(A)和(B)飞机通用注意地图由传统模块实现。(C)和(D)时态模块生成的飞机注意地图。(E)和(F)传统模块制作的鸟类注意地图。(G)和(H)b注意图时域注意法生成的税务局。在上述4对地图中,前者用于第一帧,后者相对于第20帧。(A)-(H)中的每一行都是多尺度注意力图从左到右,它们分别用Conv 4_3、Conv 7、Conv 8_2、Conv 9_2、Conv 10_2和Conv 11_2生成。
此外,在TSSD中生成多尺度注意映射,并生成具有更高层次特征的多尺度注意映射。为便于观察,图4和图5中的所有地图都已统一。通过双线性上采样操作,达到与输入图像相同的空间分辨率。
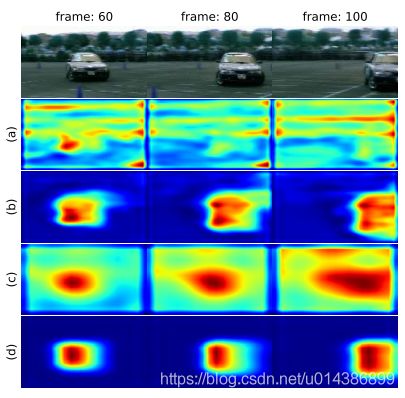
图5.时间注意力对ConvLSTM的影响。ConvLSTM的内存是可视化的(通过计算每个空间位置的特征通道的L2范数来获得显着性地图)。奥里吉用于(a)Conv4_3和(c)Conv7的Nal ConvLSTM内存。用于(B)Conv4_3和(D)Conv7在AC-LSTM中的内存。

我们为这个测试选择了两个具有挑战性的场景。飞机框架包括小物体,并且鸟架包含丰富的条纹,这两者都难以注意操作。如所描绘的在图4(A)、(B)、(E)和(F)中,原始的注意方法无法处理这两个场景。也就是说,虽然目标是粗略的聚焦,但背景和小贡献的多尺度特征地图并没有得到有效的抑制。此外,时间序列之间没有任何改善。奥相反,如图4(C)、(D)、(G)和(H)所示,拟议的注意机制表现得更好。总之,我们的方法不仅能更准确地定位目标,而且能更有效地抑制背景。此外,我们的方法是有效的规模抑制。例如,小o飞机框架中的物体用Conv4_3描述。如图所示。第4(d)段,Conv4_3和Conv7飞机的注意地图定位,最后四张地图都是“冷的”。也就是说,当它来的时候。对于更大的尺度,我们的注意机制找不到任何目标,所以整个特征图都被抑制了。此外,性能随着时间信息的积累,所提出的方法得到了改进。例如,在图4(G)和(H)中,Conv_4_3的注意图很难找到第一帧中的鸟,但是在第20帧中,E鸟的轮廓是集中的,没有过多的背景。此外,如果比较第一帧的注意映射,可以得出结论,时间注意方法是。更好的是,即使时间信息还没有生成。究其原因,在于时间注意力可以得到更有效的训练。
另一方面,与传统的ConvLSTM相比,AC-LSTM有一些好处.参照图5,将ConvLSTM对Conv_4_3和Conv_7的记忆可视化。小型内存处理图像详细信息,但是convlstm无法生成有效的内存,因为它被肌肉功能混淆了,而ac-lstm能够在没有背景的情况下记住汽车的基本信息(请参阅fi)。g.5(A)和(B)]。考虑到汽车的规模,Conv 7对于检测它来说更为关键。如图5(C)所示,ConvLSTM对于Conv 7有一种学习简单表示的倾向。输入。此外,这种记忆也涉及到背景。因此,并不是所有这些信息都对未来的检测有用,它们可能会产生不准确的结果。相反,ACLSTMpro引入更清晰的内存和关键功能(见图5(D)。然而,我们不能得出结论最佳的时间学习长度..


图6.检测性能与θ的对比。此图显示模型性能与关联损失中的置信阈值θ的函数关系。
因此,AC-LSTM从以前的所有帧中学习,并且在其遗忘门的控制下,有效内存的长度取决于特定场景中的顺序学习。由于上述rEasons,AC-LSTM带来的改善是明显的,即在SSD的基础上地图上升了1.60%。
3)多阶段训练:
上述分析不涉及第三个培训步骤和RSS。如表二所示,虽然在第二个训练阶段它只带来0.14%的地图改进,但RSS使它成为可能。进行第三步训练。在没有关联损失的情况下,经过最后一步,我们得到了65.13%的地图,但![]() 可以进一步改进。
可以进一步改进。
在第三个培训步骤中采用关联损失,其中sp=1确保培训数据高度相关。考虑到使用的NMS,有三个参数设置。计算关联损失,即置信阈值θ、IOU阈值和顶k保留框。由于NMS的存在,保留框数相对不敏感,IOU阈值与推理阶段一致。因此,![]() 的主要含义是θ,Wich表示应该涉及哪种对象。如图6所示,地图通常随着θ的增加而减少。也就是说,当θ=0.01时,会考虑过多的无效框。而
的主要含义是θ,Wich表示应该涉及哪种对象。如图6所示,地图通常随着θ的增加而减少。也就是说,当θ=0.01时,会考虑过多的无效框。而![]() 却逐渐失去了效力因为所涉及的物体的减少。因此,考虑到当θ=0.1时,几乎所有阳性样品,LASSO是最有效的。多步训练使MAP提高0.8%,TSSD提高65.43%。
却逐渐失去了效力因为所涉及的物体的减少。因此,考虑到当θ=0.1时,几乎所有阳性样品,LASSO是最有效的。多步训练使MAP提高0.8%,TSSD提高65.43%。
4)与其他建筑的比较:
我们还比较了TSSD与以前和当代的几种方法。如表三所示,它们的构成部分和性能已作了总结。大多数方法都是建立在两级探测的基础上的。R与RPN的区域建议,很少有方法成功地采用注意或LSTM的时间相干性。此外,TCNN[16]和D&T[21]中的跟踪是提高召回率的好方法,但在一定程度上影响了时间效率。在骨干方面,一些基于t的方法。他ResNet-101可以实现更高的地图,但这个更深层次的骨干并不适合我们的任务.参考[49],在处理SSD中的小尺寸图像时,ResNet-101在准确性方面有一个不可忽视的优势。主要原因是两阶段方法通常利用大量的输入大小(例如,1000×600),因此更深的骨干可以更有效地学习这些更丰富的视觉特征。然而,我们的单级检测器使用300×300输入图像,且视觉特征相对不足,推理速度较快,因此ResNet-101的优势可以忽略不计。另一方面,有些以批处理方式(即离线方法)处理视频序列,在该模式下,未来的帧也被用于当前帧检测。因此,这种非因果方法是禁止在现实世界的应用。由于tsd的实时性和在线特性,它能够为实际应用程序临时检测对象。.根据作者的知识,我们的方法有以下优点。
1)TSSD是第一个以VGG-16为骨干,输入图像小,MAP达到65%以上的时序单级检测器。
2)TSSD-OTA是一个统一的框架,其中实时在线检测器能够对目标进行检测和识别。在现有的视频检测方法中缺乏这一框架。
5)质量结果:
我们在图7中的ImageNetVID验证集上显示了一些定性的结果。我们只显示分数大于0.5的检测边界框。

图7.ImageNet VID验证数据集上的演示结果。所提出的TSSD(-OTA)能够更准确地处理多目标的各种场景。另外,与tra不同的是传统的检测器,我们的方法有识别能力。检测结果显示为“ID:class:Score”。ID=−1表示没有生成标识。
不同颜色的边框表示不同的对象标识。所提出的TSSD具有较好的精度和时间稳定性。
D.2 DMOT 15数据集的跟踪性能
我们使用2DMOT 15数据集共同调查TSSD-OTA,其指标是为跟踪而设计的。MOTA考虑了综合跟踪性能,MOTP对跟踪性能进行了严格的度量。跟踪结果和地面真相。FP和PN分别表示假阳性和假阴性的总数。对于每个轨道,如果超过80%的位置是suc成功地跟踪,MT增加1。另一方面,如果超过80%的位置丢失,ML增加1。最后,IDS计数ID切换次数。
1)参数分析:
在OTA中有三个参数,,即匹配阈值T,管束生成分数G和管状长度的浴缸。要跟踪每个检测到的对象,![]() 应该等于检测器的置信阈值Conf和T,BUB_LEN会影响跟踪性能。我们让conf=G=0.3,Tub_len=10,考察T的影响。采用Mota和IDS的变化来表示跟踪性能的变化。参考图8(A),Mota和IDS受到T的强烈影响。并且对于我们的验证集,t=1.0是最优的。也就是说,如果T太高失败匹配的数量将增加。另一方面,较低的T会导致错误匹配。失败和错误匹配都会削弱跟踪性能。然而,如图8(A)所示,失败的比赛有更大的影响,因为
应该等于检测器的置信阈值Conf和T,BUB_LEN会影响跟踪性能。我们让conf=G=0.3,Tub_len=10,考察T的影响。采用Mota和IDS的变化来表示跟踪性能的变化。参考图8(A),Mota和IDS受到T的强烈影响。并且对于我们的验证集,t=1.0是最优的。也就是说,如果T太高失败匹配的数量将增加。另一方面,较低的T会导致错误匹配。失败和错误匹配都会削弱跟踪性能。然而,如图8(A)所示,失败的比赛有更大的影响,因为![]() 。防止OTA错误匹配过多。如图8(B)所示,IDS也先减少后增加,当浴缸上升时(T=1.0)。如果BUB_LEN=1,则匹配过程仅依赖于最近的对象,因此对于某些紧急情况(例如遮挡)是不可靠的。然而,超大型的BULEN将保留远程信息CH可能导致不准确。
。防止OTA错误匹配过多。如图8(B)所示,IDS也先减少后增加,当浴缸上升时(T=1.0)。如果BUB_LEN=1,则匹配过程仅依赖于最近的对象,因此对于某些紧急情况(例如遮挡)是不可靠的。然而,超大型的BULEN将保留远程信息CH可能导致不准确。

图8.跟踪性能相对于(A)匹配阈值T和(B)管状长度tub_len。

我们还揭示了IDS注意映射的有效性,参数为CONF=G=0.3,BUB_LEN=10,T=1.0。注意,大小为1×1的Conv 11_2的注意映射不是定性的。ED为了识别,所以它没有涉及到这个测试。参考表IV,仅用IOU计算S时,IDS等于550(T=0.5和S=0)。注意力图的有效性是很明显,IDS因此下降了大约60%。此外,随着视觉尺度的增加,效果也逐渐下降,因为高级特征通常包含更多类内相似的信息。在……上面。在此基础上,结合多尺度注意映射计算S,得到了在低层交流LSTM中使用注意映射的最佳结果。
2)跟踪结果:
在BUB_len=10,T=1.0,CONF=G=0.3的条件下,利用TSSDOTA对2DMOT 15数据集中的行人进行跟踪。参考表五,f中描述了FPS总速度/跟踪部件速度的ORM。结论是基于与以往和当代方法的比较,所提出的TSSD-OTA可以在超越实时的框架下运行,同时保持可比较的跟踪性能。关于THEMT和ML,FasterRCNNSORT性能更好,因为两级检测器对召回率有很好的效果.在MOTA的情况下,SSD-ALSTM由于其基于LSTM的跟踪组件而更好.不过他们的解决方案有一个很大的缺点,那就是时间成本太高。造成建议的TSSD-OTA在某些标准上不能等同于比较方法的主要原因有两个。
1)在2DMOT 15数据集中存在着大量的小目标,但是我们的检测器在处理这些小目标时并没有采用如此小的输入图像。
2)与大多数方法不同的是,我们的模型是在不涉及身份或关联的情况下进行优化的。在本实验中也不采用建议的关联损失,我们将解释第IV-E节的理由。
然后,以TSSD作为检测器,对OTA和排序[45]进行了全面的比较。如表V所示,我们在Mota、MT、ML、FN和IDS上实现了更好的索引。也就是说,OTA生成打赌。跟踪性能,同时保持较高的处理速度。
3)质量结果:
如图9所示,拟议的TSSD-OTA能够在各种场景中跟踪行人,我们演示了一些典型的结果。在图9的第一行中,#56位于最初的尺寸很小,然后随着视觉视角的改变而变大。因此,TSSD-OTA能够适应这种持续的规模变化.第二行航天飞机中的#149人群,它经历了光照的变化。尽管如此,这一具有挑战性的目标被TSSD-OTA跟踪得很好。图9的第三行有混沌的小物体,它们相互封闭。然而,我们的方法在#0、#3、#4、#23、#30等方面运行良好。不幸的是,在这个场景中出现了一些失败的情况,例如ID开关(#15→#39,#26→#23,#34→#30)和false。负片(#4,#49)。
E.讨论
我们使用ImageNetVID和2DMOT 15数据集进行实验,它们在视频量(4000比8)、类数(30比1)和度量(MAP对Mota等)方面有很大的不同。在……里面此外,2DMOT 15包含巨大的小对象,而VID则包含各种各样的场景。因此,我们将详细讨论以下主题。
1)RSS:
如表二所示,采用RSS后,MAP仅增加0.14%。然而,减少的数据量突出了对此的需要。例如,如果没有rss,TSSD就无法接受良好的培训。2 DMOT 15数据集,导致Mota在第三步训练后下降1.4。显然,这种现象是由训练数据的多样性造成的。也就是说,由于各种场景i在不使用RSS的情况下,可以保持数据的多样性。不幸的是,当训练2DMOT 15数据集时,这个技巧不能被忽略,因为只有8个被雇用的视频。

 图9.在2DMOT15验证数据集上的演示结果。该TSSD-OTA可以跟踪行人在各种多目标场景。每个对象的标识在框上表示,以及一些r。呈现结果以红色、绿色、蓝色或橙色表示。
图9.在2DMOT15验证数据集上的演示结果。该TSSD-OTA可以跟踪行人在各种多目标场景。每个对象的标识在框上表示,以及一些r。呈现结果以红色、绿色、蓝色或橙色表示。
由于我们的关联损失需要连续采样,因此在2DMOT15培训期间不采用..
2)关联损失:
这不是第一次设计关联损失。例如,Lu等人。[23]还利用它来训练LSTM。与以前的设计不同,我们的协会损失主要集中在glo上。BAL分类而不是每个相关的对象对,放弃了在训练过程中引入身份地面真相标签的需要。这是必要的,因为检测数据集通常不涉及标识标签,或者收集ID标记数据是一项昂贵的工作。虽然OTA可以生成对象标识,但它不适合。能够计算关联损失。也就是说,由于缺乏ID标签,OTA也不能被监督,因此在训练期间它的错误是直接不可校正的。此外,OTA是紧密依赖的。对于TSSD的结果,如果TSSD没有得到良好的培训,则无法正常运行。如果使用OTA来计算关联损失,则可能出现一些匹配误差,使得训练过程不稳定。
3)准确性和速度之间的权衡:
在我们的实验中,SSD、SSD ConvLSTM和SSDAC-LSTM的平均推理时间分别为0.022 s、0.026 s和0.037 s.因此,注意模块对检测结果的影响较大。因为它执行三层卷积(convlstm只需要一层卷积)。因此,简化注意模块有利于提高推理速度,但注意性能也明显下降。另外,ConvLSTM的特殊设计可以提高速度。L,例如瓶颈-LSTM[27]。时间信息的综合方法是提高检测精度的关键步骤。一方面,单目标跟踪[21]比LSTM更有效.(请注意,多目标跟踪或检测跟踪方法,如ota,不能用于此目的,因为它(每一时间步骤都需要检测结果。)然而,单目标跟踪方法通常会对推理速度产生不利影响.另一方面,众所周知,SSD的性能是伴随着一系列的数据增强而来的,例如,SSD随机扩展了原始的训练图像,并通过附加的随机光网络来生成原始的训练图像。三次失真[7]。然而,现有的数据增强方法大多不适用于序列学习(即它们会改变时空关系),因此第二次和第三次训练是第二次和第三次训练。EPS不包括任何数据增强。因此,在训练过程中利用序列数据增强可以进一步提高检测精度。总的来说,tsd实现了一个合理的tra。准确性和速度之间的差距。
4)OTA:
对于OTA,有一些类似的方法,例如[50]和[51],分析了时空作用。
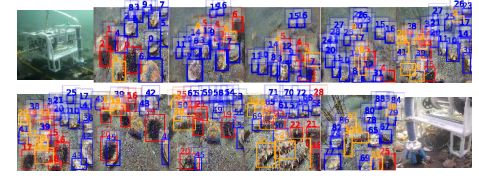
图10.海底物体抓取和数量统计。海胆、扇贝和海参分别用红色、蓝色和橙色展示.对象的标识在o顶部表示。f盒子。除了计算物体的数量外,TSSD-OTA还可以定位每个目标个体进行抓取.
这些方法和OTA有一个类似的目的,即将检测到的框连接到现有的管道以进行数据关联。然而,我们有两个关键优势:
1)首先使用IOU阈值选择“候选人”。相反,我们将IOU阈值视为影响相似度的权重[见(7)],因此OTA可以在计算上更好地发挥作用。好色的。
2)现有方法中的匹配分数通常是基于管道成员检测框的类分平均值。
这些类别的分数可能会受到不稳定波动的影响,因为像素级的变化可能会显着地影响检测分数。此外,[50]和[51]中的方法只处理一个小数值。对于多目标跟踪任务,需要考虑具有相似类分的数十个目标。因此,[50]和[51]提出的方法不足以区分跟踪。无数的物体。相反,我们使用来自时间检测器的注意向量来描述物体的显著质量,而盒和管束之间的匹配则是基于注意力的相似性。矢量。因此,OTA支持特征级匹配.
F.现实世界的应用
如图10所示,我们使用遥控飞行器(ROV)在海底进行了实际实验。配有摄像机作为视觉引导,ROV长0.68米,宽0.57米,身高0.39米,体重50公斤。测试地点位于中国大连张子岛,水深约为10米。对于人类来说,管理海底产品(例如海胆,(扇贝、海参等)是非常困难的。此外,他们的收藏一直是一个大问题。为此,我们利用ROV来代替人类从事这项艰苦而危险的工作。此外,在这一策略中,TSSD-OTA是至关重要的.一方面,当ROV直线行驶时,我们提出的方法能够准确地计算出各类海产品的数量。在最上面呃,不同于传统的检测方法,TSSD-OTA能够定位每个目标个体进行抓取。完整的视频演示可在https://youtu.be/v3L上获得。GO异常
五.结论
本文旨在对实时目标进行实时检测和识别,以满足实际应用的需要.创意建议采用TSSD。不同于现有的视频检测方法,TSSD是一种时间一级检测器,它可以很好地根据检测精度和推断速度执行。为了提出了一种高效集成金字塔特征层次结构的LH-TU,其中高层特征和低级特征共享各自的时间单元。此外,我们还设计了一个AC-lst。M作为一个时态分析单元,其中时态注意机制负责背景抑制和尺度抑制。本文还提出了一种新的关联损失函数和多步训练方法。为序列学习而设计的。此外,OTA算法还使TSSD具有低计算量的辨识能力.因此,tsd-ota看到了相当大的改进。检测精度、跟踪性能和推理速度。最后,我们提出的方法已应用于实际应用。
未来,我们计划进一步提高TSSD-OTA的推理速度.此外,TSSD-OTA将用于动态环境下的机器人视觉导航.