M-LSD 面向轻量化实时线段检测
摘要
之前的基于深度学习的线段检测(LSD) 模型大且计算耗时。这限制了他们的实时性和使用环境。 在这个 论文中,我们提出了在资源受限的环境下的一种实时的、轻量级的线段检测器Mobile LSD (M-LSD)。 我们设计了一种非常高效的结构,通过最小化骨干网络和去除典型的多模块流程进行直线预测。为了在一个轻量级的网络中保持竞争性能,我们提出了新的训练方案:线段分割增强(SoL)、匹配和几何关系损失函数。 SoL增强将一条线细分成多个子部件,用于在训练过程中提供辅助线端数据。 此外,匹配和几何损失允许模型捕捉额外的几何线索。 与以前最好的实时LSD方法TP-LSD-Lite相比,我们的模型(M-LSDtiny)以2.5%的模型达到了具有竞争力的性能,GPU上的推断速度提高了130.5%。此外,我们的模型可以以56.8 FPS和48.6 FPS运行在最新的Android和iPhone移动设备。 据我们所知,这是第一次实时深度 移动设备上可用的LSD。 且代码是开源的,开源地址:https://github.com/navervision/mlsd
1、介绍
线段和连接是重要的低级视觉特征,为更高层次的视觉任务提供了基本信息,如姿势估计、运动结构恢复、3D重建、图像匹配,线框到图像平移和图像校正。 此外,执行此类视觉任务的需求日益增长,在资源受限的平台上,如移动或嵌入式平台 ,实时线段检测(LSD) 这是一项必要但具有挑战性的任务。 主要的困难来自于有限的计算能力和模型大小,我们需要找到速度和精度的平衡。

图1 M-LSD与现有LSD方法在Wireframe数据集的比较。 GPU单元为Tesla V100 GPU。 M-LSD可以说是又快、又好,模型还小。
随着深度神经网络的出现,基于深度学习的LSD架构已经采用模型来学习线段的各种几何关系,并已被证明性能的有所提高。
如图2所示,我们总结了多种使用深度学习的LSD学习模型策略。自上而下的策略首先检测具有一定关注度的区域,然后将这些区域进行线段预测。而自底向上策略则是先检测节点,然后将其排列成线段,最后使用一个额外分类器对线段进行验证,或合并算法。 最近,(Huang et al. 2020)提出三点式(TP)表示法的直线化过程比较简单,无需耗时的线段建议和验证步骤的预测。

图2 a 以往的LSD方法采用多模块处理进行线段预测。 相比之下,我们的方法利用单个模块直接从特征图中预测线段。
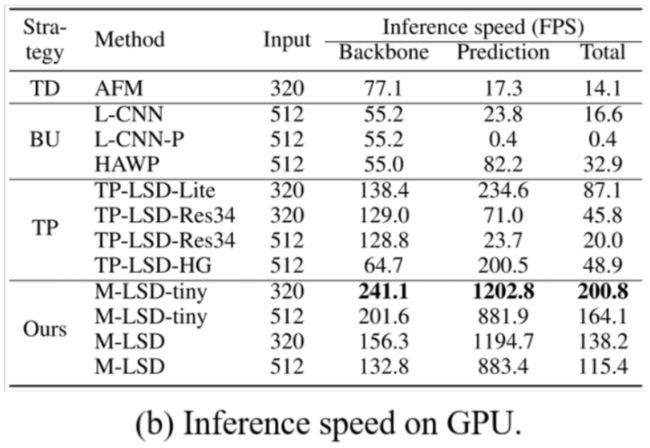
图2 b 我们的方法显示了卓越的速度
尽管之前使用深度网络的努力已经在LSD的实时推理方面取得了显著的成就,然而在资源约束平台上仍然是受限制的。已经有人尝试展示实时LSD,但它们仍然依赖于服务器级gpu。这主要是因为使用的模型利用了比较重的骨干网络。 此外, 如图2a所示,线段预测过程由多个模块组成整体推理速度较慢,如图2b所示。 因此,计算成本的增加使得在资源约束平台上部署LSD变得困难。
在本文中,我们提出了一种实时性和轻量化的方法用于资源受限环境的LSD,命名为Mobile LSD (M-LSD)。 对于网络,我们设计了一个显著高效的体系结构,用单一模块进行预测线段。 通过最小化网络大小和删除以往的多模块处理方法相比,M-LSD具有非常轻、非常快的优点。我们提出了新的训练方案:SoL增强、匹配和几何损失。SoL增强将线段划分为子段,进一步用于在训练阶段提供增强线数据。 匹配和几何损失附加额外的几何信息训练模型,包括线段之间的关系、结点与线段的分割、长度与角度的回归。 因此,我们的模型是能够在训练中捕捉额外的几何信息,做出更准确的直线预测。 此外,提出的训练方案可以与现有方法结合使用,以即插即用的方式进一步提高性能。
如图1所示,我们的方法具有竞争力性能和更快的推理速度与一个小得多模型的尺寸。 M-LSD优于以前的实时方法,TP-LSD-Lite (Huang et al. 2020),仅为6.3% 在模型大小的基础上,推理速度提高了32.5%。 此外,M-LSD-tiny的实时运行速度为56.8FPS,最新Android和iPhone手机的FPS和48.6 FPS 设备。 据我们所知,这是移动设备上的第一个实时LSD方法。
2、相关工作
深度线段分割检测。关于基于深度学习的LSD的研究一直很活跃。 在junction-based方法,DWP包括两个平行预测分支线和结点的热图,紧随其后进行合并。PPGNet和L-CNN利用了基于连接的方法,线段表示法用一个额外的分类器来验证一对点是否属于同一线段。另一种方法使用密集预测。最近,提出TP- lsd,该网络网络的两个分支:TP提取分支和分割分支。 其他方法 包括使用Hough通过深度网络进行转换。 然而,通常可以看到,上述的多模块在资源受限的环境中使用受限。
实时目标检测器。实时目标检测已成为基于深度学习的对象的重要任务。早期的目标检测器,分为来年各个阶段。一阶段进行区域建议,然后进行二阶段的判别。yolo、ssd系列算法使用一阶段检测。 通过减小主干尺寸实现GPU实时推理,将两个阶段的过程简化为一个阶段。 在此基础上进一步研究和改进了单级体系结构在移动设备上实时运行。 由于目标检测体系结构从两阶段到一阶段的转变,我们认为以前LSD中复杂的多模块处理可以忽略。 我们用一个模块简化了直线预测过程,提高了推理速度,并通过有效的训练策略提高了性能。
3、直线检测器M-LSD
在本节中,我们将介绍M-LSD的详细信息。 我们的设计主要关注效率,同时保持效果。 首先,我们利用了一个轻量级的骨干网络,减少了复杂的模块设计以提高推理效率。 接下来,我们使用额外的训练方案:SoL提升,匹配和几何损失,用来捕捉额外的几何线索。 结果表明,M-LSD能够在精度和效率之间取得平衡,非常适合移动设备 。
3.1、网络结构
我们设计了轻(M-LSD)和轻(M-LSD-tiny)的模型作为流行的编码器-解码器架构。为了建立一个轻量级的LSD模型,我们的编码器网络是基于MobileNetV2 (Sandler et al. 2018)。 编码器网络使用了MobileNetV2结构使其更轻量。如图3所示,M-LSD的编码器包含96通道的bottleneck blocks。 编码器网络中的参数数量为0.56M(占MobileNetV2的16.5%),MobileNetV2的总参数为3.4M。 M-LSD-tiny是一种略小但速度更快的模型,编码器网络还使用MobileNetV2结构,包括64通道的bottleneck blocks ,结果为0.25M(7.4%的MobileNetV2)。解码器网络是采用块的组合设计的类型A, B,和C。这里不好描述,看图。

图3:M-LSD的总体架构。 在特征提取器中,第1 ~ 14块是MobileNetV2的一部分,第15 ~块是MobileNetV2的一部分 其中23个被设计为自顶向下的架构。 预测线段是由中心和位移图生成的。
如图2b所示,我们观察到其中多模块的预测过程是影响推理速度的关键瓶颈。在本文中,我们认为复杂的多模块可以忽略。见图3,我们直接从最终的特征图预测线段。 在最后的特征图中,每个特征图通道都有自己的作用:
1) TP图有7个特征图,包括一个长度图,一个角度图,一个中心图,和四个位移图;
2) SoL图有7个特征图与TP图有相同的意义;
3) 分割图有两个特征图,包括节点和线段图。
3.2、线段分割表示
线段表示方法最终影响LSD的效率。 因此,我们引入TP表示(Huang et al. 2020) ,TP是一个简单的线生成过程,并可在GPU上实时LSD。TP表示使用三个关键点来描述线段:起点、中心和终点。 如图4a所示,开始ls点和结束le点是用两个关于中心lc点的位移向量(ds, de)表示。 直线生成过程是把中心点和位移向量转换成向量化线段分割,表示为:

式中(xα, yα)为任意α点的坐标。ds(xlc, ylc)和de(xlc, ylc)表示二维位移,中心点lc对应于起始点ls和结束点le点。中心点和位移向量使用一个中心特征同一和四个位移特征图训练。 在直线生成过程中,我们通过应用非最大抑制中心的特征图提取了精确的中心点位置。 接下来,我们使用上述简单的算术运算公式提取中心点及其对应的位移向量来生成线段。因此,使推理高效和快速 。

图4a TP表示,图4b SoL增强
3.3、匹配损失
我们使用加权交叉熵(WBCE)损失和平滑L1损失分别作为中心损失Lcenter和位移损失Ldisp。在TP表示下线段表示为中心点和位移向量,两者解耦合分别进行优化。 然而,耦合信息的线段在目标函数中利用不足。

图5 匹配与几何损失
为了解决这个问题,我们提出了一个匹配损失,它利用了真值标记上的耦合信息。如图5a所示,匹配损失通过引导生成的直线来考虑线段之间的关系片段与匹配的GT相似性。我们首先取每个预测的终点,它可以通过线生成过程,测量到GT端点的欧氏距离d(·)。然后,这个距离用于测量真值GT与预测线段的匹配度在阈值 r 下:

ls和le是直线l的起点和终点,γ设置为5像素。 然后,我们得到一个匹配直线的集合M(l, l^)段满足这个条件。 之后,L1损失用于匹配损失,其目的是使损失最小化匹配线段的几何距离、起始点、结束点、中心点,定义如下:
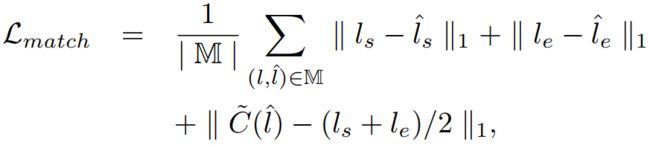
其中C~(l^)是距离中心图的线lc的中心点。TP图的总损失函数可以表示为:
![]()
3.4、SoL 增强
我们提出线段(SoL)增强,这增加了用于训练的不同长度线段的数量。在一些情况下,如:线段的长可能比感受野大或两个不同线段的中心点太近,此时对学习线段中心点和位移向量可能不够 。为了解决这些问题并为TP表示提供辅助信息,SoL显式地将线段分割为多个重叠的子部分。 每个分割之间的重叠是强制的保持子部件之间的连接性 。
如图4b所示,我们计算k个内部划分点(l0, l1, ···, Lk),将线段ls le为k个子部分(ls l1, l0 l2,···,lk−1 le)。 表达TP表示时,每个子部分被训练成一个有代表性的线段。 内部分割点的个数k由线段的长度k=[r(l) / (u/2)] -1 决定,其中r(l)为线段l的长度,µ为子段的基长。 注意,当K≤1时,不分割线段。我们通过经验进行设置 µ=输入尺寸× 0.125。SoL的损失函数与TP损失相同,每个子部件都被当为一个单独的线段。 注意线段增强处理只在TP特征图中使用,不在SoL特征图中完使用。
3.5、几何信息学习
为了提高预测的质量,我们纳入了各种线段的几何信息有助于整个学习过程。 在本节中,我们介绍学习LSD的结点、线分割、长度、角度度回归等附加的几何信息。
节点与线段分割。中心点和位移向量与像素级连接高度相关。图3分割图中的线段,端点需由中心点和位移矢量导出。 此外,中心点必须定位在像素级线段上。同时,学习连接和线的分割特征图片段作为LSD的空间注意线索。 如图3所示,M-LSD分割图包括连接特征图和线特征图。 我们构建的以高斯核为中心图进行缩放连接GT图,线GT图采用二值图。 总的分割损失定义为:
![]()
,其中 我们Ljunc和Lline均使用WBCE损失。
长度和角度回归。方向向量可以由线段的长度和角度推导出, 它们可以是为位移特征图提供的额外几何线索。 我们从真值标记中计算长度和角度,并将它标记在每个GT特征图中。接下来,这些值被一个3 × 3的窗口,以便所有相邻像素给定的像素包含相同的值。 如图3所示,我们TP和预测的长度、角度特征图、SoL映射,TP使用原始线段和SoL增强。 由于长度和角度的范围很宽,我们将每个长度除以对角线长度 用于归一化的输入图像。 对于角度,我们除以2π,再加0.5。 总回归损失可以表示为:
![]()
,我们使用平滑L1损失作为Llength和Ldegree的计算。

图6、从TP中心地图生成的显著性地图。 模型数(M1 ~ 4)来自表1。
3.6、最终的损失函数
几何损失函数定义为分割损失和回归损失之和:
![]()
M-LSD的最终损失函数:
![]()
4、实验
在本节中,我们对所提出的方法进行了广泛的消融研究、定量和定性分析。
4.1、实验设置
数据集和评估指标。我们使用两个著名的LSD数据集评估我们的模型:Wireframe (Huang et al. 2018)和YorkUrban (Denis, Elder和Estrada 2008)。 Wireframe数据集包括5000张人造环境的训练图像和462张测试图像,而YorkUrban Dataset有102张测试图像。 遵循经典的训练和测试方案(Huang et al. 2020; Zhou, Qi, and Ma 2019),我们使用来自Wireframe数据集的训练集训练我们的模型,并使用Wireframe和YorkUrban数据集进行测试。 我们使用流行的LSD指标评估我们的模型(Huang et al. 2020; Zhang等2019; 孟等人2020; Xue等人2019a; Zhou, Qi, Ma 2019),包括:基于热图的度量FH,结构平均精度(sAP)和线匹配平均精度(LAP)。
优化。我们在Tesla V100 GPU上训练模型。 我们使用TensorFlow (Abadi等人2016)框架进行模型训练,并使用TFLite 2将模型移植到移动设备。 在训练和测试中,输入图像的大小都被调整为320 × 320或512 × 512,输入增强包括水平和垂直翻转、剪切、旋转和缩放。 我们在M-LSD和M-LSD-tiny中使用ImageNet (Deng et al. 2009)对MobileNetV2部分(Sandler et al. 2018)的预训练权重。 我们的模型使用Adam优化器(Kingma和Ba 2014)进行训练,学习率为0.01。 我们对前5个迭代使用线性学习率,从70个迭代到150个迭代使用余弦学习率衰减(Loshchilov and Hutter 2016)。 我们训练模型为总共150个epoch,批大小为64。
4.2、消融研究和可解释性
表1、M-LSD-tiny在Wireframe上的消融研究。 基线是M-LSD-tiny在只有TP训练结果,M为模型数。

我们进行了一系列的消融实验来分析我们提出的方法。M-LSD-tiny在输入尺寸为512 × 512的Wireframe数据集上进行训练和测试。 如表1所示,所有建议的方案都有助于显著的性能改进。 此外,我们使用GradCam将每个特征图生成的显著图可视化,以分析从每个训练方案中学习到的网络,如图6所示(Selvaraju et al. 2017)。 显著性地图通过计算每个特征地图的梯度来解释输入图像上的重要区域和重要级别。

图6 由TP中心点特征图生成的显著性地图,模型数(M1 ~ 4)来自表1
匹配损失。综合匹配损失表明线预测质量的像素定位精度和性能都有所提高。我们可以看到微弱的中心点显著度,如图6b。这表明,利用中心点和位移向量的耦合信息进行训练可以让该模型具有更多的线路感知功能。
几何损失。添加几何损失可以提高每个指标的性能。此外,该算法的显著性图6c显示,对中心点和线段的关注更明显、更强,它表明几何信息作为训练的空间注意线索发挥作用。
SoL增强。SoL 增广显示出显著的性能提升。在显著性图中在图6c中,w/几何损失显示了对中心点的强烈但模糊的注意力,而对中心点的线注意是断开的长线段。这可能是个问题,因为整个直线信息对于计算中心点至关重要。在里面相比之下,图6d中的w/SoL增强显示了更精确的中心点注意力以及清晰的连接线注意这表明,增加线段根据数量和长度,该模型在基于像素和基于线匹配的质量方面更加稳健。
4.3、与其他方法的比较
如表2所示,我们进行了结合提出的训练方案(SoL增强、匹配和几何损失)与现有方法相结合。最后,我们将我们提出的M-LSD和M-LSD-tiny与以前最先进的方法对比。M-LSD训练方案的现有方法。像我们提出的训练方案可用于现有的LSD方法,我们使用L-CNN和HAWP继Deep Hough Transform(HT)(Lin、Pintea和van Gemert 2020)之后,最近提出了一种可组合的方法L-CNN+HT(HT-L-CNN)展示了一场表演增加1.4%,而L-CNN+M-LSD-s显示增加sAP 10中的0.9%。HAWP+HT(HT-HAWP)显示0.1%的性能提升,而HAWP+M-LSD-s显示0.6%sAP 10中的性能提升,使该组合成为最先进的性能之一。因此,这表明训练方式是灵活和有效的功能强大,可与现有的LSD方法一起使用。
表2、

M-LSD和M-LSD-tiny。我们提出的模型实现了具有竞争力的性能和最快的推理速度,即使模型尺寸有限。与之前最快的型号相比,TP LSD Lite、M-LSD具有输入大小512的性能更高,增长32.5%推理速度仅为模型大小的6.3%。我们的最快的型号是M-LSD-tiny,输入大小为320,有轻微的性能低于TP LSD Lite,但达到推理速度提高了130.5%只有2.5%模型大小的。与之前最轻的车型相比输入大小为512的TP-LSD-HG、M-LSD在sAP 5、sAP 10和LAP的推理速度提高了136.0%,模型尺寸提高了20.3%。我们最轻的型号为M-LSDtiny,输入大小为320,显示出增长趋势推理速度为310.6%,模型为8.1%与TP-LSD-HG相比的尺寸。以前的方法可以部署为服务器类上的实时线段检测器GPU,但也不适用于资源受限的环境因为模型尺寸太大或者推理速度太快太慢了。虽然M-LSD并没有达到最先进的性能,但它表现出了竞争力和推理速度最快,模型尺寸最小,提供在资源受限环境(如移动设备)上的实时应用程序中使用的潜力。
4.4、可视化
图7显示了M-LSD和M-LSD-tiny的输出。交叉点和线段用青色着色分别是蓝色和橙色。与GT相比即使在复杂的低对比度情况下,模型也能够以高精度识别连接点和线段环境,如(a)和(c)。虽然MLSD的结果很微小,但可能会有一些小线段丢失和丢失接头连接不正确,用于识别环境结构的基本线段是准确的。我们模型的目标是检测结构线段(Huanget al.2018),同时避免纹理和光度线段。然而,我们观察到,有些是包括在我们的结果中,例如(b)中的地板纹理和(d)中的墙壁阴影。我们承认这是现有方法的一常见问题,并且考虑到纹理用于训练的光度学功能将是一个伟大的未来工作我们包括了更多的可视化,并比较了补充材料中的现有方法。

图7 在WireFrame数据集上对M-LSD-tiny和M-LSD进行定性评价
4.5、在移动设备上的部署
我们在移动设备上部署了M-LSD,并评估了内存使用和推理速度。我们使用iPhone 12 ProA14仿生芯片组和配备Snapdragon的Galaxy S20 Ultra865芯片组。如表3所示,M-LSD-tiny和M-LSD足够小,可以部署在内存需求在78MB到78MB之间的移动设备上508MB。M-LSD-tiny的推理速度足够快在移动设备上实现实时性,从最低17.9 FPS至最高56.8 FPS。M-LSD仍然可以是实时的,输入大小为320,但输入大小为512输入大小,FP16可能需要更快的FPS超过10。总的来说,由于我们所有型号的内存需求都很小以及在移动设备上的快速推理速度效率允许在现实世界中使用M-LSD变体应用。据我们所知,这是第一次以及有史以来最快的移动设备实时线段检测器。
表3 推理速度和内存使用的iPhone(A14仿生芯片组)和Android手机(骁龙865芯片组)。 FP表示浮点数。

5、结论
我们介绍了M-LSD,一种用于资源受限环境的轻型实时线段检测器。我们的该模型采用了高效的网络体系结构和预测线段的单模块流程。即使在资源受限下,我们提出了新颖的训练方案:臂增强、匹配和几何损失。因此我们提出的方法达到了有竞争力的性能和效率推理速度最快,模型尺寸最轻。此外,我们还证明了M-LSD可以部署在移动设备上实时的设备,这证明了用于实时移动应用程序。