shardingsphere 支持达梦数据库
1、项目中分表分库插件用的是 shardingsphere,现在需要从mysql 数据转移到达梦数据库。
2、但是shardingsphere并不支持达梦数据库,所以查看了源码。基于shardingsphere(4.1.1版本)源码优化了支持达梦数据库大部分sql查询能力,(复合查询需要自己拆解)。
1、第一步 首先找到
DataSourceMetaData 接口实现该接口 这里需要注意java 包路径
org.apache.shardingsphere.underlying.common.database.metadata.dialect
public final class DMDataSourceMetaData implements DataSourceMetaData {
private static final int DEFAULT_PORT = 5236;
private final String hostName;
private final int port;
private final String catalog;
private final String schema;
private final Pattern pattern = Pattern.compile("jdbc:dm://([\\w\\-\\.]+):?([0-9]*)/([\\w\\-]+)", Pattern.CASE_INSENSITIVE);
public DMDataSourceMetaData(final String url, final String username) {
Matcher matcher = pattern.matcher(url);
if (!matcher.find()) {
throw new UnrecognizedDatabaseURLException(url, pattern.pattern());
}
hostName = matcher.group(1);
port = Strings.isNullOrEmpty(matcher.group(2)) ? DEFAULT_PORT : Integer.valueOf(matcher.group(2));
catalog = matcher.group(3);
schema = username;
}
}
2、实现
BranchDatabaseType接口
包路径 org.apache.shardingsphere.underlying.common.database.type.dialect
* Database type of Oracle.
*/
public final class DMDatabaseType implements BranchDatabaseType {
@Override
public String getName() {
return "DM";
}
@Override
public Collection getJdbcUrlPrefixAlias() {
return Collections.emptyList();
}
@Override
public DMDataSourceMetaData getDataSourceMetaData(final String url, final String username) {
return new DMDataSourceMetaData(url, username);
}
//作为MySQL的子集,sql解析等操作使用MySQL的实现
@Override
public DatabaseType getTrunkDatabaseType() {
return DatabaseTypes.getActualDatabaseType("MySQL");
}
} 解析器 选择的MYSQL, (我测试了下 选择orcal时分页查询会返回多表查询的所有结果。)
当然也可以自己实现解析器
自定义解析器在这个包路径 自己新建一个达梦模块就好。
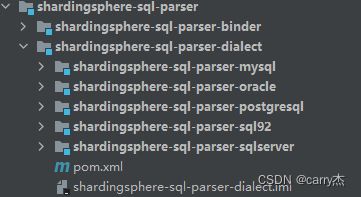
3、添加配置文件

在 这个目录把 上面的类型实现类加入 不然在加载类型的时候 不能加载(如下地方)
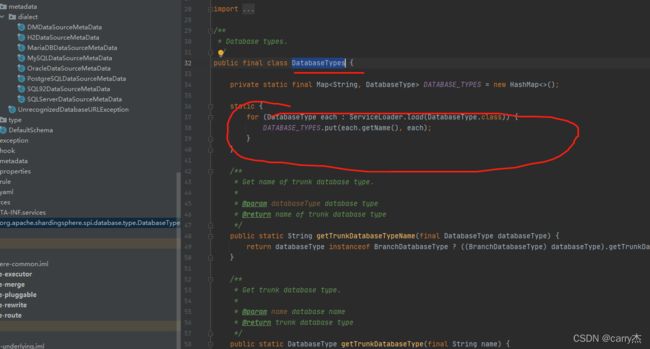
4、处理查询类型
SelectStatementContext 这里要处理 空格 这有空格匹配不了
private void setIndexForAggregationProjection(final Map columnLabelIndexMap) {
for (AggregationProjection each : projectionsContext.getAggregationProjections()) {
String index = each.getColumnLabel();
Integer key = columnLabelIndexMap.get(index);
if (key == null) {
index = index.replaceAll(" ", "");
}
Preconditions.checkState(columnLabelIndexMap.containsKey(index), "Can't find index: %s, please add alias for aggregate selections", each);
key = columnLabelIndexMap.get(index);
each.setIndex(key);
for (AggregationProjection derived : each.getDerivedAggregationProjections()) {
Preconditions.checkState(columnLabelIndexMap.containsKey(derived.getColumnLabel()), "Can't find index: %s", derived);
derived.setIndex(columnLabelIndexMap.get(derived.getColumnLabel()));
}
}
}
5、针对达梦数据库配置
找到
SchemaMetaDataLoader 类 修改load 你们的逻辑 过滤 SYS,SYSDBA模式里面的表,视图等。(这个逻辑根据实际需要自己过滤) 不然会包表或试图不存在 (当使用非SYSDBA账户链接的时候)。
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.shardingsphere.sql.parser.binder.metadata.schema;
import com.google.common.collect.Lists;
import lombok.AccessLevel;
import lombok.NoArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.apache.shardingsphere.sql.parser.binder.metadata.column.ColumnMetaDataLoader;
import org.apache.shardingsphere.sql.parser.binder.metadata.index.IndexMetaDataLoader;
import org.apache.shardingsphere.sql.parser.binder.metadata.table.TableMetaData;
import org.apache.shardingsphere.sql.parser.binder.metadata.util.JdbcUtil;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
/**
* Schema meta data loader.
*/
@NoArgsConstructor(access = AccessLevel.PRIVATE)
@Slf4j(topic = "ShardingSphere-metadata")
public final class SchemaMetaDataLoader {
private static final String TABLE_TYPE = "TABLE";
private static final String TABLE_NAME = "TABLE_NAME";
/**
* Load schema meta data.
*
* @param dataSource data source
* @param maxConnectionCount count of max connections permitted to use for this query
* @param databaseType database type
* @return schema meta data
* @throws SQLException SQL exception
*/
public static SchemaMetaData load(final DataSource dataSource, final int maxConnectionCount, final String databaseType) throws SQLException {
List tableNames;
try (Connection connection = dataSource.getConnection()) {
tableNames = loadAllTableNames(connection, databaseType);
}
List tableNamesA = new ArrayList<>();
for (String tableName : tableNames) {
// 过滤 达梦的系统表
if(tableName.startsWith("#")){
continue;
}else if("POLICIES".equals(tableName)){
continue;
}else if("POLICY_CONTEXTS".equals(tableName)){
continue;
}else if("POLICY_GROUPS".equals(tableName)){
continue;
}else if("AQ$_".startsWith(tableName)){
continue;
}else {
tableNamesA.add(tableName);
}
}
log.info("Loading {} tables' meta data.", tableNamesA.size());
if (0 == tableNamesA.size()) {
return new SchemaMetaData(Collections.emptyMap());
}
List> tableGroups = Lists.partition(tableNamesA, Math.max(tableNamesA.size() / maxConnectionCount, 1));
Map tableMetaDataMap = 1 == tableGroups.size()
? load(dataSource.getConnection(), tableGroups.get(0), databaseType) : asyncLoad(dataSource, maxConnectionCount, tableNamesA, tableGroups, databaseType);
return new SchemaMetaData(tableMetaDataMap);
}
private static Map load(final Connection connection, final Collection tables, final String databaseType) throws SQLException {
try (Connection con = connection) {
Map result = new LinkedHashMap<>();
for (String each : tables) {
result.put(each, new TableMetaData(ColumnMetaDataLoader.load(con, each, databaseType), IndexMetaDataLoader.load(con, each, databaseType)));
}
return result;
}
}
private static List loadAllTableNames(final Connection connection, final String databaseType) throws SQLException {
List result = new LinkedList<>();
try (ResultSet resultSet = connection.getMetaData().getTables(connection.getCatalog(), JdbcUtil.getSchema(connection, databaseType), null, new String[]{TABLE_TYPE})) {
while (resultSet.next()) {
String table = resultSet.getString(TABLE_NAME);
if (!isSystemTable(table)) {
result.add(table);
}
}
}
return result;
}
private static boolean isSystemTable(final String table) {
return table.contains("$") || table.contains("/");
}
private static Map asyncLoad(final DataSource dataSource, final int maxConnectionCount, final List tableNames,
final List> tableGroups, final String databaseType) throws SQLException {
Map result = new ConcurrentHashMap<>(tableNames.size(), 1);
ExecutorService executorService = Executors.newFixedThreadPool(Math.min(tableGroups.size(), maxConnectionCount));
Collection>> futures = new LinkedList<>();
for (List each : tableGroups) {
futures.add(executorService.submit(() -> load(dataSource.getConnection(), each, databaseType)));
}
for (Future> each : futures) {
try {
result.putAll(each.get());
} catch (final InterruptedException | ExecutionException ex) {
if (ex.getCause() instanceof SQLException) {
throw (SQLException) ex.getCause();
}
Thread.currentThread().interrupt();
}
}
return result;
}
}
6、 效果。

demo 下载 shardingsphere整合达梦数据库实现分表分库(包含testdemo)-Java文档类资源-CSDN下载
6、 特别注意 :经测试 不要使用
MybatisPlusConfig 分页插件
需要自己在mapper.xml里面实现分页逻辑