Numpy使用
文章目录
- 一. numpy简介
-
- 1.1 概念
- 1.2 作用
- 1.3 内容
- 1.4 优势
- 1.5 应用
- 1.6 Scipy
- 1.7 ndarray简介
- 二. 数组的使用
-
- 2.1 numpy数据类型
- 2.2 创建Ndarray数组对象
- 2.3 Ndarray数组对象属性
- 三. 数组内元素的操作
-
- 3.1 切片和索引
- 3.2 高级索引
- 3.3 广播
- 3.4 迭代
- 四. 数组的操作
-
- 4.1 修改数组的形状
- 4.2 翻转数组
- 4.3 修改数组的维度
- 4.4 连接数组
- 4.5 分割数组
- 4.6 数组元素的添加和删除
- 五. 函数
-
- 5.1 字符串函数
- 5.2 数学函数
- 5.3 算术函数
- 5.4 统计函数
- 5.5 排序函数
- 5.6 搜索函数
- 六. 拷贝
-
- 6.1 赋值
- 6.2 视图
- 6.3 副本
- 七. IO函数
一. numpy简介
1.1 概念
Numpy是Python语言的一个扩展函数库,支持大量的维度数组和矩阵运算,此外也针对数组运算提供大量的数学函数库。
1.2 作用
Numpy是一个运行速度非常快的数学库,主要用于数组计算
1.3 内容
- 一个强大的N维数组对象ndarray
- 广播功能函数
- 整合C/C++/Fortan代码的工具
- 线性代数、傅立叶变换和随机数生成等功能
1.4 优势
- 对于同样的数值计算任务,使用numpy要比直接编写Python代码便捷的多
- numpy中的数组的存储效率和输入输出性能均远远优于python中等价的基本数据结构,且其能够提升性能是与数组中的元素成比例的
- numpy的大部分代码都是c语言写的,其底层算法在设计时就有着优异的性能,这使得numpy比纯python代码高效的多
1.5 应用
Numpy通常与Scipy和Matplotlib一起使用,这种组合广泛用于替代Matlab,是一个强大的科学计算环境,有助于我们通过python学习数据科学或者机器学习
1.6 Scipy
是一个开源的Python算法库和数学工具包,包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程常用的计算
1.7 ndarray简介
- Numpy最重要的一个特点是其N维数组数组对象ndarray,它是一系列同类型数据的集合,以0下标开始进行集合中元素的索引
- ndarray对是用于存放同类型元素的多维数组
- ndarray中的每个元素在内存中都有相同存储大小的区域
二. 数组的使用
2.1 numpy数据类型
2.2 创建Ndarray数组对象
- 说明:numpy默认ndarray的所有元素的类型是相同的,这一点与Python中的list不同,如果传进来的列表中包含不同的类型,则统一为同一类型,优先级:str>float>int
- 创建Ndarray数组对象(array)
bumpy.array(object,dtype=None,copy=true,order=none,subok=False,ndmin=0)
object:数组或嵌套的数列
dtype:数组元素的数据类型,可选
copy:对象是否需要复制,可选
oder:创建数组的样式,C为行方向,F为列方向,A为任意方向(默认)
subok:默认返回一个与基类类型一致的数组
ndmin:指定生成数组的最小维度
代码实现
import numpy as np
arr=np.array([1,2,3,4,5]) #创建一维数组
print(arr)
arr=np.array([1,2,3.5,4,5]) #数据类型优先级
print(arr)
arr=np.array([[1,2,3],[4,5,6]]) #创建多维数组
print(arr)
arr=np.array([1,2,3,4,5,6,7,8,9],ndmin=2) #一维数组转二维
print(arr)
arr=np.array([1,2,3,4,5],dtype='f')
print(arr)
student=np.dtype([('name','S20'),('age','i4'),('marks','f4')]) #结构化数据类型
arr=np.array([('jakiechai',12,99.99),('jakiechai2',13,99.99)],dtype=student)
print(arr)

3. 创建Ndarray数组对象(asarray)
numpy.asarray(a,dtype=None,order=None)
a:任意形式的输入参数,可以是列表,列表的元组,元组,元组的元组,元组的列表,多维数组
dtype:数据类型,可选
order:可选,有C和F两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序
代码实现
arr=np.asarray([1,2,3,4,5])#传递列表
print(arr)
arr=np.asarray((1,2,3,4,5)) #传递元组
print(arr)
arr=np.asarray([(1,2,3),(4,6)])#列表元组
print(arr)
arr=np.asarray([1,2,3,4,5],dtype="f")#传递列表
print(arr)

4. 创建Ndarray数组对象(empty)
numpy.empty(shape,dtype=float,order='C)
创建一个指定形状(shape),数据类型(dtype)且未初始化的数组
shape:数组的形状
dtype:数据类型,可选
order:有C和F两个选项,分别代表行优先和列优先,在计算机内存中的存储元素的顺序
代码实现
arr=np.empty([3,2],dtype=int)#3行两列数组(未初始化导致每次打印结果不同)
print(arr)

5. 创建Ndarray数组对象(zeros)
numpy.zeros(shape,dtype=float,order='c')
创建指定大小的数组,数组元素以0填充
shape:数组形状
dtype:数据类型,可选
order:C用于C的行数组,或则F用于FORTRAN的列数组
arr=np.zeros([3,4],dtype=int)
print(arr)

6. 创建Ndarray数组对象(ones)
numpy.ones(shape,dtype=None,order="C")
使用方法和zeros一样只不过ones用填充
7. 创建Ndarray数组对象(full)
numpy.full(shape,fill_value,dtype=None,order='C')
创建指定形状的数组,数组以fill_value来填充,使用方法和ones一样,只不过是自己指定填充
8. 创建Ndarray数组对象(eye)
numpy.eye(N,M=None,k=0,dtype=float,order='C)'
对角线为1其他的位置为0
N:行数量
M:列数量,默认等于行数量,可选
代码实现
arr=np.eye(10)
print(arr)

9. 创建Ndarray数组对象(arange)
numpy.arange(start,stop,step,dtype)
创建数组范围并返回ndarray对象,根据start与stop指定的范围以及step设定的步长,生成ndarray
start:起始值
stop:终止值
step:步长,默认为1
arr=np.arange(1,20,2)
arr

10. 创建Ndarray数组对象(frombuffer)
numpy.frombuffer(buffer,dtype=float,cout=-1,offset=0)
用于实现动态数组,接受buffer输入参数,以流的形式读入转换成ndarray对象(buffer是字符串的时候,Python3默认str是Unicode类型,所以要转成bytestring在原str上加上b
buffer:可以是任意对象。会以流的形式读入
dtype:返回数组的数据类型,可选
count:读取的数据数量,默认为-1,读取所有数据
offset:读取的起始位置,默认为0
x=b'i am jakiechai'
arr=np.frombuffer(x,dtype='S1')
arr

11. 创建Ndarray数组对象(fromiter)
numpy.fromiter(iterable,dtype,count=-1)
从迭代对象中建立ndarray对象,返回一维数组
iterable:可迭代对象
x=[1,2,3,4,5]
z=iter(x) #转换为迭代对象
arr=np.fromiter(z,dtype='f')
arr

12. 创建Ndarray数组对象(linspace)
numpu.linspace(start,stop,num=50,endpoint=True,retstep=False)
创建一个一维数组,数组是一个等差数列构成的
num:要生成的等步长的样本数量,默认为50
endpoint:该值为true时,数列中包含stop值,反之不包含,默认为true
retstep:如果为true时,生成的数组中会显示间距,反之不显示
arr=np.linspace(1,10,10,dtype='i4')
arr

13. 创建Ndarray数组对象(logspace)
numpy.logspace(start,stop,num=50,endpoint=True,base=10.0,dtype=None)
创建一个等比数列
base:对数log的底数,默认为10
arr=np.logspace(1,10,10,dtype='i4',base=2)
arr

14. 创建Ndarray数组对象(rand)
numpy.random.rand(d0,d1,d2....)
生成0-1之间的随机数数组
arr=np.random.rand() #生成0-1的随机数
print(arr)
arr=np.random.rand(3) #生成3个随机数的随机数组
print(arr)
arr=np.random.rand(3,2) #生成2维数组
print(arr)

15. 创建Ndarray数组对象(random)
numpy.random.random(size=None)
生成[0,1)之间的随机数
size:元素个数
arr=np.random.random(2)
arr

16. 创建Ndarray数组对象(ranint)
numpy.random.randint(low,high=None,size=None,dtype='l')
生成随机整数
low:包含的下限
high:不包含的上限
arr=np.random.randint(0,10,5)
arr

17. 创建Ndarray数组对象(randn)
numpy.random.randn(d0,d1,....,dn)
返回一个或一组样本,具有标准正态分布
arr=np.random.randn(100)
arr
18. 创建Ndarray数组对象(normal)
numpy.random.normal(loc=0.0,scale=1.0,size=None)
生成高斯分布的概率密度随机数
loc:浮点型,此概率分布的均值
scale:浮点型,此概率分布的标准差
arr=np.random.normal(loc=1,scale=2,size=5)
arr
![]()
2.3 Ndarray数组对象属性
| 属性 | 说明 |
|---|---|
| ndim | 矩阵的秩 |
| shape | 矩阵的形状 |
| size | 数组元素的总的个数 |
| dtype | ndarray对象中的元素类型 |
| itemsize | ndarray对象中的每个元素的大小,一字节为单位 |
| flags | ndarray对象的内存信息 |
| real | ndarray对象的实部 |
| imag | ndarray对象的虚部 |
| data | 包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性 |
arr=np.random.randn(4,5)
print("arr的秩:",arr.ndim)
print("arr的形状:",arr.shape)
print("arr的元素总个数:",arr.size)
print("arr的元素类型:",arr.dtype)
print("arr的元素大小:",arr.itemsize)
print("arr的内存信息:",arr.flags)

三. 数组内元素的操作
3.1 切片和索引
ndarrya对象的内容可以通过索引或切片来访问和修改,与python中list的切片操作一样,ndarray数组可以基于0-n的下标进行索引,切片对象可以通过内置的slice函数,并设置start,stop以及step参数进行,从原数组中切割出一个新的数组
arr=np.arange(10)
print(arr)
print(arr[1])#下标拿元素
s=slice(2,7,1)#使用slice切片
print(arr[s])
arr2=arr[2:7:1]#使用冒号代替slice函数,效果时一样的
print(arr2)

冒号:解释:如果只放置一个参数,如[2],将返回该索引相对应的单个元素,如果为[2:],表示从该索引开始以后所有项都被提取,如果使用两个参数,如[2:7],那么则提取两个索引(不包括停止索引)之间的项
arr=np.arange(15)
arr.shape=(3,5) #3维数组
print("拿到第二个元素(是一个列表):",arr[2])
print("拿到第二个元素里面的第一个元素):",arr[2,0])
print("拿到第1个以及所有元素):",arr[1:,:])
print("拿到第1个以及所有元素,里面的1-3个元素):",arr[1:,0:3])

切片还可以包括省略号…,来使选择元组的长度和数组的维度相同,如果在行位置使用省略号,它将返回包含行中元素的ndarray
arr=np.arange(15)
arr.shape=(3,5) #3维数组
print(arr)
print("拿出所有行的第2列的数据",arr[...,1])

3.2 高级索引
Numpy比一般的Python序列提供更多的索引方式,除了之前看到的用整数和切片的索引外,数组还使用整数数组索引和布尔索引
- 整数数组索引
arr=np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]])
print(arr)
#获取(0,0),(1,1)和(2,0)位置的数据
print("整数索引使用1:",arr[[0,1,2],[0,1,0]])
#获取行索引是[0,0]和[3,4],而列索引是[0,2]和[0,2]
rows=np.array([[0,0],[3,3]])
cols=np.array([[0,2],[0,2]])
print("整数索引使用2:",arr[rows,cols])
######
print("整数索引使用3:",arr[...,1:3])

- 布尔索引
布尔索引通过布尔运算(如:比较运算符)来获取指定条件的元素的数组
arr=np.array([[1,2,3],[4,5,6],[7,8,9],[10,11,12]])
print(arr)
##获取值大于5的元素
print(arr[arr>5])
##使用取补运算符过滤空值
arr=np.array([np.nan,1,2,np.nan])
print(arr[~np.isnan(arr)])

3.3 广播
是numpy对不同形状(shape)的数组进行数值计算的方式,对数组的算术运算通常在相应的元素上进行
- 形状相同
如果两个数组a和b的形状相同,那么a+b的结果就是a与b数组的相对应元素相加即可。这要求维数相同,且各维度的长度相同
- 形状不同
如果两个数组的维数不同,则元素到元素的操作是不可能的,然而,在Numpy中仍然可以对形状不相似的数组进行操作,因为它拥有广播功能。较小的数组会广播到较大数组的大小,以便使它们的形状可兼容
a=np.array([[0,0,0],[1,1,1],[2,2,2],[3,3,3]])
b=np.array([1,2,3])
a+b

- 广播的规则
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加1补齐
- 输出数组的形状是输入数组形状的各个维度上的最大值
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或则其长度为1时,这个数组能够用来计算,否则出错
- 当输入数组的某个维度的长度为1时,沿着此维度运算时都用此维度的第一组值
3.4 迭代
numpy.nditer是一个有效的多维迭代器对象,可以用在数组傻姑娘进行迭代。数组的每个元素可使用Python的标准Iterator接口来访问
a=np.arange(12)
a=a.reshape(3,4)
for x in np.nditer(a):
print (x,end=",")
print("\n")
for x in np.nditer(a.T):
print (x,end=",")

它不是使用的标准的C或Forlan顺序,选择的顺序是和数组内存布局一致的,这样做是为了提升访问的效率,默认是行序优先。比如a和a.T(a的转置)的变量顺序是一样的,因为它们在内存中的存储的顺序是一样的。
控制迭代顺序的方法
| 顺序 | 说明 | 使用方式 |
|---|---|---|
| Fortan order | 列序优先 | for x in np.nditer(a,order=‘F’) |
| C order | 行序优先 | for x in np.nditer(a,order=‘C’) |
a=np.arange(12)
a=a.reshape(3,4)
for x in np.nditer(a,order='F'):
print (x,end=",")
print("\n")
for x in np.nditer(a.T,order='C'):
print (x,end=",")
for x in np.nditer(a,order='F',op_flags=['readwrite']):
x[...]=x*2
print()
print(a)

外部循环
nditer类的构造器拥有flags参数,它可以接受下列值
| 值 | 说明 |
|---|---|
| c_inde | 可以跟踪c顺序的所有 |
| f_index | 可以跟踪Fortran顺序的索引 |
| multi-index | 每次迭代可以跟踪一种索引 |
| external_loop | 给出的值是具有多个值的一维数组,而不是零维数组 |
a=np.arange(12)
a=a.reshape(3,4)
print(a)
print("\n")
for x in np.nditer(a,flags=['external_loop'],order="f"):
print(x,end=",")
print(" ")

广播迭代
如果两个数组是可以广播的,nditer组合对象能够同时迭代它们,假设数组a具有维度3X4,并且存在维度1X4的另一个数组b,则使用一下类型的迭代器(数组b被广播到a的大小)
a=np.arange(12).reshape(3,4)
print(a)
b=np.arange(1,5)
print(b)
for x,y in np.nditer([a,b]):
print("%d:%d"%(x,y),end=",")
print()

四. 数组的操作
4.1 修改数组的形状
reshape(shape,order="C")
| 参数 | 说明 |
|---|---|
| shape | 形状 |
| order | C(按行) F(按列) A(原顺序) K(元素在内存中的出现顺序) |
flat
一个数组元素的迭代器
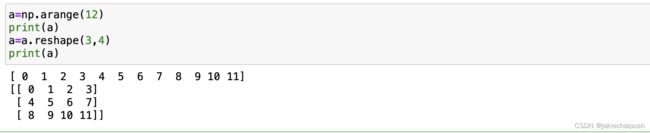
a=np.arange(12).reshape(3,4)
for x in a.flat:
print(x,end=',')

flatten(order=c)
展平数组元素并拷贝一份,顺序通常是C风格(修改返回的数组不会对原数组产生影响)
a=np.arange(12).reshape(3,4)
print("1",a)
b=a.flatten()
print("2",b)
b=a.flatten(order="f")
print("3",b)
print("4",a)

numpy.ravel(order="c")
展平数组元素,顺序通常是C风格,返回的是数组的视图(修改会影响原来的数组,F风格不会变)
a=np.arange(12).reshape(3,4)
print("原始a:",a)
b=a.ravel(order="F")
print("原始b:",b)
b=a.ravel()
print("原始b:",b)
b[1]=20
print("修改后的a:",a)

4.2 翻转数组
numpy.transpose(a,axes=None)
可以对数组进行转置(修改会影响原来的数组)
| 参数 | 说明 |
|---|---|
| a | 要操作的数组 |
| axes | 整数列表,对应维度,通常所有维度都会对换 |
a=np.arange(12).reshape(3,4)
print(a)
b=a.transpose() ##或者np.transpode(a)
b[1]=10
print(b)
print("b修改后对a的影响:",a)

ndarray.T
类似于numpy.transpose
a=np.arange(12).reshape(3,4)
print(a)
b=a.T
b[1]=10
print(b)
print("b修改后对a的影响:",a)

numpy.rollaxis(a,axis,start=0)
向后滚动特定的轴到一个特定的位置
| 参数 | 说明 |
|---|---|
| a | 要操作的数组 |
| axis | 要向后滚动的轴,其他轴的相对位置不会发生变化 |
| start | 默认为零,表示完整的滚动,会滚动到特定的轴 |
a=np.arange(12).reshape(3,4)
print("a为:")
print(a)
print("a的形状为:",a.shape)
print("\n")
b=np.rollaxis(a,1)##将1轴滚动到0轴,即4滚动到3的位置上,3就向后面滚动滚到4的位置上了
print(b)
print("b的形状为",b.shape)

numpy.swapaxes(a,axis1,axis2)
用于交换数组的两个轴
| 参数 | 说明 |
|---|---|
| a | 要操作的数组 |
| axis1 | 对应第一个轴的整数 |
| axis2 | 对应第二周的额整数 |
a=np.arange(12).reshape(3,4)
print("a为:")
print(a)
print("a的形状为:",a.shape)
print("\n")
b=np.swapaxes(a,0,1)##0轴和1轴进行交换
print(b)
print("b的形状为",b.shape)

4.3 修改数组的维度
注意这和修改数组的形状不同,修改维度不是很常用
broadcast()
用于模仿广播的对象,它返回一个对象,该对象封装了将一个数组广播到另一个数组的结果
x=np.array([[1],[2],[3]])
y=np.array([4,5,6])
b=np.broadcast(x,y)
r,c=b.iters #b定义为迭代器
print(b.shape) #发现y广播成了x的形状

numpy.broadcast_to(array,shape,subok=False)
将数组广播到新形状。它在原始数组上返回只读的视图,它通常不连续,如果新形状不符合Numpy的广播规则,该函数可能抛出ValueError
| 参数 | 说明 |
|---|---|
| array | 待修改的数组 |
| shape | 修改后的形状 |
a=np.arange(1,5).reshape((1,4))
print(a)
b=np.broadcast_to(a,(4,4))
print(b)

numpy.expand_dims(arr,axis=None)
通过在指定的位置插入新的轴来扩展数组的形状
| 参数 | 说明 |
|---|---|
| arr | 输入数组 |
| axis | 新轴插入位置 |
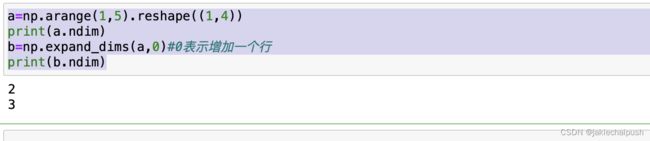
a=np.arange(1,5).reshape((1,4))
print(a.ndim)
b=np.expand_dims(a,0)#0表示增加一个轴
print(b.ndim)
numpy.squeeze(arr,axis)
从给定数组的形状中删除一维的条目
| 参数 | 说明 |
|---|---|
| arr | 输入数组 |
| axis | 删除轴的位置 |
a=np.arange(1,5).reshape((1,4))
print(a.ndim)
c=np.squeeze(a)
print(c.ndim)

4.4 连接数组
numpy.concatenate((a1,a2,...),axis)
用于沿指定轴连接相同形状的两个或多个数组(维度不会上升)
| 参数 | 说明 |
|---|---|
| a1,a2,… | 相同类型的数组 |
| axis | 沿着它连接数组的轴,默认为0 |
print(a)
print("")
b=np.arange(4).reshape(2,2)
print(b)
print("")
print(np.concatenate((a,b)))
print("")
print(np.concatenate((a,b),axis=1))

numpy.stack(arrays,axis)
用于创建一个新轴,并在该新轴上连接数组序列(维度会上升)
| 参数 | 说明 |
|---|---|
| arrays | 相同形状的数组序列 |
| axis | 数组中的轴,输入数组沿着它来堆叠 |
a=np.arange(4).reshape(2,2)
print(a)
print("")
b=np.arange(4).reshape(2,2)
print(b)
print("")
print(np.stack((a,b),0))
print("")
print(np.stack((a,b),1))

numpy.hstack()
是numpy.stack的一个变体,它通过水平堆叠的方式来生成数组(与此相对是vstack是沿着垂直方向堆叠的)
a=np.arange(4).reshape(2,2)
print(a)
print("")
b=np.arange(4).reshape(2,2)
print(b)
print("")
print(np.hstack((a,b)))

4.5 分割数组
numpy.split(ary,indices_or_sections,axis=0)
函数沿着特定的轴将数组分割为子数组
| 参数 | 说明 |
|---|---|
| ary | 被分割的数组 |
| indices_or_sections | 是一个整数,就用该数平均分割,如果是一个数组,为沿着轴切分的位置(左开右闭) |
| axis | 沿着哪个维度进行切分,默认为0,横向切分,为1时纵向切分 |
a=np.arange(12)
print(a)
x=np.split(a,3)#将a分为4份
print(x)
y=np.split(a,[2,7])#在位置2和7的位置切两刀
print(y)
b=np.arange(12).reshape(3,4)
print(b)
x=np.split(b,3)
print(x)
y=np.split(b,[2,7])#在位置2和7的位置切两刀
print(y)
z=np.split(b,2,axis=1)#在位置2和7的位置切两刀
print(z)

hsplit()和vsplit()
前者用于水平切割数组,后者用于垂直切割数组
b=np.arange(12).reshape(3,4)
print(b)
x=np.hsplit(b,2)
y=np.vsplit(b,3)
print(x)
print()
print(y)

4.6 数组元素的添加和删除
numpy.resize(arr,shape)
返回指定大小的新数组
| 参数 | 说明 |
|---|---|
| arr | 要修改大小的数组 |
| shape | 返回的数组的形状 |
b=np.arange(12).reshape(3,4)
print(b)
print()
y=np.resize(x,(2,2))
print(y)

numpy.append(arr,values,axis=None)
会在数组的末尾添加值,追加操作到整个数组,并把原来的数组复制到新的数组中,输入数组的维度必须匹配,否则将生成ValueError
| 参数 | 说明 |
|---|---|
| arr | 输入数组 |
| values | 要向arr添加,需要和arr形状相同(除了要添加的轴) |
| axis | 默认为None,当axis无定义时,是横向加成,返回总是为一维数组!当axis有定义时,分别为0和1的时候。为0的时候(列数要相同)。当axis为1的时候,数组是加在右边(行数要相同) |
b=np.arange(12).reshape(3,4)
print(b)
print()
a=np.append(b,[7,8,9])
print(a) ##返回1维数组
print(a.shape)
a=np.append(b,[[7,8,9,10]],axis=0)
print(a) ##返回1维数组
print(a.shape)
a=np.append(b,[[7],[8],[9]],axis=1)
print(a) ##返回1维数组
print(a.shape)

numpy.insert(arr,obj,values,axis)
在给定索引之前,沿着给定轴在输入数组中插入值(如果值的类型转换为要插入的值的类型,则它与输入数不同。插入没有原地的,函数会返回一个新的数组。此外如果未提供轴,则输入数组会被展开)
| 参数 | 说明 |
|---|---|
| arr | 输入数组 |
| obj | 在其之前插入值的索引 |
| values | 要插入的值 |
| axis | 沿着它插入值,如果未提供,则输入数组会被展开 |
b=np.arange(12).reshape(3,4)
print(b)
print()
a=np.insert(b,3,[11,12])
print(a) #未指定axis,会被展开
print()
a=np.insert(b,3,[11],axis=0) #行插入,输入数组只有一个元素,但需要四个元素,所以会自动进行广播为4个11
print(a)
print()
a=np.insert(b,3,[11],axis=1) #列插入,输入数组只有一个元素,但需要四个元素,所以会自动进行广播为4个11(且插入位置为3)
print(a)
print()

numpy.delete(arr,obj,axis)
返回从输入数组中删除指定子数组的新数组。与insert一样,如果未提供axis值,会被展开
| 参数 | 说明 |
|---|---|
| arr | 输入数组 |
| obj | 可以被切片,整数或者整数数组,表明要输入数组删除的子数组 |
| axis | 沿着它删除给定子数组的轴,如果未提供,则输入数组会被展开 |
b=np.arange(12).reshape(3,4)
print(b)
print()
a=np.delete(b,4) #下标为4的元素会被删除(即4会被删除)
print(a)
print()
a=np.delete(b,2,axis=0) #第2行会被删除
print(a)
print()
a=np.delete(b,2,axis=1) #第2列会被删除
print(a)
print()

numpy.unique(arr,return_index,return_inverse,return_counts)
去除数组的重复元素
| 参数 | 说明 |
|---|---|
| arr | 输入数组,如果不是一维数组则会展开 |
| return_index | 如果为true,返回新列表元素会在旧列表中的位置,并以列行存存储 |
| return_inverse | 如果为true,返回旧列表元素会在新列表的位置,并以列表形式存储 |
| return_counts | 如果为true,返回去重数组中的元素在原数组中的出现次数 |
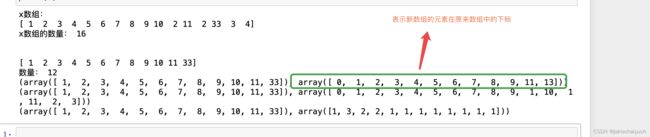
x=np.array([1,2,3,4,5,6,7,8,9,10,2,11,2,33,3,4])
print("x数组:")
print(x)
print("x数组的数量:",x.size)
print('\n')
a=np.unique(x)#去重
print(a)
print("数量:",a.size)
a=np.unique(x,return_index=True)#去重
print(a)
a=np.unique(x,return_inverse=True)#去重
print(a)
a=np.unique(x,return_counts=True)#去重
print(a)
五. 函数
5.1 字符串函数
是用于对dtype为numpy_string_或numpy.unicode_的数组执行向量化字符串操作,基于python内置库中的标准字符串函数在字符数组类(numpy.char)定义
| 函数名 | 说明 |
|---|---|
add() |
对两个数组的元素进行字符串拼接 |
multiply() |
返回按元素多重连接后的字符串 |
center() |
将字符串居中,并使用指字符在左侧和右侧进行填充 |
capitalize() |
将字符串第一个字母转换为大写 |
title() |
将字符串的每一个单词的第一个字母转换为大写 |
lower() |
数组元素转换为小写 |
upper() |
数组元素转换为大写 |
split() |
指定分隔符对字符串进行分割,并返回数组列表 |
splitlines() |
返回元素中的行列表,以换行符分割 |
strip() |
移除元素开头或者结尾处的特定字符 |
join() |
通过指定分隔符来连接数组中的元素 |
replace() |
使用新字符替换字符串中的所有子字符串 |
encode() |
编码,数组元素会依次调用str.encode方法 |
decode() |
解码,数组元素会依次调用str.decode方法 |
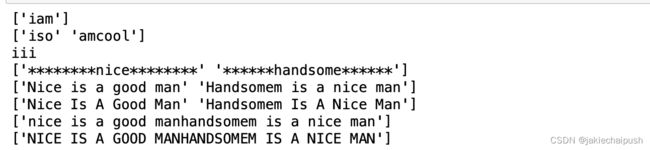
print(np.char.add(['i'],['am']))
print(np.char.add(['i','am'],['so','cool']))
print(np.char.multiply('i',3))
print(np.char.center(["nice","handsome"],20,fillchar="*"))
print(np.char.capitalize(["nice is a good man","handsomem is a nice man"]))
print(np.char.title(["nice is a good man","handsomem is a nice man"]))
print(np.char.lower(['Nice Is A Good Man' 'Handsomem Is A Nice Man']))
print(np.char.upper(['Nice Is A Good Man' 'Handsomem Is A Nice Man']))
5.2 数学函数
- 标准三角函数:
sin()cos()tan()
a=np.array([0,1,2,3,4])
print(np.sin(a*np.pi/180))
print(np.cos(a*np.pi/180))
print(np.tan(a*np.pi/180))

2. 反三角函数:arcsin() arccos() arctan()(使用方法和上面一样)
3. numpy.around(a,decimals=0
返回指定数字的四舍五入值
| 参数 | 说明 |
|---|---|
| a | 数组 |
| decimals | 舍入的小数位数,默认值为0.如果为负数,整数将四色五入到小数点左侧的位置 |
x=np.array([1.0,3.456,1234,0.12345,245.34])
print(np.around(x))
print(np.around(x,decimals=1))
print(np.around(x,decimals=-1))

4. floor()
向下取整数
5. ceil()
向上取整数
5.3 算术函数
add() subtract() mutiply() divide()
加减乘除函数,直接用运算符和效果是一样的
x=np.arange(9,dtype='f').reshape(3,3)
print(x)
print()
y=np.array([10,10,10])
print(y)
print()
print(np.add(x,y)) #类似广播
print()
print(np.subtract(x,y))
print()
print(np.divide(x,y))
print()
print(np.multiply(x,y))
print()

2. reciprocal()
返回参数逐个元素的倒数
y=np.array([10,10,10],dtype="f")
print(y)
print()
print(np.reciprocal(y))

3. powder()
将第一个输入数组中的元素作为底数,计算它与第二个数组中相应元素的幂数
y=np.array([10,10,10])
x=np.array([2,3,4])
print(np.power(y,x))
![]()
4. mod() remainder()
计算输入数组中相应元素的相除后的余数(取模)
y=np.array([10,10,10],dtype="f")
x=np.array([2,3,4],dtype='f')
print(np.mod(y,x))
print(np.remainder(y,x))

5.4 统计函数
amax() amin()
计算数组中的元素沿着指定轴的最大值和最小值ptp()
x=np.array([2,3,4],dtype='f')
print(np.amax(x))
print(np.min(x))
print(np.ptp(x))

计算数组中元素的最大值和最小值之差
4. numpy.percentile(a,q,axis)
百分位数统计中使用的度量,表示小于这个值的观察值的百分比
| 参数 | 说明 |
|---|---|
| a | 输入数组 |
| q | 要计算的百分位数,在0-100之间 |
| axis | 沿着它计算百分位数的轴 |
第q个百分位数是这样的一个值,它使得至少有q%的数据项小于或等于这个值,且至少有(100-q)%的数据项大于或等于这个值
x=np.array([[10,7,4],[3,2,1]])
print(x)
print()
print(np.percentile(x,50)) #表示50%是3.5
print(np.percentile(x,50,axis=0))
print(np.percentile(x,50,axis=1))

5. median()
算数组元素的中位数
6. mean()
算数组元素的平均值
x=np.array([[10,7,4],[3,2,1]])
print(x)
print()
print(np.median(x))
print(np.median(x,axis=0))
print(np.median(x,axis=1))
print(np.mean(x))
print(np.mean(x,axis=0))
print(np.mean(x,axis=1))

7. average()
根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值,可以接受一个轴参数,如果没有指定轴,则数组会被展开
加权平均值:将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的权重和
x=np.array([1,2,3])
y=np.array([4,6,7])
print(np.average(x))#平均值
print(np.average(x,weights=y))#平均值
####多维数组中
b=np.arange(12).reshape(3,4)
print(b)
print()
wts=np.array([3,5,6,7])
print(np.average(b,axis=1,weights=wts))

8. 标准差和方差
标准差(是一组数据平均值分散程度的一种度量,是方差的算法平方根):std=sqrt(mean((x-x.mean())**2))
方差(是每个样本与全体样本值的平均数之差的平方值的平均数):mean((x-x.mean())**2)
5.5 排序函数
| 种类 | 速度 | 最坏情况 | 工作空间 | 稳定性 |
|---|---|---|---|---|
| 快速排序 | 1 | O ( n 2 ) O(n^2) O(n2) | 0 | 否 |
| 归并排序 | 1 | O ( n l o g n ) O(nlogn) O(nlogn) | ~ n 2 \frac n 2 2n | 是 |
| 堆排序 | 3 | O ( n l o g n ) O(nlogn) O(nlogn) | 0 | 否 |
sort(a,axis,kind,order)
功能输入数组的排序副本
| 参数 | 说明 |
|---|---|
| a | 要排序的数组 |
| axis | 沿着它排序数组的轴,如果没有数组会被展开,沿着最后的轴排序,axis=0按列排序,axis=1按行排序kind排序算法,默认为快排 |
| order | 如果数组包含该字段,则是要排序的字段 |
x=np.random.randint(1,11,12).reshape(3,4)
print("x数组:")
print(x)
print("\n")
a=np.sort(x) #默认按行排序
print(a)
print()
a=np.sort(x,axis=0) #按列排序
print(a)
print()
####
dt=np.dtype([("name","S10"),("age",int)])
y=np.array([("zhanga",12),("jake",23),("liig",25)],dtype=dt)
c=np.sort(y,order="age")
print(c)

argsort()
对输入数组沿给定轴执行简接排序,并使用指定排序类型返回数据的索引数组,这个索引数组用于构造排序后的数组
x=np.array([3,1,2])
print("x数组:")
print(x)
print("\n")
a=np.argsort(x)
print(a) #打印的是排序后的数组元素在原数组中索引的位置

3. lexsort()
使用键序执行简介排序。键可以看作是电子表格的一列,该函数返回一个索引数组,使用它可以获得排序数据(通过键来排序)。
nm=('raju','anil','ravi','amar')
dv=('f.y.','s.y.','s.y.','f.y.')
a=np.lexsort((dv,nm))
print(a)
print([nm[i]+"-"+dv[i] for i in a])

4. msort(a)
数组按第一个轴(行)排序,返回排序后的数组样本
5. sort_complex(a)
对复数安装先实后虚的顺序进行排序
x=np.array([5,3,6,2,1])
y=np.array([1+2j,2-1j,3-2j,3-3j,3+2j]) #复数数组
print("x数组:")
print(x)
print("\n")
m=np.sort_complex(x)#这里排实部分
print(m)
m=np.sort_complex(y)#这里排实部分
print(m)

6. partition()
指定一个数对数组进行分区
x=np.array([3,4,2,1])
print("x数组:")
print(x)
print("\n")
print(np.partition(x,3))#以下标为3对数组为标准,比其小的排在其前面,比其大的排在其后面(达到一个分区效果),不是真正的排序
print(np.partition(x,(1,3))) #以下标为1和3对数组为标准,比下标1元素小的排在其前面,比下表3大的排在其后面,其它的排中间

7. argpartition(a,kth[axis,kind,order])
可以通过关键字kind指定算法沿着指定轴对数组进行分区(得到的是下标)
y=np.array([46,57,23,39,1,1,0,120])
print("y数组:")
print(y)
print("\n")
print(np.argpartition(y,2)) #找到数组第3小的值,比它小的放左边,比它大的放右边
print(y[np.argpartition(y,2)])

5.6 搜索函数
max() min()
沿着给定轴返回最大值和最小值
x=np.array([[30,40,70],[80,20,10],[50,90,60]])
print("x数组为:")
print(x)
print("\n")
print(x.flatten())#展开数组
print(np.max(x)) #全局最大值
print(np.max(x,axis=0))#行最大值
print(np.max(x,axis=1))#列最大值
print(np.min(x)) #全局最大值
print(np.min(x,axis=0))#行最大值
print(np.min(x,axis=1))#列最大值

2. argmax() argmin()
沿给定轴返回最大和最小元素的索引
x=np.array([[30,40,70],[80,20,10],[50,90,60]])
print("x数组为:")
print(x)
print("\n")
print(x.flatten())#展开数组
print(np.argmax(x)) #全局最大值索引
print(np.argmax(x,axis=0))#行最大值索引
print(np.argmax(x,axis=1))#列最大值索引
print(np.argmin(x)) #全局最大值索引
print(np.argmin(x,axis=0))#行最大值索引
print(np.argmin(x,axis=1))#列最大值索引

3. nonezero()
返回输入数组中非0元素的索引
x=np.array([[0,0,0],[80,0,0],[0,0,60]])
print("x数组为:")
print(x)
print("\n")
print(np.nonzero(x))

where()
返回输入数组中满足给定条件的元素的索引
x=np.array([[0,0,0],[80,0,0],[0,0,60]])
print("x数组为:")
print(x)
print("\n")
print(np.where(x>23))

5. extract()
根据某个条件从数组中抽取元素,返回满足条件的元素
x=np.array([[30,40,70],[80,20,10],[50,90,60]])
print("x数组为:")
print(x)
print("\n")
con=np.mod(x,2)==0 #条件,判断x数组中的元素是不是模2为0
print(np.extract(con,x))#第一参数为条件,第二个数组

六. 拷贝
6.1 赋值
简单的赋值不会创建数组对象的副本。相反,它使用原始数组的相同id()来访问它。id()返回python对象的通用标识符,类似于c中的指针。(类似于c中的深拷贝)
x=np.array([1,2,3,4,5,6])
print(x)
print()
print(id(x))#打印x地址
y=x
print(id(y))#打印y地址,发现地址一样,说明只是浅拷贝,y和x指向同一个内存空间

6.2 视图
又称为浅拷贝,是数据的一个别称或引用,通过该别称或引用也可以访问,操作数组原有数据,但原有数据不会产生拷贝。对视图进行修改,它会影响到原有数据,物理内存存在同一位置
x=np.arange(12)
print(x)
print()
y=x[3:] #切片操作创建的就是视图
print(y)
y[1]=2
print(y)
print(x) #修改视图,x和y都发生了改变

ndarry的view函数也可以产生视图
x=np.arange(12).reshape(3,4)
print(x)
y=x.view()
y[1][0]=100
print(y)
print() #修改y时,x也变了
print(x)

6.3 副本
又可以称为深拷贝,是一个数据的完整的拷贝(创建了新的内存,修改拷贝不会对原来数组造成影响)
x=np.arange(12).reshape(3,4)
print(x)
y=x.copy()
y[1][1]=100
print(x)
print(y)

七. IO函数
numpy可以读取磁盘上的文本数据或者二进制数据,numpy为ndarray对象引入了一个简单的文件格式npy,npy文件用于存储重建ndarray所需的数据、图形、dtype和其它信息
| 常用IO函数 | 作用 |
|---|---|
| load()和save() | 是读写文件数组数据的两个主要函数,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy文件中 |
| savez() | 用于将多个数组写入文件,默认情况下是以未压缩的原始二进制格式保存在扩展名为.npz文件中 |
| loadtxt()和savetxt() | 处理政策额文本文件(.txt等) |
numpy.save(file,arr,allow_pikle=True,fix_imports=True)
| 参数 | 说明 |
|---|---|
| file | 要保存的文件名 |
| arr | 要保存的数组 |
| allow_pikle | 运行python pickles保存对象数组,Python中的pickle用于在保存到磁盘文件或从磁盘文件读取之前,对对象数组进行序列化和反序列化 |
| fix_imports | 可选,为了方便python2中读取python3 保存的数据 |
x=np.arange(12).reshape(3,4)
np.save("./jakiechai",x)
y=np.load("./jakiechai.npy")
print(y)


numpy.savez(file,*args,**kwds)
将多个数组保存以npz为扩展名的文件中
| 参数 | 说明 |
|---|---|
| file | 要保存的文件名 |
| arr | 要保存的数组 |
| **kwds | 要保存的数组使用关键字名称 |
x=np.arange(12).reshape(3,4)
y=np.array([1,2,3,4,5,6])
np.savez("test",x,y,sin_arr=z)
ret=np.load("./test.npz")
print(ret["arr_0"])
print(ret["sin_arr"])


3. numpy.savetxt(Filename,a,fmt="%d",delimiter=",")和numpy.loadtxt(Filename,dtype=int,delimiter=",")
| 参数 | 说明 |
|---|---|
| delimiter | 指定各种分隔符 |
x=np.array([1,2.1,3])
np.savetxt("out.txt",x,fmt="%d",delimiter=",")#以整数保存,分隔符为,
y=np.loadtxt("out.txt",delimiter=",")
print(y)

![]()