回顾多元时间序列预测的发展与简单有效的 Baseline
从2017年开始,时空图神经网络模型被广泛应用于多元时间序列预测、交通预测等应用场景,然而到了2022年,这些方法的发展似乎出现了停滞:模型越来越复杂,性能提升非常有限(甚至倒退)。
最近,来自中国科学院,华中科技大学的几位研究者重新审视多变量时间序列预测这个问题,梳理其发展,特别是时空图神经网络模型的发展,在数据挖掘和信息检索学术峰会 CIKM 2022 上发表了一篇短文。研究者将样本在空间和时间维度上的不可区分性确定为关键瓶颈,并通过附加空间和时间实体信息为多维时间序列预测提出了一个简单而有效的 Baseline,该方法基于简单的多层感知器同样可以实现最佳性能和效率。

论文地址:https://arxiv.org/abs/2208.05233
论文源码:https://github.com/zezhishao/STID
多维时间序列预测
多维时间序列(Multivariate Time Series, MTS) 是各类应用系统中广泛存在的一类数据,例如交通、能源、金融等。MTS包含着多条时间序列。MTS最关键的、区别于其他数据的特点是,这些时间序列之间存在着明显的依赖关系。因此,一般认为 MTS 预测的关键是:对 MTS 的第 i 条时间序列进行预测的时候,不仅要考虑这第 i 条时间序列的历史信息,也要考虑其他时间序列的历史信息。
MTS 一类典型的,也是各大ML、DM社区一直以来研究很多的下游应用,就是交通预测(例如交通流、交通速度、交通需求等)。在这个场景中,每条时间序列来自一个传感器,记录着通过车辆的一些特征,例如交通流、交通速度等。由于车辆得沿着路网行驶,因此这些传感器之间肯定存在着很明显的依赖。一般来说,离的越近的传感器(注意这个离得近是指路网距离,而非经纬度算出来的欧式距离),他们的记录下来的时间序列一般会比较相似。
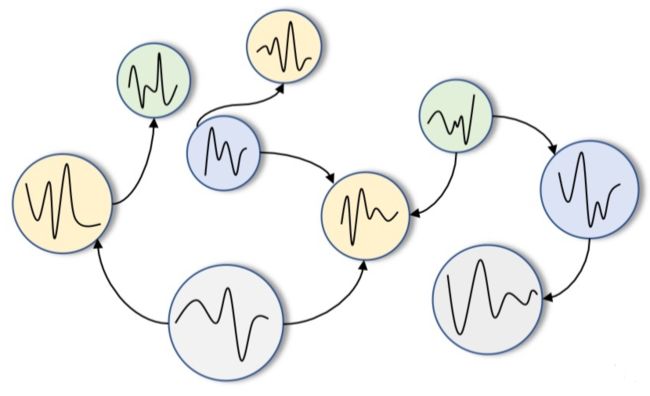
如上图所示,包含相互关联的多条时间序列。例如,在交通流系统中,每个时间序列来自一个传感器,记录着通过传感器的车辆总数。
两篇经典工作
刚刚提到在交通系统的图结构中隐含的假设是:靠得越近的传感器(即节点),记录下来的时间序列(即节点上的值)会比较相似。这种特自然和图卷积网络(Graph Convolution Network, GCN)的数据假设所吻合。
因此在GCN 于2017年被提出的那一刻就有研究者意识到:图卷积网络可以作为一个有效的工具来设计全新MTS预测模型。于是时空图神经网络(Spatial-Temporal Graph Neural Network,STGNN)在领域内就流行了起来。
在2018年的ICLR上,MTS预测领域最经典的Baseline之一 DCRNN 发表了出来,其实想法很简单:将交通系统的每个时刻,建模为车辆沿着路网的扩散过程(Diffusion Process)。具体的方法是将自己设计的GCN的变体,替换掉GRU内部的全连接层,从而使得GRU可以处理MTS数据。这种设计方法很有趣,它是把GRU打破了,将其内部的全连接进行替换,而非简单堆叠GCN和GRU。这种思路其实最早可能可以追溯到NeurIPS 2015上的一篇论文convLSTM:将CNN替换掉LSTM中的全连接层。
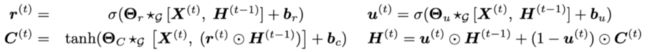
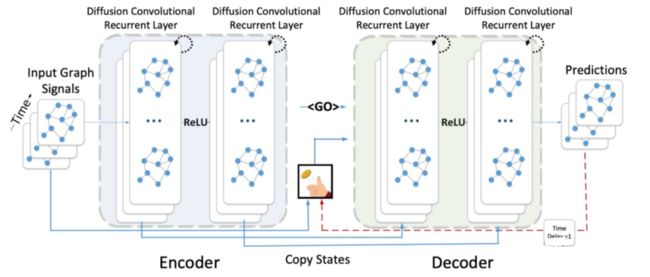
上图展示了一个DCGRU构建的Seq2Seq的模型,实现MTS预测。总之,2018年的DCRNN有机地结合了GCN和RNN,在性能上取得了很大的飞跃。即便是2022年的今天,它的性能依旧是前列的。
既然结合GCN和RNN挺有效,那结合GCN和CNN呢?注意,一维的CNN也是处理序列数据的一种非常有效的工具(在NLP和Time Series上都多有应用)。于是另一个经典的Baseline:Graph WaveNet,在2019年的 IJCAI 上发表了出来。它将GCN和TCN(一种处理时间序列的卷积网络)有机的结合到一起。而2019年的Graph WaveNet的性能,到2022年了基本上,基本上还能位列前三。

如上图所示,Graph WaveNet的架构。每一层CNN(即TCN)上搭配一个GCN使用。Skip Connect、Residual Connect、Gated TCN都是很重要的design。
DCRNN和Graph WaveNet作为两个里程碑式的时空图神经网络,是许多后续工作的基础。
近期的工作
在这两篇里程碑式的工作提出后,后续的工作主要分为两个方面:
第一,开发新的模型。把GCN和其他的序列模型、思想结合起来。
第二,学习图结构。GCN是需要依赖一个预定义图进行卷积操作的。然而,在许多任务中,这个预定义图通常是有偏、有错,甚至直接就是缺失的。例如,在股票市场上,我们很难构造出一个足够正确的、能表示不同股票之间关联关系的、符合“连接的节点更相似”这个homophily假设的图结构。
沿着上述这两个思路,从2019年开始,基于时空图神经网络的范式设计MTS预测模型这个领域,似乎就开启了军备竞赛,“卷”的不行了。
一方面,大家开始设计新的模型结构。例如借鉴GCN领域的最新成果(例如新的卷积方式)、结合Attention、结合Transformer、结合Meta-Learning、结合Multi-View Learning、使用层次化视角等等等等。
另一方面,大家开始学习图结构。一开始大家的动机是预定义图是不准的、缺失的,因此要自己学习一个潜在图——这是完全合理的,创新性等级比较高但真的要做好了很难;后来大家又把交通系统的动态特性加上去了——这也是合理的,但创新性等级开始趋向于incremental了,但相关工作的方法设计都挺有意思的。
总的来说,相关的模型真的是越来越复杂,完全没有了一开始的 DCRNN 和 Graph WaveNet的简洁。然而,变得更加复杂的相关工作,带来的提升其实非常有限(后续充分的实验会显示这一点)。甚至,许多工作在性能上其实也比不过DCRNN和Graph WaveNet。
另外,时空图神经网络领域的“卷”,并没有带来很大的进步,反而带来了许多有意无意的错误。例如,有一些工作在论文中宣称得到了大幅度提升,但实际上要么是Error的计算方式出现了错误、要么是没开源代码难复现。
到了2022年的今天,刚刚放出来的许多最新工作已经不再使用由 DCRNN 和 Graph WaveNet 以及 STGCN 等经典Baseline提出的那几个经典的数据集(METR-LA、PEMS-BAY、PEMS03、PEMS04、PEMS07、PEMS08等数据集)进行评测了——实在是刷不动分了。
MTS预测的独特之处
再这么卷下去,不是件好事:增量性的工作很难做出好东西。因此有必要重新审视一下MTS预测这个问题,重新思考一下它和普通的时间序列预测问题的不同之处到底在哪里,而不应该将自己的局限在时空图神经网络中。
因此该工作的研究者们从样本的构造方面进行审视和反思。时间序列的样本是从一条原始的时间序列上,用滑动窗口取的。
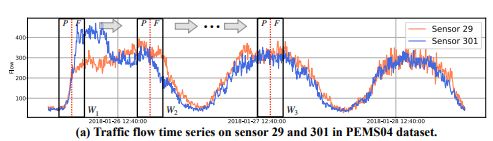
如上图所示,窗口(长度为P+F)分为两部分,前P长度内的数据代表着历史数据(Past),后F长度内的数据代表着未来数据(Future)。他们分别对应着机器学习的Sample和Ground Truth——模型输入前P部分数据,尝试去预测后F部分数据。(时间窗口每滑动一次,就会产生一个样本。然后再按照训练、验证、测试去划分就行了。)
例如,上面W1,W2 和 W3 是滑动到不同位置的窗口
考虑到不同的变量和不同的时期会有不同的模式,我们发现最终会生成许多具有相似历史数据、但不同未来数据的样本。
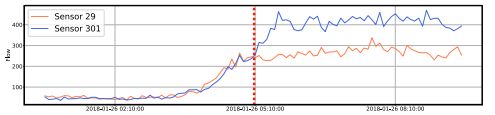
例如窗口W1下的红色和蓝色时间序列如上图所示。他们的输入数据(红线左侧)非常相似,但是未来数据(红线右侧)非常不同。假如使用普通的回归模型(例如多层感知机),那么我们不可能为这两个来自同一时间但不同空间的相似的样本,产生迥异的预测结果。
再比如W2和W3的蓝色时间序列样本如下图所示,他们的历史数据也很相似,但未来数据也是迥异的。那么普通的模型仍然不可能为这两个来自同一空间但不同时间的相似的样本,产生迥异的预测结果。
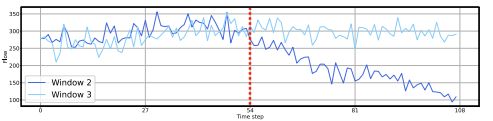
上面这两种情况,我们分别叫他们样本在空间上的不可区分性和时间上的不可区分性。这种不可区分性广泛的存在于时间序列预测的样本池(即数据集)中,使得普通的模型很难做出有效的预测。
上述的例子是我们重新审视MTS预测问题时,在直观上产生的一些观察。后续我们发现有一些类似的理论证明,可以参考SIGKDD 2021的论文ST-Norm。ST-Norm还在论文中还验证了GCN能够起作用就是因为它依靠图结构以及“相邻的节点更相似”基本假设缓解了空间上的不可区分性。
简单有效的办法
时间和空间的不可区分性,直观上说就是预测模型(例如多层感知机)不知道输入的两个几乎一模一样的样本数据,都是来自于哪条时间序列、来自于什么时候。那么解决这个问题最简单、最直观的思路是什么呢?
模型不知道的话,就直接告诉模型就好了——给输入的样本附加身份信息,从而使得模型可以区分这些样本。基于这么简单的思想,我们设计了一个附加时空信息(Spatial-Temporal IDentity,STID)的模型。那么该附加哪些身份信息呢?我们使用了三个身份信息:
首先是空间信息。假设有 N 条时间序列,我就随机初始化一个Embedding矩阵
![]()
,其中D是Embedding的维度。
其次是time in day时间信息。假设时间序列的是每天采样![]()
次得到的,那就随机初始化一个Embedding矩阵。
最后设计day in week的时间信息。每周有7天,所以随机初始化一个Embedding矩阵
![]()
,其中![]() 。
。
注意这三个Embedding矩阵是随机初始化并且完全由模型自己去训练的。

对于给定的第 i 条时间序列,在第 t 时刻产生的样本
![]()
分别去查询上面三个矩阵,得到三个长度为D 的向量:。样本也通过一层FC Embedding一下,把P维变成D维度。上述这四个D维度的向量拼接到一起,然后再通过多层感知器去做Encoding。最后,通过回归层(一层FC)进行预测。多层感知器使用的是带残差链接的全连接,使用了三层。
显然STID这个模型足够简单(甚至已经可以说是最简单了):全部都是全连接层,没有任何复杂操作。
实验验证
STID只做了一件事:试图去契合MTS预测的关键瓶颈,即样本在空间和时间上的不可区分性。那么这样简单的模型真的有效吗?研究者基于BasicTS在5个常用数据集上,和现有的11个Baseline,基于完全统一的Pipeline(只有送进去的模型结构不同,其他的步骤完全相同)做了详尽的对比。
数据集设置:Traffic Speed数据集PEMS-BAY,Traffic Flow数据集PEMS04、07、08,电力数据集Electricity(336个variate、1小时采样时间的那个版本)。
Baseline 设置:HI (2020 CIKM)、 VAR(传统方法)、DCRNN(2018 ICLR)、STGCN(2018 IJCAI)、Graph WaveNet(2019 IJCAI)、AGCRN(2020 NeurIPS)、StemGNN(2020 NIPS)、GMAN(2020 AAAI)、MTGNN(2020 SIGKDD)、ST-Norm(2021 SIGKDD)。
实验结果很惊讶,在这几个数据集上,基于MLP的STID的性能几乎超过所有的时空图神经网络方法:
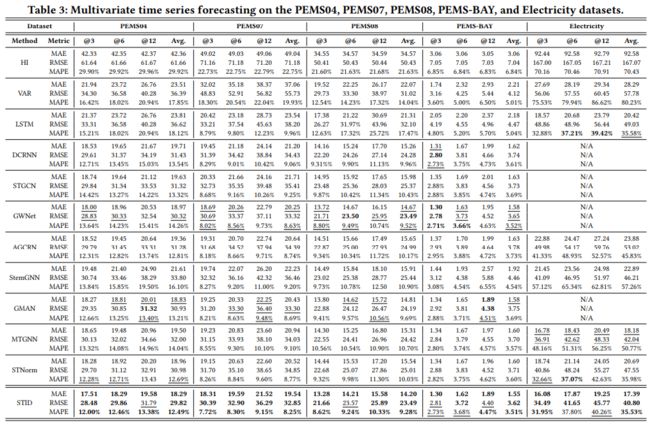
并且,STID完全不需要预定义或者训练图结构!
在效率上,由于STID的结构非常简单——只有MLP,因此它在所有的数据集上的速度都非常之快:
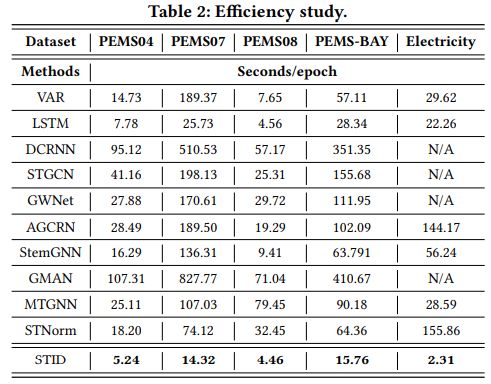
虽然STID的性能很好,但它真的是由于附加了时空信息吗?所以研究者在PEMS04数据集上分别去除那三个身份信息embedding,做了个消融实验:
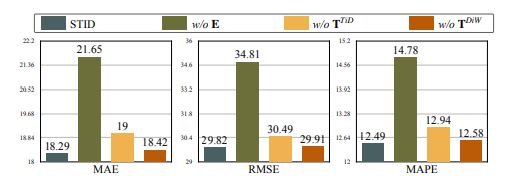
看来这些Embedding矩阵真的很重要,去掉他们之后的全连接层的性能确实是不如STGNN-based的方法。那这几个Embedding矩阵到底学到了啥,不妨把他们可视化一下看看:
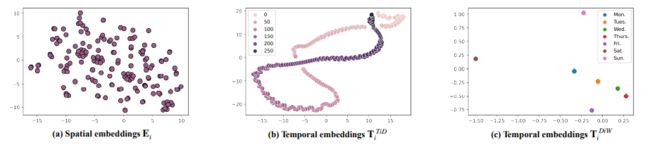
一方面,可以看到的是,空间Embedding出现了明显的聚类趋势,这和GCN起到了同样的效果。另一方面,PEMS04数据集是交通流数据集,具有明显的周期性。而在Time of Day Embedding上,明显地展示了周期性的变化:Embedding最终凑成了一个环,这意味着以“一天“为单位的周期性,而交叉点意味着每天内的相似性,例如早高峰和晚高峰的交通是相似的。
最后,Day of Week展示了一周内七天的Embedding可视化结果,可以看到周一到周五比较相似,周六和周日则离它们更远,且周六、周日它们俩也不太靠近。
总结
如果读者您有兴趣,还可以对更多的Baseline、在更多的数据集上做实验,详情可以参考BasicTS:
https://github.com/zezhishao/BasicTS/tree/master
STID的性能和效率很令人惊喜,这意味着我们并不需要必须基于时空图神经网络去做新的设计。研究者完全可以更加天马行空一点——只要模型的设计契合MTS预测的特点和关键瓶颈。
虽然STID的效果还不错,但它只是一个很小的尝试——基本上所有的动机、方法都是基于直觉。如何进一步,定量地量化样本的不可区分性,并站在这个角度上Formulate问题,再合理地对问题进行建模,最终再定性、定量地设计一个模型出来,可能才是最终理想。
内容来源
时序人公众号CIKM 2022 | 回顾多元时间序列预测的发展与简单有效的 Baseline (qq.com)
原出处为知乎,未找到源,欢迎作者补充提醒。
不作商用,侵权告删