IROS2022 | 4D车载雷达自监督场景流估计(上汽、爱丁堡大学)
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【IROS2022】获取IROS2022所有自动驾驶方向论文!
 作者单位:爱丁堡大学,上汽集团
作者单位:爱丁堡大学,上汽集团
论文:https://arxiv.org/abs/2203.01137
主页:https://toytiny.github.io/projects/raflow/raflow.html
代码:https://github.com/Toytiny/RaFlow
讲解:https://youtu.be/5_iJCZytrxo
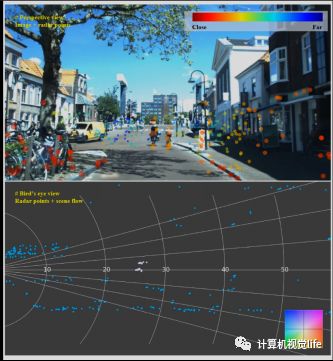
Demo 请欣赏:
一. 内容概述
场景流 (Scene Flow) 使自动驾驶汽车能够推理多个独立物体的任意运动,是实现长期移动自动化的关键。虽然目前在激光雷达 (LiDAR) 场景流估计上有了很多的进展,但如何估计4D雷达(radar)场景流依旧是未知的。作为一种新型的传感器,凭借其对抗恶劣天气以及光照条件的鲁棒性,4D radar 受到了越来越多的关注。但和 LiDAR 相比,radar 数据十分地稀疏,嘈杂,而且有着较低的分辨率。另外,标注真实场景下的场景流非常的昂贵和耗时,这些因素共同作用使得 radar 场景流估计极具挑战性。为了解决诸多的挑战,本工作提出了通过自监督学习在 4D radar 点云上估计场景流。针对棘手的 radar 点云数据,我们设计了一个专门的场景流估计模型,并提出了三个新的损失函数来实现端到端的训练。通过真实场景下的实验结果,我们验证所提出的方法能够鲁棒地在室外道路上估计 radar 场景流,而且可以有效地支持下游的运动分割 (Motion Segmentation) 任务。
二. 研究背景
推理道路上动态目标的运动,对于自动驾驶汽车的安全规划和导航是至关重要的。其中,一种重要运动表征就是场景流,一个能够描述3D场景连续两帧之间运动场的向量集合。作为光流在3D空间的延伸,场景流天生就和自动驾驶汽车上不同3D传感器 (例如 LiDAR)所生成的点云数据相适配。场景流能够超越目标层面的运动描述,在点的层面描述运动场,提供更高细粒度的场景运动表达。一旦场景流被精确估计了,它可以支持一系列的下游任务,例如动态目标分割,点云叠加,以及多目标跟踪。
通过监督或自监督学习,研究者们最近在场景流估计领域取得了不错的进展。但是这些方法主要针对于 LiDAR 点云,并不能够直接地迁移到 radar 数据上来。作为一种新型的传感器,4D毫米波 radar 与 LiDAR 相比有着一系列的优势,引起了汽车工业界的广泛关注。首先,目前先进的radar传感器提供了更丰富的场景信息观测。它不仅能够测量点的3D位置而且能够测量点的相对径向速度 (RRV)。额外的相对速度信息测量能够自然地帮助场景流估计任务。另外,由于发射毫米波,这些radar传感器能够应对各种恶劣天气情况,比如雾天,雨天,沙尘,以及任何不良的光照状况,例如黑暗,昏暗以及强烈光照等等。最后,radar 传感器与 LiDAR 相比有着更轻的重量(单片的尺寸)以及更低的价格,因此能够被用在成本或者载重有限的移动平台上,例如中低端的汽车或者快递运送机器人。
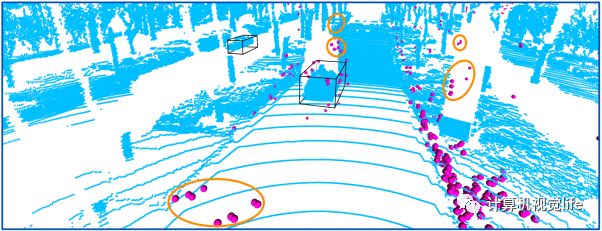
图1 LiDAR (蓝色) 和 radar (品红色) 点云的可视化对比图。黑色的框表示 LiDAR 目标检测的输出。如图所示,radar 点云和 LiDAR 点云相比特别地稀疏,只有很少一部分点重合。另外,radar 点云有很多噪声点,明显的噪声点团被橙色圈所标出。由于比较低的分辨率,很多原本应该在目标框的点落在了外面。
尽管4D毫米波 radar 拥有上述所说的各种优点,但在 radar 点云上估计场景流依然不是一个简单的任务。直到如今,还没有工作提出解决这一问题。相比于 LiDAR 输出的点云,radar 点云非常地稀疏,嘈杂以及有着较低的分辨率 (如图1)。具体来说,一帧 4D radar 点云一般只有二三百个点 (少于普通 LiDAR 点云的1%)。这样稀疏的特点阻碍了鲁棒的局部特征提取。另外,由于多路反射效应以及镜面反射,radar反射经常被噪声所干扰。结果,噪声点占据了不可忽略的部分 (在我们的工作中最多20%)。它们影响了场景流估计中的点与点的关联。与此同时,由于成本的原因,毫米波 radar 只有有限的接收和发送天线,限制了它的距离和角测量分辨率。比如,我们所使用的 radar 的角分辨率比 LiDAR 的差了一个量级。除了以上的挑战,在本篇工作提交时还没有公开的 4D radar 数据集,更不用说标注场景流本身就是一个昂贵的步骤。因此,许多基于监督学习的场景流方法难以使用在我们的工作上。。
三. 主要贡献
●本文是第一个研究 4D radar 场景流估计的工作。我们提出一个面向 4D radar 场景流估计的自监督学习框架, 不需要任何标注就可以进行模型训练。●我们提出的 RaFlow 方法能够应对稀疏,嘈杂,低分辨率的 radar 点云, 并可以有效的利用 radar 独特的 RRV 测量来大大提升预测的鲁棒性。●我们驾驶采集车在真实道路场景中收集了一个多模态数据集用于系统性的评估。实验结果证明了 RaFlow 要优于 SOTA 的自监督点云场景流方法。我们的代码开源在了https://github.com/Toytiny/RaFlow。
四. 方法介绍
1.概述
对于 4D radar 场景流估计任务,我们的输入是连续两帧 radar 点云,其中每个点的信息包括它在 radar 坐标系下的3D位置,相对径向速度 (RRV)测量以及 RCS 和 Power 测量, 如图2所示。模型输出的是第一帧点云中每个点的场景流向量,表示该点在两帧间的坐标移动。在真实世界的 radar 数据中,两帧点云之间不存在着绝对的双向映射,也就是说第一帧点云中点在第二帧中的相应位置不需要和第二帧点云中的任何点重合。
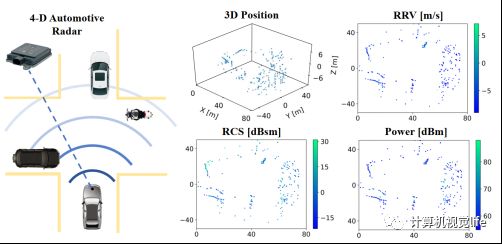
图2 radar 点云的6维测量可视化,包括3D的位置测量信息,RRV, RCS以及Power测量。
我们所提方法RaFlow的模型结构如图3所示。我们的模型包括两个模块,包括ROFE模块以及SFR模块。首先,两帧连续点云被输入到Radar-Oriented Flow Estimation (ROFE)模块来估计一个粗略的场景流。然后,基于该输出,Static Flow Refinement (SFR) 模块估计一个静态分割mask以及一个全局的刚性变换。最后我们用该变换来refine所分辨出的静态点的场景流输出。
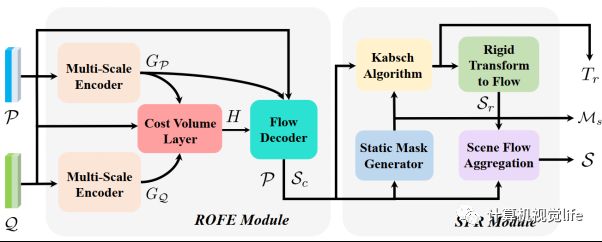
图3 RaFlow 场景流估计模型框架。
2.ROFE 模块
如图3所示,我们的ROFE模块包括三个组成部分,multi-scale encoder, cost volume layer 以及 flow decoder。Multi-scale encoder 用于在每一个输入的点云上提取局部-全局特征。首先,我们使用多个的 点云卷积 (set conv) 层来提取多尺度的局部特征。该方法可以有效应对 radar 点云的稀疏性以及不均匀的点的密度。然后,我们在通道方向使用最大池化 (max-pooling)操作来得到全局特征向量。最后我们把全局特征向量连接到每个点的局部特征上,并输出每个点云的局部-全局特征。
Cost Volume Layer 用于在关联两帧点云的特征。相比于点对点的关联, cost volume layer可以块对块地 (patch-to-patch)进行信息交叉传递,从而使得特征关联更加的鲁棒。此方法能够有效解决 rada r点云的低分辨率以及非双向的映射问题。
Flow Decoder 利用以上的局部-全局以及关联特征来估计场景流。它主要由多层感知机组成,最后输出一个粗略的三维场景流。
3.RRV 测量与场景流
作为 4D 雷达一个重要测量,RRV可由多普勒效应 (Doppler effect) 所得到。它描述目标在径向方向上相对传感器的速度。一般地,该测量主要被用于额外的输入特征来编码点的运动信息。在这里,我们建立了RRV测量与场景流之间的关系,如图4所示。RRV测量乘以时间长度可以近似看作是 ground truth 场景流在径向上的投影。利用RRV与场景流的关系,我们在SFR模块中提出了一个静态分割mask的算法,以及建立了一个相关的径向运动损失函数。
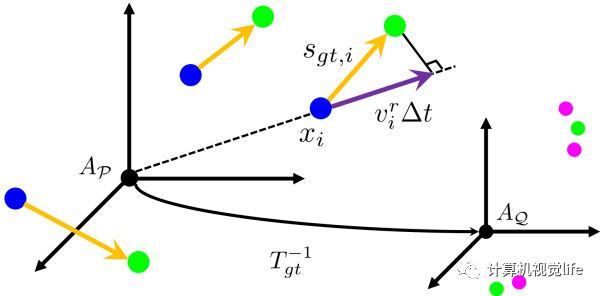
图4 radar 场景流和RRV测量的说明。蓝色和品红色点代表数量的两帧点云,绿色的点代表通过ground truth场景流warp到第二帧的点。黄色表示ground truth场景流,紫色代表RRV测量乘以时间长度。
4.SFR模块
考虑到 radar 点云的稀疏性和其中不可忽略的噪声, 从ROFE模块中输出的场景流是粗略的。在本模块中我们refine该粗略场景流来得到最终的输出。首先我们利用RRV和场景流的关系,提出了一个静态分割mask生成算法,如下所示。

然后我们利用输出的mask将静态点分割出来,并用场景流生成静态点的correpondences,最后将其输入到Kasch算法中输出一个描述ego-motion的刚性变换。考虑到静态点的场景流都是由自车的ego-motion所产生的,我们用该变换来refine所分辨出的静态点的场景流输出。
5.损失函数
我们设计了三个针对 4D radar 场景流自监督学习的损失函数来在约束模型的训练。
第一个损失函数是径向运动 (radial displacement) 损失函数。基于图4中RRV与场景流的关系,我们利用RRV测量来约束最后的场景流输出。
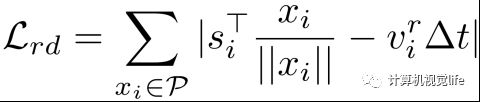
第二个损失函数是 Soft chamfer 损失函数。它通过利用两帧点云互相之间的最近邻点进行chamferpipei来约束场景流估计。相比传统的chamfer损失函数,我们的soft函数能够有效地减轻 radar 噪声点对于chanfer匹配的影响,并能够容忍由 radar 低分辨率带来的小的匹配误差。

第三个损失函数是空间连续性 (spatial smoothness) 损失函数。它利用每个点周围最近的N个点的输出来约束每个点的场景流估计。考虑到 radar 的稀疏性,我们还引入了一个与欧式距离相关的权重函数来减轻远处点的干扰。
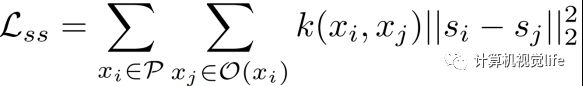
五. 实验结果
我们在自采集的多模态数据集对我们的RaFlow方法进行评估。作为自监督的方法,我们不需要任何数据标注就可以进行训练。首先,我们先与SOTA的自监督场景流方法进行比较,结果如下表所示。

相比于SOTA的方法,RaFlow在各个指标上取得了明显的提升。这验证了我们所提出的模型框架以及损失函数能够有效应对稀疏,嘈杂以及低分辨率的 radar 点云。为了更好的展示我们的场景流估计效果,我们在图5展示了定性的结果。除了场景流估计,RaFlow还能够输出一个副产物,即运动分割mask。在图6中我们展示在运动分割任务上的定性结果。
除了在自采集的数据上进行实验外,我们还在最近开源的View-of-Delft数据上测试了RaFlow,实验结果demo在推文开始处已展示。
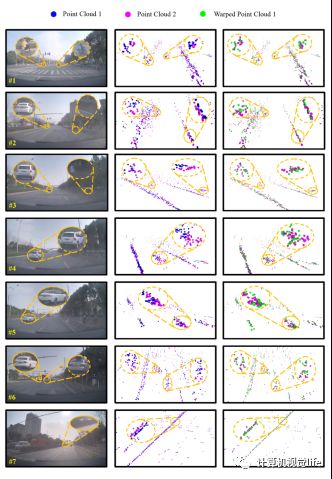
图5 场景流估计可视化。左列为对应的相机图像,中间列为输入的两帧点云,右列为输出结果。其中蓝色点表示输入的第一帧点云,品红色表示第二帧,绿色表示用估计的场景流warp后的第一帧点云。
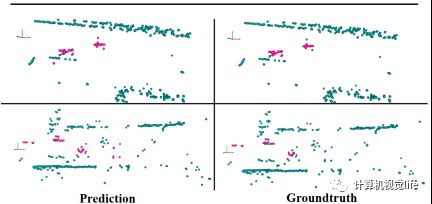
图6 运动分割结果可视化。左列是我们的输出,右列是ground truth。运动和静态点分别被染为粉色和青色。图中两个场景中自车均在运动。
往期回顾
毫米波雷达在多模态视觉任务上的近期工作及简析
【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;
加入我们:自动驾驶之心技术交流群汇总!
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
