【paddle】Vision Transformer(attention)
【参考:4.Attention实现_哔哩哔哩_bilibili】
讲得非常好
可以看看paddle的transformer.py的源码
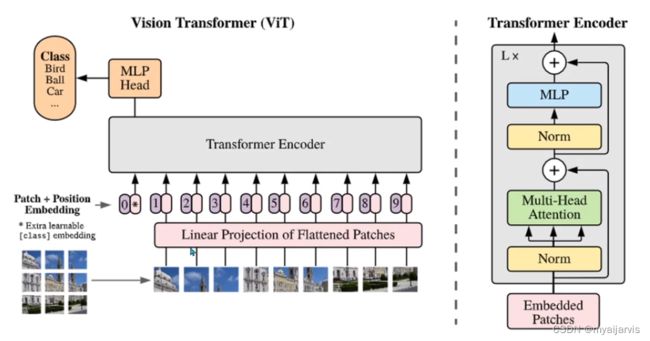

多头注意力
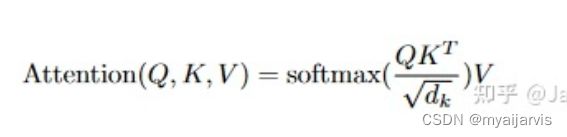

class Attetion(nn.layer):
"""
多头注意力
- 使用伸缩点积模型
Forward:
- 输入每条为[N,D]的数据,初始化QKV矩阵
- 再将QKV矩阵转化为多头,并把每条数据的一部分[N,head_dims]分配给每个头
- 伸缩点积模型计算,获得多头结果
- 将多头结果进行组合还原(通过线性层的方式),还原回原来的维度D
"""
def __init__(self,
embed_dims=768,
num_head=12,
attn_dropout_rate=0.,
dropout_rate=0.):
"""
B(batch_size),N(seq_len),D(embed_dims)
:param embed_dims: 输入数据的维度
:param num_head: 注意力头数
:param attn_dropout_rate: 注意力分布的丢弃率
:param dropout_rate: 注意力结果的丢弃率
"""
super(Attetion, self).__init__()
self.embed_dims = embed_dims
self.num_head = num_head
assert embed_dims % num_head == 0, \
"Warning Attetion embed_dims % num_head != 0"
self.head_dims = embed_dims // num_head
self.scale = self.head_dims ** -0.5 # 开根号再取倒数
# q,k,v初始化
# B(batch_size),N(seq_len),D(embed_dims) -> B,N,3*D
self.qkv_proj = nn.Linear(in_features=embed_dims,
out_features=3 * self.head_dims * self.num_head)
self.out = nn.Linear(in_features=self.head_dims * self.num_head,
out_features=embed_dims)
self.softmax = nn.Softmax()
self.attn_dropout = nn.Dropout(p=attn_dropout_rate)
self.dropout = nn.Dropout(p=dropout_rate)
def forward(self, inputs):
# inputs:B,N,D
qkv = self.qkv_proj(inputs) # B,N,3*D
q, k, v = qkv.chunk(3, axis=-1) # B,N,D
B, N, D = q.shape
# 将最后一个维度embed_dims平分给每个头
q = q.reshape(shape=[B, N, self.num_head, self.head_dims])
# [B,N,self.num_head,self.head_dims] -> [B,self.num_head,N,self.head_dims]
# 这样每个头都获得了每条数据的一部分 [N,self.head_dims]
q = q.transpose(perm=[0, 2, 1, 3])
k = k.reshape(shape=[B, N, self.num_head, self.head_dims])
k = k.transpose(perm=[0, 2, 1, 3])
v = v.reshape(shape=[B, N, self.num_head, self.head_dims])
v = v.transpose(perm=[0, 2, 1, 3])
# [B,self.num_head,N,N]
attn = paddle.matmul(q, k, transpose_y=True) # q*k^T
attn = attn * self.scale
attn = self.softmax(attn) # 注意力分布
attn = self.attn_dropout(attn)
z = paddle.matmul(attn, v) # # [B,self.num_head,N, self.head_dims]
z = z.transpose(perm=[0, 2, 1, 3]) # [B,N,self.num_head, self.head_dims]
z = z.reshape(shape=[B, N, self.num_head * self.head_dims])
# 将多头结果进行组合还原(通过线性层的方式)
# 论文中是先concat再通过Linear
z = self.out(z) # [B,N,D]
z = self.dropout(z)
return z
代码
import paddle
from paddle import nn
class MLP(nn.layer):
"""
Forward
- 将输入特征映射到更高维度去学习隐藏特征
- 然后经过激活,丢弃,再回到原始输入特征大小
"""
def __init__(self,
in_features,
out_features=None,
mlp_ratio=4,
dropout_rate=0.,
act=nn.GELU):
"""
:param in_features: 输入特征大小
:param out_features: 输出特征大小 default:None
:param mlp_ratio: MLP中隐藏层伸缩比例
:param dropout_rate: 丢弃率
:param act: 激活函数 nn.GELU or nn.functional
"""
super(MLP, self).__init__()
self.in_features = in_features
self.out_features = out_features if out_features is None \
else in_features
self.mlp_ratio = mlp_ratio
self.dropout_rate = dropout_rate
# 将输入维度映射到隐藏层特征维度
self.fc1 = nn.Linear(in_features=in_features,
out_features=int(in_features * mlp_ratio))
# 将输入从隐藏层维度降回指定的输出维度
self.fc2 = nn.Linear(in_features=int(in_features * mlp_ratio),
out_features=self.out_features)
self.act = act()
self.dropout = nn.Dropout(p=dropout_rate)
def forward(self, inputs):
x = self.fc1(inputs)
x = self.act(x)
x = self.fc2(x)
x = self.dropout(x)
return x
class Attetion(nn.layer):
"""
多头注意力
- 使用伸缩点积模型
Forward:
- 输入每条为[N,D]的数据,初始化QKV矩阵
- 再将QKV矩阵转化为多头,并把每条数据的一部分[N,head_dims]分配给每个头
- 伸缩点积模型计算,获得多头结果
- 将多头结果进行组合还原(通过线性层的方式),还原回原来的维度D
"""
def __init__(self,
embed_dims=768,
num_head=12,
attn_dropout_rate=0.,
dropout_rate=0.):
"""
B(batch_size),N(seq_len),D(embed_dims)
:param embed_dims: 输入数据的维度
:param num_head: 注意力头数
:param attn_dropout_rate: 注意力分布的丢弃率
:param dropout_rate: 注意力结果的丢弃率
"""
super(Attetion, self).__init__()
self.embed_dims = embed_dims
self.num_head = num_head
assert embed_dims % num_head == 0, \
"Warning Attetion embed_dims % num_head != 0"
self.head_dims = embed_dims // num_head
self.scale = self.head_dims ** -0.5 # 开根号再取倒数
# q,k,v初始化
# B(batch_size),N(seq_len),D(embed_dims) -> B,N,3*D
self.qkv_proj = nn.Linear(in_features=embed_dims,
out_features=3 * self.head_dims * self.num_head)
self.out = nn.Linear(in_features=self.head_dims * self.num_head,
out_features=embed_dims)
self.softmax = nn.Softmax()
self.attn_dropout = nn.Dropout(p=attn_dropout_rate)
self.dropout = nn.Dropout(p=dropout_rate)
def forward(self, inputs):
# inputs:B,N,D
qkv = self.qkv_proj(inputs) # B,N,3*D
q, k, v = qkv.chunk(3, axis=-1) # B,N,D
B, N, D = q.shape
# 将最后一个维度embed_dims平分给每个头
q = q.reshape(shape=[B, N, self.num_head, self.head_dims])
# [B,N,self.num_head,self.head_dims] -> [B,self.num_head,N,self.head_dims]
# 这样每个头都获得了每条数据的一部分 [N,self.head_dims]
q = q.transpose(perm=[0, 2, 1, 3])
k = k.reshape(shape=[B, N, self.num_head, self.head_dims])
k = k.transpose(perm=[0, 2, 1, 3])
v = v.reshape(shape=[B, N, self.num_head, self.head_dims])
v = v.transpose(perm=[0, 2, 1, 3])
# [B,self.num_head,N,N]
attn = paddle.matmul(q, k, transpose_y=True) # q*k^T
attn = attn * self.scale
attn = self.softmax(attn) # 注意力分布
attn = self.attn_dropout(attn)
z = paddle.matmul(attn, v) # # [B,self.num_head,N, self.head_dims]
z = z.transpose(perm=[0, 2, 1, 3]) # [B,N,self.num_head, self.head_dims]
z = z.reshape(shape=[B, N, self.num_head * self.head_dims])
# 将多头结果进行组合还原(通过线性层的方式)
# 论文中是先concat再通过Linear
z = self.out(z) # [B,N,D]
z = self.dropout(z)
return z
class DropPath(nn.layer):
"""
多分支的Dropout
B,N,C 沿着B这个维度丢弃
paddle源码使用的是Dropout(dropout, mode="upscale_in_train")
"""
def __init__(self, p=0.):
super(DropPath, self).__init__()
self.p = p
def forward(self, inputs):
if self.p > 0 and self.training:
keep_p = 1 - self.p # 保留的部分
keep_p = paddle.to_tensor([keep_p], dtype='float32')
# B,1,1
# [B] + [1]*(inputs.ndim-1) == [1,1]
# [B,1,1]
shape = [inputs.shape[0]] + [1.] * (inputs.ndim - 1) # ??? 没理解
# 加上一个0到1的正态分布随机数
random_keep = keep_p + paddle.rand(shape=shape, dtype='float32')
# > 1.0 == 1 , < 1.0 == 0
random_mask = random_keep.floor() # 向下丢弃
# inputs: B,N,D
# random_mask: B,1,1
# 1,N,D -> 全部丢弃
output = inputs.divide(keep_p) * random_mask # 保持总的期望不变 ??? 没理解
class EncoderLayer(nn.layer):
def __init__(self,
# MLP 参数和 Attetion参数
embed_dims=768,
mlp_ratio=4,
num_head=12,
attn_dropout_rate=0.,
dropout_rate=0.,
droppath_rate=0.,
act=nn.GELU,
norm=nn.LayerNorm
):
"""
:param embed_dims:
:param mlp_ratio:
:param num_head:
:param attn_dropout_rate:
:param dropout_rate: 注意力结果丢弃率&MLP丢弃率
:param droppath_rate: 多分支丢弃率
:param act:
:param norm: 归一化层
"""
super(EncoderLayer, self).__init__()
self.embed_dims = embed_dims
self.mlp_ratio = mlp_ratio
self.num_head = num_head
self.attn_dropout_rate = attn_dropout_rate
self.dropout_rate = dropout_rate
# 两个不同的norm
self.attn_norm = norm(embed_dims)
self.mlp_norm = norm(embed_dims)
self.multi_attn = Attetion(embed_dims=embed_dims,
num_head=num_head,
attn_dropout_rate=attn_dropout_rate,
dropout_rate=dropout_rate)
self.mlp = MLP(in_features=embed_dims,
mlp_ratio=4,
dropout_rate=dropout_rate,
act=act)
# paddle源码使用的是Dropout(dropout, mode="upscale_in_train")
self.attn_droppath = DropPath(p=droppath_rate)
self.mlp_droppath = DropPath(p=droppath_rate)
def forward(self, inputs):
res = inputs # 残差1
x = self.attn_norm(inputs)
x = self.mutil_attn(x)
x = self.attn_droppath(x) # dropout
x = x + res
res = x # 残差2
x = self.mlp_norm(x)
x = self.mlp(x)
x = self.mlp_droppath(x) # dropout
x = x + res
return x
class Encoder(nn.layer):
def __init__(self,
num_layers,
embed_dims=768,
mlp_ratio=4,
num_head=12,
attn_dropout_rate=0.,
dropout_rate=0.,
droppath_rate=0.,
act=nn.GELU,
norm=nn.LayerNorm
):
super(Encoder, self).__init__()
self.num_layers = num_layers
self.embed_dims = embed_dims
self.mlp_ratio = mlp_ratio
self.num_head = num_head
self.attn_dropout_rate = attn_dropout_rate
self.dropout_rate = dropout_rate
blocks = []
for i in range(num_layers):
blocks.append(
EncoderLayer(
embed_dims=embed_dims,
mlp_ratio=mlp_ratio,
num_head=num_head,
attn_dropout_rate=attn_dropout_rate,
dropout_rate=dropout_rate,
droppath_rate=droppath_rate,
act=act,
norm=norm
)
)
self.encoder_blocks = nn.LayerList(blocks) # 像list一样可以索引
def forward(self, inputs):
x = self.encoder_blocks[0](inputs)
for i in range(1, self.num_layers):
x = self.encoder_blocks[i](x)
return x