RGB-D场景识别论文阅读:MSN: Modality Separation Networks for RGB-D Scene Recognition
2020年6月26日
MSN: Modality Separation Networks for RGB-D Scene Recognition 是由 Xiong et al. 发表在SCI二区Neurocomputing的一篇关于RGB-D场景识别的论文。
一、摘要:
由于场景布局复杂且对象杂乱,基于RGB-D图像的室内场景识别是一项艰巨的任务。尽管深度模态可以提供额外的几何信息,但是如何更好地学习多模态特征仍然是一个悬而未决的问题。考虑到这一点,在本文中,我们提出了模态分离网络,以同时提取模态一致和模态特定的特征。这项工作的动机来自两个方面:1)第一个是学习每种模式的独特之处,以及明确地了解两种模式之间的共同之处。 2)第二个是探索全局/局部特征与特定于模态/一致特征之间的关系。为此,提出的框架包含两个子模块分支,以学习多模式特征。一个分支用于通过最小化两个模态之间的相似性来提取每个模态的特定特征。另一个分支是通过最大化相关项来学习两种模态之间的公共信息。此外,借助空间关注模块,我们的方法可以可视化不同子模块关注的空间位置。我们在两个公共RGB-D场景识别数据集上评估了我们的方法,并通过提出的框架获得了最新的技术成果。
二、三个贡献:
1)我们提出了一个两分支模态分离网络,以明确学习模态特定和模态一致的特征。 全局模态特定(GMS)和局部模态一致性(LMC)特征学习模块旨在同时学习特定于模态的特征和一致特征。
2)我们提出了一个局部模态一致性(LMC)特征学习模块,该模块由空间注意模块和关键特征选择模块组成,以学习局部模态一致性特征。 局部特征学习模块选择具有响应图和三元组排名损失的局部特征。 使用此模块,无需额外的注释即可学习重要的本地对象级功能。
3)我们探讨了局部/全局和模态特定/一致特征之间的关系。 据我们所知,所提出的方法是探索局部或全局特征是否更适合于学习模态一致或特定信息的第一项工作。
三、MSN网络的大体框架:
1)分别提取RGB模态和Depth模态的深度特征;
2)在Global Modal-Specific (GMS) 模块中,通过最小化correlation损失函数学习到RGB和Depth模态各自的modal-specific features;在Local Modal-Consistent (LMC) 模块中,通过最小化difference损失函数学习到RGB和Depth模态各自modal-consistent features;
3)将四个特征串联起来得到最终的特征,用于分类表示。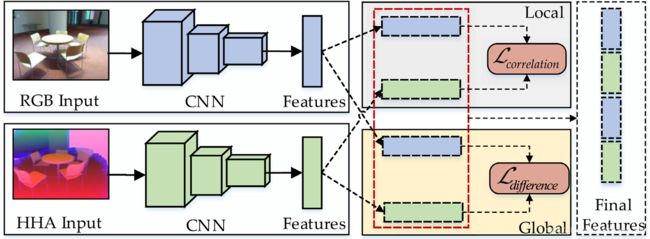
四、MSN网络框架:
MSN网络的几个主要模块:1)Local modal-consistent feature learning:由Spatial Attention, Key Feature Selection (采用Triplet loss), Modal-consistent Feature Learning (采用 correlation loss) 构成。2)Global modal-specific feature learning: 由 Spatial Attention, Modal-specific feature Learning (采用 cross-entropy loss 和 difference loss) 构成。
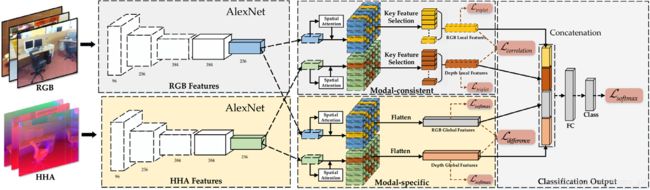
在这项工作中,使用RGB-D图像的三元组作为输入,并采用边距排序损失来选择关键的局部特征。 首先,随机采样三个RGB和HHA 编码的图像对,包括两个具有相同类别标签的样本{a,p}和一个具有不同类别标签的样本{n},以形成三元组{a,p,n}输入 (a表示锚样本,p是正样本,n是负样本)。 然后将RGB CNN分支和深度CNN分支用于第一阶段特征编码。 两个CNN分支的最后一层功能输入到建议的两个子模块:LMC模块和GMS模块。 使用这两个特征学习模块,可以提取局部模态一致特征和全局模态特定特征,以进行最终场景分类。

五、网络细节:
1)Local modal-consistent feature learning
Spatial attention module:是将Convolutional maps的每一个通道看成一个local feature, 然后通过spatial attention module学习关注到不同的空间位置。

Key feature Selection:不同于patch based local features, 本文是在在语言特征convolutional maps上面挑选k 个 key features,其好处就是卷积本身可以过滤掉一些不相关性的信息而且计算量还大。由于有些高响应的local features可能与分类任务无关,因此采用三元组损失函数(Triplet loss,即使得anchor feature与positive feature的距离相对小,anchor feature与negative feature的距离相对大)选择相同场景的不同图像中公共的特征,并且与不同场景的图像不一样的特征。

![]()
Modal-consistent feature learning:为了使得RGB模态和Depth模态的consistent特征更相似,因此使得关联损失函数尽可能的小,即让两个模态的特征cos距离尽可能的大。
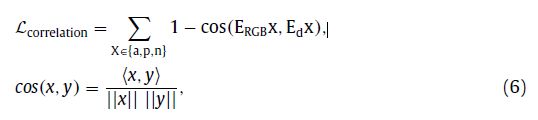
最后,Local modal-consistent features learning的损失函数为:![]()
2)Global modal-specific feature learning
先采用Spatial Attention Module分别对RGB和Depth模态的Conv maps加权,对加Attention的Conv maps做扁平化操作,得到向量化的特征。为了使得RGB模态和Depth模态的specific特征区别更大,采用交叉熵损失函数:
为了进一步使得两个特征区别更大,还使用损失函数: ,
,
最后Global modal-specific feature learning模块的损失函数为:![]()
在两个模块中学习到的四个特征最后串联起来,再加全连接层可以 train in an end-to-end manner。
## 一个半小时弄好的,所以可能有错误,望指正。 ##