lstm多变量输入回归预测模型_教你搭建多变量时间序列预测模型LSTM(附代码、数据集)...
来源:机器之心
本文长度为2527字,建议阅读5分钟
本文为你介绍如何在Keras深度学习库中搭建用于多变量时间序列预测的LSTM模型。
长短期记忆循环神经网络等几乎可以完美地模拟多个输入变量的问题,这为时间序列预测带来极大益处。本文介绍了如何在 Keras 深度学习库中搭建用于多变量时间序列预测的 LSTM 模型。
诸如长短期记忆(LSTM)循环神经网络的神经神经网络几乎可以无缝建模具备多个输入变量的问题。
这为时间序列预测带来极大益处,因为经典线性方法难以适应多变量或多输入预测问题。
通过本教程,你将学会如何在 Keras 深度学习库中搭建用于多变量时间序列预测的 LSTM 模型。
完成本教程后,你将学会:
如何将原始数据集转换成适用于时间序列预测的数据集
如何处理数据并使其适应用于多变量时间序列预测问题的 LSTM 模型。
如何做出预测并将结果重新调整到初始单元。
我们开始吧!
教程概述
本教程分为三大部分,分别是:
空气污染预测
准备基本数据
搭建多变量 LSTM 预测模型
Python 环境
本教程假设你配置了 Python SciPy 环境,Python 2/3 皆可。
你还需要使用 TensorFlow 或 Theano 后端安装 Keras(2.0 或更高版本)。
本教程还假定你已经安装了 scikit-learn、Pandas、NumPy 和 Matplotlib。
空气污染预测
本教程将使用空气质量数据集。这是美国驻北京大使馆记录了五年的数据集,其按小时报告天气和污染水平。
此数据包括日期、PM2.5 浓度,以及天气信息,包括露点、温度、气压、风向、风速和降水时长。原始数据中的完整特征列表如下:
1. NO:行号
2. year:年份
3. month:月份
4. day:日
5. hour:时
6. pm2.5:PM2.5 浓度
7. DEWP:露点
8. TEMP:温度
9. PRES:气压
10. cbwd:组合风向
11. Iws:累计风速
12. s:累积降雪时间
13. Ir:累积降雨时间
我们可以使用这些数据并构建一个预测问题,我们根据过去几个小时的天气条件和污染状况预测下一个小时的污染状况。此数据集亦可用于构建其他预测问题。
您可以从 UCI 机器学习库中下载此数据集。
下载数据集并将其命名为「raw.csv」,放置到当前工作目录。
基本数据准备
原始数据尚不可用,我们必须先处理它。
以下是原始数据集的前几行数据。

第一步,将零散的日期时间信息整合为一个单一的日期时间,以便我们可以将其用作 Pandas 的索引。
快速检查第一天的 pm2.5 的 NA 值。因此,我们需要删除第一行数据。在数据集中还有几个零散的「NA」值,我们现在可以用 0 值标记它们。
以下脚本用于加载原始数据集,并将日期时间信息解析为 Pandas DataFrame 索引。「No」列被删除,每列被指定更加清晰的名称。最后,将 NA 值替换为「0」值,并删除前一天的数据。
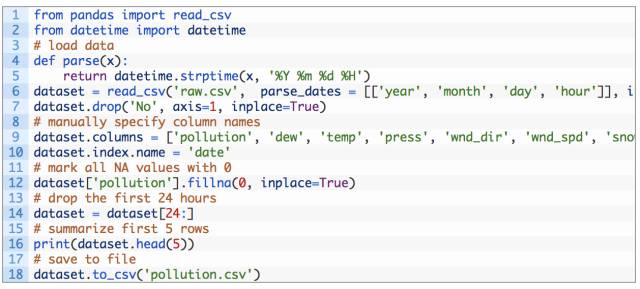
运行该例子打印转换后的数据集的前 5 行,并将转换后的数据集保存到「pollution.csv」。

现在数据已经处理得简单易用,我们可以为每个天气参数创建快图,看看能得到什么。
下面的代码加载了「pollution.csv」文件,并且为每个参数(除用于分类的风速以外)绘制了单独的子图。
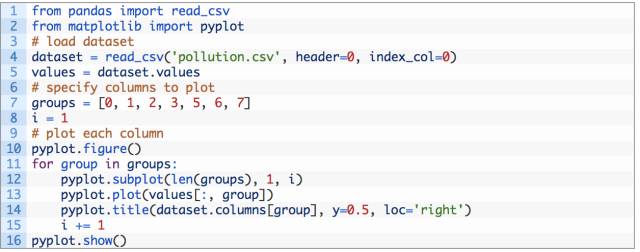
运行上例创建一个具有 7 个子图的大图,显示每个变量 5 年中的数据。

空气污染时间序列折线图
多变量 LSTM 预测模型
本节,我们将调整一个 LSTM 模型以适合此预测问题。
LSTM 数据准备
第一步是为 LSTM 模型准备污染数据集,这涉及将数据集用作监督学习问题以及输入变量归一化。
我们将监督学习问题设定为:根据上一个时间段的污染指数和天气条件,预测当前时刻(t)的污染情况。
这个表述简单直接,只是为了说明问题。你可以探索的一些替代方案包括:
根据过去一天的天气情况和污染状况,预测下一个小时的污染状况。
根据过去一天的天气情况和污染状况以及下一个小时的「预期」天气条件,预测下一个小时的污染状况。
我们可以使用之前博客中编写的 series_to_supervised()函数来转换数据集:
如何用 Python 将时间序列问题转换为监督学习问题(https://machinelearningmastery.com/convert-time-series-supervised-learning-problem-python/)
首先加载「pollution.csv」数据集。给风速特征打上标注(整型编码)。如果你再深入一点就会发现,整形编码可以进一步进行一位有效编码(one-hot encoding)。
接下来,所有特征都被归一化,然后数据集转换成监督学习问题。之后,删除要预测的时刻(t)的天气变量。
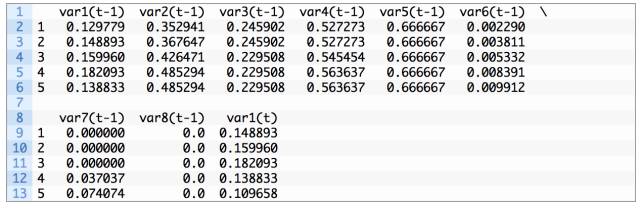
完整的代码列表如下。

运行上例打印转换后的数据集的前 5 行。我们可以看到 8 个输入变量(输入序列)和 1 个输出变量(当前的污染水平)。
这个数据准备过程很简单,我们可以深入了解更多相关知识,包括:
对风速进行一位有效编码
用差值和季节性调整使所有序列数据恒定
提供超过 1 小时的输入时间步长
最后也可能是最重要的一点,在学习序列预测问题时,LSTM 通过时间步进行反向传播。
定义和拟合模型
在本节中,我们将拟合多变量输入数据的 LSTM 模型。
首先,我们必须将准备好的数据集分成训练集和测试集。为了加快此次讲解的模型训练,我们将仅使用第一年的数据来拟合模型,然后用其余 4 年的数据进行评估。
下面的示例将数据集分成训练集和测试集,然后将训练集和测试集分别分成输入和输出变量。最后,将输入(X)重构为 LSTM 预期的 3D 格式,即 [样本,时间步,特征]。

运行此示例输出训练数据的维度,并通过测试约 9K 小时的数据对输入和输出集合进行训练,约 35K 小时的数据进行测试。
![]()
我们现在可以定义和拟合 LSTM 模型了。
我们将在第一个隐藏层中定义具有 50 个神经元的 LSTM,在输出层中定义 1 个用于预测污染的神经元。输入数据维度将是 1 个具有 8 个特征的时间步长。
我们将使用平均绝对误差(MAE)损失函数和高效的随机梯度下降的 Adam 版本。
该模型将适用于 50 个 epoch,批大小为 72 的训练。请记住,每个批结束时,Keras 中的 LSTM 的内部状态都将重置,因此内部状态是天数的函数可能有所帮助(试着证明它)。
最后,我们通过在 fit()函数中设置 validation_data 参数来跟踪训练过程中的训练和测试损失,并在运行结束时绘制训练和测试损失图。

评估模型
模型拟合后,我们可以预测整个测试数据集。
我们将预测与测试数据集相结合,并调整测试数据集的规模。我们还用预期的污染指数来调整测试数据集的规模。
通过初始预测值和实际值,我们可以计算模型的误差分数。在这种情况下,我们可以计算出与变量相同的单元误差的均方根误差(RMSE)。

完整示例
完整示例如下所示。



运行示例首先创建一幅图,显示训练中的训练和测试损失。
有趣的是,我们可以看到测试损失低于训练损失。该模型可能过度拟合训练数据。在训练过程中测绘 RMSE 可能会使问题明朗。
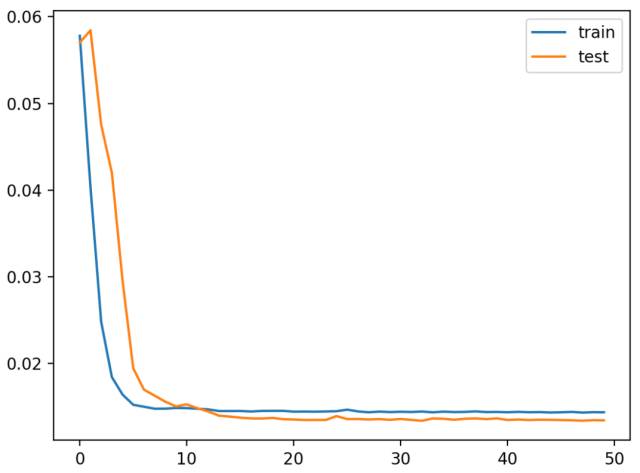
多变量 LSTM 模型训练过程中的训练、测试损失折线图
在每个训练 epoch 结束时输出训练和测试的损失。在运行结束后,输出该模型对测试数据集的最终 RMSE。我们可以看到,该模型取得了不错的 RMSE——3.836,这显著低于用持久模型(persistence model)得到的 RMSE(30)。
总结
在本教程中,您学会了如何将 LSTM 应用于多变量时间序列预测问题。
具体点讲,你学会了:
如何将原始数据集转换成适用于时间序列预测的数据集
如何处理数据并使其适应用于多变量时间序列预测问题的 LSTM 模型。
如何做出预测并将结果重新调整到初始单元。
原文链接:https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/
编辑:文婧