- python常用的第三方库下载方法
ZJ_star_1220
pycharmidepython
方法一:在windows系统中使用pip命令下载打开dos窗口输入命令“pipinstallselenium“后按回车键,看到successfully既安装成功。其他常用的命令:【pipinstallselenium==4.4.3】安装指定版本的库/包【pipinstallselenium】安装最新版本的库/包【pipshowselenium】查看库/包的安装路径、版本号【pipuninstall
- PyWavelets(pywt)安装与使用指南
贾雁冰
PyWavelets(pywt)安装与使用指南项目地址:https://gitcode.com/gh_mirrors/pyw/pywtPyWavelets是一个用于离散小波变换(DiscreteWaveletTransform,DWT)和连续小波变换(ContinuousWaveletTransform,CWT)的Python库。该库广泛应用于信号处理、图像分析以及数据压缩等领域。以下是基于提供的
- python 开放的通讯系统 高保密性
张小秦
命令模式算法python
优点1.点对点(P2P)加密通信:•采用点对点通信模式,消息直接在客户端之间传输,无需通过中央服务器。•提高隐私性,避免中央服务器成为单点故障或攻击目标。•降低通信延迟,消息传输更高效。2.强大的加密机制:•使用AES(高级加密标准)对消息进行加密,确保通信内容的安全性。•每个会话生成唯一的加密密钥,确保密钥的安全性。•使用AES的EAX模式,支持加密和消息认证,防止消息被篡改。3.临时数据存储:
- Python的pywt库的安装
赵孝正
Python标准库使用#python和pip安装python数据库开发语言
目录pywt库的全称是PyWavelets,https://pywavelets.readthedocs.io/en/latest/。安装pywt库:pipinstallPyWavelets而不是VS2017中默认的pipinstallpywt,真是坑啊。>>>importpywt>>>x=[3,7,1,1,-2,5,4,6]>>>cA,cD=pywt.dwt(x,‘db2′)>>>printcA
- Python漂浮爱心代码
Want595
趣味编程python开发语言
目录系列文章前言小海龟漂浮爱心完整代码尾声系列文章序号直达链接表白系列1Python无法拒绝的表白界面(完整代码)_python玫瑰花雨编程-CSDN博客2Python满屏飘字表白代码(完整代码)_抖音同款满屏飘字表白代码(python版)-CSDN博客3Python无限弹窗满屏表白代码(完整代码)_python弹窗满屏幕-CSDN博客4Python李峋同款跳动的爱心(完整代码)_python绘制
- VSCode 2025最新后端开发必备插件汇总(必备插件合集,Python、Java、Go等语言)
Code_流苏
实用软件与高效工具vscodepythonjava后端开发必备插件合集
前言:作为微软推出的轻量级跨平台编辑器,VSCode凭借智能代码补全、远程开发、Git集成等核心功能,已成为后端开发者首选工具。其强大的插件生态更是覆盖了主流后端语言支持、代码质量优化、性能分析等全场景需求。名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder)目录一、语言支持类插件二、代码质量和格式化工具三、数据库工具四、AP
- 2025年Python后端开发指南:从基础到云原生实践
ctrl_cv工程师¥
云原生djangoflaskpycharm
在2025年,Python后端开发已全面进入云原生与智能化时代。开发者不仅需要掌握传统后端技术栈,还需融合容器化、AI辅助编程等新兴技术。本文基于行业最新趋势与最佳实践,系统梳理Python后端开发的核心要点与进阶方向,涵盖开发环境、架构设计、性能优化等关键领域。一、开发环境与工具链1.环境配置标准化Python版本:推荐Python3.12+,支持模式匹配(PatternMatching)和更优
- shell脚本 重启python脚本
mzgong
python
#!/bin/bashwhiletrue#循环检测脚本是否停止doprocnum=$(ps-ef|grep"run.py"|grep-vgrep|wc-l)#记录正在运行run.py的数量echo"ps-efgrepreturn:"${procnum}#信息输出if[[${procnum}==0]];then#如果run.py正在运行数量等于0,脚本中断,需要重启filename=$(date+%
- 使用Python的 multiprocessing 模块实现多进程并行计算(上完整代码)
小码小李
开发语言python数据库
使用Python的multiprocessing模块实现多进程并行计算的较为详细复杂的示例代码,用于计算一个较大范围内数字的平方,并将结果汇总。以下是一个更具体、复杂且详尽的多进程并行计算代码示例,用于分析多个大型文本文件中单词出现的频率:importmultiprocessingimporttimeimportrefromcollectionsimportCounter#函数用于读取单个文件内容
- You are using pip version 10.0.1, however version 20.0.2 is available.的解决方案
柒柒钏
小知识点python
在安装第三方库时出现以下提示:Youareusingpipversion10.0.1,howeverversion20.0.2isavailable.输入:python-mpipinstall--upgradepip结果:还是提示上述错误输入:python-mpipinstall--Upip结果:如下所示,更新完成之后继续安装第三库即可。
- 【Python】全局解释器锁(Global Interpreter Lock,GIL)
彬彬侠
Python基础全局解释器锁GILCPython多进程C扩展python
全局解释器锁(GlobalInterpreterLock,简称GIL)是CPython(Python的标准实现)中的一个机制,它确保同一时刻只有一个线程在执行Python字节码。GIL的主要作用是保护Python内部的数据结构,避免多线程访问共享数据时发生竞争条件,导致数据损坏。GIL的工作原理在Python的多线程环境中,GIL会限制多个线程同时执行Python字节码。尽管操作系统可以调度多个线
- 深度学习在医疗影像诊断中的应用与实现
Evaporator Core
#DeepSeek快速入门人工智能#深度学习深度学习人工智能
引言随着人工智能技术的快速发展,深度学习在医疗领域的应用日益广泛,尤其是在医疗影像诊断方面。医疗影像数据量大、复杂度高,传统的诊断方法往往依赖于医生的经验,容易受到主观因素的影响。而深度学习通过自动学习特征,能够从海量数据中提取出有用的信息,辅助医生进行更精准的诊断。本文将探讨深度学习在医疗影像诊断中的应用,并通过代码示例展示如何实现一个简单的医疗影像分类模型。深度学习在医疗影像诊断中的应用1.图
- PINN物理信息网络 | 基于物理信息神经网络PINN求解Burger方程
算法如诗
物理信息网络(PINN)神经网络人工智能深度学习物理信息网络
基于物理信息神经网络(PINN)求解Burger方程的研究背景源于对非线性偏微分方程(PDE)求解方法的不断探索和改进。传统的数值方法,如有限差分法和有限元法,通常需要进行网格离散化和迭代求解,对于复杂的非线性问题计算成本较高。因此,研究人员开始探索基于机器学习和神经网络的新方法来求解PDEs。神经网络在近年来取得了显著的发展,能够通过学习大量数据来建立输入和输出之间的复杂映射关系。然而,将神经网
- C++调用Python程序方法
超级大反派@_@
C++c++python开发语言
前言:在之前做的一个项目中,要使用一段Python的代码。一般来讲可以将Python代码中的功能在C++项目中重构,但是如果Python项目太大,或者这部分是别人写的,自己不清楚整个项目的逻辑,这样重构起来就比较麻烦。这里给出了另外一种实现方法,即利用Python的API使得C++项目可以直接启动Python程序,快速在PC端验证代码功能。急性子可直接看:2.2C++调用python有参有返回值函
- 1985-2024年地级市人工智能专利数据
经管数据库
人工智能
《地级市人工智能专利数据(1985-2024)》于2025年1月完成最新更新。数据聚焦于中国各地级市,时间跨度设定为1985年至2024年。在数据整理过程中,参照《关键数字技术专利分类体系(2023)》,依据其中“人工智能”类技术的专利分类号,结合国家知识产权局所提供的信息,对各地每年的专利申请展开搜索与匹配。在此基础上,从众多专利申请中精准筛选出属于“人工智能”类别的专利,并进行数量统计,数据涵
- vscode中调试Python和C++的混合代码
destiny44123
vscodepythonc++
文章目录使用流程参考一些差异使用流程参考ExampledebuggingmixedPythonC++inVSCode一些差异这里假设的项目是通过python调用c++的相应共享库(so)文件。首先,新建文件夹.vscode,在其中添加文件配置launch.json.示例如下:{"version":"0.2.0","configurations":[{"name":"(gdb)附加","type":
- Python一键搞定Word与PDF文档批量转换
Selina .a
python教程pythonwordpdf
在日常工作中,我们经常需要将Word文档(.docx)转换为PDF格式,或者反过来操作。手动进行这种转换不仅费时费力,还容易出错。为此,我们可以利用Python编写一个批量转换工具,一键搞定Word与PDF文档的转换。本文将详细介绍如何实现这一目标,并提供源码和工具。所需库的安装首先,我们需要安装一些Python库来实现这个功能。推荐使用以下两个库:python-docx:用于处理Word文件内容
- 【Python】multiprocessing 模块:多进程并行计算
彬彬侠
Python基础multiprocessing多进程ProcessPoolManagerLockpython
Pythonmultiprocessing模块Python的multiprocessing模块用于多进程并行计算,可以充分利用多核CPU进行任务加速,突破PythonGIL(全局解释器锁)的限制,提高程序执行效率。1.为什么使用multiprocessing?Python默认的threading模块使用线程进行并发,但由于GIL(全局解释器锁)的存在,多线程无法真正实现CPU级别的并行计算,适用于
- python语言写的一款pdf转word、word转pdf的免费工具
典龙330
pdfword
Word与PDF文件转换工具这是一个简单的Web应用程序,允许用户将Word文档转换为PDF文件,或将PDF文件转换为Word文档。功能特点-Word(.docx)转换为PDF-PDF转换为Word(.docx)-简单易用的Web界面-即时转换和下载-详细的错误处理和日志记录安装要求-Python3.7或更高版本-依赖库(见requirements.txt)-对于Word到PDF的转换,建议安装L
- python实现KNN算法的手写数字识别:深入解析与完整项目流程
快撑死的鱼
Python算法精解算法
随着人工智能和机器学习的快速发展,图像识别技术在多个领域得到广泛应用。而手写数字识别作为图像识别的典型场景之一,已经成为研究者和开发者学习、应用机器学习算法的经典项目。本文将深入解析如何使用Python编程语言,结合KNN(K-最近邻)算法实现手写数字识别系统。文章不仅介绍了算法的核心原理,还从用户交互、图像处理、数据预处理等多个角度对整个项目进行了全方位的讲解。读者通过本文,可以全面掌握手写数字
- 《今日AI-人工智能-编程日报》
小亦工作室
人工智能
1.AI行业动态1.1Manus通用智能体初成型,开启AIAgent新时代中泰证券发布研报称,首款通用型AI智能体Manus已问世,能够将复杂任务拆解为可执行的步骤链,并在虚拟环境中灵活调用工具,标志着AI从“Reasoner”走向“Agent”阶段。Manus的成功引发了开源复现潮,DeepSeek模型已被整合到OWL项目中,并在GAIA基准测试中表现接近Manus。1.2DeepSeek-R2
- 1章5节:大模型术语解读与从生成到推理的演进
DAT|R科学与人工智能
人工智能
在人工智能的浩瀚宇宙中,大模型正以前所未有的速度演进,推动着科技变革的新浪潮。从多模态到通用模型,再到行业模型,人工智能的边界不断拓展,为各行各业带来了全新的机遇与挑战。本篇文章将深入剖析大模型相关的核心术语,探讨其内涵、应用及发展趋势,并回顾大模型从生成到推理的演进历程,解析全球科技巨头与国内前沿企业在这一领域的竞争与创新。让我们一同探索大模型的演进脉络,把握智能时代的发展脉搏。一、剖析大模型相
- 云原生周刊:基于 KubeSphere LuBan 架构打造DeepSeek 插件
云计算
开源项目推荐KubeAIKubeAI是一个K8s上的AI推理操作器,旨在简化在生产环境中部署和管理大型语言模型(LLM)、向量嵌入和语音处理等机器学习模型。它提供与OpenAI兼容的API,支持在CPU和GPU上运行,并具备按需自动扩缩容的能力。KubeAI无需依赖Istio、Knative等其他系统,能够在几乎任何K8s集群中开箱即用。此外,它内置了模型代理,优化了键值缓存利用率,从而显著提升系
- python webdriver-manager 实现selenium 免下载安装webdriver
小马MT
pythonselenium爬虫
pythonwebdriver-manager实现selenium免下载安装webdriverselenium在自动化测试中,通常需要使用浏览器驱动来与浏览器进行交互。然而,手动下载、安装、以及管理这些驱动非常麻烦,尤其是当驱动版本频繁更新时。为此,webdriver-manager库提供了一个极简的方案,自动帮我们下载、更新和管理驱动,使Selenium代码更简洁优雅。webdriver-man
- python tkinter控件位置_python tkinter组件摆放方式详解
weixin_39895995
pythontkinter控件位置
1.最小界面组成#导入tkinter模块importtkinter#创建主窗口对象root=tkinter.Tk()#设置窗口大小(最小值:像素)root.minsize(300,300)#创建一个按钮组件btn=tkinter.Button(root,text='屠龙宝刀,点击送')btn.pack()#加入消息循环root.mainloop()设置初始化界面大小#设置初始化界面大小root.g
- python表格控件_Python使用tkinter的Treeview组件实现表格功能
weixin_39619481
python表格控件
fromtkinterimportTk,Scrollbar,Framefromtkinter.ttkimportTreeview#创建tkinter应用程序窗口root=Tk()#设置窗口大小和位置root.geometry('500x300400300')#不允许改变窗口大小root.resizable(False,False)#设置窗口标题root.title('通信录管理系统')#使用Tre
- Microsoft Fabric 功能更新!更多智能优化,数据平台更强大
近期,微软MicrosoftFabric又更新了,大大增强了AI方面的功能。迅易科技作为微软13年来紧密的生态合作伙伴,为300+行业头部客户实施1000+项目。今天,我们带大家来看下,MicrosoftFabric有什么新玩法?一年前,微软正式推出了一款端到端数据平台,MicrosoftFabric(国际版)是一个集成一体化的平台,提供支持各种数据项目的人工智能驱动服务,帮助所有数据团队能够更快
- 深入探究 Ryu REST API
漫谈网络
网络技术进阶通途网络
Ryu4.34RESTAPI详细接口说明与示例Ryu4.34的RESTAPI提供了对SDN网络的核心管理功能,涵盖交换机、流表、端口、拓扑和QoS等操作。以下是详细的接口分类、功能说明及Python示例代码。1.交换机管理1.1获取所有交换机DPID端点:GET/stats/switches功能:返回当前连接到控制器的所有交换机的DPID(数据路径标识符)列表。示例:importrequestsR
- python web开发pyramid库安装与使用
范哥来了
python
为了在Python中使用Pyramid进行Web开发,你需要先安装Pyramid库。接着我会指导你如何安装它,并给出一个简单的示例来展示如何创建一个基本的Pyramid应用。安装Pyramid确保你的环境中已经安装了pip工具,然后可以通过以下命令安装Pyramid:pipinstallpyramid如果你想要开始一个新的Pyramid项目,推荐同时安装pyramid_starter模板,这可以帮
- Python激活码
qq_36357944
Python
EB101IWSWD-eyJsaWNlbnNlSWQiOiJFQjEwMUlXU1dEIiwibGljZW5zZWVOYW1lIjoibGFuIHl1IiwiYXNzaWduZWVOYW1lIjoiIiwiYXNzaWduZWVFbWFpbCI6IiIsImxpY2Vuc2VSZXN0cmljdGlvbiI6IkZvciBlZHVjYXRpb25hbCB1c2Ugb25seSIsImNoZWNrQ
- Spring4.1新特性——综述
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- Schema与数据类型优化
annan211
数据结构mysql
目前商城的数据库设计真是一塌糊涂,表堆叠让人不忍直视,无脑的架构师,说了也不听。
在数据库设计之初,就应该仔细揣摩可能会有哪些查询,有没有更复杂的查询,而不是仅仅突出
很表面的业务需求,这样做会让你的数据库性能成倍提高,当然,丑陋的架构师是不会这样去考虑问题的。
选择优化的数据类型
1 更小的通常更好
更小的数据类型通常更快,因为他们占用更少的磁盘、内存和cpu缓存,
- 第一节 HTML概要学习
chenke
htmlWebcss
第一节 HTML概要学习
1. 什么是HTML
HTML是英文Hyper Text Mark-up Language(超文本标记语言)的缩写,它规定了自己的语法规则,用来表示比“文本”更丰富的意义,比如图片,表格,链接等。浏览器(IE,FireFox等)软件知道HTML语言的语法,可以用来查看HTML文档。目前互联网上的绝大部分网页都是使用HTML编写的。
打开记事本 输入一下内
- MyEclipse里部分习惯的更改
Array_06
eclipse
继续补充中----------------------
1.更改自己合适快捷键windows-->prefences-->java-->editor-->Content Assist-->
Activation triggers for java的右侧“.”就可以改变常用的快捷键
选中 Text
- 近一个月的面试总结
cugfy
面试
本文是在学习中的总结,欢迎转载但请注明出处:http://blog.csdn.net/pistolove/article/details/46753275
前言
打算换个工作,近一个月面试了不少的公司,下面将一些面试经验和思考分享给大家。另外校招也快要开始了,为在校的学生提供一些经验供参考,希望都能找到满意的工作。
- HTML5一个小迷宫游戏
357029540
html5
通过《HTML5游戏开发》摘抄了一个小迷宫游戏,感觉还不错,可以画画,写字,把摘抄的代码放上来分享下,喜欢的同学可以拿来玩玩!
<html>
<head>
<title>创建运行迷宫</title>
<script type="text/javascript"
- 10步教你上传githib数据
张亚雄
git
官方的教学还有其他博客里教的都是给懂的人说得,对已我们这样对我大菜鸟只能这么来锻炼,下面先不玩什么深奥的,先暂时用着10步干净利索。等玩顺溜了再用其他的方法。
操作过程(查看本目录下有哪些文件NO.1)ls
(跳转到子目录NO.2)cd+空格+目录
(继续NO.3)ls
(匹配到子目录NO.4)cd+ 目录首写字母+tab键+(首写字母“直到你所用文件根就不再按TAB键了”)
(查看文件
- MongoDB常用操作命令大全
adminjun
mongodb操作命令
成功启动MongoDB后,再打开一个命令行窗口输入mongo,就可以进行数据库的一些操作。输入help可以看到基本操作命令,只是MongoDB没有创建数据库的命令,但有类似的命令 如:如果你想创建一个“myTest”的数据库,先运行use myTest命令,之后就做一些操作(如:db.createCollection('user')),这样就可以创建一个名叫“myTest”的数据库。
一
- bat调用jar包并传入多个参数
aijuans
下面的主程序是通过eclipse写的:
1.在Main函数接收bat文件传递的参数(String[] args)
如: String ip =args[0]; String user=args[1]; &nbs
- Java中对类的主动引用和被动引用
ayaoxinchao
java主动引用对类的引用被动引用类初始化
在Java代码中,有些类看上去初始化了,但其实没有。例如定义一定长度某一类型的数组,看上去数组中所有的元素已经被初始化,实际上一个都没有。对于类的初始化,虚拟机规范严格规定了只有对该类进行主动引用时,才会触发。而除此之外的所有引用方式称之为对类的被动引用,不会触发类的初始化。虚拟机规范严格地规定了有且仅有四种情况是对类的主动引用,即必须立即对类进行初始化。四种情况如下:1.遇到ne
- 导出数据库 提示 outfile disabled
BigBird2012
mysql
在windows控制台下,登陆mysql,备份数据库:
mysql>mysqldump -u root -p test test > D:\test.sql
使用命令 mysqldump 格式如下: mysqldump -u root -p *** DBNAME > E:\\test.sql。
注意:执行该命令的时候不要进入mysql的控制台再使用,这样会报
- Javascript 中的 && 和 ||
bijian1013
JavaScript&&||
准备两个对象用于下面的讨论
var alice = {
name: "alice",
toString: function () {
return this.name;
}
}
var smith = {
name: "smith",
- [Zookeeper学习笔记之四]Zookeeper Client Library会话重建
bit1129
zookeeper
为了说明问题,先来看个简单的示例代码:
package com.tom.zookeeper.book;
import com.tom.Host;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.Wat
- 【Scala十一】Scala核心五:case模式匹配
bit1129
scala
package spark.examples.scala.grammars.caseclasses
object CaseClass_Test00 {
def simpleMatch(arg: Any) = arg match {
case v: Int => "This is an Int"
case v: (Int, String)
- 运维的一些面试题
yuxianhua
linux
1、Linux挂载Winodws共享文件夹
mount -t cifs //1.1.1.254/ok /var/tmp/share/ -o username=administrator,password=yourpass
或
mount -t cifs -o username=xxx,password=xxxx //1.1.1.1/a /win
- Java lang包-Boolean
BrokenDreams
boolean
Boolean类是Java中基本类型boolean的包装类。这个类比较简单,直接看源代码吧。
public final class Boolean implements java.io.Serializable,
- 读《研磨设计模式》-代码笔记-命令模式-Command
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
/**
* GOF 在《设计模式》一书中阐述命令模式的意图:“将一个请求封装
- matlab下GPU编程笔记
cherishLC
matlab
不多说,直接上代码
gpuDevice % 查看系统中的gpu,,其中的DeviceSupported会给出matlab支持的GPU个数。
g=gpuDevice(1); %会清空 GPU 1中的所有数据,,将GPU1 设为当前GPU
reset(g) %也可以清空GPU中数据。
a=1;
a=gpuArray(a); %将a从CPU移到GPU中
onGP
- SVN安装过程
crabdave
SVN
SVN安装过程
subversion-1.6.12
./configure --prefix=/usr/local/subversion --with-apxs=/usr/local/apache2/bin/apxs --with-apr=/usr/local/apr --with-apr-util=/usr/local/apr --with-openssl=/
- sql 行列转换
daizj
sql行列转换行转列列转行
行转列的思想是通过case when 来实现
列转行的思想是通过union all 来实现
下面具体例子:
假设有张学生成绩表(tb)如下:
Name Subject Result
张三 语文 74
张三 数学 83
张三 物理 93
李四 语文 74
李四 数学 84
李四 物理 94
*/
/*
想变成
姓名 &
- MySQL--主从配置
dcj3sjt126com
mysql
linux下的mysql主从配置: 说明:由于MySQL不同版本之间的(二进制日志)binlog格式可能会不一样,因此最好的搭配组合是Master的MySQL版本和Slave的版本相同或者更低, Master的版本肯定不能高于Slave版本。(版本向下兼容)
mysql1 : 192.168.100.1 //master mysq
- 关于yii 数据库添加新字段之后model类的修改
dcj3sjt126com
Model
rules:
array('新字段','safe','on'=>'search')
1、array('新字段', 'safe')//这个如果是要用户输入的话,要加一下,
2、array('新字段', 'numerical'),//如果是数字的话
3、array('新字段', 'length', 'max'=>100),//如果是文本
1、2、3适当的最少要加一条,新字段才会被
- sublime text3 中文乱码解决
dyy_gusi
Sublime Text
sublime text3中文乱码解决
原因:缺少转换为UTF-8的插件
目的:安装ConvertToUTF8插件包
第一步:安装能自动安装插件的插件,百度“Codecs33”,然后按照步骤可以得到以下一段代码:
import urllib.request,os,hashlib; h = 'eb2297e1a458f27d836c04bb0cbaf282' + 'd0e7a30980927
- 概念了解:CGI,FastCGI,PHP-CGI与PHP-FPM
geeksun
PHP
CGI
CGI全称是“公共网关接口”(Common Gateway Interface),HTTP服务器与你的或其它机器上的程序进行“交谈”的一种工具,其程序须运行在网络服务器上。
CGI可以用任何一种语言编写,只要这种语言具有标准输入、输出和环境变量。如php,perl,tcl等。 FastCGI
FastCGI像是一个常驻(long-live)型的CGI,它可以一直执行着,只要激活后,不
- Git push 报错 "error: failed to push some refs to " 解决
hongtoushizi
git
Git push 报错 "error: failed to push some refs to " .
此问题出现的原因是:由于远程仓库中代码版本与本地不一致冲突导致的。
由于我在第一次git pull --rebase 代码后,准备push的时候,有别人往线上又提交了代码。所以出现此问题。
解决方案:
1: git pull
2:
- 第四章 Lua模块开发
jinnianshilongnian
nginxlua
在实际开发中,不可能把所有代码写到一个大而全的lua文件中,需要进行分模块开发;而且模块化是高性能Lua应用的关键。使用require第一次导入模块后,所有Nginx 进程全局共享模块的数据和代码,每个Worker进程需要时会得到此模块的一个副本(Copy-On-Write),即模块可以认为是每Worker进程共享而不是每Nginx Server共享;另外注意之前我们使用init_by_lua中初
- java.lang.reflect.Proxy
liyonghui160com
1.简介
Proxy 提供用于创建动态代理类和实例的静态方法
(1)动态代理类的属性
代理类是公共的、最终的,而不是抽象的
未指定代理类的非限定名称。但是,以字符串 "$Proxy" 开头的类名空间应该为代理类保留
代理类扩展 java.lang.reflect.Proxy
代理类会按同一顺序准确地实现其创建时指定的接口
- Java中getResourceAsStream的用法
pda158
java
1.Java中的getResourceAsStream有以下几种: 1. Class.getResourceAsStream(String path) : path 不以’/'开头时默认是从此类所在的包下取资源,以’/'开头则是从ClassPath根下获取。其只是通过path构造一个绝对路径,最终还是由ClassLoader获取资源。 2. Class.getClassLoader.get
- spring 包官方下载地址(非maven)
sinnk
spring
SPRING官方网站改版后,建议都是通过 Maven和Gradle下载,对不使用Maven和Gradle开发项目的,下载就非常麻烦,下给出Spring Framework jar官方直接下载路径:
http://repo.springsource.org/libs-release-local/org/springframework/spring/
s
- Oracle学习笔记(7) 开发PLSQL子程序和包
vipbooks
oraclesql编程
哈哈,清明节放假回去了一下,真是太好了,回家的感觉真好啊!现在又开始出差之旅了,又好久没有来了,今天继续Oracle的学习!
这是第七章的学习笔记,学习完第六章的动态SQL之后,开始要学习子程序和包的使用了……,希望大家能多给俺一些支持啊!
编程时使用的工具是PLSQL
 的正则化项添加到成本函数。这迫使学习算法不仅拟合数据,而且还使模型权重尽可能小。注意仅在训练期间将正则化项添加到成本函数中。训练完模型后,你要使用非正则化的性能度量来评估模型的性能。
的正则化项添加到成本函数。这迫使学习算法不仅拟合数据,而且还使模型权重尽可能小。注意仅在训练期间将正则化项添加到成本函数中。训练完模型后,你要使用非正则化的性能度量来评估模型的性能。
 没有进行正则化(总和从i=1开始,而不是0)。如果我们将w定义为特征权重的向量
没有进行正则化(总和从i=1开始,而不是0)。如果我们将w定义为特征权重的向量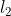 范数。对于梯度下降,只需将αw添加到MSE梯度向量
范数。对于梯度下降,只需将αw添加到MSE梯度向量