刘二大人CNN
10.卷积神经网络(基础篇)_哔哩哔哩_bilibili
0、前一部分 卷积层 和 subsampling 叫做Feature Extraction特征提取器,后一部分叫做classification

1、每一个卷积核它的通道数量要求和输入通道是一样的。这种卷积核的总数有多少个和你输出通道的数量是一样的。
2、卷积(convolution)后,C(Channels)变,W(width)和H(Height)可变可不变,取决于是否padding。subsampling(或pooling)后,C不变,W和H变。
3、卷积层:保留图像的空间信息。
4、卷积层要求输入输出是四维张量(B,C,W,H),全连接层的输入与输出都是二维张量(B,Input_feature)。
传送门 PyTorch的nn.Linear()详解
5、卷积(线性变换),激活函数(非线性变换),池化;这个过程若干次后,view打平,进入全连接层~
处理图像经常用:二维卷积神经网络
把图像通过一个卷积层,来保留图像的空间特征
做成全连接会丧失一些空间结构信息。
CNN是把图像直接按照原始的空间结构来进行保存
subsampling目的是减少feature maps的数据量
栅格图像是我们用从自然界获取图像的方式,处理图像时ccd 电子器件 光敏电阻 随着光照电阻值发生变化,一个光敏电阻就能处理一个光锥;光敏做的越小 捕获的光锥就越小 图像分辨率就高;把这些光敏电阻做成阵列,每个光敏电阻就叫做像素。
这是一个黑白的数码摄像的采集器
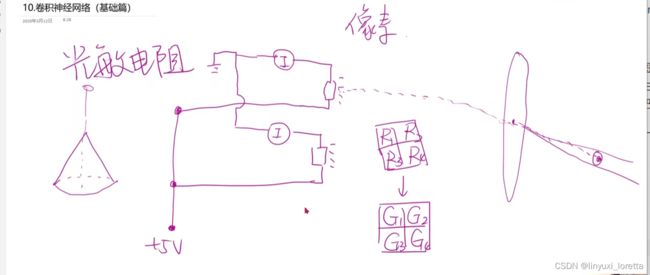
彩色图像要对传感器做进一步的改进,
处理一个像素拓展成传感器阵列,这个像素的值来自于三种光敏器件
这里其实也正好解释了为什么抠图要用绿幕,因为绿色在每个像素就多一些
矢量图像大部分都是人工生成或者程序生成的,现画的,所以 随意缩放也不会改变清晰度



因为在pytorch里面、所有的输入数据必须是小批量的数据啊
torch.randn() 从正太分布采样的随机数

stride=2进行卷积运算时的步长,默认为1;bias=False卷积运算是否需要偏置bias,默认为False。padding = 0,卷积操作是否补0。

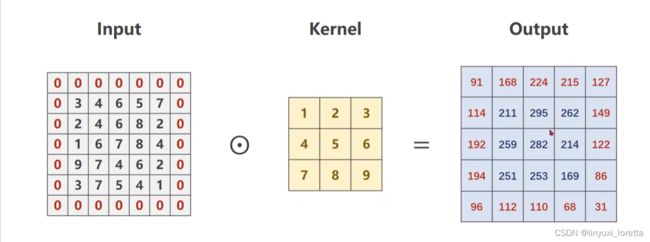



先做 relu还是先做池化区别不大,先池化后relu计算量小一些
view()函数用来转换size大小。x = x.view(batchsize, -1)中batchsize指转换后有几行,而-1指根据原tensor数据和batchsize自动分配列数。
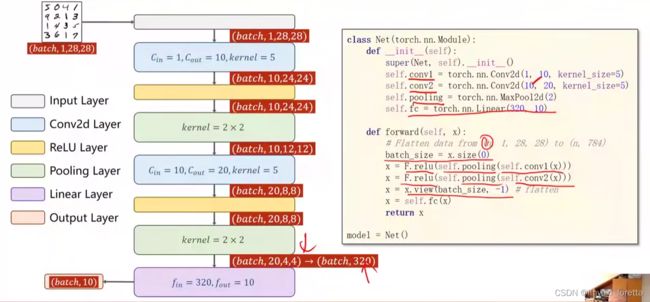
将上一讲的模型换成这个即可
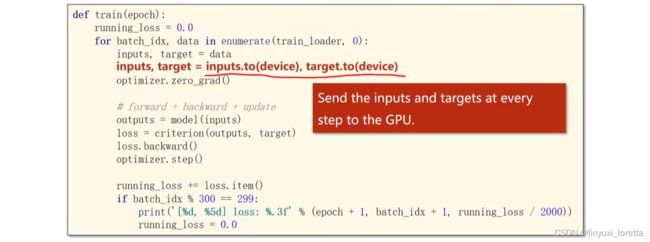
运算迁移到GPU,1. move model to GPU
模型参数和缓存 都放到cuda上

2. move tensors to GPU 移动计算的张量、输入和输出


2、self.fc = torch.nn.Linear(320, 10),这个320获取的方式,可以通过x = x.view(batch_size, -1) # print(x.shape)可得到(64,320),64指的是batch,320就是指要进行全连接操作时,输入的特征维度。
11.卷积神经网络(高级篇)_哔哩哔哩_bilibili

这个结构和物联网课里提到的LeNet5很接近
other:拼接层等...
减少代码冗余:
在过程式的编程范式里 比如C语言,我们使用函数
面向对象,类
GoogLeNet
googleNet可以说是现在非常常用的一种基础架构,我们经常拿这个网络做主干网络,再给他做一些修改,

实际上inception model有好多可以构造的方式
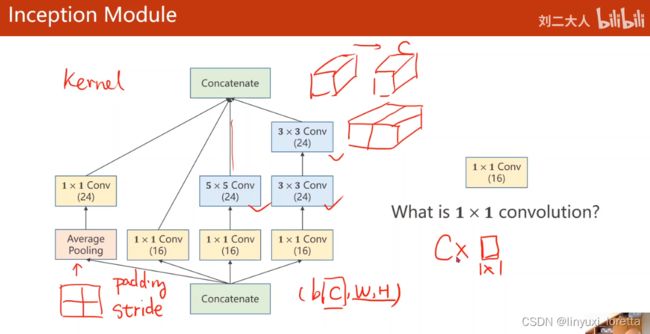
concatenate 把张量沿着通道拼接到一起
Inception Moudel
1、卷积核超参数选择困难,自动找到卷积的最佳组合。
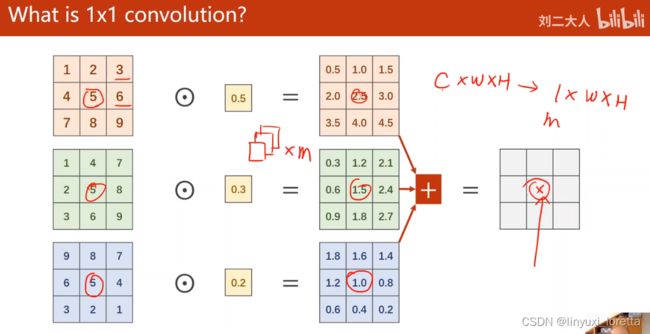
2、1x1卷积核,不同通道的信息融合。作用:改变通道个数 network in network





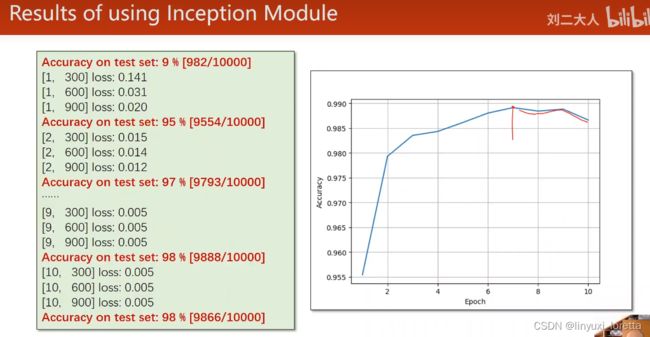
观察test来看训练多少轮合适。 准确率达到新高时,备份当前网络参数,

residual net
要解决的问题:梯度消失
跳连接,H(x) = F(x) + x,张量维度必须一样,加完后再激活。

就可以把离输入非常近的那些层进行充分的训练

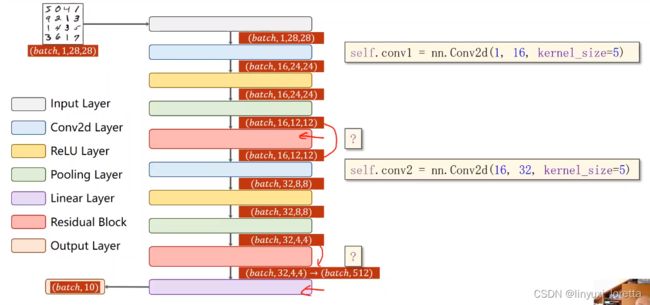

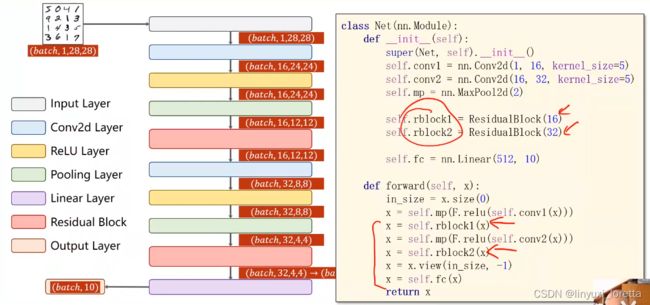
最重要是在构造网络时,要把这个网络里面的超参数以及它的输入输出的这些size,要算出来
增量式开发
identity mapping in deep residual network论文

DenseNet
后面的路怎么走:

读代码,学习别人做的系统架构,训练的架构、测试的架构、数据读取的架构、损失函数的构建
根据论文尝试自己写,卡住了去读代码,循环。