机器学习笔记之条件随机场(四)建模对象描述(参数表示vs向量表示)
机器学习笔记之条件随机场——建模对象描述
- 引言
-
- 回顾:
-
- 最大团与势函数
- 最大熵模型
- 条件随机场
-
- 条件随机场的合理性
- 个人理解:条件随机场PDF的表示形式
- 向量角度描述条件概率(2022/11/13)
-
- 状态转移过程逻辑解释
- 条件概率的简化过程
-
- 场景设计
- 简化过程
引言
上一节介绍了最大熵马尔可夫模型(Maximum Entropy Markov Model,MEMM)中的标注偏置问题,本节将介绍条件随机场(Condition Random Field,CRF),并介绍它的建模思想以及概率密度函数 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)。
回顾:
最大团与势函数
在马尔可夫随机场的结构表示中介绍过极大团(Maximum Clique)。极大团表示马尔可夫随机场中结点的子集,该子集需要满足的条件是:子集内部任意两结点之间都有边连接,并且在该子集中加入任意一个结点后都不再形成团。
已知马尔可夫随机场示例如下:
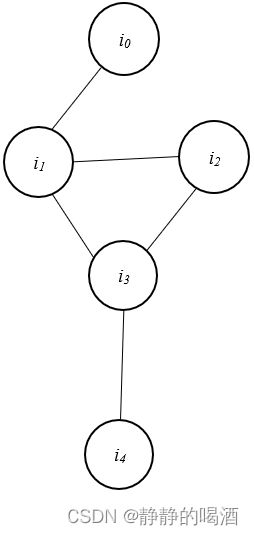
上图中一共包含 3 3 3个极大团,分别是:
例如极大团 { i 1 , i 2 , i 3 } \{i_1,i_2,i_3\} {i1,i2,i3},首先,该三个结点之间两两存在边相连,如果再加入一个结点 i 0 i_0 i0,由于 ( i 0 , i 2 ) , ( i 0 , i 3 ) (i_0,i_2),(i_0,i_3) (i0,i2),(i0,i3)之间不存在边相连,因此无法构成极大团。
x C 1 = { i 0 , i 1 } , x C 2 = { i 1 , i 2 , i 3 } , x C 3 = { i 3 , i 4 } x_{\mathcal C_1} = \{i_0,i_1\},x_{\mathcal C_2} = \{i_1,i_2,i_3\},x_{\mathcal C_3} = \{i_3,i_4\} xC1={i0,i1},xC2={i1,i2,i3},xC3={i3,i4}
而势函数(Potential Function)表示最大团内部结点之间的一种关系,通过这种关系描述马尔可夫随机场中结点的联合概率分布:
- 假设数据集合 X \mathcal X X中的 p p p个维度/特征划分为 K \mathcal K K个极大团:
注意,这里并没有说p p p个特征一定会出现p p p个结点,按照概率图中结点的定义,每个结点包含1个/多个特征。但这里,结点数量显然不是重点。
{ x C 1 , x C 2 , ⋯ , x C K } \{x_{\mathcal C_1},x_{\mathcal C_2},\cdots,x_{\mathcal C_{\mathcal K}}\} {xC1,xC2,⋯,xCK} - 联合概率分布 P ( X ) \mathcal P(\mathcal X) P(X)表示为:
P ( X ) = 1 Z ∏ i = 1 K ψ i ( x C i ) \mathcal P(\mathcal X) = \frac{1}{\mathcal Z} \prod_{i=1}^{\mathcal K} \psi_{i}(x_{\mathcal C_i}) P(X)=Z1i=1∏Kψi(xCi)
其中, ψ i ( x C i ) \psi_i(x_{\mathcal C_i}) ψi(xCi)表示极大团 x C i x_{\mathcal C_i} xCi的势函数,是一个 非负实函数;而 Z \mathcal Z Z表示规范化因子,具体表示如下:
Z = ∑ x 1 , ⋯ , x p ∏ i = 1 K ψ i ( x C i ) \mathcal Z = \sum_{x_1,\cdots,x_p} \prod_{i=1}^{\mathcal K} \psi_{i}(x_{\mathcal C_i}) Z=x1,⋯,xp∑i=1∏Kψi(xCi)
最大熵模型
最大熵模型的原理是:满足给定约束条件的模型集合中选取熵最大的模型。并且在最大熵原理与指数族分布的关系中通过推导确定了满足给定约束条件情况下,满足约束条件下熵最大的分布是指数族分布(Exponential Family of Distributions)。
最大熵模型本质上就是求解‘条件概率分布’的一种方式。
最大熵模型公式表示如下:
最大熵模型公式推导给大家推荐一篇~传送门
P ( Y ∣ X ) = 1 Z exp [ ∑ i = 1 N λ i f i ( X , Y ) ] \mathcal P(\mathcal Y \mid \mathcal X) = \frac{1}{\mathcal Z} \exp \left[\sum_{i=1}^N \lambda_if_i(\mathcal X,\mathcal Y)\right] P(Y∣X)=Z1exp[i=1∑Nλifi(X,Y)]
其中 f i ( X , Y ) f_i(\mathcal X,\mathcal Y) fi(X,Y)表示 特征函数(Feature Funtion), λ i \lambda_i λi表示需要学习的特征权值:
f i ( X , Y ) = { 1 X , Y → Satisfy facts 0 o t h e r w i s e f_i(\mathcal X,\mathcal Y) = \begin{cases} 1 \quad \mathcal X,\mathcal Y \to \text{ Satisfy facts} \\ 0 \quad otherwise \end{cases} fi(X,Y)={1X,Y→ Satisfy facts0otherwise
Z \mathcal Z Z表示归一化因子;
Z = ∑ Y exp [ ∑ i = 1 N λ i f i ( X , Y ) ] \mathcal Z = \sum_{\mathcal Y} \exp \left[\sum_{i=1}^N \lambda_if_i(\mathcal X,\mathcal Y)\right] Z=Y∑exp[i=1∑Nλifi(X,Y)]
条件随机场
在MEMM介绍过程中,提到了标注偏置问题(Label bias Problem)。其核心思想是:MEMM虽然引入了观测变量 O 1 : T \mathcal O_{1:T} O1:T的全局影响,但是当训练数据分布不均衡时,会导致内部概率分布相差很大,从而导致概率分布差异性对条件概率结果影响小,最终使状态转移结果与给定观测结果不匹配。
条件随机场的核心时将 最大熵马尔可夫模型中隐变量之间有向边的方向性抹除。从而有如下形式:
这是视频中的描述格式,但西瓜书中的描述格式,将观测变量到隐变量有向边的方向性也去掉了。见第二张图。
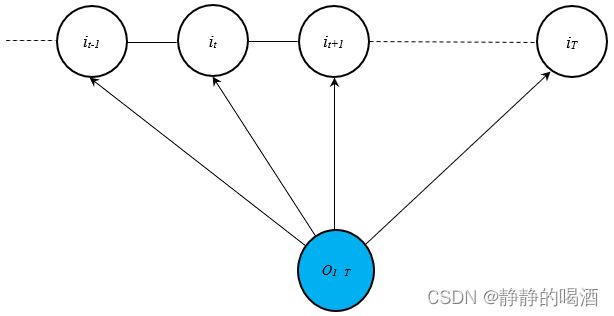
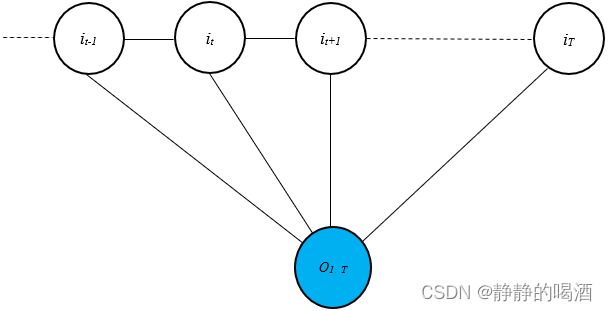
上述图表示的是最常用的链式条件随机场(Chain-Structured CRF),条件随机场中随机场的部分只是隐变量的部分,而观测变量部分 O 1 : T \mathcal O_{1:T} O1:T在概率图中仅表示条件的概念。
条件随机场的合理性
条件随机场的合理性体现在两方面:
- 条件随机场是 概率判别模型,它针对 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)进行建模。
- 条件随机场是一个无向图/马尔可夫随机场。
由于是无向图,因此 无法直接使用因子分解直接写出 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)。这里使用势函数和图结构中的团来定义 条件概率/概率密度函数 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O):
这里针对‘链式条件随机场’进行推导。
-
假设整个概率图模型中一共包含 K \mathcal K K个极大团:
从马尔可夫随机场的角度理解,它求解的并不是条件概率分布P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O),而是基于‘马尔可夫随机场’中隐变量I \mathcal I I的联合概率分布。
P ( I ∣ O ) = 1 Z ∏ k = 1 K ψ k ( i C k ) \mathcal P(\mathcal I \mid \mathcal O) = \frac{1}{\mathcal Z} \prod_{k=1}^{\mathcal K} \psi_{k}(i_{\mathcal C_k}) P(I∣O)=Z1k=1∏Kψk(iCk) -
其中 i C k i_{\mathcal C_k} iCk表示编号为 k k k的极大团。由于 ψ k ( i C k ) \psi_k(i_{\mathcal C_k}) ψk(iCk)是非负实函数,因此将上式修改为:
P ( I ∣ O ) = 1 Z ∏ k = 1 K exp [ − E k ( i C k ) ] \mathcal P(\mathcal I \mid \mathcal O) = \frac{1}{\mathcal Z} \prod_{k=1}^{\mathcal K} \exp [-\mathbb E_{k}(i_{\mathcal C_k})] P(I∣O)=Z1k=1∏Kexp[−Ek(iCk)]
其中 − E k ( i C k ) -\mathbb E_{k}(i_{\mathcal C_k}) −Ek(iCk)称为能量函数,继续展开,将 exp \exp exp和 ∏ \prod ∏调换位置,有:
能量函数在‘马尔可夫随机场’中并没有扩展介绍。依然是在介绍玻尔兹曼机时再去介绍能量函数。这里仅将其视作一个函数即可。这里将− E k ( i C k ) -\mathbb E_{k}(i_{\mathcal C_k}) −Ek(iCk)替换为f k ( i C k ) f_k(i_{\mathcal C_k}) fk(iCk),只是换了一个函数表示。
P ( I ∣ O ) = 1 Z exp ∑ k = 1 K f k ( i C k ) \mathcal P(\mathcal I \mid \mathcal O) = \frac{1}{\mathcal Z} \exp \sum_{k=1}^{\mathcal K} f_{k}(i_{\mathcal C_k}) P(I∣O)=Z1expk=1∑Kfk(iCk)
观察这个链式的马尔可夫随机场,由于链式结构,其最大团只能是两个隐变量结点组成的团结构,因此将最大团数量 K \mathcal K K使用时刻 T T T进行表示( O \mathcal O O表示观测变量输入):
个人认为有争议的点:如果将O \mathcal O O也算作马尔可夫随机场的结点,也就是‘西瓜书’中描述的马尔可夫随机场,那么最开始的‘极大团’中必然含O \mathcal O O,那求解的就不是P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O),而是P ( I , O ) \mathcal P(\mathcal I,\mathcal O) P(I,O)。如果O \mathcal O O不算作马尔可夫随机场的结点,也就是‘视频’中描述的马尔可夫随机场,那么f k ( i C k ) → f t ( i t , i t + 1 , O ) f_k(i_{\mathcal C_k}) \to f_t(i_{t},i_{t+1},\mathcal O) fk(iCk)→ft(it,it+1,O)这种写法是将O \mathcal O O直接强行加入。因为O \mathcal O O确实不是‘极大团’i C k i_{\mathcal C_k} iCk中的元素。
个人比较倾向于第二种解释,因为f t ( i t , i t + 1 , O ) f_t(i_{t},i_{t+1},\mathcal O) ft(it,it+1,O)可能已经描述的不是概率分布,而是一种关联关系。这里将O \mathcal O O视作‘观测变量输入’即可。
为了方便下面公式的表达,这里假设存在一个i T + 1 i_{T+1} iT+1结点满足下面公式,并将其消去。
P ( I ∣ O ) = 1 Z exp ∑ t = 1 T f t ( i t , i t + 1 , O ) = 1 Z exp [ ∑ t = 1 T − 1 f t ( i t , i t + 1 , O ) + f T ( i T , O ) ] \begin{aligned} \mathcal P(\mathcal I \mid \mathcal O) & = \frac{1}{\mathcal Z} \exp \sum_{t=1}^{T} f_t(i_{t},i_{t+1},\mathcal O) \\ & = \frac{1}{\mathcal Z} \exp \left[\sum_{t=1}^{T-1}f_{t}(i_t,i_{t+1},\mathcal O) + f_{T}(i_T,\mathcal O)\right] \end{aligned} P(I∣O)=Z1expt=1∑Tft(it,it+1,O)=Z1exp[t=1∑T−1ft(it,it+1,O)+fT(iT,O)]
上述公式中 t t t既表示特征函数的下标,也表示隐变量的下标。由于链式结构,所有的特征函数针对的极大团格式均相同(见红色椭圆部分):
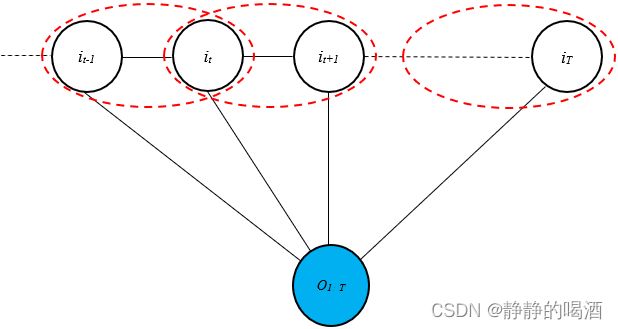
因此,将特征函数的下标 t t t消除:
即所有极大团均使用‘同一款特征函数’表示极大团结构。
P ( I ∣ O ) = 1 Z exp [ ∑ t = 1 T − 1 f ( i t , i t + 1 , O ) + f ( i T , O ) ] \mathcal P(\mathcal I \mid \mathcal O) = \frac{1}{\mathcal Z} \exp \left[\sum_{t=1}^{T-1}f(i_t,i_{t+1},\mathcal O) + f(i_T,\mathcal O)\right] P(I∣O)=Z1exp[t=1∑T−1f(it,it+1,O)+f(iT,O)]
观察连加号中的项: f ( i t , i t + 1 , O ) f(i_t,i_{t+1},\mathcal O) f(it,it+1,O),将其划分成两个部分:- 关于单个结点与观测变量的函数:假设存在 L \mathcal L L个项,定义其函数为 g l ( l = 1 , 2 , ⋯ , L ) g_l(l=1,2,\cdots,\mathcal L) gl(l=1,2,⋯,L),并给对应函数分配学习函数 η l ( l = 1 , 2 , ⋯ , L ) \eta_{l}(l=1,2,\cdots,\mathcal L) ηl(l=1,2,⋯,L),其结果表示如下:
∑ l = 1 L η l ⋅ g l ( i t , O ) \sum_{l=1}^{\mathcal L} \eta_l \cdot g_l(i_t,\mathcal O) l=1∑Lηl⋅gl(it,O) - 关于相邻结点与观测变量的函数:假设存在 M \mathcal M M个项,定义其函数为 s m ( m = 1 , 2 , ⋯ , M ) s_{m}(m=1,2,\cdots,\mathcal M) sm(m=1,2,⋯,M),并给对应函数分配学习函数 λ m ( m = 1 , 2 , ⋯ , M ) \lambda_m(m=1,2,\cdots,\mathcal M) λm(m=1,2,⋯,M),其结果表示如下:
∑ m = 1 M λ m ⋅ s m ( i t + 1 , i t , O ) \sum_{m=1}^{\mathcal M} \lambda_m \cdot s_m(i_{t+1},i_t,\mathcal O) m=1∑Mλm⋅sm(it+1,it,O)
至此, P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)表示如下:
最后一项f ( i T , O ) f(i_T,\mathcal O) f(iT,O)同样是‘关于单个结点与观测变量的函数’,因此也将其展开。
P ( I ∣ O ) = 1 Z exp [ ∑ t = 1 T − 1 f ( i t , i t + 1 , O ) + f ( i T , O ) ] = 1 Z exp { ∑ t = 1 T − 1 [ ∑ l = 1 L η l ⋅ g l ( i t , O ) + ∑ m = 1 M λ m ⋅ s m ( i t + 1 , i t , O ) ] + ∑ l = 1 L η l ⋅ g l ( i T , O ) } \begin{aligned} \mathcal P(\mathcal I \mid \mathcal O) & = \frac{1}{\mathcal Z} \exp \left[\sum_{t=1}^{T-1}f(i_t,i_{t+1},\mathcal O) + f(i_T,\mathcal O)\right]\\ & = \frac{1}{\mathcal Z} \exp \left\{\sum_{t=1}^{T-1}\left[\sum_{l=1}^{\mathcal L}\eta_l \cdot g_l(i_t,\mathcal O) + \sum_{m=1}^{\mathcal M} \lambda_m \cdot s_m(i_{t+1},i_t,\mathcal O)\right] + \sum_{l=1}^{\mathcal L} \eta_l \cdot g_l(i_T,\mathcal O)\right\} \\ \end{aligned} P(I∣O)=Z1exp[t=1∑T−1f(it,it+1,O)+f(iT,O)]=Z1exp{t=1∑T−1[l=1∑Lηl⋅gl(it,O)+m=1∑Mλm⋅sm(it+1,it,O)]+l=1∑Lηl⋅gl(iT,O)}
继续展开,并将 f ( i T , O ) f(i_T,\mathcal O) f(iT,O)项合并,最终得到结果如下:
P ( I ∣ O ) = 1 Z exp [ ∑ t = 1 T − 1 ∑ m = 1 M λ m ⋅ s m ( i t + 1 , i t , O ) + ∑ t = 1 T ∑ l = 1 L η l ⋅ g l ( i t , O ) ] \mathcal P(\mathcal I \mid \mathcal O) = \frac{1}{\mathcal Z}\exp \left[\sum_{t=1}^{T-1} \sum_{m=1}^{\mathcal M }\lambda_m \cdot s_{m}(i_{t+1},i_t,\mathcal O) + \sum_{t=1}^{T}\sum_{l=1}^{\mathcal L}\eta_l \cdot g_l(i_t,\mathcal O)\right] P(I∣O)=Z1exp[t=1∑T−1m=1∑Mλm⋅sm(it+1,it,O)+t=1∑Tl=1∑Lηl⋅gl(it,O)]
称 s m s_m sm为转移特征函数(Transition Feature Function),称 g l g_l gl为状态特征函数(State Feature Function),其中 λ m , η l \lambda_m,\eta_l λm,ηl是对应需要学习的模型参数。
个人理解:条件随机场PDF的表示形式
关于上述公式的替换过程,其替换结果已经非常接近最大熵模型对于 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)的表达形式。从本质上观察,其就是使用最大熵模型对极大团的势函数进行描述。针对链式条件随机场,任意一个时刻 t t t的极大团表示如下:
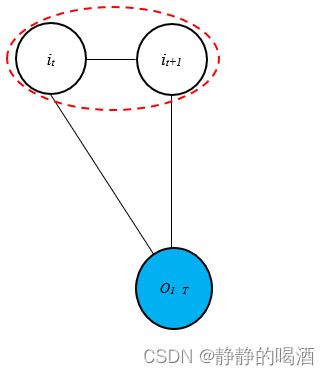
该极大团的势函数大致表示如下:
1 Z ψ t ( i C t ) = 1 Z exp f t ( i t , i t + 1 , O ) = 1 Z exp [ ∑ l = 1 L η l ⋅ g l ( i t , O ) + ∑ m = 1 M λ m ⋅ s m ( i t + 1 , i t , O ) ] = 1 Z exp [ ∑ l = 1 L η l ⋅ g l ( i t , O ) ] ⋅ exp [ ∑ m = 1 M λ m ⋅ s m ( i t + 1 , i t , O ) ] \begin{aligned} \frac{1}{\mathcal Z}\psi_{t}(i_{\mathcal C_t}) & = \frac{1}{\mathcal Z}\exp f_t(i_t,i_{t+1},\mathcal O) \\ & = \frac{1}{\mathcal Z} \exp \left[\sum_{l=1}^{\mathcal L}\eta_l \cdot g_l(i_t,\mathcal O) + \sum_{m=1}^{\mathcal M} \lambda_m \cdot s_m(i_{t+1},i_t,\mathcal O)\right] \\ & = \frac{1}{\mathcal Z} \exp \left[\sum_{l=1}^{\mathcal L}\eta_l \cdot g_l(i_t,\mathcal O)\right] \cdot \exp \left[\sum_{m=1}^{\mathcal M} \lambda_m \cdot s_m(i_{t+1},i_t,\mathcal O)\right] \end{aligned} Z1ψt(iCt)=Z1expft(it,it+1,O)=Z1exp[l=1∑Lηl⋅gl(it,O)+m=1∑Mλm⋅sm(it+1,it,O)]=Z1exp[l=1∑Lηl⋅gl(it,O)]⋅exp[m=1∑Mλm⋅sm(it+1,it,O)]
对比最大熵马尔可夫模型使用最大熵模型求解 P ( i t ∣ i t − 1 , O ) \mathcal P(i_t \mid i_{t-1},\mathcal O) P(it∣it−1,O)基本相同:
P ( i t ∣ i t − 1 , O ) = 1 Z exp [ ∑ a λ a f a ( i t , i t − 1 , O ) ] \mathcal P(i_t \mid i_{t-1},\mathcal O) = \frac{1}{\mathcal Z} \exp \left[\sum_a\lambda_a f_a(i_t,i_{t-1},\mathcal O)\right] P(it∣it−1,O)=Z1exp[a∑λafa(it,it−1,O)]
基于上述描述,由于链式条件随机场极大团形状的特殊性,我们可以将 ψ t ( i C t ) \psi_t(i_{\mathcal C_t}) ψt(iCt)看成两步操作:
- 通过状态特征函数,可以近似求解给定观测变量 O \mathcal O O的条件下, i t i_t it的条件概率 G ( i t ∣ O ) \mathcal G(i_t \mid \mathcal O) G(it∣O):
G ( i t ∣ O ) → exp [ ∑ l = 1 L η l ⋅ g l ( i t , O ) ] \mathcal G(i_t \mid \mathcal O) \to \exp \left[\sum_{l=1}^{\mathcal L}\eta_l \cdot g_l(i_t,\mathcal O)\right] G(it∣O)→exp[l=1∑Lηl⋅gl(it,O)] - 通过转移特征函数,可以近似求解给定观测变量 O \mathcal O O和隐变量 i t i_t it的条件下, i t + 1 i_{t+1} it+1的条件概率 Q ( i t + 1 ∣ i t , O ) \mathcal Q(i_{t+1} \mid i_t,\mathcal O) Q(it+1∣it,O):
Q ( i t + 1 ∣ i t , O ) → exp [ ∑ m = 1 M λ m ⋅ s m ( i t + 1 , i t , O ) ] \mathcal Q(i_{t+1} \mid i_t,\mathcal O) \to \ \exp \left[\sum_{m=1}^{\mathcal M} \lambda_m \cdot s_m(i_{t+1},i_t,\mathcal O)\right] Q(it+1∣it,O)→ exp[m=1∑Mλm⋅sm(it+1,it,O)] - 最终通过 条件概率公式将两项结合,描述出该极大团中隐变量的条件分布:
P ( i t , i t + 1 ∣ O ) = G ( i t ∣ O ) ⋅ Q ( i t + 1 ∣ i t , O ) \mathcal P(i_t,i_{t+1} \mid \mathcal O) = \mathcal G(i_t \mid \mathcal O) \cdot \mathcal Q(i_{t+1} \mid i_t,\mathcal O) P(it,it+1∣O)=G(it∣O)⋅Q(it+1∣it,O)
将所有极大团串联在一起,最终得到关于隐变量的条件概率密度函数 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)。
向量角度描述条件概率(2022/11/13)
状态转移过程逻辑解释
继续观察线性条件随机场的条件概率表示 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O):
P ( I ∣ O ) = 1 Z exp [ ∑ t = 1 T − 1 ∑ m = 1 M λ m ⋅ s m ( i t + 1 , i t , O ) + ∑ t = 1 T ∑ l = 1 L η l ⋅ g l ( i t , O ) ] \mathcal P(\mathcal I \mid \mathcal O) = \frac{1}{\mathcal Z}\exp \left[\sum_{t=1}^{T-1} \sum_{m=1}^{\mathcal M }\lambda_m \cdot s_{m}(i_{t+1},i_t,\mathcal O) + \sum_{t=1}^{T}\sum_{l=1}^{\mathcal L}\eta_l \cdot g_l(i_t,\mathcal O)\right] P(I∣O)=Z1exp[t=1∑T−1m=1∑Mλm⋅sm(it+1,it,O)+t=1∑Tl=1∑Lηl⋅gl(it,O)]
假设隐变量 i t ( t = 1 , 2 , ⋯ , T ) i_t(t = 1,2,\cdots,T) it(t=1,2,⋯,T)是 离散型随机变量:
i t ∈ S = { s 1 , s 2 , ⋯ , s ∣ S ∣ } i_t \in \mathcal S = \{s_1,s_2,\cdots,s_{|\mathcal S|}\} it∈S={s1,s2,⋯,s∣S∣}
其中 ∣ S ∣ |\mathcal S| ∣S∣表示可选离散集合中可选的元素数量。而上式中 M \mathcal M M表示隐状态 i t i_t it向 i t + 1 i_{t+1} it+1转移过程中可能性的数量。根据 ∣ S ∣ |\mathcal S| ∣S∣的描述,必然有:
例如: i t = s 1 → i t + 1 = s 1 i_t = s_1 \to i_{t+1} = s_1 it=s1→it+1=s1,以此类推。
M ≤ ∣ S ∣ 2 \mathcal M \leq |\mathcal S|^2 M≤∣S∣2
而这些排列组合,对应的转移特征函数 s m ( i t + 1 , i t , O ) s_m(i_{t+1},i_t,\mathcal O) sm(it+1,it,O)集合仅包含 两种结果: 0 , 1 0,1 0,1。根据上述特征函数的定义,结果为 1 1 1的状态转移过程是满足既定事实的,但即便这些组合满足条件,同样存在区分,而这些区分由模型参数 λ m \lambda_m λm决定。
条件概率的简化过程
场景设计
实际上, P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)中 I , O \mathcal I,\mathcal O I,O分别以关于隐变量与观测变量的向量形式出现:
I = ( i 1 i 2 ⋮ i T ) , O = ( o 1 o 2 ⋮ o T ) \mathcal I = \begin{pmatrix}i_1\\ i_2 \\ \vdots \\i_T\end{pmatrix},\mathcal O = \begin{pmatrix}o_1 \\o_2 \\ \vdots \\ o_T\end{pmatrix} I=⎝⎜⎜⎜⎛i1i2⋮iT⎠⎟⎟⎟⎞,O=⎝⎜⎜⎜⎛o1o2⋮oT⎠⎟⎟⎟⎞
在条件随机场——背景介绍提到的最大熵模型中,归一化因子 Z \mathcal Z Z是一个关于条件部分的函数。从上述的条件概率描述来看, Z \mathcal Z Z同样和模型参数存在关系:
注意:归一化函数 Z \mathcal Z Z本身就是对后验 I \mathcal I I进行归一化/积分,因此, Z \mathcal Z Z和 I \mathcal I I无关。
因此,引入模型参数向量 λ , η \lambda,\eta λ,η:
λ = ( λ 1 λ 2 ⋮ λ M ) M × 1 , η = ( η 1 η 2 ⋮ η L ) L × 1 \lambda = \begin{pmatrix}\lambda_1 \\ \lambda_2 \\ \vdots \\ \lambda_{\mathcal M}\end{pmatrix}_{\mathcal M \times 1},\eta = \begin{pmatrix}\eta_1 \\ \eta_2 \\ \vdots \\ \eta_{\mathcal L}\end{pmatrix}_{\mathcal L \times 1} λ=⎝⎜⎜⎜⎛λ1λ2⋮λM⎠⎟⎟⎟⎞M×1,η=⎝⎜⎜⎜⎛η1η2⋮ηL⎠⎟⎟⎟⎞L×1
于此同时,为了消除 ∑ m = 1 M , ∑ l = 1 L \sum_{m=1}^{\mathcal M},\sum_{l=1}^{\mathcal L} ∑m=1M,∑l=1L,并将其表示为向量的乘积形式,同样需要对 状态特征函数 g g g和转移特征函数 s s s 进行向量表示:
s ( i t + 1 , i t , O ) = ( s 1 ( i t + 1 , i t , O ) s 2 ( i t + 1 , i t , O ) ⋮ s M ( i t + 1 , i t , O ) ) M × 1 , g ( i t , O ) = ( g 1 ( i t , O ) g 2 ( i t , O ) ⋮ g L ( i t , O ) ) L × 1 s(i_{t+1},i_t,\mathcal O) = \begin{pmatrix}s_1(i_{t+1},i_t,\mathcal O) \\ s_2(i_{t+1},i_t,\mathcal O) \\ \vdots \\ s_{\mathcal M}(i_{t+1},i_t,\mathcal O)\end{pmatrix}_{\mathcal M \times 1}, g(i_t,\mathcal O) = \begin{pmatrix}g_1(i_t,\mathcal O) \\ g_2(i_t,\mathcal O) \\ \vdots \\ g_{\mathcal L}(i_t,\mathcal O)\end{pmatrix}_{\mathcal L \times 1} s(it+1,it,O)=⎝⎜⎜⎜⎛s1(it+1,it,O)s2(it+1,it,O)⋮sM(it+1,it,O)⎠⎟⎟⎟⎞M×1,g(it,O)=⎝⎜⎜⎜⎛g1(it,O)g2(it,O)⋮gL(it,O)⎠⎟⎟⎟⎞L×1
简化过程
-
在定义完上述向量后,对建模对象 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)进行如下简化:
将∑ m = 1 M , ∑ l = 1 L \sum_{m=1}^{\mathcal M},\sum_{l=1}^{\mathcal L} ∑m=1M,∑l=1L用‘向量乘积’的方式表示。
P ( I ∣ O ) = 1 Z ( O , λ , η ) exp [ ∑ t = 1 T − 1 λ T s ( i t + 1 , i t , O ) + ∑ t = 1 T η T g ( i t , O ) ] \mathcal P(\mathcal I \mid \mathcal O) = \frac{1}{\mathcal Z(\mathcal O,\lambda,\eta)} \exp \left[\sum_{t=1}^{T-1} \lambda^{T}s(i_{t+1},i_t,\mathcal O) + \sum_{t=1}^{T} \eta^{T}g(i_t,\mathcal O)\right] P(I∣O)=Z(O,λ,η)1exp[t=1∑T−1λTs(it+1,it,O)+t=1∑TηTg(it,O)] -
继续观察中括号中的项,以第一项 ∑ t = 1 T − 1 λ T s ( i t + 1 , i t , O ) \sum_{t=1}^{T-1}\lambda^{T}s(i_{t+1},i_t,\mathcal O) ∑t=1T−1λTs(it+1,it,O)为例,假设将其展开,可能会得到如下形式:
注意:不要将λ T \lambda^T λT中的'转置'T T T与表示时间/序列的T T T搞混~
∑ t = 1 T − 1 λ T s ( i t + 1 , i t , O ) = λ T s ( i 2 , i 1 , O ) + λ T s ( i 3 , i 2 , O ) + ⋯ + λ T s ( i T , i T − 1 , O ) = λ T [ s ( i 2 , i 1 , O ) + s ( i 3 , i 2 , O ) + ⋯ + s ( i T , i T − 1 , O ) ] = λ T ∑ t = 1 T − 1 s ( i t + 1 , i t , O ) \begin{aligned} \sum_{t=1}^{T-1}\lambda^{T}s(i_{t+1},i_t,\mathcal O) & = \lambda^{T}s(i_2,i_1,\mathcal O) + \lambda^Ts(i_3,i_2,\mathcal O) + \cdots + \lambda^Ts(i_{T},i_{T-1},\mathcal O) \\ & = \lambda^T \left[s(i_2,i_1,\mathcal O) + s(i_3,i_2,\mathcal O) + \cdots + s(i_T,i_{T-1},\mathcal O) \right] \\ & = \lambda^T\sum_{t=1}^{T-1} s(i_{t+1},i_t,\mathcal O) \end{aligned} t=1∑T−1λTs(it+1,it,O)=λTs(i2,i1,O)+λTs(i3,i2,O)+⋯+λTs(iT,iT−1,O)=λT[s(i2,i1,O)+s(i3,i2,O)+⋯+s(iT,iT−1,O)]=λTt=1∑T−1s(it+1,it,O)
同理, ∑ t = 1 T η T g ( i t , O ) \sum_{t=1}^T \eta^Tg(i_t,\mathcal O) ∑t=1TηTg(it,O)也可以写成如下形式:
∑ t = 1 T η T g ( i t , O ) = η T ∑ t = 1 T g ( i t , O ) \sum_{t=1}^T \eta^Tg(i_t,\mathcal O) = \eta^T \sum_{t=1}^{T}g(i_t,\mathcal O) t=1∑TηTg(it,O)=ηTt=1∑Tg(it,O)
此时, P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)可化简为如下形式:
P ( I ∣ O ) = 1 Z ( O , λ , η ) exp [ λ T ∑ t = 1 T − 1 s ( i t + 1 , i t , O ) + η T ∑ t = 1 T g ( i t , O ) ] \mathcal P(\mathcal I \mid \mathcal O) = \frac{1}{\mathcal Z(\mathcal O,\lambda,\eta)} \exp \left[\lambda^T\sum_{t=1}^{T-1} s(i_{t+1},i_t,\mathcal O) + \eta^T \sum_{t=1}^{T}g(i_t,\mathcal O)\right] P(I∣O)=Z(O,λ,η)1exp[λTt=1∑T−1s(it+1,it,O)+ηTt=1∑Tg(it,O)] -
继续观察中括号内的项,这种两项相乘再相加 的形式,同样可以继续化简称向量乘积的形式:
定义 参数向量 θ \theta θ,特征矩阵 H ( i t + 1 , i t , O ) \mathcal H(i_{t+1},i_t,\mathcal O) H(it+1,it,O) 表示如下:
由于s ( i t + 1 , i t , O ) s(i_{t+1},i_t,\mathcal O) s(it+1,it,O)向量维度是M × 1 \mathcal M \times 1 M×1,因此∑ t = 1 T − 1 s ( i t + 1 , i t , O ) \sum_{t=1}^{T-1} s(i_{t+1},i_t,\mathcal O) ∑t=1T−1s(it+1,it,O)的向量维度也是M × 1 \mathcal M \times 1 M×1(向量对应元素相加)。同理,∑ t = 1 T g ( i t , O ) \sum_{t=1}^{T}g(i_t,\mathcal O) ∑t=1Tg(it,O)的向量维度是L × 1 \mathcal L \times 1 L×1.
θ = ( λ η ) = ( λ 1 ⋮ λ M η 1 ⋮ η L ) ( M + L ) × 1 H ( i t + 1 , i t , O ) = ( ∑ t = 1 T − 1 s ( i t + 1 , i t , O ) ∑ t = 1 T g ( i t , O ) ) ( M + L ) × 1 \theta = \begin{pmatrix}\lambda \\ \eta\end{pmatrix} = \begin{pmatrix}\lambda_1\\ \vdots \\ \lambda_{\mathcal M} \\ \eta_1 \\ \vdots \\ \eta_{\mathcal L}\end{pmatrix}_{(\mathcal M + \mathcal L) \times 1} \mathcal H(i_{t+1},i_t,\mathcal O) = \begin{pmatrix} \sum_{t=1}^{T-1} s(i_{t+1},i_t,\mathcal O) \\ \quad \\ \sum_{t=1}^{T}g(i_t,\mathcal O) \end{pmatrix}_{(\mathcal M +\mathcal L) \times 1} θ=(λη)=⎝⎜⎜⎜⎜⎜⎜⎜⎜⎛λ1⋮λMη1⋮ηL⎠⎟⎟⎟⎟⎟⎟⎟⎟⎞(M+L)×1H(it+1,it,O)=⎝⎛∑t=1T−1s(it+1,it,O)∑t=1Tg(it,O)⎠⎞(M+L)×1
至此,将条件概率 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)化简称如下向量乘积形式:
P ( I ∣ O ) = 1 Z ( O , θ ) exp [ θ T ⋅ H ( i t + 1 , i t , O ) ] = 1 Z ( O , θ ) exp ⟨ θ , H ( i t + 1 , i t , O ) ⟩ \begin{aligned} \mathcal P(\mathcal I \mid \mathcal O) & = \frac{1}{\mathcal Z(\mathcal O,\theta)} \exp\left[\theta^T \cdot \mathcal H(i_{t+1},i_t,\mathcal O)\right] \\ & = \frac{1}{\mathcal Z(\mathcal O,\theta)} \exp \left\langle \theta,\mathcal H(i_{t+1},i_t,\mathcal O)\right\rangle \end{aligned} P(I∣O)=Z(O,θ)1exp[θT⋅H(it+1,it,O)]=Z(O,θ)1exp⟨θ,H(it+1,it,O)⟩
后续将使用 P ( I ∣ O ) \mathcal P(\mathcal I \mid \mathcal O) P(I∣O)的向量表示处理 学习以及推断任务。
相关参考:
最大熵模型(maximum entropy model)
(系列十七)条件随机场4-概率密度函数的参数形式
机器学习-条件随机场(5)-CRF模型-概率密度函数的向量形式
机器学习-周志华著