Word2Vec之CBOW&Skip-gram
我们之前介绍过分布假设,主要是通过上下文来构造一个共现矩阵 ,度量词的相似性或关联性可以在共现矩阵的基础上采用余弦相似度、Jaccard相似度、点互信息等,为了避免低频技术在统计上的不可靠性,可以对共现矩阵胡必须把矩阵奇异分解,获得矩阵更鲁棒的低阶表示后,在分解后的低阶矩阵上进行了词的表示与计算。
,度量词的相似性或关联性可以在共现矩阵的基础上采用余弦相似度、Jaccard相似度、点互信息等,为了避免低频技术在统计上的不可靠性,可以对共现矩阵胡必须把矩阵奇异分解,获得矩阵更鲁棒的低阶表示后,在分解后的低阶矩阵上进行了词的表示与计算。
分布式表示则是将每个词映射到低维空间中的连续向量,每个维度有着不明确的含义,而词的含义由其向量表示及与其他词的空间关系决定。
Word2Vec
词向量已成为基于神经网络的自然语言处理方法的一个重要组成部分,在词向量的表示方法中,每个词被标示为一个低维向量空间(一般100~1000维)中的稠密空间使得近义词的空间表示也相近。
Word2Vec算法包含训练词向量的两种模型CBOW和Skip-gram。前者的思想是利用上下文多个词预测一个词,后者的思想上是利用每一个词独立的预测上下文,二者大同小异
CBOW模型首先将上下文中所有词的向量相加,然后直接和输出词的向量计算内积,再归一化到概率分布上。模型的参数由两个词向量矩阵构成——词输出向量矩阵和词输入向量矩阵,仍然利用最大似然估计准则进行优化。这种做法较前馈神经网络而言利用更简单的模型更适用于大规模的数据和大词表。
Skip-gram模型相比前者拥有更强的独立性假设,即上下文的每个词也可以独立地被预测,模型表示如下:
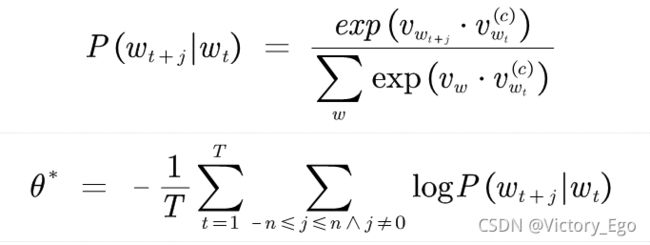
其中![]() 表示
表示![]() 的词向量,
的词向量,![]() 表示词
表示词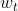 的上下文词向量。
的上下文词向量。
和语言模型相比,二者的优化目标一样但最终目的不同。语言模型利用参数化模型估计条件概率从而预测下一个词;词向量模型通过条件概率获得词向量矩阵。
虽然模型更为简单,效率更高但预测能力也差了很多。下面介绍两种优化计算代价的方法。
1.词向量模型训练优化:负采样
负采样方法将条件概率的估计问题转换为一个二分类问题,若词w和上下文c匹配正确B=1,反之B=0。模型如下:
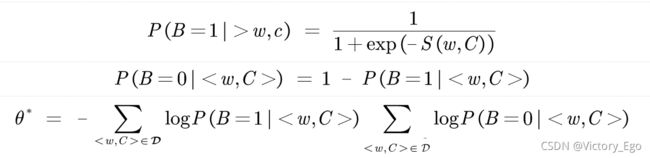
通过利用sigmoid函数来替代softmax从而避免计算归一化因子。
2.词向量模型训练优化:层次化softmax
主要思路是将softmax中归一化因子的计算转换为一系列的二分类问题,首先将词表中的所有单词表示在一颗二叉树上,每个单词出现在树的叶子节点上,对应唯一的二进制编码。为了使整体代价最优可使用Huffman编码。

下附Skip-gram代码加注释:
# code by Tae Hwan Jung @graykode
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
def random_batch():
random_inputs = []
random_labels = []
random_index = np.random.choice(range(len(skip_grams)), batch_size, replace=False)#随机选择预测键对,每次预测两个
for i in random_index:
random_inputs.append(np.eye(voc_size)[skip_grams[i][0]]) # target
random_labels.append(skip_grams[i][1]) # context word
return random_inputs, random_labels
# Model
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
# W and WT is not Traspose relationship
self.W = nn.Linear(voc_size, embedding_size, bias=False) # voc_size > embedding_size Weight 将独热表示值映射到二维平面上一个点
self.WT = nn.Linear(embedding_size, voc_size, bias=False) # embedding_size > voc_size Weight 再将二维平面点映射到一个词表大小的向量上作为预测值
def forward(self, X):
# X : [batch_size, voc_size]
hidden_layer = self.W(X) # hidden_layer : [batch_size, embedding_size]
output_layer = self.WT(hidden_layer) # output_layer : [batch_size, voc_size]
return output_layer
if __name__ == '__main__':
batch_size = 2 # mini-batch size
embedding_size = 2 # embedding size
sentences = ["apple banana fruit", "banana orange fruit", "orange banana fruit",
"dog cat animal", "cat monkey animal", "monkey dog animal"]
word_sequence = " ".join(sentences).split()
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}
voc_size = len(word_list)
# Make skip gram of one size window
skip_grams = []
for i in range(1, len(word_sequence) - 1):
target = word_dict[word_sequence[i]]#构造键值对,选中间词作为预测目标,两边的词可以独立的作为上下文
context = [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]]
for w in context:
skip_grams.append([target, w])
model = Word2Vec()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Training
for epoch in range(5000):
input_batch, target_batch = random_batch()
input_batch = torch.Tensor(input_batch)
target_batch = torch.LongTensor(target_batch)#torch.Tensor默认是torch.FloatTensor是32位浮点类型数据,torch.LongTensor是64位整型
optimizer.zero_grad()
output = model(input_batch)
# output : [batch_size, voc_size], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))#因为是random出来所以并没有直观的loss下降
loss.backward()
optimizer.step()
for i, label in enumerate(word_list):
W, WT = model.parameters()
x, y = W[0][i].item(), W[1][i].item()
plt.scatter(x, y)#利用hidden层映射到二维平面上打印,更直观看出同类词距离更近
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
静态词向量可以反映满足一定传递关系的词向量(如哥哥姐姐、孙子孙女的关系是相似的仅有性别的区别),依赖于其运算的简单。
但这也同时带来了缺点,由于缺少语境,用一个单词在不同语境下尽管有不同的语义,仍有相同的向量。此外在反义词的处理上也有问题,互为反义词的词语在句子中替换的话语义仍通顺,这就导致了二者词向量距离可能很近。这也就引出了我们现在的语境化表示模型。