Python计算机视觉——图像检索与识别
目录
一、原理解析
1.1计算机视觉的图像分类是什么意思?
1.2图像分类如何实现?
1.3Bag of features算法和过程
1)提取图像特征
2)训练字典
3)图像直方图生成
4)训练分类器
1.4TF-IDF
二、实验过程
2.1代码分析
2.2实验过程
2.3实验结果
一、原理解析
1.1计算机视觉的图像分类是什么意思?
图像分类,即通过图像内容的不同将图像划分为不同的类别,
该技术二十世纪九十年代末提出,并命名为基于图像内容的图像分类(Content- Based ImageClassific- ation, CEIC)算法概念,
基于内容的图像分类技术不需要对图像的语义信息进行人工标注,
而是通过计算机提取图像中所包含的特征,并对特征进行处理和分析,得出分类结果。
常用的图像特征有 图像颜色、纹理、灰度等信息。而图像分类过程中,
提取的特征要求不容易受随机因素干扰,特征的有效提取可提高图像分类的精度。
特征提取完成后,选择合适的算法创建图像类型与视觉特征之间的关联度,对图像进行类别划分。
图像分类领域中,根据图像分类要求,一般可以分为 场景分类和 目标分类两类问题。
场景分类也可以称为事件分类,场景分类是对 整幅图像所代表的 整体信息进行分类,或者是对图像中 所发生事件的总体描述。
目标分类(又称为物体分类)是对图像中 出现的目标 (物体)进行识别或分类。
1.2图像分类如何实现?
视觉词袋模型( Bag-of-features )是当前计算机视觉领域中较为常用的图像表示方法。
视觉词袋模型来源于词袋模型(Bag-of-words),词袋模型最初被用在文本分类中,将文档表示成特征矢量。它的基本思想是假定 对于一个文本,忽略其词序和语法、句法, 仅仅将其看做是一些词汇的集合, 而文本中的每个词汇都是独立的。简单说就是讲每篇文档都看成一个袋子 (因为里面装的都是词汇,
所以称为词袋,Bag of words即因此而来)然后看这个袋子里装的都是些什么词汇,将其分类。
如果文档中猪、 马、牛、羊、山谷、土地、拖拉机这样的词汇多些,而银行、大厦、汽车、公园这样的词汇少些, 我们就倾向于判断它是一 篇描绘乡村的文档,而不是描述城镇的。
Bag of Feature也是借鉴了这种思路,只不过在图像中,我们抽出的不再是一个个word, 而是 图像的关键特征Feature,所以研究人员将它更名为Bag of Feature.Bag of Feature在检索中的算法流程和分类几乎完全一样,唯一的区别在于,对于原始的BOF特征,也就是直方图向量,我们引入TF_IDF权值。
图像分类问题是计算机视觉领域的基础问题,它的目的是根据图像的语义信息将不同类别图像区分开来,实现最小的分类误差。具体任务要求是从给定的分类集合中给图像分配一个标签的任务。总体来说,对于单标签的图像分类问题,它可以分为跨物种语义级别的图像分类,子类细粒度图像分类,以及实例级图像分类三大类别。因为VOC数据集是不同物种类别的数据集,所以本文主要研究讨论跨物种语义级别的图像分类任务。
通常图像分类任务存在以下技术难点:
(1)视角变化:同一个物体,摄像机可以从多个角度来展现。
(2)大小变化:物体可视的大小通常是会变化的。
(3)形变:很多东西的形状并非一成不变,会有很大变化。 (4)遮挡:目标物体可能被挡住。有时候只有物体的一小部分是可见的。
(5)光照条件:在像素层面上,光照的影响非常大。
(6)背景干扰:物体可能混入背景之中,使之难以被辨认。
(7)类内差异:一类物体的个体之间的外形差异很大,比如椅子。这一类物体有许多不同的对象,每个都有自己的外形
1.3Bag of features算法和过程
1)提取图像特征
特征提取及描述主要是将一些 具有代表性且 区分性较强的 全局或局部特征从图像中进行抽取,并对这些特征进行描述。
这些特征一般是类别之间差距比较 明显的特征,可以将其与其他类别区分开,其次,这些特征还要求具有 较好的稳定性,能够最大限度的在光照、视角、尺度、噪声以及各种外在因素变化的情况下保持稳定,不受其影响。这样即使在非常复杂的情况下,计算机也能通过这些稳定的特征很好的检测与识别出这个物体。
特征提取最简单且有效的方法就是 规则网格方法,
该方法采用均匀网格对图像进行划分,从而得到图像的局部区域特征。
兴趣点检测方法是另一个有效的特征提取方法,兴趣点检测的基本思想是:
在人为判断一幅图像的类别时,首先捕捉到物体的整体轮廓特征,然后聚焦于物体与其他物体具有显著特征区别的地方,最后判断出图像的类别。即通过该物体与其他物体 区别开的 显著特征,进而判断图像的类别。
在提取完图像的特征后,下一步就要应用特征描述子来对抽取的图像特征进行描述,特征描述子所表示的特征向量一般在处理算法时会作为输入数据,因此,如果描述子具有一定的判别性及可区分性,则该描述子会在后期的图像处理过程中起着很大的作用。
其中,SIFT描述子是近年比较经典且被广泛应用的一种描述子。
SIFT会从图片上提取出很多特征点,每个特征点都是128维的向量,因此,如果图片足够多的话,我们会提取出一个巨大的特征向量库。

2)训练字典
在上面提取完SIFT特征的步骤后,利用K-means聚类算法将提取的SIFT特征聚类生成视觉词典。
K-means算法是度量样本间相似性的一种方法,该算法设置参数为K,把N个对象分成K个簇,簇内之间的相似度较高,而簇间的相似度较低。聚类中心有K个,视觉词典为K。构建视觉单词的过程如图所示。
3)图像直方图生成
利用视觉词典中的词汇表示待分类图像。计算每幅图像中的SIFT特征到这K个视觉单词的距离,
其中 距离最近的视觉单词为该SIFT特征对应的视觉单词。
通过统计每个单词在图像中出现的次数,将图像表示成一个K维数值向量,
如图所示,其中K=4,每幅图像用直方图进行描述。
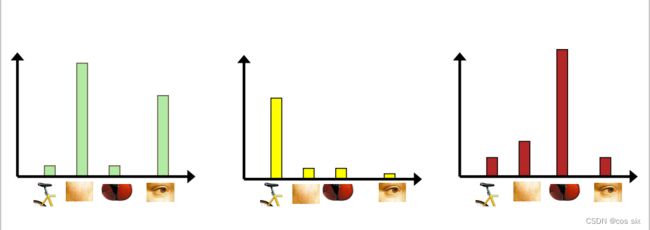
4)训练分类器
当我们得到每幅图片的直方图向量后,剩下的这一步跟以往的步骤是一样的。
无非是数据库图片的向量以及图片的标签,训练分类器模型。然后对需要预测的图片,我们仍然按照上述方法,提取SIFT特征,再根据字典量化直方图向量,用分类器模型对直方图向量进行分类。当然,也可以直接根据 KNN 算法对直方图向量做相似性判断
1.4TF-IDF
TF-IDF(Term frequency-Inverse document frequency)是一种统计方法,用来评估特征词的重要程度。根据TF-IDF公式,特征词的权重与在 语料库中出现的频率有关,也与在文档里出现的频率有关。传统的TF-IDF公式如下

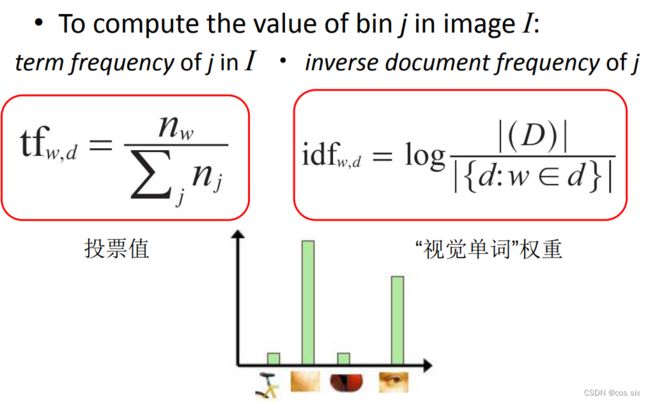
TF-IDF用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。就目前来说,如果一个 关键词只在很少的网页中出现,我们通过它就 容易锁定搜索目标,它的 权重也就应该 大。反之如果一个词在大量网页中出现,我们看到它仍然 不是很清楚要找什么内容,因此它应该 小。
二、实验过程
2.1代码分析
生成词汇表:
# -*- coding: utf-8 -*-
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
# 获取图像列表
imlist = get_imlist('test/')
nbr_images = len(imlist)
# 获取特征列表
featlist = [imlist[i][:-3] + 'sift' for i in range(nbr_images)]
# 提取文件夹下图像的sift特征
for i in range(nbr_images):
sift.process_image(imlist[i], featlist[i])
# 生成词汇
voc = vocabulary.Vocabulary('test77_test')
voc.train(featlist, 122, 10)
# 保存词汇
# saving vocabulary
'''with open('D:/Program Files (x86)/QQdate/BagOfFeature/BagOfFeature/BOW/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)'''
with open('C:/Users/86158/Desktop/计算机视觉实验/Bag Of Feature/BOW/vocabulary.pkl', 'wb') as f:
pickle.dump(voc, f)
print('vocabulary is:', voc.name, voc.nbr_words)
生成数据库:
import pickle
from PCV.imagesearch import vocabulary
from PCV.tools.imtools import get_imlist
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from sqlite3 import dbapi2 as sqlite # 使用sqlite作为数据库
#获取图像列表
imlist = get_imlist('test/')
nbr_images = len(imlist)
#获取特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
# load vocabulary
#载入词汇
with open('BOW/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
#创建索引
indx = imagesearch.Indexer('testImaAdd.db',voc) # 在Indexer这个类中创建表、索引,将图像数据写入数据库
indx.create_tables() # 创建表
# go through all images, project features on vocabulary and insert
#遍历所有的图像,并将它们的特征投影到词汇上
for i in range(nbr_images)[:888]:
locs,descr = sift.read_features_from_file(featlist[i])
indx.add_to_index(imlist[i],descr) # 使用add_to_index获取带有特征描述子的图像,投影到词汇上
# 将图像的单词直方图编码存储
# commit to database
#提交到数据库
indx.db_commit()
con = sqlite.connect('testImaAdd.db')
print (con.execute('select count (filename) from imlist').fetchone())
print (con.execute('select * from imlist').fetchone())
图像搜索:
# -*- coding: utf-8 -*-
#使用视觉单词表示图像时不包含图像特征的位置信息
import pickle
from PCV.localdescriptors import sift
from PCV.imagesearch import imagesearch
from PCV.geometry import homography
from PCV.tools.imtools import get_imlist
# load image list and vocabulary
#载入图像列表
imlist = get_imlist('test/')
nbr_images = len(imlist)
#载入特征列表
featlist = [imlist[i][:-3]+'sift' for i in range(nbr_images)]
#载入词汇
'''with open('E:/Python37_course/test7/first1000/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)'''
with open('BOW/vocabulary.pkl', 'rb') as f:
voc = pickle.load(f)
src = imagesearch.Searcher('testImaAdd.db',voc)# Searcher类读入图像的单词直方图执行查询
# index of query image and number of results to return
#查询图像索引和查询返回的图像数
q_ind = 0
nbr_results = 130
# regular query
# 常规查询(按欧式距离对结果排序)
res_reg = [w[1] for w in src.query(imlist[q_ind])[:nbr_results]] # 查询的结果
print ('top matches (regular):', res_reg)
# load image features for query image
#载入查询图像特征进行匹配
q_locs,q_descr = sift.read_features_from_file(featlist[q_ind])
fp = homography.make_homog(q_locs[:,:2].T)
# RANSAC model for homography fitting
#用单应性进行拟合建立RANSAC模型
model = homography.RansacModel()
rank = {}
# load image features for result
#载入候选图像的特征
for ndx in res_reg[1:]:
try:
locs,descr = sift.read_features_from_file(featlist[ndx])
except:
continue
#locs,descr = sift.read_features_from_file(featlist[ndx]) # because 'ndx' is a rowid of the DB that starts at 1
# get matches
matches = sift.match(q_descr,descr)
ind = matches.nonzero()[0]
ind2 = matches[ind]
tp = homography.make_homog(locs[:,:2].T)
# compute homography, count inliers. if not enough matches return empty list
# 计算单应性矩阵
try:
H,inliers = homography.H_from_ransac(fp[:,ind],tp[:,ind2],model,match_theshold=4)
except:
inliers = []
# store inlier count
rank[ndx] = len(inliers)
# sort dictionary to get the most inliers first
# 对字典进行排序,可以得到重排之后的查询结果
sorted_rank = sorted(rank.items(), key=lambda t: t[1], reverse=True)
res_geom = [res_reg[0]]+[s[0] for s in sorted_rank]
print ('top matches (homography):', res_geom)
# 显示查询结果
imagesearch.plot_results(src,res_reg[:6]) #常规查询
imagesearch.plot_results(src,res_geom[:6]) #重排后的结果
2.2实验过程
数据集:

测试集:

2.3实验结果


