kitti数据集转换成可运行的YOLOv5格式
如果想跳过步骤直接获取YOLOv5格式的kitti数据集评论获取阿里云盘提取码
我们再yolov5/dataset下创建文件夹kitti
再kiiti中放入我们的数据
数据集结构框架
|——kitti
├── imgages
│ ├── val
│ │ └── 000000.png
├── .......
│ └── train
│ │ └── 000000.png
├── .......
│
└── labels
└── train
注意此时先不要把标签数据放入,我们需要对标签转换一下
二、KITTI数据集转换
我们打开标签中的一个内容
比如000000.txt
Pedestrian 0.00 0 -0.20 712.40 143.00 810.73 307.92 1.89 0.48 1.20 1.84 1.47 8.41 0.01
这里是kitty独有的数据格式,不适用于我们的yolov5网络,所以我们得转换一下
首先我们把类别归一一下,因为我们只需要用到三个类(代码中的路径自行修改)
第一个脚本
# modify_annotations_txt.py
import glob
import string
txt_list = glob.glob('E:/datasets/yolov5-6.0/mydata/labels/train/*.txt') # 存储Labels文件夹所有txt文件路径 注意要保留/*
print(txt_list)
def show_category(txt_list):
category_list= []
for item in txt_list:
try:
with open(item) as tdf:
for each_line in tdf:
labeldata = each_line.strip().split(' ') # 去掉前后多余的字符并把其分开
category_list.append(labeldata[0]) # 只要第一个字段,即类别
except IOError as ioerr:
print('File error:'+str(ioerr))
print(set(category_list)) # 输出集合
def merge(line):
each_line=''
for i in range(len(line)):
if i!= (len(line)-1):
each_line=each_line+line[i]+' '
else:
each_line=each_line+line[i] # 最后一条字段后面不加空格
each_line=each_line+'\n'
return (each_line)
print('before modify categories are:\n')
show_category(txt_list)
for item in txt_list:
new_txt=[]
try:
with open(item, 'r') as r_tdf:
for each_line in r_tdf:
labeldata = each_line.strip().split(' ')
# if labeldata[0] in ['Truck','Van','Tram']: # 合并汽车类
# labeldata[0] = labeldata[0].replace(labeldata[0],'Car')
if labeldata[0] == 'Person_sitting': # 合并行人类
labeldata[0] = labeldata[0].replace(labeldata[0],'Pedestrian')
if labeldata[0] == 'DontCare': # 忽略Dontcare类
continue
if labeldata[0] == 'Misc': # 忽略Misc类
continue
new_txt.append(merge(labeldata)) # 重新写入新的txt文件
with open(item,'w+') as w_tdf: # w+是打开原文件将内容删除,另写新内容进去
for temp in new_txt:
w_tdf.write(temp)
except IOError as ioerr:
print('File error:'+str(ioerr))
print('\nafter modify categories are:\n')
show_category(txt_list)
然后我们再把它转换为xml文件
创建一个Annotations文件夹用于存放xml
第二个脚本
# kitti_txt_to_xml.py
# encoding:utf-8
# 根据一个给定的XML Schema,使用DOM树的形式从空白文件生成一个XML
from xml.dom.minidom import Document
import cv2
import glob
import os
def generate_xml(name,split_lines,img_size,class_ind):
doc = Document() # 创建DOM文档对象
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
title = doc.createElement('folder')
title_text = doc.createTextNode('KITTI')
title.appendChild(title_text)
annotation.appendChild(title)
img_name=name+'.jpg'
title = doc.createElement('filename')
title_text = doc.createTextNode(img_name)
title.appendChild(title_text)
annotation.appendChild(title)
source = doc.createElement('source')
annotation.appendChild(source)
title = doc.createElement('database')
title_text = doc.createTextNode('The KITTI Database')
title.appendChild(title_text)
source.appendChild(title)
title = doc.createElement('annotation')
title_text = doc.createTextNode('KITTI')
title.appendChild(title_text)
source.appendChild(title)
size = doc.createElement('size')
annotation.appendChild(size)
title = doc.createElement('width')
title_text = doc.createTextNode(str(img_size[1]))
title.appendChild(title_text)
size.appendChild(title)
title = doc.createElement('height')
title_text = doc.createTextNode(str(img_size[0]))
title.appendChild(title_text)
size.appendChild(title)
title = doc.createElement('depth')
title_text = doc.createTextNode(str(img_size[2]))
title.appendChild(title_text)
size.appendChild(title)
for split_line in split_lines:
line=split_line.strip().split()
if line[0] in class_ind:
object = doc.createElement('object')
annotation.appendChild(object)
title = doc.createElement('name')
title_text = doc.createTextNode(line[0])
title.appendChild(title_text)
object.appendChild(title)
bndbox = doc.createElement('bndbox')
object.appendChild(bndbox)
title = doc.createElement('xmin')
title_text = doc.createTextNode(str(int(float(line[4]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('ymin')
title_text = doc.createTextNode(str(int(float(line[5]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('xmax')
title_text = doc.createTextNode(str(int(float(line[6]))))
title.appendChild(title_text)
bndbox.appendChild(title)
title = doc.createElement('ymax')
title_text = doc.createTextNode(str(int(float(line[7]))))
title.appendChild(title_text)
bndbox.appendChild(title)
# 将DOM对象doc写入文件
f = open(r'D:\1\win10_yolov5_deepsort_counting-main\Annotations\labels\test\ '+name+'.xml','w')#xml要改这里
f.write(doc.toprettyxml(indent = ''))
f.close()
if __name__ == '__main__':
class_ind=('Pedestrian', 'Car', 'Cyclist')
cur_dir=os.getcwd()
labels_dir=os.path.join(cur_dir,r'D:\1\win10_yolov5_deepsort_counting-main\Annotations\labels\train') #要改这里
# labels_dir=os.path.join(cur_dir,'label_2')
for parent, dirnames, filenames in os.walk(labels_dir):# 分别得到根目录,子目录和根目录下文件
for file_name in filenames:
full_path=os.path.join(parent, file_name) # 获取文件全路径
f=open(full_path)
split_lines = f.readlines() #以行为单位读
name= file_name[:-4] # 后四位是扩展名.txt,只取前面的文件名
img_name=name+'.png'
img_path=os.path.join(r'D:\1\win10_yolov5_deepsort_counting-main\Annotations\images\train',img_name) # 路径需要自行修改 改这里
img_size=cv2.imread(img_path).shape
generate_xml(name,split_lines,img_size,class_ind)
print('txts has converted into xmls')
这个时候我们已经将.txt转化为.xml并存放在Annotations下了
最后我们再把.xml转化为适合于yolo训练的标签模式
也就是darknet的txt格式
例如:

第三个脚本
# xml_to_yolo_txt.py
# 此代码和VOC_KITTI文件夹同目录
import glob
import xml.etree.ElementTree as ET
# 这里的类名为我们xml里面的类名,顺序现在不需要考虑
class_names = ['Car', 'Cyclist', 'Pedestrian']
# xml文件路径
path = r'D:\1\win10_yolov5_deepsort_counting-main\Annotations\labels\test\ ' #要改这里
# 转换一个xml文件为txt
def single_xml_to_txt(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
# 保存的txt文件路径
txt_file = xml_file.split('.')[0]+'.'+xml_file.split('.')[1]+'.txt'
with open(txt_file, 'w') as txt_file:
for member in root.findall('object'):
#filename = root.find('filename').text
picture_width = int(root.find('size')[0].text)
picture_height = int(root.find('size')[1].text)
class_name = member[0].text
# 类名对应的index
class_num = class_names.index(class_name)
box_x_min = int(member[1][0].text) # 左上角横坐标
box_y_min = int(member[1][1].text) # 左上角纵坐标
box_x_max = int(member[1][2].text) # 右下角横坐标
box_y_max = int(member[1][3].text) # 右下角纵坐标
print(box_x_max,box_x_min,box_y_max,box_y_min)
# 转成相对位置和宽高
x_center = float(box_x_min + box_x_max) / (2 * picture_width)
y_center = float(box_y_min + box_y_max) / (2 * picture_height)
width = float(box_x_max - box_x_min) / picture_width
height = float(box_y_max - box_y_min) / picture_height
print(class_num, x_center, y_center, width, height)
txt_file.write(str(class_num) + ' ' + str(x_center) + ' ' + str(y_center) + ' ' + str(width) + ' ' + str(height) + '\n')
# 转换文件夹下的所有xml文件为txt
def dir_xml_to_txt(path):
for xml_file in glob.glob(path + '*.xml'):
single_xml_to_txt(xml_file)
dir_xml_to_txt(path)
最后我们将得到的Annotations/下的所有txt文件放入我们之前的dataset/labels中
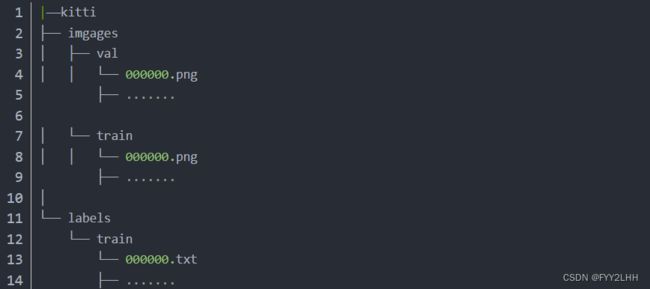
这样我们的数据集就准备好了
接下来我们可以训练了,你们可以先了解怎么训练yolov5的步骤,训练步骤数据集标注(在线标注,方便快捷)/YOLOV5自建数据集_FYY2LHH的博客-CSDN博客_数据集标注网站