什么是Python爬虫
Python爬虫,顾名思义是进行信息抓取的。现如今大数据时代,信息的获取是非常重要的,它甚至可以决定一个公司的发展方向和未来。如果将互联网比作一张大网,那么获取信息就需要在这张大网里面捞取,这种做法也被称作为搜索引擎,那么百度搜狗便是这种做法。
学习爬虫,首先得先培养爬虫的思想,比如网络上的文本,图片,视频等等,其实都是由“某个东西”保存起来的,然后通过网络返回给用户。
可能会有小伙伴对“某个东西”感到好奇,这里引用一个概念,叫做URL,可以将URL简单理解为找到“某个东西”所需要的路线,即大家平常所说的网址或链接。
URL:统一资源定位系统(uniform resource locator;URL)是因特网的万维网服务程序上用于指定信息位置的表示方法。URL也可以称为是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。URL是通用的资源定位符,URI同样也是资源定位符,由于URL包括URI,且URL适用范围广,所以URL就占了上风,爬虫是要有爬取的信息目标的,而目标就是URL包含的文件信息,这样就不难理解为什么爬虫一定要有确切的网址才能爬取到该文件了。
那么爬虫简单来说就是某个虫子顺着这个路线找到我们想要的东西,然后将其解析,提取出来。
那么如何找到URL呢,通常Chrome和火狐按F12可以进入开发者模式,然后找到Network,再在Name里面随便找个文件打开,如果没有刷新出文件,在原先的网页上刷新即可。点击某个文件,就可以看到下图中的Request URL,即该网址的初始URL,当然URL的加解密也会导致URL的不同,这就要靠以后去学啦。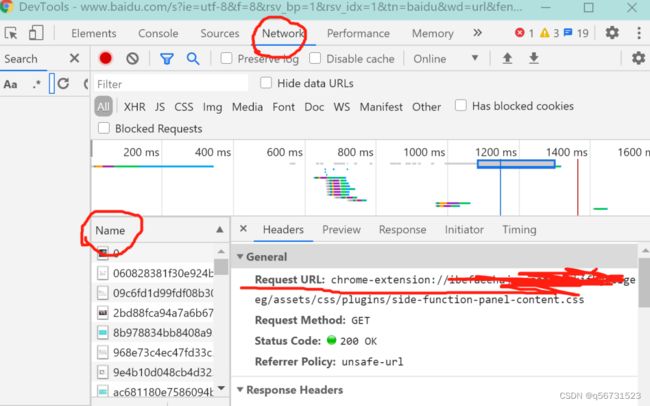
爬虫的基本流程
1、发起请求
通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,然后等待服务器响应。这个请求的过程就像我们打开浏览器,在浏览器地址栏输入网址:www.baidu.com,然后点击回车。这个过程其实就相当于浏览器作为一个浏览的客户端,向服务器端发送了 一次请求。
2、获取响应内容
如果服务器能正常响应,我们会得到一个Response,Response的内容便是所要获取的内容,类型可能有HTML、Json字符串,二进制数据(图片,视频等)等类型。这个过程就是服务器接收客户端的请求,进过解析发送给浏览器的网页HTML文件。
3、解析内容
得到的内容可能是HTML,可以使用正则表达式,网页解析库进行解析。也可能是Json,可以直接转为Json对象解析。可能是二进制数据,可以做保存或者进一步处理。这一步相当于浏览器把服务器端的文件获取到本地,再进行解释并且展现出来。
4、保存数据
保存的方式可以是把数据存为文本,也可以把数据保存到数据库,或者保存为特定的jpg,mp4 等格式的文件。这就相当于我们在浏览网页时,下载了网页上的图片或者视频。