循环神经网络--LSTM与PyTorch实现(前馈)
承接上篇SimpleRNN, PyTorch中对于LSTM也有两个方法,即nn.LSTM和nn.LSTMCell。同样地,我们用两种方法来做一个简单例子的前馈。
先来看LSTMCell,实例化用到的参数如下:
from torch import nn
torch.nn.LSTMCell(input_size: int, hidden_size: int, bias: bool = True)
下面是官方文档中对于公式的说明以及参数的说明。
请注意:实例化后的LSTM(或LSTMCell)对象,其权重是 i , f , g , o i,f,g,o i,f,g,o这四个矩阵的拼接,且其拼接顺序也是 i → f → g → o i\rightarrow f\rightarrow g\rightarrow o i→f→g→o

这次我用的是台大李宏毅老师2020机器学习深度学习课程的一个例子,并且我人为做了一些改动。
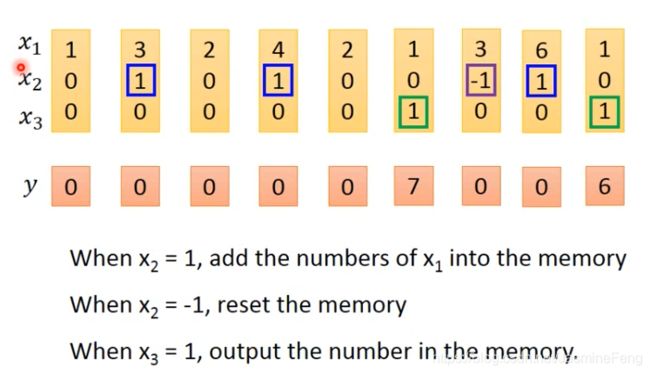
规则是这样的: x 2 = 1 x_2=1 x2=1,则更新记忆; x 2 = − 1 x_2=-1 x2=−1,则重置记忆; x 3 = 1 x_3=1 x3=1,则输出记忆。对于激活函数,老师在三个门控用的是sigmoid,把输入和输出的tanh换成了线性激活(也就是原样输出)。
在PyTorch里面似乎是不能人为指定非线性激活函数的,所以只能用tanh函数作为输入和输出时的激活。观察 tanh \tanh tanh函数的图像,我们可以发现,在 [ − 0.25 , 0.25 ] [-0.25,0.25] [−0.25,0.25]这个区间里 tanh \tanh tanh函数近似可以视作线性函数并且满足 y = x y=x y=x。
因此我们把老师PPT上的输入序列稍微变一下,我们要保证 x 1 x_1 x1在 [ − 0.25 , 0.25 ] [-0.25,0.25] [−0.25,0.25]这个区间里。
| x 1 x_1 x1 | 0.2 | 0.1 | -0.1 | -0.2 | 0.25 |
|---|---|---|---|---|---|
| x 2 x_2 x2 | 1 | 1 | 0 | 0 | -1 |
| x 3 x_3 x3 | 0 | 0 | 0 | 1 | 0 |
| 现在就让我们手动运作一下LSTMCell吧! | |||||
| t t t | 1 | 2 | 3 | 4 | 5 |
| – | – | – | – | – | – |
| i i i | σ ( 90 ) ≈ 1 \sigma(90)\approx1 σ(90)≈1 | σ ( 90 ) ≈ 1 \sigma(90)\approx1 σ(90)≈1 | σ ( − 10 ) ≈ 0 \sigma(-10)\approx0 σ(−10)≈0 | 0 | 0 |
| f f f | σ ( 110 ) ≈ 1 \sigma(110)\approx1 σ(110)≈1 | σ ( 110 ) ≈ 1 \sigma(110)\approx1 σ(110)≈1 | σ ( 10 ) ≈ 1 \sigma(10)\approx1 σ(10)≈1 | 1 | 0 |
| g g g | tanh ( 0.2 ) ≈ 0.2 \tanh(0.2)\approx0.2 tanh(0.2)≈0.2 | tanh ( 0.1 ) ≈ 0.1 \tanh(0.1)\approx0.1 tanh(0.1)≈0.1 | tanh ( − 0.1 ) ≈ − 0.1 \tanh(-0.1)\approx-0.1 tanh(−0.1)≈−0.1 | -0.2 | 0.25 |
| o o o | σ ( − 10 ) ≈ 0 \sigma(-10)\approx0 σ(−10)≈0 | σ ( − 10 ) ≈ 0 \sigma(-10)\approx0 σ(−10)≈0 | σ ( − 10 ) ≈ 0 \sigma(-10)\approx0 σ(−10)≈0 | 1 | 0 |
| c c c | 0 × f + g × i = 0.2 0\times f+g\times i=0.2 0×f+g×i=0.2 | 0.2 × f + g × i = 0.3 0.2\times f+g\times i=0.3 0.2×f+g×i=0.3 | 0.3 × f + g × i = 0.3 0.3\times f+g\times i=0.3 0.3×f+g×i=0.3 | 0.3 | 0 |
| h h h | tanh ( c × o ) = 0 \tanh(c\times o)=0 tanh(c×o)=0 | tanh ( c × o ) = 0 \tanh(c\times o)=0 tanh(c×o)=0 | tanh ( c × o ) = 0 \tanh(c\times o)=0 tanh(c×o)=0 | 0.3 | 0 |
| 记住这里的 c ( i ) , h ( i ) c^{(i)},h^{(i)} c(i),h(i),马上我们将拿他们与PyTorch运算结果对比。 |
import torch
from torch import nn
from torch.autograd import Variable
batch_size = 1
seq = 5
input_size, hidden = 3, 1
lstm_cell = nn.LSTMCell(input_size=input_size, hidden_size=hidden, bias=True)
lstm_cell.weight_ih.data = torch.Tensor([[0, 100, 0], [0, 100, 0],
[1, 0, 0], [0, 0, 100]]) # 1
lstm_cell.weight_hh.data = torch.zeros(4, 1) # 2
lstm_cell.bias_ih.data = torch.Tensor([-10, 10, 0, -10]) # 3
lstm_cell.bias_hh.data = torch.zeros(4) # 4
x = Variable(torch.Tensor([[[0.2, 1, 0]],
[[0.1, 1, 0]],
[[-0.1, 0, 0]],
[[-0.2, 0, 1]],
[[0.25, -1, 0]]]))
h_n = Variable(torch.zeros(1, 1))
c_n = h_n.clone()
for step in range(seq):
h_n, c_n = lstm_cell(x[step], (h_n, c_n))
print('t=%d' % step)
print('c=%.1f' % c_n.data)
print('h=%.1f' % h_n.data)
print('-' * 40)
nn.LSTM()
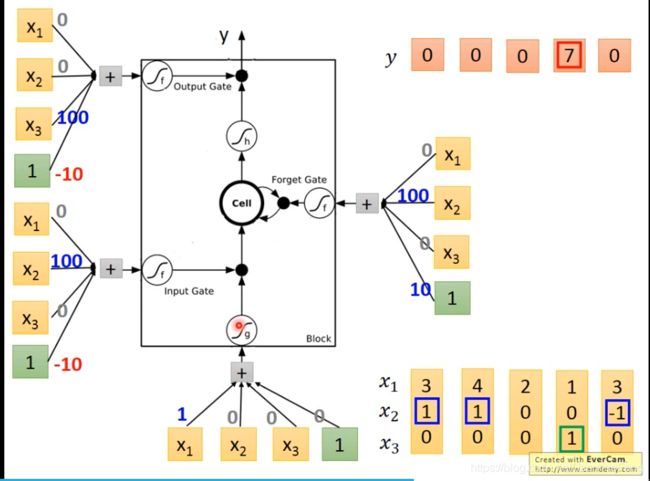
再次强调一下,实例化后的LSTM(或LSTMCell)对象,其权重是 i , f , g , o i,f,g,o i,f,g,o这四个矩阵的拼接,且其拼接顺序也是 i → f → g → o i\rightarrow f\rightarrow g\rightarrow o i→f→g→o,在#1处与#3处我是严格按照这个顺序赋值的。
在#2处和#4处,由于我们规则里当前时刻的行动(更新/重置/输出)只取决于当前时刻输入而与历史输入无关,所以理应给 W h i , W h f , W h g , W h o W_{hi},W_{hf},W_{hg},W_{ho} Whi,Whf,Whg,Who这些权重以及 b h i , b h f , b h g , b h o b_{hi},b_{hf},b_{hg},b_{ho} bhi,bhf,bhg,bho这些偏置置零。
看一下运行结果:

如果我们用更简单的LSTM而不是LSTMCell:
batch_size = 1
seq = 5
input_size, hidden = 3, 1
lstm = nn.LSTM(input_size=input_size, hidden_size=hidden, bias=True, num_layers=1)
lstm.weight_ih_l0.data = torch.Tensor([[0, 100, 0], [0, 100, 0],
[1, 0, 0], [0, 0, 100]])
lstm.weight_hh_l0.data = torch.zeros(4, 1)
lstm.bias_ih_l0.data = torch.Tensor([-10, 10, 0, -10])
lstm.bias_hh_l0.data = torch.zeros(4)
x = Variable(torch.Tensor([[[0.2, 1, 0]],
[[0.1, 1, 0]],
[[-0.1, 0, 0]],
[[-0.2, 0, 1]],
[[0.25, -1, 0]]]))
h_0 = Variable(torch.zeros(1, 1, 1)) # 1
c_0 = h_0.clone()
output, (h_n, c_n) = lstm(x, (h_0, c_0))
torch.set_printoptions(precision=1, sci_mode=False)
print('this is output:\n', output.data)
print('this is c_n:\n', c_n.data)
print('this is h_n:\n', h_n.data)
#1处的0初始化有没有都可以,如果不对 h ( 0 ) h^{(0)} h(0)初始化的话,缺省值也是零向量或零矩阵。
运行结果:
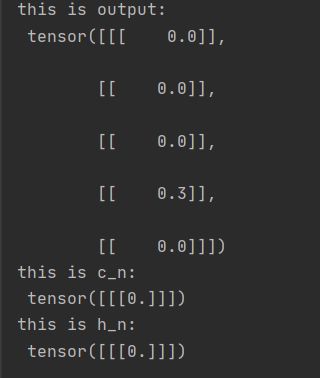
c_n和h_n用于下一时间步输入,虽然这里已经结束了。
我们可以看到,这三次结果是相吻合的✌