2021年“泰迪杯”数据分析技能赛A题任务1:数据分析与预测
2021年“泰迪杯”数据分析技能赛A题任务1:数据分析与预测
-
- 一、背景
- 二、目标
- 三、任务
- 四、过程
-
- 4.1查看数据
- 4.2数据处理与分析
-
- 4.2.1查看数据是否有空缺值
- 4.2.2去除数据中的重复值
- 4.2.3粗略查看数据是否异常
- 4.2.4统计各年度各国销售额数据&计算同比增长率
- 4.2.5统计各年度各国利润数据&计算同比增长率
- 4.2.6统计各年度各服务分类销售额数据&计算同比增长率
一、背景
进入本世纪以来,我国通讯产品得到了飞速发展,其技术先进,价格便宜,
深受世界各国和地区尤其是非洲国家的欢迎。某通讯公司在非洲的多个国家深耕
多年,产品与服务遍布整个非洲大陆。为了更好地了解公司的销售情况,采用产
品的销售额和利润数据,对其盈利能力进行分析和预测,给决策人员提供分析报
告,以便为非洲各国提供更好的产品销售策略和服务。
二、目标
- 统计产品在当地的销售数据,预测未来的销售情况。
三、任务
根据附件“非洲通讯产品销售数据”中的数据,分别实现以下任务:
任务 1.1 统计各个年度/季度中,地区、国家、服务分类的销售额和利润数
据,并计算各国、各服务分类销售额和利润的同比增长率。
任务 1.2 统计各地区、国家有关服务分类销售额和利润数据。
任务 1.3 统计各个销售经理的成交合同数和成交率。
任务 1.4 分别预测各个地区、国家、服务分类 2021 年第一季度销售额和利
润。
原始数据:https://kdocs.cn/l/clmWG135WsLe
四、过程
4.1查看数据
导入数据
import pandas as pd
import numpy as np
SalesData = pd.read_excel("D:/2021泰迪杯数据/2021 泰迪杯数据分析/A题-通讯产品销售和盈利能力分析/非洲通讯产品销售数据.xlsx", sheet_name = "SalesData")
SalesData

SalespersonData = pd.read_excel("D:/2021泰迪杯数据/2021 泰迪杯数据分析/A题-通讯产品销售和盈利能力分析/非洲通讯产品销售数据.xlsx", sheet_name =
"SalespersonData")
SalespersonData

#从上表我们发现,在读取数据时将第六,七列读进去了,这两列没有任何意义,因此删掉。
SalespersonData=SalespersonData.iloc[:,0:5]
#该代码表示为每行都进行读取,列只读取索引为[0,1,2,3,4]的前五列
#iloc的索引为数字,loc的索引为预先定义好的索引
SalespersonData
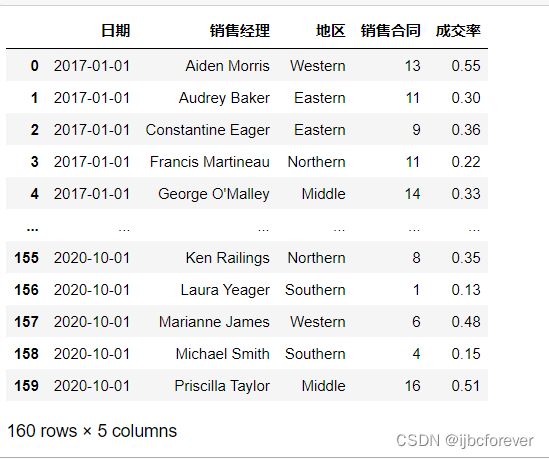
4.2数据处理与分析
4.2.1查看数据是否有空缺值
SalesData.info()
#从下方结果看到无缺失值

SalespersonData.info()

4.2.2去除数据中的重复值
SalesData.drop_duplicates(inplace = True)
#inplace=True表示直接在原数组上对数据进行修改。
SalesData.info()
#依旧是1056行数据,所以不存在重复数据

SalespersonData.drop_duplicates(inplace=True)#发现没有重复值
SalespersonData.info()

4.2.3粗略查看数据是否异常
#粗略查看数据有无异常
SalesData.describe()
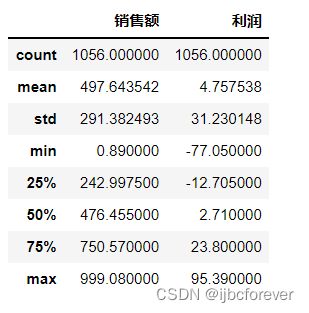
SalespersonData.describe()
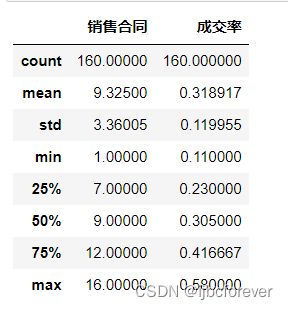
经过以上步骤确定数据基本没问题
4.2.4统计各年度各国销售额数据&计算同比增长率
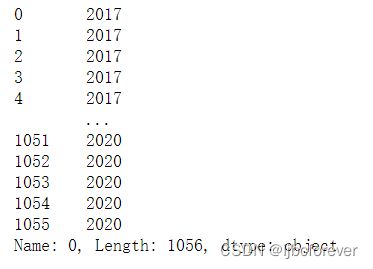
#因为统计的是各年度的销售额数据,所有需要对“日期”列进行拆分,取出年份
year = SalesData.loc[:, "日期"].astype("str").str.split("-",expand = True)[0]
#astype()函数可用于转化DataFrame某一列的数据类型
#str.split("分割符", 分割次数)
#expand表示是否把series类型转化为DataFrame类型
#因为日期形式如:2017-01-21,分割后成为三列(年,月,日),[0]代表只展示年份
year
year_data = SalesData.loc[:, ["国家", "地区", "服务分类", "销售额", "利润"]]
year_data["年份"] = year
#追加一个年份
year_data
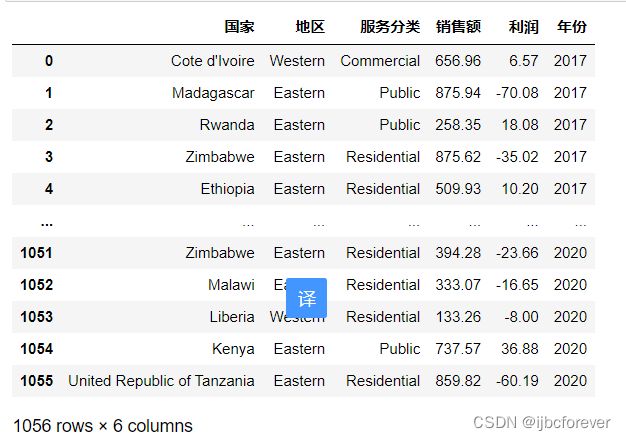
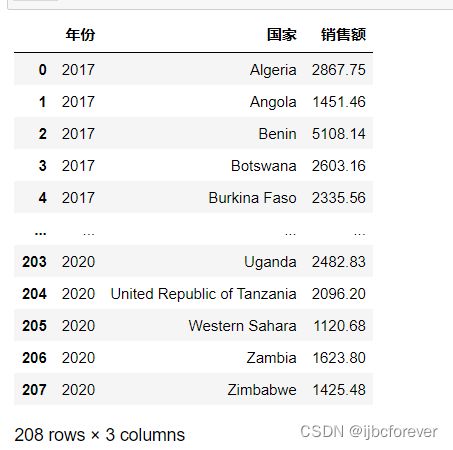
#通过groupby函数对["年份", “国家"]进行分组,对”销售额“进行求和
year_cou_sale = year_data.groupby(["年份", "国家"])["销售额"].sum()
#以csv格式保存本地
year_cou_sale.to_csv("D:/2021泰迪杯数据/自己练习/year_cou_sale.csv")
task1=pd.read_csv("D:/2021泰迪杯数据/自己练习/year_cou_sale.csv")
task1
计算出各年度各国销售额数据的同比增长率
同比增长率 (今年销售额 -去年销售额 )/去年销售额
import warnings
warnings.filterwarnings("ignore")
#merge(left, right, how='inner'(内连接), on=None, left_on=None, right_on=None, left_index=False,
#right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)合并函数
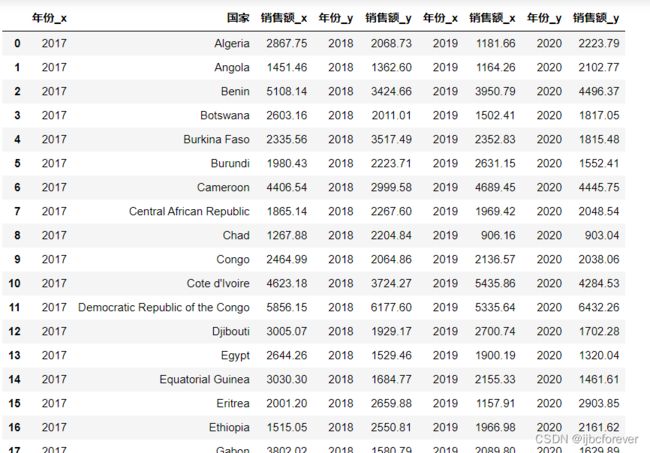
temp = pd.merge(task1[task1.loc[:, "年份"] == 2017], task1[task1.loc[:, "年份"] ==
2018], how="inner", left_on = "国家", right_on = "国家")
temp = pd.merge(temp, task1[task1.loc[:, "年份"] == 2019] ,how="inner", left_on =
"国家", right_on = "国家")
temp = pd.merge(temp, task1[task1.loc[:, "年份"] == 2020] ,how="inner", left_on =
"国家", right_on = "国家")
temp
temp.drop(["年份_x", "年份_y"], axis = 1, inplace=True)
temp

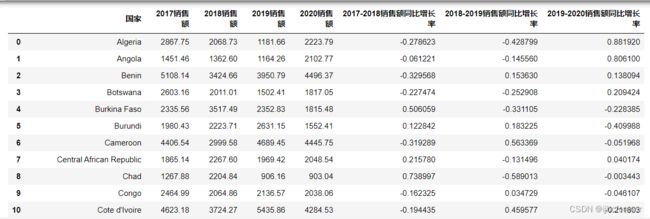
temp.columns = ["国家", "2017销售额", "2018销售额", "2019销售额", "2020销售额"] # 修改列索引
temp

temp["2017-2018销售额同比增长率"] = (temp["2018销售额"] - temp["2017销售额"]) /temp["2017销售额"]
temp["2018-2019销售额同比增长率"] = (temp["2019销售额"] - temp["2018销售额"]) /temp["2018销售额"]
temp["2019-2020销售额同比增长率"] = (temp["2020销售额"] - temp["2019销售额"]) /temp["2019销售额"]
temp
将文件保存本地
temp.to_csv("D:/2021泰迪杯数据/自己练习/各年份各国家的销售额同比增长率.csv")
temp
显示2020年度销售额Top3的国家及其年增长率
temp.loc[:, ["国家", "2020销售额", "2019-2020销售额同比增长率"]].sort_values("2020销售额", ascending = False).head(3)
#ascending表示逆序或者正序排序,ascending=False代表的是从大到小

4.2.5统计各年度各国利润数据&计算同比增长率
#通过groupby函数对[“年份”, “国家”]进行分组,对”利润“进行求和计算出各年度各国利润数据的同比增长率
year_cou_pro = year_data.groupby(["年份", "国家"])["利润"].sum()
year_cou_pro.to_csv("D:/2021泰迪杯数据/自己练习/year_cou_pro.csv")
task2=pd.read_csv("D:/2021泰迪杯数据/自己练习/year_cou_pro.csv")
task2

temp2 = pd.merge(task2[task2.loc[:, "年份"] == 2017], task2[task2.loc[:, "年份"]
== 2018], how="inner", left_on = "国家", right_on = "国家")
temp2 = pd.merge(temp2, task2[task2.loc[:, "年份"] == 2019] ,how="inner", left_on
= "国家", right_on = "国家")
temp2 = pd.merge(temp2, task2[task2.loc[:, "年份"] == 2020] ,how="inner", left_on
= "国家", right_on = "国家")
temp2
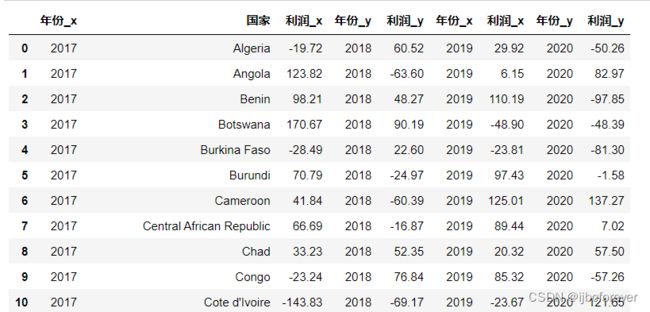
temp2.drop(["年份_x", "年份_y"], axis = 1, inplace=True)
temp2

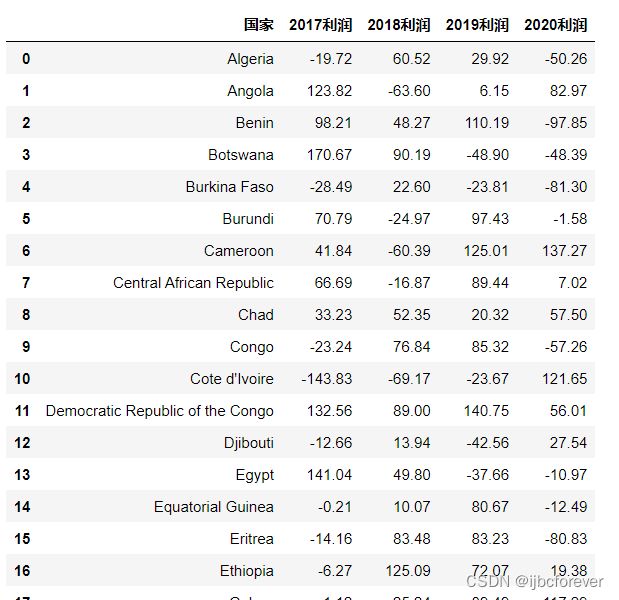
temp2.columns = [“国家”, “2017利润”, “2018利润”, “2019利润”, “2020利润”]
temp2
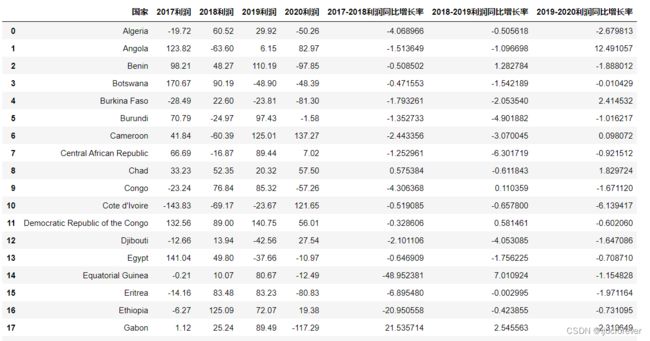
temp2["2017-2018利润同比增长率"] = (temp2["2018利润"] - temp2["2017利润"]) /temp2["2017利润"]
temp2["2018-2019利润同比增长率"] = (temp2["2019利润"] - temp2["2018利润"]) /temp2["2018利润"]
temp2["2019-2020利润同比增长率"] = (temp2["2020利润"] - temp2["2019利润"]) /temp2["2019利润"]
temp2.to_csv("D:/2021泰迪杯数据/自己练习/各年份各国家的利润同比增长率.csv")
temp2
4.2.6统计各年度各服务分类销售额数据&计算同比增长率
year_sor_sale = year_data.groupby(["年份", "服务分类"])["销售额"].sum()
year_sor_sale.to_csv("D:/2021泰迪杯数据/自己练习/year_sor_sale.csv")
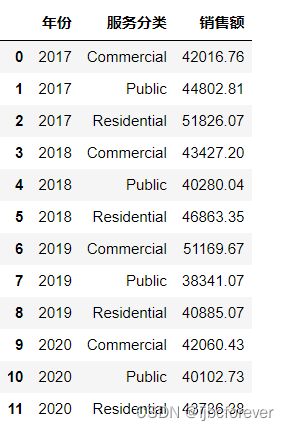
task3=pd.read_csv("D:/2021泰迪杯数据/自己练习/year_sor_sale.csv")
task3
temp3 = pd.merge(task3[task3.loc[:, "年份"] == 2017], task3[task3.loc[:, "年份"]== 2018], how="inner", left_on = "服务分类", right_on = "服务分类")
temp3 = pd.merge(temp3, task3[task3.loc[:, "年份"] == 2019] ,how="inner", left_on= "服务分类", right_on = "服务分类")
temp3 = pd.merge(temp3, task3[task3.loc[:, "年份"] == 2020] ,how="inner", left_on= "服务分类", right_on = "服务分类")
temp3
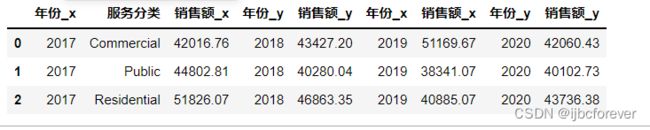
temp3.drop(['年份_x','年份_y'],axis=1,inplace=True)
temp3
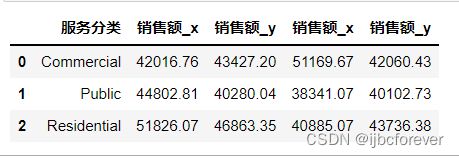
temp3.columns = ["服务分类", "2017销售额", "2018销售额", "2019销售额", "2020销售额"]
temp3
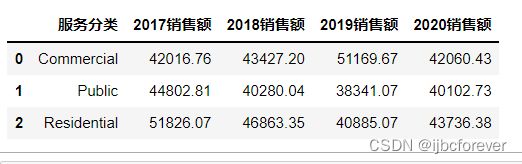
temp3["2017-2018销售额同比增长率"] = (temp3["2018销售额"] - temp3["2017销售额"]) /temp3["2017销售额"]
temp3["2018-2019销售额同比增长率"] = (temp3["2019销售额"] - temp3["2018销售额"]) /temp3["2018销售额"]
temp3["2019-2020销售额同比增长率"] = (temp3["2020销售额"] - temp3["2019销售额"]) /temp3["2019销售额"]
temp3.to_csv("D:/2021泰迪杯数据/自己练习/各年份各服务分类的销售额同比增长率.csv")
temp3
