基于sklearn实现LDA主题模型(附实战案例)
目录
LDA主题模型
1.LDA主题模型原理
2.LDA主题模型推演过程
3.sklearn实现LDA主题模型(实战)
3.1数据集介绍
3.2导入数据
3.3分词处理
3.4文本向量化
3.5构建LDA模型
3.6LDA模型可视化
3.7困惑度
LDA主题模型
1.LDA主题模型原理
其实说到LDA能想到的有两个含义,一种是线性判别分析(Linear Discriminant Analysis),一种说的是概率主题模型:隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA)。
现在讨论的是主题模型这个东西,它通俗点说吧,就是可以将一篇文中的主题以概率分布的形式来给出,从而通过去分析一些文档抽取出来它们的主题(分布)以后,就可以根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋子模型,也就是说一篇文档是由一组词构成,词与词之间没有先后顺序的关系。除此之外,一篇文章它可以包含多个主题,文章中每一个词都由是其中的一个主题生成。
我们其实很简单就可以想到我们是如何生成的文章?就是给几个主题,然后按一定的概率去选择主题,以一定的概率选择这个主题所包含的词汇,最终组合成一篇文章。LDA就是反过来的,给它一篇文章,去推断该文章的主题分布是什么。
2.LDA主题模型推演过程
我们先从一个类似LDA的模型开始,它就是PLSA模型,它类型属于有向边概率图模型。比如说我有一批数据,有部分是垃圾邮件,有部分是正常邮件,来个新数据,我怎么判定它是不是垃圾邮件?我们首先需要建立词汇表(使用现有的单子字典或者将邮件里的单词统计下得到字典),然后随机一个矩阵,经过训练后让这个矩阵去表示那个词,为啥不用onehot呢?因为比较稀疏,很容易梯度爆炸。然后套到贝叶斯公式里: P(C|X) = P©*P(X|C) / P(X),会有个问题,它没有办法解决一词多意或者多词一意的问题,会导致我们计算文本之间相似度时候的不准确性。我们找到个解决办法就是为每一篇文档加上一个主题。其实它核心的过程就是选定文章生成主题,确定主题生成词。在这个过程里,我们其实并没有关注词和词之间的出现顺序,所以PLSA是一种词袋子方法。它主要应用于信息检索,过滤,自然语言处理等领域,考虑到词分布和主题分布,使用EM最大期望算法去学习参数。
然后我们将PLSA模型加上一个贝叶斯框架就是我们的LDA主题模型了,换句话说LDA就是PLSA的贝叶斯版本,朴素贝叶斯的文本分类问题里的两个基础条件是:①条件独立;②每个特征的重要性都是一样的。
LDA在选主题和选词两个参数都弄成随机的,而且加入了一个dirichlet先验随机确定;但是PLSA中主题分布和词分布是唯一确定的,用EM极大似然估计算法去推断两未知的固定参数,这也是它俩之间最大的区别。
3.sklearn实现LDA主题模型(实战)
3.1数据集介绍
首先介绍一下本次实验的数据集,数据集通过爬虫采集新闻网中的数据,主要有两个字段,一个的文章内容,一个的内容所属分类,每个分类各有100条数据,如下所示:


3.2导入数据
首先还是导入数据,
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
data = pd.read_excel('data.xlsx')
data.head()
3.3分词处理
接着对内容content进行分词处理,对于中文分词可以使用jieba库
import re
import jieba
def chinese_word_cut(mytext):
jieba.load_userdict('dic.txt') # 这里你可以添加jieba库识别不了的网络新词,避免将一些新词拆开
jieba.initialize()
# 文本预处理 :去除一些无用的字符只提取出中文出来
new_data = re.findall('[\u4e00-\u9fa5]+', mytext, re.S)
new_data = " ".join(new_data)
# 文本分词
seg_list_exact = jieba.cut(new_data, cut_all=True)
result_list = []
with open('停用词库.txt', encoding='utf-8') as f: # 可根据需要打开停用词库,然后加上不想显示的词语
con = f.readlines()
stop_words = set()
for i in con:
i = i.replace("\n", "") # 去掉读取每一行数据的\n
stop_words.add(i)
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
return " ".join(result_list)
data["content_cutted"] = data.content.apply(chinese_word_cut)
data.head()
3.4文本向量化
from sklearn.feature_extraction.text import CountVectorizer
n_features = 1000 #提取1000个特征词语
tf_vectorizer = CountVectorizer(strip_accents = 'unicode',
max_features=n_features,
stop_words='english',
max_df = 0.5,
min_df = 10)
tf = tf_vectorizer.fit_transform(data.content_cutted)3.5构建LDA模型
因为在这里我们已经有内容所属分类这个特征,共有8个分类,所有这里我们构建8个主题模型。如果我们没有提前没有主题标签,那可以使用困惑度分析来得出这里的主题数,这个我后面再讲。
from sklearn.decomposition import LatentDirichletAllocation
n_topics = 8 # 这里是设置LDA分类的主题个数,因为这里我们已经知道了每个内容的标签共有8个类型
lda = LatentDirichletAllocation(n_components=n_topics, max_iter=50,
learning_method='batch',
learning_offset=50,
doc_topic_prior=0.1,
topic_word_prior=0.01,
random_state=666) # 关于模型的参数,可查看官方文档
lda.fit(tf)构建模型好了后,我们来输出每个主题对应的词语,
def print_top_words(model, feature_names, n_top_words):
tword = []
for topic_idx, topic in enumerate(model.components_):
print(f"Topic #{topic_idx}:" )
topic_w = " ".join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]])
tword.append(topic_w)
print(topic_w)
return tword
# 输出每个主题对应词语
n_top_words = 25
tf_feature_names = tf_vectorizer.get_feature_names()
topic_word = print_top_words(lda, tf_feature_names, n_top_words)
我们来分析一下输出的结果,第一个0主题对应的应该是....好像还看不出来,先看后面的,第二个1主题对应的应该是股票,2主题对应的应该是教育,3主题对应的应该是科技,4主题对应的应该是体育,5主题对应的是房地产,6主题对应的是娱乐,7主题对应的应该是游戏,最后还剩一个彩票,那应该就是主题0,但是效果好像不是很好,为了提高准确率,可在数据处理和参数选择的时候多下点功夫多研究研究,得到最优的模型。
接着,我们利用训练好的模型得出每篇文章对应的主题
import numpy as np
topics=lda.transform(tf)
topics[0] # 查看第一篇文章的主题概率
topic = []
for t in topics:
topic.append(list(t).index(np.max(t)))
data['topic']=topic
data.to_excel("data_topic.xlsx",index=False) # 将结果保存为Excel文件
我们可以看出第一篇文章在八个主题中的概率,其中是4主题的概率最大,说明这是一篇体育类的文章。最后保存的excel文件如下:
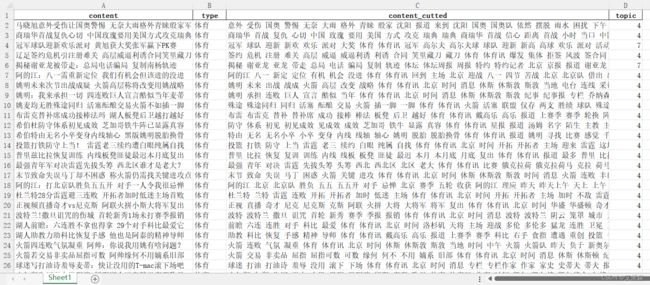
大部分都是预测正确的,也有少部分误差,这主要还是跟文章质量、数据预处理、模型参数选择有较强的关系。
3.6LDA模型可视化
import pyLDAvis
import pyLDAvis.sklearn
pyLDAvis.enable_notebook()
pic = pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer)
pyLDAvis.save_html(pic, 'lda_pass'+str(n_topics)+'.html') # 将可视化结果打包为html文件
pyLDAvis.show(pic,local=False)这里在保存为html的时候会花费大量的时间,可忽略这一步,运行后会跳出如下界面:

在上图我们可以看出我们模型各主题的分布,模型最好的结果就是每个主题都是互相隔开的,所有在前期不确定要分多个主题的时候不妨不断通过测试可视化来确定,当鼠标滑到每个主题上时,会在看见右边该主题中频次最高的前30个词语。
3.7困惑度
最后来讲讲如何利用困惑度在未知主题个数的时候通过可视化来确定。
import matplotlib.pyplot as plt
plexs = []
scores = []
n_max_topics = 16 # 这里值可自行设置
for i in range(1,n_max_topics):
lda = LatentDirichletAllocation(n_components=i, max_iter=50,
learning_method='batch',
learning_offset=50,random_state=666)
lda.fit(tf)
plexs.append(lda.perplexity(tf))
scores.append(lda.score(tf))
n_t=15 # 区间最右侧的值。注意:不能大于n_max_topics
x=list(range(1,n_t))
plt.plot(x,plexs[1:n_t])
plt.xlabel("number of topics")
plt.ylabel("perplexity")
plt.show()
如何根据图形来选取呢,原则上是看图形的最低点,因为最低点意味着主题数会很大,这样就造成了模型过拟合,所以我们只要发现在小区间内有转折点,像图中的8就是最适合的主题数。