pytorch学习笔记——4.2Pytorch中训练过程的可视化
摘要:
网络训练过程的可视化主要是帮助使用者监督所搭建的网络的训练过程,以期获得更有效的训练效果。在4.1中我们已经定义了一个简单的卷积神经网络,本节中我们将以该网络为例使用HiddenLayer库来可视化网络的训练过程。
一、搭建网络结构(同4.1内容)
由于内容与4.1节基本相同,因此不过多赘述,代码如下:
#导入相关库和数据
import torch
import torch.nn as nn
import torchvision
import torchvision.utils as vutils
from torch.optim import SGD
import torch.utils.data as Data
from sklearn.datasets import load_boston
from sklearn.metrics import accuracy_score
import numpy as np
import matplotlib.pyplot as plt
#导入手写字体数据,并定义数据加载器
train_data = torchvision.datasets.MNIST(
root="./data/MNIST",
train=False,#训练数据集
##将数据转化为张量,取值范围为[0,1]
transform=torchvision.transforms.ToTensor(),
download=True
)
#将数据处理为数据加载器
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=64,
shuffle=True,
num_workers=2,)
#准备测试数据集
test_data = torchvision.datasets.MNIST(
root="./data/MNIST/",
train=False,
download=False)
#为测试数据添加一个通道维度,并将取值范围缩放到0~1
test_data_x = test_data.data.type(torch.FloatTensor)/255.0
test_data_x = torch.unsqueeze(test_data_x,dim=1)
test_data_y = test_data.targets#测试集的标签
print("test_data_x.shape:",test_data_x.shape)
print("test_data_y.shape:",test_data_y.shape)
#搭建一个卷积神经网络
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet,self).__init__()
#定义第一个卷积层
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1,
out_channels=16,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),#激活函数
nn.AvgPool2d(
kernel_size=2,#2*2
stride=2,)
)
#定义第二个卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16,
out_channels=32,
kernel_size=3,
stride=1,
padding=1,
),
nn.ReLU(),#激活函数
nn.MaxPool2d(
kernel_size=2,#2*2
stride=2,)
)
#定义全连接层
self.fc = nn.Sequential(
nn.Linear(
in_features=32*7*7,#输入特征
out_features=128,#输出特征数
),
nn.ReLU(),#激活函数
nn.Linear(128,64),
nn.ReLU(),
)
#定义最后的分类层
self.out = nn.Linear(64,10)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0),-1)#展平多维的卷积图层
x = self.fc(x)
output = self.out(x)
return output
二、HiddenLayer库可视化训练过程
下面我们介绍如何使用HiddenLayer库可视化训练过程。
首先,导入需要的模块与库:
import hiddenlayer as hl
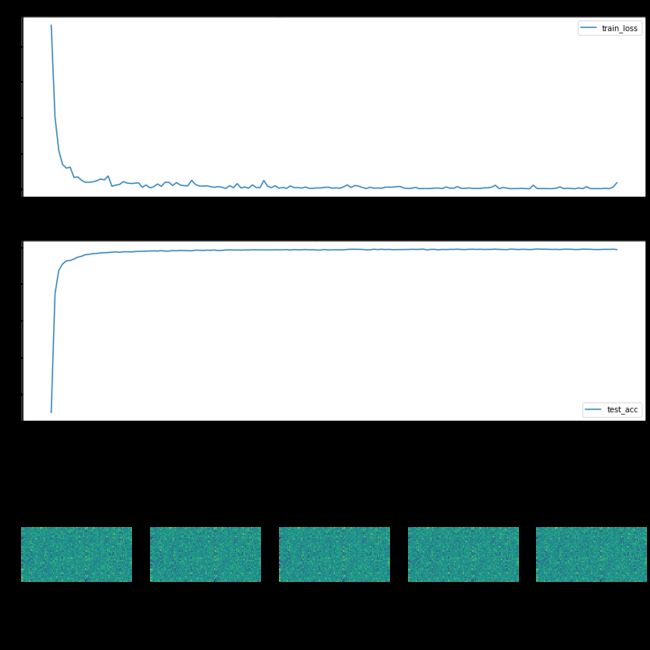
import time接下来我们在网络训练过程之前,使用history1 = hl.History()初始化一个对象history1来记录训练过程中需要可视化的内容个,接着使用canvas1 = hl.Canvas()初始化一个图层对象canvas1用于可视化网络的训练过程。在训练的过程中,我们规定每隔100个batch输出一个可视化结果。在保存需要可视化的过程时,我们使用history1.log()函数,添加需要可视化的变量,分别为训练集损失、测试集精度和第二个全连接层的权重。若要想将保存的结果可视化,我们需要使用canvas1.draw_plot()函数进行可视化折线,以及使用canvas1.draw_image()函数对权重进行可视化。代码如下:
MyConvNet = ConvNet()
optimizer = torch.optim.Adam(MyConvNet.parameters(),lr=0.0003)#定义优化器
loss_func = nn.CrossEntropyLoss()#损失函数
#记录训练过程中的指标
history1 = hl.History()
#使用convas进行可视化
canvas1 = hl.Canvas()
print_step = 100#经过100次迭代后 输出损失
#对模型进行迭代训练(epoch轮)
for epoch in range(30):
#对训练数据的加载器迭代计算
for step,(b_x,b_y) in enumerate(train_loader):
output = MyConvNet(b_x)#在训练batch的输出
loss = loss_func(output,b_y)#交叉熵损失函数
optimizer.zero_grad()#每步迭代后梯度初始化为0
loss.backward()#损失的后向传播,计算梯度
optimizer.step()#使用梯度进行优化
#计算迭代次数=
#计算100次迭代后的损失输出
if step % print_step == 0:
#计算在测试集上的精度
output = MyConvNet(test_data_x)
_,pre_lab = torch.max(output,1)
acc = accuracy_score(test_data_y,pre_lab)
#计算每个epoch和step的模型输出特征
history1.log((epoch,step),
train_loss = loss,#训练集损失
test_acc = acc,#测试集精度
hidden_weight = MyConvNet.fc[2].weight)
#可视化网络训练的过程
with canvas1:
canvas1.draw_plot(history1["train_loss"])
canvas1.draw_plot(history1["test_acc"])
canvas1.draw_image(history1["hidden_weight"])
print("training:epoch:{},loss is:{}".format(epoch,loss))结果为: