研究型论文_MBTree: Detecting Encryption RATs Communication Using Malicious Behavior Tree(CCF-A)
文章目录
- MBTree: Detecting Encryption RATs Communication Using Malicious Behavior Tree
-
- 摘要
- 存在的问题
- 论文贡献
- 1. MBTree整体框架流程
- 2. Host Behavior Formulation(主机行为表述)
-
- 2.1 Preprocessing(预处理)
- 2.2 DirPiz Extraction(DirPiz提取)
- 2.3 MLTree Construction(MLTree构建)
- 3. Detection(检测)
- 4. Experiment(实验)
-
- 4.1 数据集
- 4.2 实验结果
- 4.3 效率评估
- 4.4 参数调整
- 4.5 分析签名
- 总结
-
- 1. 提取出的论文结构
- 2. 论文的创新点
中文题目:MBTree:利用恶意行为树检测加密远程访问木马通信
发表期刊及年份:TIFS,IEEE Transactions on Information Forensics and Security ( Volume: 16),07 April 2021
作者:Cong Dong; Zhigang Lu; Zelin Cui; Baoxu Liu; Kai Chen
latex引用:
@article{dong2021mbtree,
title={MBTree: detecting encryption rats communication using malicious behavior tree},
author={Dong, Cong and Lu, Zhigang and Cui, Zelin and Liu, Baoxu and Chen, Kai},
journal={IEEE Transactions on Information Forensics and Security},
volume={16},
pages={3589--3603},
year={2021},
publisher={IEEE}
}
MBTree: Detecting Encryption RATs Communication Using Malicious Behavior Tree
摘要
检测加密远程控制木马(RAT)通信痕迹是网络安全防御的一个关键挑战。如何对不同环境下的加密RAT进行精确检测,仍然是一个有待研究的问题。
此前在这一领域的研究要么无法处理加密内容,要么在不同的环境中执行不稳定的操作。
为了解决这两个问题,我们提出了MBTree,一种新的基于主机级签名的加密RAT流量检测方法。MBTree由一个名为MLTree的结构和一个相似度匹配机制组成。MLTree集成了多个有向包有效载荷大小序列作为主机签名。匹配机制通过比较两个MLTree来判断是否触发告警。
与以往的相关研究相比,MBTree
(i)更准确地表征了不同加密RAT;
(ii)在测试环境中出现新的良性应用时具有更稳健的性能;
(iii)可以自动从恶意流量创建签名,而不需要人工交互。
为了进行评估,我们从多个来源收集流量,并以复杂的方式重新组织它们。实验结果表明,该方法具有较高的精度和鲁棒性,尤其适用于有新应用的情况。
存在的问题
- 传统的基于签名的检测RAT的方法因加密导致失效。现在一般采用机器学习的方法来检测加密。
- 机器学习在不同的环境中检测RAT的效果不稳定。大多数机器学习方法试图学习良性和恶意之间的分类边界。该策略使得模型的训练过程不仅需要恶意流量,还需要良性流量。然而,在不同的环境中,良性应用是不同的,并且每天都在变化。在这种情况下,当将一个训练过的模型转移到另一个环境中时,训练过程中没有出现的未知应用程序可能会严重混淆模型。
- 需要大量适当的训练数据。足够的数据是训练机器学习模型的关键。由于大多数训练模型依赖于数据的统计,仅用有限的训练实例很难达到完美的性能。此外,为了满足这一要求,从真实环境中收集到的数据大多不满足输入格式,包含无效记录,需要进行人工预处理。
- 解释性不足。大多数机器学习模型都是黑箱工作的,这意味着我们只能获得关于结果的少量知识。此外,这种机制很难帮助安全分析人员挖掘警报的触发因素或提供有关恶意行为的知识。
论文贡献
-
提出了一种新的名为Malicious network Behavior Tree (MBTree)的签名方法来进行RAT检测。由于RAT通常遵循固定代码过程来建立或释放连接。我们使用会话的有向包有效载荷大小(DirPiz)作为主要指纹。DirPiz可以用来识别恶意握手,以及用于加密RAT检测的挥手行为。
使用DirPiz的优势:(1)对加密流量有效。由于DirPiz不需要关于流量内容的信息,因此它也可以适应加密上下文。此外,在之前的研究中,DirPiz序列已经被证明可以有效地识别加密的应用程序和IoT设备事件。
(2)在不同环境下的稳定性。根据我们的观察,大多数样品的DirPiz序列在不同的机器上保持不变。因此,它们可以在不同的环境中使用,以获得健壮的性能。
(3)提取方便。DirPiz可以自动从pcap或pcapng格式文件中生成。与传统签名相比,该签名更加方便,无需人工操作。 -
提出了多层次树(MLTree)结构来更准确地描述恶意行为。
使用MLTree的优势:(1)MLTree可以准确捕获独特的恶意行为。通过记录DirPiz的统计数据,可以在MLTree中突出显示典型的握手或挥手行为,从而精确捕获恶意活动。更重要的是,与匹配流量指纹DirPiz序列相比,匹配主机签名MLTree需要足够的恶意流量证据。因此,DirPiz可以避免由少数巧合引起的误报。
(2)可以有效地管理MLTree签名。在层次结构的基础上,设计了一种合并机制来集成相关签名。因此,多个恶意跟踪可以在一个签名中表示,以减少存储开销和检测开销。
(3)可以自动创建MLTree,以适应规模签名的创建。整个签名创建过程,包括DirPiz提取和MLTree构造,都可以通过流量预处理库自动实现。该特性使安全专家从繁琐的手工签名编制工作中解脱出来。 -
提出了一种相似度匹配机制,以取代以往大多数签名研究中采用的精确匹配策略。测试实例和签名之间的相似度包括两个部分:握手相似度和挥手相似度。两部分相似度都由连续边的比较作为路径评分,由不同节点的比较作为节点评分组成。综合四个分数和预先设定的阈值,可以判断该流量是否属于恶意流量。
使用相似度匹配机制的优势:与精确匹配策略相比,该机制能够覆盖生成签名的偏差,并通过阈值调整检测的告警级别。因此,这种策略更灵活,更适合我们的新签名。
-
证明了所提出的MBTree方法可以适应训练实例有限和未知良性应用的严格情况。
-
通过调优参数和分析生成的签名,深化了所提出的MBTree。
1. MBTree整体框架流程
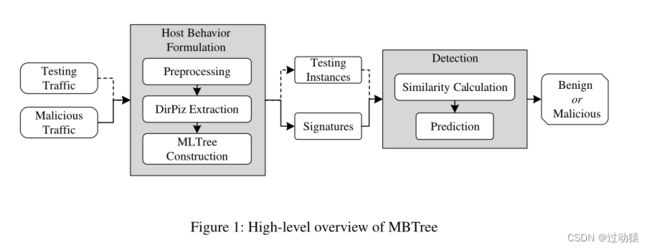
组成部分:
- Host Behavior Formulation(主机行为表述):将流量构造为MLTree表述
- Detection(检测):根据相似度向量进行预测,看测试流量是否为恶意流量
具体流程:
- 测试流量和恶意流量一起进入Host Behavior Formulation模块。
Preprocessing(预处理):实现了流量清理和会话重组。
DirPiz Extraction(DirPiz提取):从每个会话中提取DirPiz作为多个独立序列。
MLTree Construction(MLTree构建):将这些序列基于公共宿主进行关联,并构建MLTree作为宿主行为。
在此过程中,恶意流量和测试流量的产生步骤相同,分别产生签名和测试实例。
- 将转换后的测试实例与每个签名进行比较,通过两个步骤确定它们是否匹配任何恶意行为。
第一步:计算测试实例和每个签名之间的相似度,以生成相似度向量。
第二步:根据相似度向量预测实例是否属于恶意。
2. Host Behavior Formulation(主机行为表述)
2.1 Preprocessing(预处理)
训练集:一部分纯Quasar流量(恶意流量)
测试集:一部分Quasar流量和WhatsApp流量的混合(恶意流量和正常流量的混合)
由于我们考虑到主机行为来自于有效会话,所以我们首先应用流量清洗来丢弃无效报文,然后进行会话重组来恢复这些通信。
流量清洗:
由于清洗目的不同,所以对训练集和测试集采用不同的策略进行清洗:
训练集:采用“白名单”策略,只保留含有恶意IPS的报文。因此,只有纯恶意报文才会被选中。
测试集:采用“黑名单”策略:删除以下几种类型的报文:(1)重复报文,(2)环路报文,(3)非传输报文。
会话重组:
清洗后,将流量重组为会话,恢复所有的端到端通信。在此过程中,我们主要基于5元组来识别传输会话。5元组包括源IP、目的IP、源端口、目的端口和协议。此外,对于TCP协议,还使用代表通信状态的标志字段来准确识别唯一的会话。
2.2 DirPiz Extraction(DirPiz提取)
给定一个重新组合的会话,我们提取会话的特定DirPiz序列来识别自动握手和挥手行为。
具体地说,DirPiz序列通常由负载大小和连接中的方向组成。
方向:数据包要么是客户机对服务器的请求,要么是服务器对客户机的响应。
负载大小:数据包字节数
事实上,数据包的多种元信息都可以作为指纹提取,如数据包间隙间隔、数据包有效载荷哈希等。然而,它们要么在不同的网络环境中缺乏稳定的性能,要么不适应动态加密密钥协商机制的可变加密内容。因此,我们选择DirPiz作为其健壮性能的元信息。
DirPiz序列生成的具体步骤如下:
- 第一步,如果设置了碎片字段,我们将重新组装不同的IP包。由于MTU或潜在的IP分片攻击的限制,通信内容可能分散在多个IP报文中。重组这些碎片IP包可以恢复通信中的真实负载。
- 第二步,根据这些重新组合的IP报文,根据上层(upper-level)协议计算负载大小,形成一个序列。该过程主要是为了减少底层(low-level)协议细节的影响,如TCP握手和SSL/TLS协商。
UDP协议:使用传输有效载荷的长度。
TCP协议:只在连接建立后,使用数据包中传输负载的长度。
SSL/TLS协议:只使用“应用程序数据(Application Data)”数据包中的SSL/TLS有效负载的长度。
- 第三步,将方向符号附加到有效载荷大小序列中。
从客户机到服务器的请求信息被表述为一个正数。
从服务器到客户机的响应信息被表述为一个负数。
- 为了关注自动握手和握手过程,统一序列的长度,我们只保留序列中的前L元素和后L元素分别描述handshake(握手)和handwave(挥手)行为。
对于长度小于L的序列,使用-1作为填充值。之后,DirPiz序列被生成并格式化为两个部分。
以下是L=6的情况:

2.3 MLTree Construction(MLTree构建)
通过将多个不同的DirPiz序列集成到MLTree中来构建主机行为结构。对应于使用DirPiz序列的握手和挥手两个部分对会话进行指纹识别,我们使用两个MLTree来表示样本的主机签名,包括一个头MLTree和一个尾MLTree。
MLTree是一个加权有向无环图(WDAG), T = ( N , E , C N , C E ) T = (N,E,C_N,C_E) T=(N,E,CN,CE),
N为节点集合,E为边集合, C N C_N CN为节点权重集合, C E C_E CE为边权重集合
N = { N l } l = 0.. L , E = { E l } l = 0.. L , C N = { C N l } l = 0.. L , C E = { C E l } l = 0.. L N = \{N^l\}_{l=0..L},E=\{E^l\}_{l=0..L},C_N=\{C_N^l\}_{l=0..L},C_E=\{C_E^l\}_{l=0..L} N={Nl}l=0..L,E={El}l=0..L,CN={CNl}l=0..L,CE={CEl}l=0..L,其中 l l l 为level(层次)节 点 集 N 节点集N 节点集N:用于表示按层次(level)分组的唯一DirPiz。
统 计 集 C N 统计集C_N 统计集CN:用于记录在级别中组织的每个唯一DirPiz的聚集发生情况。
边 集 E 边集E 边集E:用于表示由两个相邻层分组的两个同时出现的DirPiz。
统 计 集 C E 统计集C_E 统计集CE:用于记录每两个相邻DirPiz的同时出现情况。
MLTree构建方法:
构建单个树:

合并树:采用合并操作,提高了重复模式的覆盖率,降低了重复模式的存储成本。

这两个算法流程图看起来不太直观,可以看下面的图来理解,这个图是根据上面那个DirPiz序列生成的MLTree:
总得来说,就是从左到右来对每个会话的DirPiz序列进行分层,以此来构建每个层次的节点和边。举个例子来说,对于Quasar Traffic而言,上面那个图的DirPiz序列的第一层:全是68(竖着看),因此构造出的节点 n 0 n^0 n0为68,节点权重 c n 0 c_n^0 cn0为4(因为一共有4个68),边 e 0 e^0 e0为(-1,68),边权重 c e 0 c_e^0 ce0为4(因为一共有4个(-1,68))。
第二层:全是-228(竖着看),构造出的节点 n 1 n^1 n1为-228,节点权重 c n 1 c_n^1 cn1为4(因为一共有4个-228),边 e 1 e^1 e1为(68,-228),边权重 c e 1 c_e^1 ce1为4(因为一共有4个(68,-228))。
以此类推…
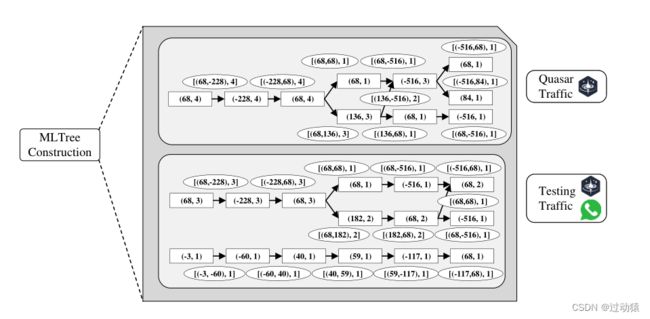
MLTree优点:
- MLTree确保了灵活的合并以有效地表示签名。除了合并DirPiz之外,MLTree设计还可以合并由相同样本生成的不同MLTree。该特性降低了存储重复签名的成本
- 层次设计可以直观合理地表示宿主行为。由于DirPiz序列可以分层组织,以方便统计不同通信位置上的DirPiz,因此可以通过区分每个层次上的频繁DirPizs和不频繁DirPizs来量化自动握手行为。因为频繁的DirPiz自动生成的概率更高。
- 可以自动构造MLTree。MLTree的构建和合并都可以用一个系统脚本完成。这样的施工不需要与安全专家和先验知识的交互,可以降低人工成本。
3. Detection(检测)
与使用精确匹配策略的传统基于签名的检测不同,该检测方法依赖于相似度匹配策略来决定测试实例是否应该被视为恶意的。
检测步骤:
- 首先,计算测试实例与每个签名的相似向量vm = [s0,s1,…,sn],n为训练集构造的MLTree树的个数。向量中的每个元素为测试实例的MLTree与相应的签名的MLTree相似度分数。
一般来说,两个ml树的相似度包括两个方面,路径相似度和节点相似度。
路径相似度的量化表示:
节点相似度的量化表示:
这里作者写的篇幅比较长,而且公式的符号也比较复杂,为了更便于理解,使用作者的例子来解释:
简单来说就是,找出测试集MLTree中的每一条路径,与训练集MLTree进行比较,计算出路径相似度和节点相似度,从而根据这两个值来量化两棵树的相似度。具体计算方法,对比来看这个图和上一个图就能明白,这里就不细讲了。
- 计算出路径相似度和节点相似度后,测试实例与签名的相似度评分S表示为:
S f n 和 S f p S_{fn}和S_{fp} Sfn和Sfp分别表示对应头MLTree的节点相似度和路径相似度,
S l n 和 S l p S_{ln}和S_{lp} Sln和Slp分别表示对应尾MLTree的节点相似度和路径相似度,
α表示决定节点分数和路径分数平衡参数,
β表示决定头分数和尾分数平衡参数。
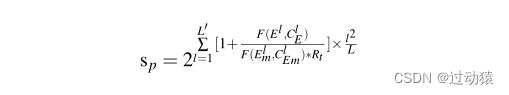


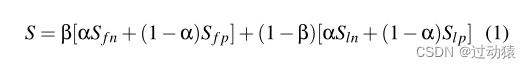
预测步骤:
- 计算出测试实例与每个签名的相似向量vm = [s0,s1,…,sn]后,选择该向量中最大值,记为 S m S_m Sm
- 设置一个阈值 θ θ θ,若 S m > θ S_m>θ Sm>θ,则可以根据 S m S_m Sm所在相似向量的索引(记为 I m I_m Im)来判断该测试实例的恶意行为类型。若 S m < = θ S_m<=θ Sm<=θ,则判断该测试实例为正常流量,因此没必要判断RAT类型。
4. Experiment(实验)
4.1 数据集
两个恶意流量部分:
自行收集的开源RATs流量(OSER)、从Stratosphere项目中选择的木马流量(WT)
两个正常流量部分:
ISCX VPN2016、USTC-TFC2016
数据集I:OSER、ISCX VPN2016、USTC-TFC2016
数据集II:WT、ISCX VPN2016、USTC-TFC2016
使用5折交叉验证,每折:trainset:validset:testset = 0.49:0.21:0.3
下表表示两个数据集的具体细节:

出现在训练集中的良性应用程序不会出现在测试集中。这种分区策略旨在模拟测试环境中出现的未知应用程序,这种场景在现实中很常见。
4.2 实验结果
数据集I的特性与结果:
- 恶意和良性流量的分布是极其不平衡的:可用于测试模型的抗不平衡数据集能力
- 训练集和测试集中的良性流量来自的不同应用程序,分布会有所偏离;训练集和测试集中的恶意流量分布也可能有所偏离(因为它们来自不同的操作系统):可用于测试不同环境下模型的鲁棒性
可以发现机器学习方法在验证集和测试集上效果不太好,这主要是因为数据集数量较少且极度不平衡导致的。

数据集II的特性与结果:
- WT中提供了更多的恶意流量,比数据集I的不平衡度要小。
- 训练集和测试集中的良性流量来自的不同应用程序,分布会有所偏离;而训练集和测试集中的恶意流量分布不会有所偏离。
(1)第一,MBTree在该数据集中仍然表现稳定,在验证集和测试集上都可以达到约99%的Acc和90%的F1。需要注意的是,MBTree并没有达到数据集i中的高性能。通过分析检测结果,我们观察到数据集II中的大多数错误分类实例由较短的通信序列组成,这意味着客户端和C&C之间只交换了一到两个有效负载。在这种情况下,由于C&C的沉默,我们怀疑没有建立积极的联系。
(2)第二,机器学习方法在验证集和测试集上的表现明显不同。尽管它们可以在验证集上达到95%以上的Acc和90%以上的F1,但它们很难处理未知的应用程序,因此在测试集上表现较差。这些结果表明,尽管验证和测试的恶意流量产生于相同的分布,但基于机器学习的方法更容易受到环境变化的影响。
(3)第三,尽管dirpizza - seq在数据集I中表现良好,但在数据集II中表现较差。这一现象表明,仅利用流级通信序列作为签名是不够的。将多个流级序列集成到具有相似匹配机制的主机级MLTree的复杂设计,在遇到规模较大的恶意流量时,具有相当好的效果。
(4)虽然深度学习已经成为目前研究的热点之一,但从我们的实验中可以看出,该技术(1)在训练实例有限的情况下性能较差,(2)在实际应用中泛化能力较差。

4.3 效率评估

与基于机器学习的方法相比,MBTree比CART和RandomForest花费更多的时间进行预测。通过分析匹配机制的工作流程,我们发现该方法的主要开销来自于计算相似度分数时的交集操作。在我们用来实现MBTree的python中,两个集合的交集操作的平均复杂度是O(min(a,b)),其中a,b指集合的长度。实际上,这可以通过其他算法进行优化来降低成本。例如,[8]已经证明,交集的复杂度可以降低到O((a + b)/√w),其中w是机器字中的比特数。
4.4 参数调整
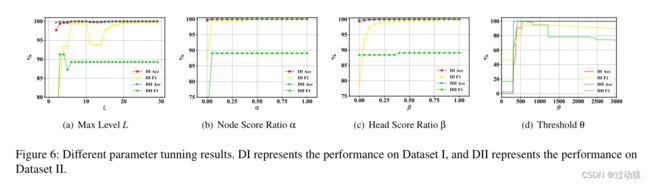
参数:最大层数L、评分比α、评分比β、阈值θ
主要思想是:选定一个默认的初始值,固定其他参数,调整其中一个参数。
4.5 分析签名

通过计算每层上唯一数据包大小值的数量来检查样本之间的差异。在本实验中,L的最大级别设置为30,这对于握手过程来说是一个比较深的值。
很明显,对每层来说,大多数签名的唯一数据包大小值的数量都小于50。这种外观表明,对于大多数恶意签名,将包大小记录为模式的成本更低(大多数都是那么几种数据包的长度,不会出现特别特别多种数据包的长度)。
总结
1. 提取出的论文结构
Abstract:
(1)两句话阐述背景
(2)阐述这一领域之前研究的存在问题
(3)为了解决上述问题,提出了什么,并阐述一下描述一下提出的内容
(4)与以往的研究相比,优点在哪,分条(i),(ii)…
(5)评估方法和最终结果
1 Introduction
(1)第1自然段:先简单介绍一些威胁(本文就是RAT)
(2)第2自然段:介绍一下现有的比较常用的防御威胁的手段,以及他们的局限性
(3)第3自然段:说一下目前的一些工作进展(但不用展开来说,只添加引用即可),并总结一下他们的局限性
(4)第4-7自然段:简单介绍一下我们的工作,并解释一下我们的工作相比于前人工作的优势。
(5)第8自然段:介绍一下我们的实验方法和最终结果。
(6)分条总结一下我们的贡献。
2 Related Work
(1)分几个部分来介绍与本文工作相关的内容
(2)每个部分可以使用先总后分的形式来介绍,按类别简单分成几个大类来统一介绍一下他们的方法及其优势,然后再选择两三个比较有代表性或者特点的论文具体讲解一下。最后总结一下他们的劣势。
3 xx Overview
总体介绍一下整个流程的框图,注意这个框图要包含所有内容,后面介绍的内容要基于这个框图来展开。
(1)画出一个整体的流程图
(2)按照流程图,通过First,Second,…,来一步一步进行介绍。
4 框图中的部分1
按照框图的内容展开讲解,如果框图中该部分由多个小部分组成,那么就按照4.1,4.2,…,分小节进行讲解,如果每小节中仍需要细分,可以使用粗体开头或者接着细分小节来展开讲解。
5 框图中的部分2
同4一样。注意这两部分的讲解除了通过文字阐述、算法流程图、图表、公式等方式进行讲解外,还可以使用举例的方式来更直观的表示出来(如本文中就通过举例的方式画图来展示4和5这两个流程对数据的处理方式)
6 Evaluation Framework
(1)6.1 Evaluation Data:这部分主要介绍使用的数据,如果使用的数据需要自行收集,那么就要在这节讲清楚收集方法。
(2)6.2 Data Organization:这部分用来介绍上一节中提到的数据要怎么使用,即训练集、验证集、测试集都使用哪些数据,比例是多少。
(3)6.3 Baselines:这部分用来介绍对比实验中采用哪些模型。一般是采用一些论文中的方法或者自己手动实现的一些模型(最好是比较前沿的)。
(4)6.4 Tasks & Metrics:这部分主要用来介绍实验任务和评估指标。
7 Experiment
(1)7.1 模型效果:这部分用来展示论文提出的方法和baseline中的方法的对比,用表格形式展示,此外还要对结果进行深刻分析。
(2)7.2 参数调整:这部分对文中提到的一些超参数进行调整,用统计图的方式展示,并对结果进行深刻分析。每个参数要分开讲解(每个参数占一个自然段)。
(3)7.3 文章的一些特殊分析:这部分主要是对文章提出的模型或方法做一些特殊性分析,如果不存在就不写。(对这篇文章来说,这节就用来分析各个RAT签名的特征了)
8 Discussion
这部分思维可以比较发散,可以从以下几个方面进行分析:
(1)对文章中存在的一些特殊情况的分析
(2)反向思维(比如这道题提出了一个检测模型,他就可以用这节来介绍如何攻击会导致该检测模型失效,即该模型的脆弱性,但最好再提出实现这种攻击很困难…)
9 Conclusion
总结一下整篇文章的工作。
2. 论文的创新点
- 没有使用当前比较流行的机器学习和深度学习方法来检测RAT,因此规避了机器学习和深度学习难以处理训练数据少或数据不平衡的弱点。
- 模型在不同环境下的稳定性较强。