【手势姿态估计】综述
目录
- 手部姿态估计相关综述的总结
-
- 什么是手部姿态估计
- 演进or发展
-
- 1.什么推动了手部姿态的发展:
- 2.发展历程概述:
- 手部姿态估计的分类
-
- 1.手部模型关节点个数分类
- 2.手部姿态估计分类
- 3.手部姿态估计方法分类
- 两种不同的传感设备(参考文献2)
-
- 基于可穿戴的设备
- 基于视觉传感设备
- 数据集和评价指标
-
- 1.数据集
- 2.评价指标
- 基于深度图像手势姿态估计方法
-
- 1.简单2D深度图像(重点)
- 2.基于3D体素数据
- 3.基于3D点云数据
- 总结和展望
-
- 1.准确性
- 2.可移植性
- 3.实用性
- 参考
手部姿态估计相关综述的总结
什么是手部姿态估计
人机交互中的手部交互,可以分为手势识别和手部姿态估计两大技术,手势识别可以认为是模式识别的问题,手部姿态估计则可以认为是回归问题,目标是在三维空间中恢复手部的完整运动结构。
具体的,手部姿态估计是指从视频或图像中精确定位到手部关节点的位置,从而根据这些位置关系推断出相应的手部姿态。
演进or发展
1.什么推动了手部姿态的发展:
- 比赛(Hands 2017\2019)
- 市场需求或应用:人机交互、增强技术、虚拟现实、手势识别、机器人抓取、智能设备,手语识别
- 计算机科学技术以及相关领域的发展
- 人体各个重要组成部分中,由于其灵活性和高效性,手部是人体最为重要的组成之一
2.发展历程概述:
运动学模型与形状模型的结合是许多模型驱动方法的基础,但手也可以以“非参数”方式建模,也就是说,可以从图像或其他类型的数据训练手的隐式结构模型。

1.基于辅助设备(非视觉手部姿态估计时期)
-
大多数手部姿态重建方法都是基于外部传感设备或直接连接在手腕上的可穿戴传感器
-
Dewaele 等人提出的数据手套方法,使用者穿戴上装有传感器设备的数据手套,通过手套中的传感器直接获取手部关节点的坐标位置,然后根据关节点的空间位置,做出相应的手势姿态估计;
-
Wang 等 人使用颜色手套来进行手势姿态估计,使用者穿戴上特制颜色手套来捕获手部关节的运动信息,利用最近颜色相邻法找出颜色手套中每种颜色所在的位置,从而定位手部关节肢体坐标位置。基于辅助设备的手势姿态估计具有一定优点,如具有良好的鲁棒性和稳定性,且不会受到光照、背景、遮挡物等环境因素影响,但昂贵的设备价格、繁琐的操作步骤、频繁的维护校准过程、不自然的处理方式导致基于辅助设备的手势姿态估计技术在实际应用中并没有得到很好地发展
2.基于传统机器学习
- 主要关注对图像的特征提取,包括颜色、纹理、方向、轮廓等。经典的特征提取算子有主成分分析( Principal Component Analysis,PCA) 、局部二值模式( Local Binary Pat- terns,LBP) 、线 性 判 别 分 析 ( Linear Discriminant Analysis, LDA) 、基于尺度不变的特征( Scale Invariant Feature Transform,SIFT) 和方向梯度直方图( Histogram of Oriented Gradient,HOG) 等。获得了稳定的手部特征后,再使用传统的机器学习算法进行分类和回归,常用的方法有决策树、随机森林和支持向量机等。
3.基于深度学习
- 文献[21]以深度图像作为输入数据源,通过卷积神经网络预测输出手部关节点的三维坐标;
- 文献[22]利用深度图的二维和三维特性,提出了一种简单有效的 3D 手势姿态估计,将姿态参数分解为关节点二维热图、三维热图和三维方向矢量场,通过卷积神经网络进行多任务的端到端训练,以像素局部投票机制进行 3D手势姿态估计;
- 文献[23]将体素化后的 3D 数据作为 3DCNN网络的输入,预测输出生成的体素模型中每个体素网格是关节点的可能性;
- 文献[24]首次提出使用点云数据来解决手势姿态估计问题,该方法首先利用深度相机参数将深度图像转化为点云数据,再将标准化的点云数据输入到点云特征提取神经网络[25,26]提取手部点云数据特征,进而回归出手部关节点位置坐标.
- 将深度学习技术引入到手势姿态估计任务中,无论是在预测精度上,还是在处理速度上,基于深度学习手势姿态估计方法都比传统手势姿态估计方法具有明显的优势,基于深度神经网络的手势姿态估计已然成为了主流研究趋势。
手部姿态估计的分类
1.手部模型关节点个数分类
常见的手部模型关节点个数为14、16、21 等。在手势姿态估计领域,手部模型关节点的个数并没有一个统一的标准,在大多数手势姿态估计相关的论文和手势姿态估计常用数据集中,往往采用 21 关节点的手部模型。
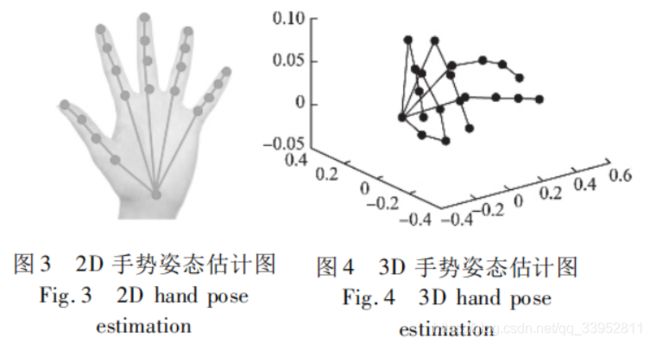
2.手部姿态估计分类
-
根据关节点所处空间位置不同,可分为2D手部姿态估计和3D手部姿态估计(目前3D手部姿态估计更多,因为其实际应用价值更大)
-
根据数据输入图像的不同,可分为基于RGB图像,深度图像、和RGB-D(RGB图像和Depthmap)图像的手部姿态估计
如下图:

3.手部姿态估计方法分类
1.模型驱动
模型驱动方法需要大量的手势模型作为手势姿态估计的基础。该方法实现的过程为: 首先,创建大量符合运动学原理即合理的手势模型,根据输入的深度图像,选择一个最匹配当前深度图像的手势模型,提出一个度量模板模型与输入模型的差异的代价函数,通过最小化代价函数,找到最接近的手势模型。
模型驱动是基于固定手势模型,手势姿态识别率高;
2.数据驱动
数据驱动方法需要大量的手势图像数据作为手势姿态估计的基础. 数据驱动方法所使用的图像数据可以是 RGB 图 像、深度图像或者是 RGB-D 图像中的任意一种或者多种类型图像相结合。基于数据驱动的手势姿态估计方法可进一步分为基于检测和基于回归的方法。
数据驱动基于神经网络,不需要固定手势模型,且对不确定手势和遮挡手势的鲁棒性高.
3.混合驱动
常见的混合式手势姿态估计方式有两种: 1) 先使用模型驱动预估一个手势结果,若预估失败或者预估的结果与手势模型相差较大,则使用数据驱动进行手势姿态估计,在这种方法中,数据驱动只是作为一种备选方案当且仅在模型驱动失败的情况下使用; 2) 先使用数据驱动预测出一个初始的手势姿势结果,再使用模型驱动对预测的初始手势结果进行优化。
两种不同的传感设备(参考文献2)
基于可穿戴的设备
- 可穿戴传感器大多是手套(也称为“数据手套”)的形式,用户可以直接戴上。数据手套使用专用的电磁或机械传感器,直接捕捉手掌和每个手指关节的弯曲角度,从而可以实时记录与手腕相关的局部配置。由于数据手套不支持位置跟踪,所以通常需要基于视觉的传感器来捕获一只手的全局配置
- 起始于20世纪70年代,活跃了超过40年,大致可以分为两个类别,一个是数据手套,一个是可穿戴标记器。手套的作用是获取数据、集成处理和供电设备,穿戴在用户的手上。自然嵌入在内的传感器可以获取手指弯曲和手指的数据。现在存在4种类型的用于手部相关的传感设备,弯曲传感、伸直传感、惯性测量单元、磁性传感。
基于视觉传感设备
-
又叫摄像头(一般情况下),可常见于各种智能手机、机器人、监控设备等设备中,可以探测任何可见光、红外线和一些激光中,最近,基于深度摄像头和深度学习算法的发展,基于此的手部姿态估计算法也得到了较快的发展
-
可以大致分为Generative Methods和Discriminative Methods(也就是生成式模型和鉴别式模型)。前者又叫基于模型或模型驱动的方法,后者又叫做基于数据驱动的方法。
-
Generative methods需要构建一个基于先验知识的明确的手部模型,以此恢复手部姿势。如下图,首先对模型进行参数初始化(根据先验知识),常用的初始化方法是根据上一帧手部姿态作为下一帧的初始化值,然后构建一个损失函数,得到从图像中获取到的真实手部特征和模型参数的距离,以此来获取手部模型,常用的特征有轮廓、边缘、阴影、光流和深度信息,最后,模型的参数值被不断更新,直到找到最优的模型参数值,常用的优化方法有迭代最近点算法和粒子群算法。常用的生成模型算法一般是几何生成模型,而几何生成模型一般有生成式圆柱形模型(GCM)、可变形多边形网格模型(DPMM)

-
Discriminative Methods的目标是学习从视觉特征(visual features)到目标参数空间(target parameter space)的映射,如图像或视频中的联合标签或联合3D位置。总之就是一个回归问题,预测手部关键点的位置,其非常依赖于数据集,一般分为随机森林(RF)和CNN的方法。
-
Keskin首先使用随机决策森林来进行手部形状的分类,并通过这种手部分类森林应用在手部姿态估计上面,然而其标注工作的难度大,使用合成数据又与真实数据差异大;Tang等人提出一种半监督转换回归方法,学习真实稀疏数据和合成数据之间的关系;由于基于像素级别的分类,常常受限于真实世界的噪声数据,Liang等人使用超像素-马尔可夫随机场(SMRF)解析方案,以加强空间平滑,以及在去除错误分类区域之前的标记共现(used a superpixel-Markov random fifield (SMRF) parsing scheme to enforce the spatial smoothness and the label co-occurrence prior to remove the misclassifified regions),他们通过使用一种新的距离自适应选择方法,以更有区别的深度-背景特征为目标,以回归的稳健性为目标。为了进一步提高基于回归森林的方法的准确性和效率,Tang等人[74]提出了一种新的基于森林的图像结构化搜索判别框架,称为潜在回归森林(LRF)。该方法以深度图为输入,采用数据驱动的无监督学习方法学习手的拓扑结构。LRF与现有方法的主要区别在于,它在点云上采用了一种结构化的从粗到细的搜索方法,而不是密集的像素点,并且采用了一个误差回归步骤来避免误差积累。(其他参考文献【2】)
-
深度学习近年来发展迅速,在手部姿态估计中得到了广泛应用。这种方法训练深度卷积神经网络,通过大量标记数据集学习模型参数,从而预测关节位置,实现手部姿态估计。
-
Tompson等提出了一种四阶段手位姿估计方法。首先对输入图像进行决策森林处理,将手从背景中分离出来。当获得图像中的手时,开发了一种鲁棒方法来标记数据集。然后,利用深度卷积神经网络从输入的手部图像中提取热图。最后,从热图中提取特征,提出并最小化目标函数,将模型的特征与热图特征进行匹配。虽然他们在手跟踪中取得了良好的效果,但在遮挡的情况下效率低下,因为它使用逆运动学(IK)方法从2D图像中恢复三维姿态。为了解决这一问题,Sinha等[20]提出了一种基于全局和局部回归的方法。在他们的工作中,首先对手腕的参数进行全局回归计算,然后使用5个局部回归网络分别计算5个手指的参数,该方法可以有效地解决遮挡问题,也避免了前一帧丢失时需要重新初始化所有参数的问题。
-
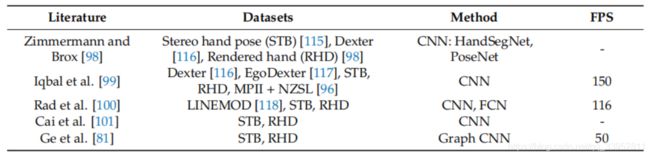
上述工作仅考虑了直接预测手关节的位置。而在手部运动过程中,不同的手部关节之间存在很强的相关性,因此可以引入先验信息来约束参数空间。Oberweger等人[80]提出的方法通过增加先验信息来预测较低维空间的姿态参数,可以解决手指关节的模糊性。他们在网络的最后一层引入了“瓶颈”结构,这一层只有必要的神经元。
-
虽然上述工作解决了遮挡问题或利用先验信息约束参数空间以获得良好的结果,但它们通常对训练数据集要求很高。为了降低从现实世界获取大量标记数据的成本,他们经常使用合成数据来训练卷积神经网络。例如,Ge等人[81]利用包含地面真实三维网格和三维位姿的合成数据集实现三维手形和位姿估计。Wan等人使用深度图,由[45]提供的手模型在线生成来训练深度神经网络。
-
由于合成数据和真实数据之间的差距,用合成数据训练出来的模型一旦应用到现实中往往表现不佳。虽然我们意识到真实数据的重要性,但建立一个涵盖所有可能的摄像机视点和带有详细注释的手部姿态的数据集仍然是一个巨大的挑战。为了在没有大型训练数据集的情况下构建功能模型,Baek等人[83]提出了一种利用骨架图将数据添加到骨架空间的方法来合成数据。如图11所示,该模型包括一个手姿估计器(HPE),一个手姿发生器(HPG)和一个手部姿势鉴别器(HPD)。该方法扩展了现有的数据集,提出了一种基于骨架图的深度图数据生成方法。数据生成与模型训练相结合的方法获得了良好的预测效果。但是,此方法仍然对初始化模型的数据集施加一些约束。如果在测试过程中输入的骨架图与数据集中的图有较大的差异,则生成的深度图会出现模糊,从而导致最终的预测结果受影响.
-
Oberweger等人提出一种关节手部-物体姿态估计方法,学习一种合成的CNN,用以合成图像,可以从一大批姿态中生成深度图。Yang和Yao[85]提出了一种方法来更好地处理背景和摄像机视点之间的大差异问题。这项工作提出了使用解纠缠表示和一个解纠缠变分自编码器(dVAE),可以合成高度逼真的图像。Spurr等人[86]开发了一种生成式深度神经网络来学习潜在空间,可以直接用于估计三维手部姿态。
-
一些其他的方法
表格:基于RGB和深度输入的手姿态估计的判别方法综述

表格:基于RGB输入的手姿态估计的判别方法综述。
-
Xu和Cheng[18]使用的是单一深度图像,采用了Hough森林模型的两阶段手部检测方法。首先使用Hough森林模型对手在平面上的方向和三维位置进行初始估计,然后使用另一个Hough森林回归模型,该模型基于第一步获得的手的坐标和方向值,用于计算对平面旋转不变性的深度特征。然后利用手的三维模型生成一组合理的3D候选手势。最后,基于候选姿态,通过求解优化问题进行姿态估计。该方法采用蒙皮网格模型相结合的方法
-
Baek等人[119]提出了一种能够从RGB图像中估计出手的三维骨架结构并从中恢复出手的形状的模型。在他们的工作中,2 d骨架模型被用来预测21联合点,和3 d模型生成网格模型叫马诺[120]代表手网格基于45-dimensional姿态参数和十维形状参数,这是用于一些最近的工作[121122]。该模型由三部分组成,即根据RGB图像计算手的二维骨架坐标的二维证据估计器,计算手的三维网格模型的三维网格估计器,将三维模型信息与手骨架坐标信息相结合,获得三维手关节坐标的投影仪。Zhang等人的另一项研究[123]通过预先训练的LSTM网络预测了当前的手姿态,这是一种有趣的生成手姿态的方法“手部模型”来自以往的经验。
两种设备方法各有优势和劣势。基于视觉的传感器通常不要求用户佩戴任何可能妨碍空闲手的设备运动;这在一些现实世界的应用中特别重要,比如康复,一个微妙的工具操作。然而,基于视觉的传感器需要摄像机始终能看到手对背景噪声敏感;数据手套之类的可穿戴设备大多是自给自足的,但是移动受限制。因此,这两种类型的传感器在手持姿态是互补的,以及更普遍的智能人机交互。
数据集和评价指标
1.数据集
| 数据集 | 发布时间 | 图像数量 | 类别数 | 关节数 | 标记方式 | 视角 | 尺寸 |
|---|---|---|---|---|---|---|---|
| ASTAR | 2013 | 870 | 30 | 20 | 自动 | 3 | 320*240 |
| Dexter 1 | 2013 | 2137 | 1 | 5 | 手动 | 2 | 320*240 |
| MSRA14 | 2014 | 2400 | 6 | 21 | 手动 | 3 | 320*240 |
| ICVL | 2014 | 17604 | 10 | 16 | 半自动 | 3 | 320*240 |
| NYU | 2014 | 81009 | 2 | 36 | 半自动 | 3 | 640*480 |
| MSRA15 | 2015 | 76375 | 9 | 21 | 半自动 | 3 | 640*480 |
| MSRC | 2015 | 102000 | 1 | 22 | 合成 | 3 | 512*424 |
| MSHD | - | 101k | - | 22 | 合成 | - | - |
| HandNet | 2015 | 212928 | 10 | 6 | 自动 | 3 | 320*240 |
| BigHand2.2M | 2017 | 2.2M | 10 | 21 | 自动 | 3 | 640*480 |
| FHAD | 2018 | 105459 | 6 | 21 | 半自动 | 1 | 640*480 |
| OpenPose | - | 16k | - | 21 | 手工 | - | - |
| STB | - | 18000f | - | 21 | - | - | - |
| RHD | - | 4386 | - | 21 | 合成 | - | - |
2.评价指标
3D 手势姿态估计方法的评价指标主要包括:
-
平均误差: 在测试集图像中,所有预测关节点的平均误差距离; 以 21 个手势关节点模型为例,会生成 21 个单关节点平均误差评测值,对 21 个单关节点平均误差求均值,得到整个测试集的平均误差.
-
良好帧占比率: 在一个测试图像帧中,若最差关节点的误差值在设定的阈值范围内,则认为该测试帧为良好帧,测试集中所有的良好帧之和占测试集总帧数的比例,称为良好帧占比率.
其中,第 1 个评价指标反映的是单个关节点预测精准度,平均误差越小,则说明关节定位精准度越高; 第 2 个评价指标反映的是整个测试集测试结果的好坏,在一定的阈值范围内,单个关节的错误定位将造成其他关节点定位无效,该评价指标可以更加严格反映手势姿态估计方法的好坏。
基于深度图像手势姿态估计方法
深度图像具有良好的空间纹理信息,其深度值仅与手部表面到相机的实际距离相关,对手部阴影、光照、遮挡等影响因素具有较高的鲁棒性. 基于深度学习和深度图像的手势姿态估计方法属于数据驱动,通过训练大量的数据来学习一个能表示从输入的深度图像到手部关节点坐标位置的映射关系,并依据映射关系预测出每个关节点的概率热图或者直接回归出手部关节点的二维或者三维坐标.
1.简单2D深度图像(重点)
机器学习:
- C.Xu等人提出随机森林直接从手部深度图像中回归出手势关节点角度
深度学习:
-
Tompson等人使用卷积神经网络应用于手势姿态估计任务中,使用卷积神经网络生成代表深度图像中手部关节二维概率分布的热图,先从每幅二维热图中分别定位到手部关节点的2D平面位置,再使用基于模型的逆运动学原理从预估的2D平面关节点和其对应的深度值估计出相对应的关节点三维空间位置。【手部存在遮挡时,无法获取关键点位置】
-
Ge等人提出将手部深度图像投影到三视图上,从多个视图的热图中恢复出手部关节点的三维空间位置。
表格总结如下:
| 算法名称 | 提出时间 | 算法特点 | 平均误差(NYU ICVL MSRA15) |
|---|---|---|---|
| ConvNet | 2014 | 首次应用CNN,关节点二维热图,逆运动学模型 | - - - |
| REN | 2017 | 区域检测网络,检测三维关键点位置 | 13.39 7.63 |
| DeepPrior++ | 2017 | 数据增强 残差网络 | 12.24 8.10 9.50 |
| Multi-View-CNN | 2018 | 多视图定位三维手势关键点位置 | 12.50 - 9.70 |
| DenseReg | 2018 | 逐像素估计,关节点二三维热图,单位矢量场 | 10.20 7.30 7.20 |
| Pose-REN | 2019 | 迭代预测三维关键点位置 | 11.81 6.79 8.65 |
| JGR-P20 | 2020 | 逐像素估计,图卷积网络 | 8.29 6.02 7.55 |
2.基于3D体素数据
表格总结如下:
| 算法名称 | 提出时间 | 算法特点 | 平均误差(NYU ICVL MSRA15) |
|---|---|---|---|
| 3DCNN | 2017 | 首次应用3DCNN,体素化,3D卷积神经网络,检测关节点三维位置 | 14.10 - 9.60 |
| improved-3DCNN | 2018 | 在上述方法基础上,利用完整手部表面作为网络模型中间监督,提升预测精准度 | 10.60 6.70 7.90 |
| V2V-PoseNet | 2019 | 体素网格到体素网格映射,避免透视失真,体素投票机制,检测关节点三维位置 | 8.42 6.28 7.59 |
3.基于3D点云数据
表格总结如下:
| 算法名称 | 提出时间 | 算法特点 | 平均误差(NYU ICVL MSRA15) |
|---|---|---|---|
| HandPoint-Net | 2018 | 直接处理点云,指尖关节修正,直接回归三维坐标 | 10.54 6.94 8.50 |
| PointttoPoint | 2018 | 双层堆叠分层PointNet,检测三维关节点位置 | 9.10 6.30 7.70 |
| PointtoPose | 2019 | PEL等值替换,残差网络,检测三维关键点位置 | 8.99 - - |
| So-HandNet | 2019 | 半监督学习,有效减少了数据集标注难度 | 11.20 7.70 - |
| Cascaded-PointNet | 2019 | 改善点云采样策略,使用级联PointNet细化关键点位置 | 8.48 - 8.40 |
总结和展望
1.准确性
手势姿态估计准确性的影响因素主要有两个,一个是训练集质量,另一个是所使用的方法. 现阶段主流方法都是基于深度学习,不同的神经网络模型都存在各自的优势与不足,这些方法模型都是基于大量图像数据在神经网络中训练而来,训练集质量的好坏会直接影响手势姿态估计准确性,而现有的数据集中,手势图像往往存在分辨率低、手部遮挡、视角不一致、手势复杂和标记错误等现象,限制了手势姿态估计准确性进一步提高. 因此,如何获得高质量、高精度标记的手势训练集是未来的一个重要研究方向.
2.可移植性
一方面,在现有的基于深度学习手势姿态估计方法中,绝大部分都依赖高性能计算机硬件设备来维持其高效性,这导致手势姿态估计技术无法很好地移植到移动设备如手机中,阻碍了手势姿态估计技术的进一步发展; 另一方面,现有的手势姿态估计方法都是基于特定的图像采集设备,且所使用的方法模型参数与深度相机硬件参数有关,这导致一种手势姿态估计方法只能适用于特定参数的深度相机,无法很好地移植到其他类型的深度相机中,如何有效移植也是未来手势姿态估计亟需解决的问题.
3.实用性
目前,大部分手势姿态估计方法为了精准分割局部手势图像,均在理想条件下只对单手进行姿态估计,默认手部图像背景单一且无遮挡等因素影响. 而在现实生活中环境复杂多变且双手协同操作的情形居多,如双手交互和手物交互,这导致在复杂环境中对存在双手交互或者手物交互的人手分割难度加大; 此外,由于深度相机图像采集距离限制,无法很好地应用于室外远距离手势姿态估计,单目 RGB 相机在户外能很好地捕捉手部图像,但由于 RGB 图像缺少深度信息无法很好地进行高效、准确的 3D 手势姿态估计。 因此,在复杂环境下实现双手交互或者手物交互,是 3D 手势姿态估计未来发展的趋势.
-
可穿戴传感器(或数据手套)有望实现精确和无干扰的手部建模,因为它们通常设计紧凑,对于灵巧的手部运动来说,它们变得更轻、更不麻烦。然而,仍有三个主要挑战有待解决。大多数数据手套仍处于“实验室”阶段,此类设备的设计和制造尚无行业标准,这导致现有商业产品成本高昂,难以负担日常使用。第二,除了基于拉伸传感器的手套外,大多数手套的尺寸都是固定的,而且很困难。
-
另一方面,基于视觉的方法克服了常见计算机视觉任务所面临的许多困难,如旋转、缩放和光照不变性,以及杂乱的背景。手部姿态表征的高维特性,甚至手部自遮挡,不再是实现实时精确手部姿态估计的障碍。然而,基于视觉的方法仍然面临以下挑战:
首先,遮挡仍然是主要问题。由于手在日常生活中被广泛用于操作物体,在交互过程中很容易被物体遮挡或部分遮挡形成手-物体交互(HOI)问题。已经有一些努力来处理物体遮挡。例如,Tekin等人[127]提出了一种端到端架构,从以自我为中心的RGB图像联合估计3D手和物体姿态。Myanganbayar等人[128]提出了一个具有挑战性的数据集,包括与148个对象交互的手,作为HOI的新基准。
其次,由于许多方法是数据驱动的,训练数据集的质量和覆盖是非常重要的。正如第4.4节所讨论的,已经有许多带有2D/3D注释的有用数据集。然而,更多的注释数据来自合成模拟。现有的方法试图采用弱监督学习、迁移学习或不同的数据增强方法来更好地应对现实世界数据的不足,但需要更多的数据来代表巨大的视点、形状、光照、背景变化和交互中的对象。
此外,大多数基于深度学习的方法在训练和推理阶段也需要大量的计算资源。许多算法需要运行在图形处理单元(GPU)上才能实现实时帧率,这使得它很难部署到移动设备(如手机和平板电脑)上。因此,在移动平台上为无处不在的应用寻找有效、高效的解决方案是非常重要的。
-
综上所述,各种各样的设备和方法已经使手姿态估计在可控环境中用于不同的应用目的,我们离实时、高效和普遍的手建模已经不远了。在不久的将来,需要材料科学和电子学的专业知识来制造易于佩戴和维护,但更经济的数据手套用于精确的手部建模。对于基于视觉的方法,需要使用数据高效的方法,如弱监督学习或混合方法,以减少对大型手位数据集的依赖,并提高对不可见情况的泛化能力。此外,我们已经看到了新的传感器的好处,例如深度传感器,因为它们可以通过使用2D数据来推断3D姿态,极大地降低计算复杂度;因此,新型精确的远程三维传感器必将为非接触式手部姿态估计做出贡献。
参考
- 【1】王丽萍,汪成,邱飞岳,章国道.深度图像中的3D手势姿态估计方法综述[J].小型微型计算机系统,2021,42(06):1227-1235.
- 【2】Chen, W. , et al. “A Survey on Hand Pose Estimation with Wearable Sensors and Computer-Vision-Based Methods.” Sensors 20.4(2020):1074.