【图论算法】邻接表、链式前向星、搜索、最短路、最小生成树、并查集、拓扑排序
纯属原创,半年前复习图论写得笔记,应该比较适合新手学习, 代码仅提供引发思路作用,部分地方代码可能又不足之处,也希望有大佬能够补充
本文涉及:图的存储(领接矩阵、邻接表、链式前向星),图的搜索(dfs和bfs)、最短路(Floyd、Dj、贝尔曼福特算法、SPFA算法)、并查集、Kruskal算法、拓扑排序
图
基本概念
图论(Graph Theory)是离散数学的一个分支,是一门研究图(Graph)的学问。
图是用来对对象之间的成对关系建模的数学结构,由"节点"或"顶点"(Vertex)以及连接这些顶点的"边"(Edge)组成。
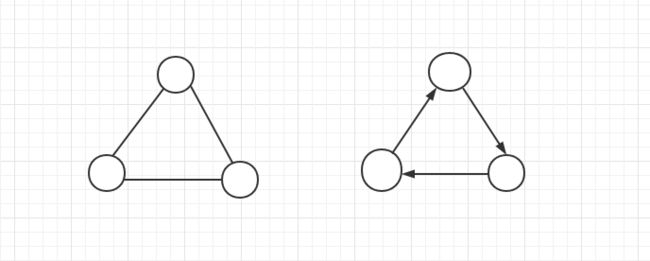
值得注意的是,图的顶点集合不能为空,但边的集合可以为空。图可能是无向的,这意味着图中的边在连接顶点时无需区分方向。否则,称图是有向的。下面左图是一个典型的无向图结构,右图则属于有向图。本章节介绍的图都是无向图。
图的分类:无权图和有权图,连接节点与节点的边是否有数值与之对应,有的话就是有权图,否则就是无权图。
**图的连通性:**在图论中,连通图基于连通的概念。在一个无向图 G 中,若从顶点 i 到顶点 j 有路径相连(当然从j到i也一定有路径),则称 i 和 j 是连通的。如果 G 是有向图,那么连接i和j的路径中所有的边都必须同向。如果图中任意两点都是连通的,那么图被称作连通图。如果此图是有向图,则称为强连通图(注意:需要双向都有路径)。图的连通性是图的基本性质。
**完全图:**完全是一个简单的无向图,其中每对不同的顶点之间都恰连有一条边相连。
**自环边:**一条边的起点终点是一个点。
**平行边:**两个顶点之间存在多条边相连接。
**入度:**指向某一个点
**出度:**某个点指出
图的表示 – 存图
邻接矩阵
1 表示相连接,0 表示不相连。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4yuVNbE2-1662459467641)(G:\TY\图\graph-02.png)]
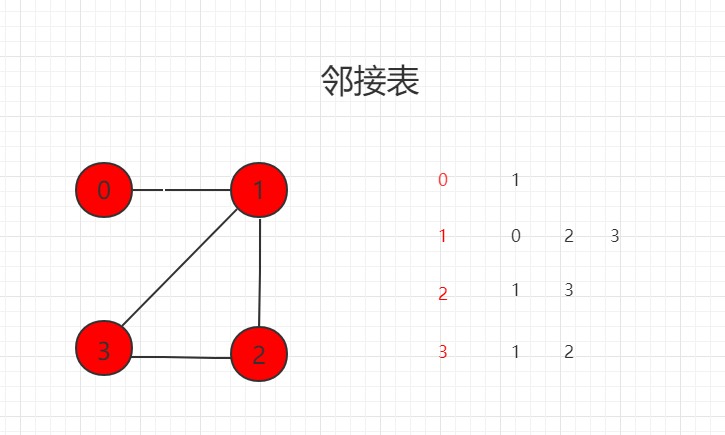
#include 邻接表(进阶,初学请先熟练邻接矩阵)
只表达和顶点相连接的顶点信息
#include 边集数组
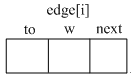
#include 链式前向星(进阶后再看)
 +
+
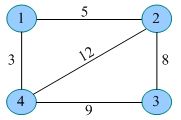
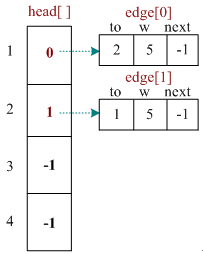
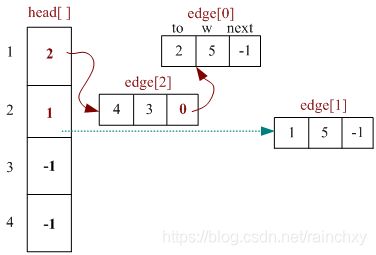
typedef struct edge{
int to;//终点
int w;//权重
int next;//兄弟结点在e数组中的下标
}edge;
//这里使用动态数组,使用普通数组也是可以的
vector<edge>e;
vector<int>head;//建议从1开始存,其值是指向一个e的下标
//后面可以用vector练习一下
#include 图的遍历(假设你已经存好图)
深度优先搜索
邻接矩阵
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LRuNGrXj-1662459467642)(G:\TY\图\graph-02.png)]
0->1->2->3(按照顺序)
//我们注意一下
//这里我们得分几种情况
// 当走到某一个点后,这个点我们走没走过?
// 这个点能不能走?
//这两个问题
//对于第一个问题:用一个数组 book来标记,如果走过,就回到上一步,避免重复走环(死循环)
//第二个,更简单了直接判断数组 !a[i][j] 那就不走
//
int book[n];//标记这个点有没有走过
void dfs(int pos){
// if(book[pos]) return ;//如果这个点走过,则返回
cout<<pos<<endl;
book[pos]=true; //这道题就不用回溯了
for(int i=0;i<n;i++){
if(!book[i]&&a[pos][i]){
dfs(i);
}
}
}
邻接表
int book[n];//标记这个点有没有走过
vector<vector<int> >edge;
void dfs(int pos){
// if(book[pos]) return ;//如果这个点走过,则返回
cout<<pos<<endl;
book[pos]=true; //这道题就不用回溯了
for(int i=0;i<a[pos].size();i++){
if(!book[a[pos][i]]){
dfs(a[pos][i]);
}
}
}
链式前向星
typedef struct Edge{
int to;
int w;
int next;
}Edge;
Edge e[10000];
int head[10000];
bool book[10000];
void dfs(int pos){
// if(book[pos])return ;
cout<<pos<<endl;
book[pos]=true;
for(int i=head[pos];i+1;i=e[i].next){
int v=e[i].to;
if(!book[v]){
dfs(v);
}
}
}
广度优先搜索
邻接矩阵
#include 邻接表
自己试着写写(小伙伴们可以补充,当时比较懒,没写,现在也不想写哈哈)
链式前向星
自己试着写写(小伙伴们可以补充,当时比较懒,没写,现在也不想写哈哈)
稠密图与稀疏图
一个图中,顶点数 n 边数 m
当 n 2 > > m n^2>>m n2>>m 时,我们称之为稀疏。(点多边少)
当m相对较大时,我们称之为稠密。(点和边差不多)
最短路径算法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bGkV93VD-1662459467643)(G:\TY\图\image-20220324003354535.png)]
Floyd - 多源最短路
三个for循环,找个中间点,松弛(更新最短路)每一个点
for(int k=0;k<n;k++)
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
if(a[i][j]>a[i][k]+a[k][j])
a[i][j]=a[i][k]+a[k][j];
优点:三个for完了以后可以取出任意两点之间的最短路径 可以有负权
缺点:时间复杂度很大
适用情况:稠密图且数据量不是很大的时候
思想:dp算法(动态规划)
Dijkstra - 迪杰斯特拉单源最短路
Dijkstra算法(后面简称dj算法),基本思想是贪心。
比如我们要找到1到各个点的最短路径,那我们不妨把一设为源点
我们每次通过找离源点最近的其他点(贪心思想)来松弛(专业术语,你可以理解为更新)源点到其他点的最短路径。
比如像下面这个图
在此之前,我们定义一个数组dis,把1到每个点的距离存进去
| i | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| dis[i] | 0 | 5 | 1 | INF | INF |
我们先找离1最近的点,是3
通过3来松弛1->4的距离 松弛以后
d i s [ 4 ] = m i n ( d i s [ 4 ] , d i s [ 3 ] + a [ 3 ] [ 4 ] ) = 3 dis[4]=min(dis[4],dis[3]+a[3][4])=3 dis[4]=min(dis[4],dis[3]+a[3][4])=3
| i | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| dis[i] | 0 | 5 | 1 | 3 | INF |
这个时候我们继续找离1最近的点,这个时候3已经找过了,只有4
我们通过dis[4]进行松弛(原则上到不了的点以及距离本来就较短的点也会算入松弛,我就不写了)
d i s [ 2 ] = m i n ( d i s [ 2 ] , d i s [ 4 ] + a [ 4 ] [ 2 ] ) = 4 dis[2]=min(dis[2],dis[4]+a[4][2])=4 dis[2]=min(dis[2],dis[4]+a[4][2])=4
d i s [ 5 ] = m i n ( d i s [ 5 ] , d i s [ 2 ] + a [ 4 ] [ 5 ] ) = 8 dis[5]=min(dis[5],dis[2]+a[4][5])=8 dis[5]=min(dis[5],dis[2]+a[4][5])=8
这一轮松弛完了,继续
| i | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| dis[i] | 0 | 4 | 1 | 3 | 8 |
那接下来,就靠2来松弛
d i s [ 3 ] = m i n ( d i s [ 3 ] , d i s [ 2 ] + a [ 2 ] [ 3 ] ) = 1 dis[3]=min(dis[3],dis[2]+a[2][3])=1 dis[3]=min(dis[3],dis[2]+a[2][3])=1
d i s [ 4 ] = m i n ( d i s [ 4 ] , d i s [ 2 ] + a [ 2 ] [ 4 ] ) = 3 dis[4]=min(dis[4],dis[2]+a[2][4])=3 dis[4]=min(dis[4],dis[2]+a[2][4])=3
d i s [ 5 ] = m i n ( d i s [ 5 ] , d i s [ 2 ] + a [ 2 ] [ 5 ] ) = 7 dis[5]=min(dis[5],dis[2]+a[2][5])=7 dis[5]=min(dis[5],dis[2]+a[2][5])=7
| i | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| dis[i] | 0 | 4 | 1 | 3 | 7 |
我们可以发现,有n个点,那我们就要进行n-1轮松弛
下面是代码:
邻接矩阵
#include
dis[j]=dis[u]+a[u][j];
}
}
cout<<dis[n];
}
邻接表
#include 前向星
#include 堆优化的dj
堆优化也就是在找离源点最近的点的时候采用最小堆
#include 练习题 史东薇尔城
J-史东薇尔城_2022年中国高校计算机大赛-团队程序设计天梯赛(GPLT)上海理工大学校内选拔赛 (nowcoder.com)
AC代码:
#include Bell-Man Ford -贝尔曼福特单源最短路
贝尔曼福特算法使用边集数组,通过边集数组直接找
#include SPFA - 贝尔曼福特算法队列优化
SPFA算法 - SHHHS - 博客园 (cnblogs.com)
源点->找邻点->入队->松弛并记录
#include 并查集
把很多个具有相同特点的元素,合并成一个集合来考虑
把 1和2 合并(按照右归左的规定)
如果在这个时候,我们要把3和2合并,那这个时候2到底是属于1还是属于3,但明显我们要两个都属于
那么我们可以 把3和1合并
也就是把祖宗指向新进来的元素
试想一下,把2和4合并和把4和2合并又该怎么做?
方法:
①初始化
②找祖宗
③合并
先说说初始化,我们先定义一个普通的一维数组a[n],并且使得 a [ i ] = i a[i]=i a[i]=i
int a[100];
void init(){
for(int i=0;i<100;i++) a[i]=i;
}
找祖宗的算法怎么写?
我们定义一个函数,如果说一个数a[i]是祖宗,那么他的值一定是i
像上面的图
| a[i] | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| i | 3 | 3 | 3 | 4 |
这是经过了合并以后的,那现在来看看找祖宗函数该怎么写
int find(int x){
//如果找到祖宗,则返回祖宗编号
if(a[x]==x) return x;
//否则 继续向上找,并把每个中间结点的父亲都变成祖宗
return a[x]=find(a[x]);
}
那合并怎么写?
看代码
bool merrge(int x,int y){
//如果两个数本就是一个集合,那就直接return;
int _posx=find(x);
int _posy=find(y);
if(_posx==_posy) return false;//没有进行合并或者说之前已经合并过,返回false
//思考:为何不直接if(a[x]==a[y]) return;
a[_posx]=_posy;
return true;
}
当全部合并完成后有什么用?
看有几个团体,如果合并后a[i]==i,那算一个
下面来讲讲并查集的用法之一
图的最小生成树(Kruskal算法)
生成树(spanning tree) :一个连通无向图的生成子图,同时要求是树。也即在图的边集中选择n-1条,将所有顶点连通。
一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的最少的边。
我们可以通过排序,或者用堆,每次取出权值最小的来加上。
这里,我们采取边集数组存储
#include 拓扑排序
在图论中,拓扑排序(Topological Sorting)是一个有向无环图(DAG, Directed Acyclic Graph)的所有顶点的线性序列。且该序列必须满足下面两个条件:
每个顶点出现且只出现一次。
若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。
有向无环图(DAG)才有拓扑排序,非DAG图没有拓扑排序一说。
算法导论上这样说:
对于一个有向无环图 G= (V,E) 来说,其拓扑排序是 中所有结点的一种线性次序,该次序满足如下条件:如果图 含边 (u, v), 则结点 在拓扑排序中处于结点 的前面(如果图 包含环路,则不可能排出一个 线性次序)。可以将图的拓扑排序看做是将图的所有结点在一条水平线上排开,图的所有有向边 都从左指向右。因此,拓扑排序与本书第二部分所讨论的通常意义上的"排序”是不同的。
先说一下拓扑排序的步骤:
- 将所有入度为0的点入队
- 从图中删除该顶点和以该顶点为起点的边
- 去掉后如果入读为0则入队
#include 部分内容参考:https://blog.csdn.net/lisonglisonglisong/article/details/45543451
《算法导论 - 原书第3版译》
更多知识可以看看我的博客哟~ https://www.wzl1.top/