python计算机视觉第10章----OpenCV
文章目录
- 1、OpenCV基础
-
- 1.1 图像的读写
- 1.2 计算积分图像
- 1.3 泛洪填充
- 1.4 提取 SURF 特征
- 2、视频处理
-
- 2.1 视频输入
- 2.2 视频模糊
- 2.3 视频读取
- 3、视频追踪
-
- 3.1 光流追踪
- 3.2 Lucas-Kanade算法跟踪器
本章概述如何通过 Python 接口使用流行的计算机视觉库 OpenCV。OpenCV 是一个C++ 库,用于(实时)处理计算视觉问题。实时处理计算机视觉的 C++ 库,最初由英特尔公司开发,现由 Willow Garage 维护。下面,我们会讲解一些基本的例子并深入了解视频与跟踪。
1、OpenCV基础
1.1 图像的读写
读取一幅图像并输出图像的大小:
import cv2
#读入图像
im = cv2.imread('d:/imdata1/library2.jpg')
#打印图像尺寸
h, w = im.shape[:2]
print (h, w)
#保存原jpg格式的图像为png格式图像
cv2.imwrite('d:/imdata1/library2.png',im)
cv2.imshow("Image", im)
cv2.waitKey()
结果如下:
![]()

1.2 计算积分图像
通过OpenCV提供的integral函数计算积分图像:
import cv2
from pylab import *
#读入图像
im = cv2.imread('d:/imdata1/library2.jpg')
#转为灰度图像
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
#显示积分图像
fig = plt.figure()
subplot(121)
plt.gray()
imshow(gray)
axis('off')
#计算积分图像
intim = cv2.integral(gray)
#归一化
intim = (255.0*intim) / intim.max()
#显示积分图像
subplot(122)
plt.gray()
imshow(intim)
axis('off')
show()
#用OpenCV显示图像
cv2.imshow("Image", intim)
cv2.waitKey()
#用OpenCV保存积分图像
cv2.imwrite('d:/imdata1/library7.jpg', intim)
#保存figure中的灰度图像和积分图像
fig.savefig("d:/imdata1/library7.png")
原图的灰度图像及积分图像如下图所示:

1.3 泛洪填充
泛洪填充的原理很简单,就是从一个点开始,将附近满足像素要求的点全部填充成指定的颜色,直到封闭区域内的所有像素点都被填充新颜色为止。实现代码如下:
import cv2
import numpy
from pylab import *
#读入图像
filename = 'd:/imdata1/library2.jpg'
im = cv2.imread(filename)
#转换颜色空间
rgbIm = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
#显示原图
fig = plt.figure()
subplot(121)
plt.gray()
imshow(rgbIm)
axis('off')
#获取图像尺寸
h, w = im.shape[:2]
#泛洪填充
diff = (6, 6, 6)
mask = zeros((h+2, w+2), numpy.uint8)
cv2.floodFill(im, mask, (10, 10), (255, 255, 0), diff, diff)
#显示泛洪填充后的结果
subplot(122)
imshow(im)
axis('off')
show()
fig.savefig("d:/imdata1/library8.png")

floodFill共包含6个参数:
1.操作的图像
2.掩模
3.起始的像素点
4.填充的颜色
5.loDiff:填充颜色的低值(起始像素点处颜色减去该值)
6.upDiff:填充颜色的高值 (起始像素点处颜色加上该值)
1.4 提取 SURF 特征
在之前我们已经学过了SIFT算法,SIFT算法对旋转、尺度缩放、亮度变化等保持不变性,对视角变换、仿射变化、噪声也保持一定程度的稳定性,是一种非常优秀的局部特征描述算法。但是其实时性相对不高。
SURF(Speeded Up Robust Features)算法改进了特征了提取和描述方式,用一种更为高效的方式完成特征点的提取和描述。SURF算法采用快速Hessian算法检测关键点,而SURF算子会通过一个特征向量来描述关键点周围区域的情况。
具体步骤为:
- 尺度空间的极值检测:搜索所有尺度空间上的图像,通过Hessian来识别潜在的对尺度和选择不变的兴趣点。
- 特征点过滤并进行精确定位。
- 特征方向赋值:统计特征点圆形邻域内的Harr小波特征。即在60度扇形内,每次将60度扇形区域旋转0.2弧度进行统计,将值最大的那个扇形的方向作为该特征点的主方向。
- 特征点描述:沿着特征点主方向周围的邻域内,取4×44×4个矩形小区域,统计每个小区域的Haar特征,然后每个区域得到一个4维的特征向量。一个特征点共有64维的特征向量作为SURF特征的描述子。
下面来看一个简单的例子:
import cv2
import numpy
from pylab import *
#读入图像
im = cv2.imread('../data/empire.jpg')
#下采样
im_lowres = cv2.pyrDown(im)
#转化为灰度图像
gray = cv2.cvtColor(im_lowres, cv2.COLOR_RGB2GRAY)
#检测特征点
#s = cv2.SURF() ##AttributeError: module 'cv2.cv2' has no attribute 'SURF'
s = cv2.xfeatures2d.SURF_create() ##卸载高版本opencv-pyhton和opencv-contribute- python安装3.4.2.16版本
mask = numpy.uint8(ones(gray.shape))
keypoints = s.detect(gray, mask)
#显示图像及特征点
vis = cv2.cvtColor(gray, cv2.COLOR_GRAY2BGR)
for k in keypoints[::10]: ##每隔10个像素取1个
cv2.circle(vis, (int(k.pt[0]), int(k.pt[1])), 2, (0, 255, 0), -1)
cv2.circle(vis, (int(k.pt[0]), int(k.pt[1])), int(k.size), (0, 255, 0), 2)
cv2.imshow('local descriptors', vis)
cv2.waitKey()
cv2.imwrite('../images/ch10/ch10_P232_Fig10-3.jpg',vis)

2、视频处理
2.1 视频输入
OpenCV能够很好地支持从摄像头中读取视频,具体代码如下:
import cv2
#setup video capture
cap = cv2.VideoCapture(0)
while True:
ret,im = cap.read()
cv2.imshow('video test',im)
key = cv2.waitKey(10)
if key == 27:
break
if key == ord(' '):
cv2.imwrite('d:/imdata2/vid_result.jpg',im)
执行上述程序后,我们即可从摄像头捕捉视频,点击空格即可保存该视频帧,按下Esc即退出应用。
2.2 视频模糊
import cv2
#setup video capture
cap = cv2.VideoCapture(0)
#get frame, apply Gaussian smoothing, show result
while True:
ret, im = cap.read()
blur = cv2.GaussianBlur(im, (0, 0), 5)
cv2.imshow('camera blur', blur)
if cv2.waitKey(10) == 27:
break
通过GaussianBlur()函数,我们可以对图像进行模糊,具体效果如下:

2.3 视频读取
使用OpenCV可以从文件中读取视频帧并将其转为数组,下面我们从摄像头捕获视频并将其存储在数组中:
from numpy import *
import cv2
#setup video capture
cap = cv2.VideoCapture(0)
frames = []
#get frame, store in array
while True:
ret, im = cap.read()
cv2.imshow('video', im)
frames.append(im)
if cv2.waitKey(10) == 27:
break
frames = array(frames)
#check the sizes
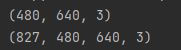
print(im.shape)
print(frames.shape)
最终得到的数组中包含了视频的帧数、帧高、帧宽及颜色通道数等信息:
3、视频追踪
3.1 光流追踪
光流(optical flow)是空间运动物体在观察成像平面上的像素运动的瞬时速度。光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。
光流法主要依赖于三个假设:
- 亮度恒定。同一目标的像素强度在连续帧之间不发生改变。
- 时间规律。短时间内或者相邻帧间目标位置的变化不会剧烈。
- 空间一致性。相邻像素具有相似的运动
一个像素I(x,y,t)在第一帧的光强度(其中t代表其所在的时间维度)。它移动了 (dx,dy)的距离到下一帧,用了dt时间。因为是同一个像素点,根据第一个假设我们认为该像素在运动前后的光强度是不变的,即: I ( x , y , t ) = I ( x + d x , y + d y , t + d t ) I(x,y,t)=I(x+dx,y+dy,t+dt) I(x,y,t)=I(x+dx,y+dy,t+dt)将 I ( x + d x , y + d y , t + d t ) I(x+dx,y+dy,t+dt) I(x+dx,y+dy,t+dt)泰勒展开得: I ( x + d x , y + d y , t + d t ) = I ( x , y , t ) + ∂ I ∂ x d x + ∂ I ∂ y d y + ∂ I ∂ t d t + ϵ I(x+dx,y+dy,t+dt)=I(x,y,t)+\frac{∂I}{∂x}dx+\frac{∂I}{∂y}dy+\frac{∂I}{∂t}dt+ϵ I(x+dx,y+dy,t+dt)=I(x,y,t)+∂x∂Idx+∂y∂Idy+∂t∂Idt+ϵ因为ϵ为极小值,故: ∂ I ∂ x d x + ∂ I ∂ y d y + ∂ I ∂ t d t = 0 \frac{∂I}{∂x}dx+\frac{∂I}{∂y}dy+\frac{∂I}{∂t}dt=0 ∂x∂Idx+∂y∂Idy+∂t∂Idt=0同除dt,有 ∂ I ∂ x d x d t + ∂ I ∂ y d y d t + ∂ I ∂ t = 0 \frac{∂I}{∂x}\frac{dx}{dt}+\frac{∂I}{∂y}\frac{dy}{dt}+\frac{∂I}{∂t}=0 ∂x∂Idtdx+∂y∂Idtdy+∂t∂I=0令 u = d x d t , v = d y d t , I x = ∂ I ∂ x , I y = ∂ I ∂ y , I t = ∂ I ∂ t u=\frac{dx}{dt},v=\frac{dy}{dt},I_x=\frac{∂I}{∂x},I_y=\frac{∂I}{∂y},I_t=\frac{∂I}{∂t} u=dtdx,v=dtdy,Ix=∂x∂I,Iy=∂y∂I,It=∂t∂I,原式可化为: I x u + I y v + I t = 0 I_xu+I_yv+I_t=0 Ixu+Iyv+It=0其中, ( u , v ) (u,v) (u,v)为像素速度,也就是光流。
但是只有一个约束方程,无法确定光流(u,v)的值,在Lucas-Kanade算法中,通过强制加入空间一致性约束获得该方程的解。
在学习Lucas-Kanade算法之前,我们先来看一个在视频中寻找运动矢量的例子:
from numpy import *
import cv2
def draw_flow(im,flow,step=16):
""" Plot optical flow at sample points
spaced step pixels apart. """
h,w = im.shape[:2]
y,x = mgrid[step/2:h:step,step/2:w:step].reshape(2,-1).astype(int)
fx,fy = flow[y,x].T
# create line endpoints
lines = vstack([x,y,x+fx,y+fy]).T.reshape(-1,2,2)
lines = int32(lines)
# create image and draw
vis = cv2.cvtColor(im,cv2.COLOR_GRAY2BGR)
for (x1,y1),(x2,y2) in lines:
cv2.line(vis,(x1,y1),(x2,y2),(0,255,0),1)
cv2.circle(vis,(x1,y1),1,(0,255,0), -1)
return vis
#setup video capture
cap = cv2.VideoCapture(0)
ret,im = cap.read()
prev_gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
while True:
# get grayscale image
ret,im = cap.read()
gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
# compute flow
flow = cv2.calcOpticalFlowFarneback(prev_gray,gray,None,0.5,3,15,3,5,1.2,0)
prev_gray = gray
# plot the flow vectors
cv2.imshow('Optical flow',draw_flow(gray,flow))
if cv2.waitKey(10) == 27:
break
3.2 Lucas-Kanade算法跟踪器
Lucas-Kanade跟踪算法是视觉跟踪中一个很经典的基于点的逐帧跟踪算法,其基本思想为:给定一个模板和一个输入 I I I,以及一个或多个变换 W W W,求一个参数最佳的变换 W W W,使得 ∑ x [ I ( W ( x ; p + Δ p ) ) − T ( x ) ] 2 \sum_{x}[I(W(x;p+Δp))−T(x)]^2 ∑x[I(W(x;p+Δp))−T(x)]2的值最小。
具体步骤为:
1.初始化参数向量 p p p
2.计算 ∑ x [ I ( W ( x ; p + Δ p ) ) − T ( x ) ] 2 \sum_{x}[I(W(x;p+Δp))−T(x)]^2 ∑x[I(W(x;p+Δp))−T(x)]2及其关于 p p p导数,求得参数增量向量 Δ p Δp Δp
3.更新 p p p, p = p + Δ p p=p+Δp p=p+Δp
4.若 Δ p Δp Δp小于某个小量,即当前参数向量 p p p基本不变化了,那么停止迭代,否则继续2,3两步骤。
下面建立一个跟踪类:
from numpy import *
import cv2
#some constants and default parameters
lk_params = dict(winSize=(15,15),maxLevel=2,
criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT,10,0.03))
subpix_params = dict(zeroZone=(-1,-1),winSize=(10,10),
criteria = (cv2.TERM_CRITERIA_COUNT | cv2.TERM_CRITERIA_EPS,20,0.03))
feature_params = dict(maxCorners=500,qualityLevel=0.01,minDistance=10)
class LKTracker(object):
""" Class for Lucas-Kanade tracking with
pyramidal optical flow."""
def __init__(self,imnames):
""" Initialize with a list of image names. """
self.imnames = imnames
self.features = []
self.tracks = []
self.current_frame = 0
def step(self,framenbr=None):
""" Step to another frame. If no argument is
given, step to the next frame. """
if framenbr is None:
self.current_frame = (self.current_frame + 1) % len(self.imnames)
else:
self.current_frame = framenbr % len(self.imnames)
def detect_points(self):
""" Detect 'good features to track' (corners) in the current frame
using sub-pixel accuracy. """
# load the image and create grayscale
self.image = cv2.imread(self.imnames[self.current_frame])
self.gray = cv2.cvtColor(self.image,cv2.COLOR_BGR2GRAY)
# search for good points
features = cv2.goodFeaturesToTrack(self.gray, **feature_params)
# refine the corner locations
cv2.cornerSubPix(self.gray,features, **subpix_params)
self.features = features
self.tracks = [[p] for p in features.reshape((-1,2))]
self.prev_gray = self.gray
def track_points(self):
""" Track the detected features. """
if self.features != []:
self.step() # move to the next frame
# load the image and create grayscale
self.image = cv2.imread(self.imnames[self.current_frame])
self.gray = cv2.cvtColor(self.image,cv2.COLOR_BGR2GRAY)
# reshape to fit input format
tmp = float32(self.features).reshape(-1, 1, 2)
# calculate optical flow
features,status,track_error = cv2.calcOpticalFlowPyrLK(self.prev_gray,self.gray,tmp,None,**lk_params)
# remove points lost
self.features = [p for (st,p) in zip(status,features) if st]
# clean tracks from lost points
features = array(features).reshape((-1,2))
for i,f in enumerate(features):
self.tracks[i].append(f)
ndx = [i for (i,st) in enumerate(status) if not st]
ndx.reverse() #remove from back
for i in ndx:
self.tracks.pop(i)
self.prev_gray = self.gray
def track(self):
""" Generator for stepping through a sequence."""
for i in range(len(self.imnames)):
if self.features == []:
self.detect_points()
else:
self.track_points()
# create a copy in RGB
f = array(self.features).reshape(-1,2)
im = cv2.cvtColor(self.image,cv2.COLOR_BGR2RGB)
yield im,f
def draw(self):
""" Draw the current image with points using
OpenCV's own drawing functions.
Press ant key to close window."""
# draw points as green circles
for point in self.features:
cv2.circle(self.image,(int(point[0][0]),int(point[0][1])),3,(0,255,0),-1)
cv2.imshow('LKtrack',self.image)
cv2.waitKey()
初始化一个对象来使用我们创建的跟踪器:
imnames = ['D:\\Python\\bt.003.pgm', 'D:\\Python\\bt.002.pgm','D:\\Python\\bt.001.pgm', 'D:\\Python\\bt.000.pgm']
#创建跟踪对象
lkt = lktrack.LKTracker(imnames)
#在第一帧进行检测,跟踪剩下的帧
lkt.detect_points()
lkt.draw()
for i in range(len(imnames)-1):
lkt.track_points()
lkt.draw()
由于版本原因,没有成功,在此借用一下书上的图:


每次画出一帧并显示当前跟踪到的点,按任意键会转移到序列的下一帧。上图显示了牛津corridor 序列的前 4 幅图像的跟踪结果。
创建一个发生器,遍历整个序列并将获得的跟踪点和这些图像以 RGB 数组保存,画出跟踪结果,代码如下:
def track(self):
""" 发生器,用于遍历整个序列 """
for i in range(len(self.imnames)):
if self.features == []:
self.detect_points()
else:
self.track_points()
#创建一份 RGB 副本
f = array(self.features).reshape(-1,2)
im = cv2.cvtColor(self.image,cv2.COLOR_BGR2RGB)
yield im,f
import lktrack
import cv2
import numpy as np
from pylab import *
from PIL import Image
imnames = ['D:\\Python\\bt.003.pgm', 'D:\\Python\\bt.002.pgm', 'D:\\Python\\bt.001.pgm', 'D:\\Python\\bt.000.pgm']
#用 LKTracker 发生器进行跟踪
lkt = lktrack.LKTracker(imnames)
for im,ft in lkt.track():
print ('tracking %d features' % len(ft))
#画出轨迹
figure()
imshow(im)
for p in ft:
plot(p[0],p[1],'bo')
for t in lkt.tracks:
plot([p[0] for p in t],[p[1] for p in t])
axis('off')
show()
结果如下:
