CE-Net: Context Encoder Network for 2D Medical Image Segmentation
CE-Net: Context Encoder Network for 2D Medical
Image Segmentation
发表期刊:IEEE Transactions on Medical Imaging(中科院SCI一区)
发表时间:2019年
Abstract
医学图像分割是医学图像分析的重要步骤。随着卷积神经网络在图像处理领域的迅速发展,深度学习已被用于医学图像分割,如视盘分割、血管检测、肺分割、细胞分割等。然而,连续的池化和跨步卷积操作会导致一些空间信息的丢失。本文提出了一种上下文编码器网络(简称CE-Net),以获取更多的高层信息,并保留二维医学图像分割的空间信息。**CENet主要由三个主要组件组成:特征编码器模块、上下文提取器模块和特征解码器模块。我们使用预先训练好的ResNet块作为固定的特征提取器。上下文提取器模块由新提出的密集Atrus卷积(DAC)块和残差多核池化(RMP)块组成。**我们将所提出的CE-Net应用于不同的二维医学图像分割任务。综合实验结果表明,该方法在视盘分割、血管检测、肺部分割、细胞轮廓分割和视网膜光学相干层析成像层分割等方面均优于原U-net方法和其他先进的分割方法。
Introduction
医学图像分割通常是医学图像分析中的一个重要步骤,例如视网膜图像中的视盘分割[1]、[2]、[3]和血管检测[4]、[5]、[6]、[7]、[8],电子显微镜(EM)记录中的细胞分割[9]、[10]、[11],肺分割[12]、[13]、[14]、[15]、[16]和脑分割[17]、[18]、[19]、[20],[21]、[22]在计算机断层扫描(CT)和磁共振成像(MRI)中。以前的医学图像分割方法通常基于边缘检测和模板匹配[15]。例如,圆形或椭圆形霍夫变换用于视盘分割[23]、[3]。模板匹配还用于MRI序列图像中的脾脏分割[24]和脑CT图像中的心室分割[22]。
已经提出了一种用于医学图像分割的形变模型。对于心脏MRI图像的二维分割和前列腺MRI图像的三维分割,已经提出了基于水平集的基于形状的分割方法[25]。此外,还提出了一种基于水平集的变形模型从腹部CT图像中分割肾脏[26]。可变形模型还与Gibbs先验模型集成,用于分割器官边界[27],使用进化算法和统计形状模型从CT体积分割肝脏[16]。在视盘分割中,也提出并采用了不同的变形模型,如数学形态学模型、全局椭圆模型、局部变形模型[28]和改进的活动形状模型[29]。
提出了基于学习的医学图像分割方法。Aganjet等[30]提出了基于局部质心的无监督学习的X射线和MRI图像分割方法。KAnimozhiet et.[31]应用平稳小波变换得到特征向量,并采用自组织映射对这些特征向量进行处理,用于无监督MRI图像分割。Tonget al.[32]结合字典学习和稀疏编码来分割腹部CT图像中的多器官。基于像素分类的方法[33]、[1]也是基于学习的方法,其使用预先注释的数据来训练基于像素的分类器。然而,要从大量的像素中选择像素并提取特征来训练分类器并非易事。程等人[1]使用超像素策略来减少像素数,并使用超像素分类进行视盘和视杯的分割。Tian等人[34]采用了一种基于超像素的图割方法来分割3D前列腺MRI图像。在[35]中,将基于超像素学习的方法与形状约束的受限区域相结合,从CT图像中分割出肺部。
这些方法的缺点在于使用手工制作的特征来获得分割结果。一方面,很难为不同的应用设计具有代表性的特征。另一方面,在一种类型的图像上工作良好的设计功能在另一种类型的图像上常常失败。因此,缺乏一种通用的特征提取方法。
随着卷积神经网络(CNN)在图像和视频处理领域[36]和医学图像分析领域[37]、[38]的发展,基于深度学习的自动特征学习算法已经成为医学图像分割的可行方法。基于深度学习的分割方法是基于像素分类的学习方法。与传统的像素或超像素分类方法通常使用手工特征不同,深度学习方法学习特征,克服了手工特征的局限性。
早期的医学图像分割深度学习方法大多是基于图像块的。Ciresanet等人[39]提出了一种基于patch和滑动窗口的显微图像神经细胞膜分割方法。然后,Kamnitsaset al.[40]采用了一种具有完全连通条件随机场(CRF)的多尺度3D CNN架构来增强基于patch的脑损伤分割。显然,这种解决方案引入了两个主要缺点:滑动窗口带来的冗余计算和无法学习全局特征。
随着端到端完全卷积网络(FCN)[41]的出现,Ronnebergeret等人在[10]中提出了用于生物医学图像分割的uShape Net(U-net)框架。U-net在电子显微镜记录中的神经元结构分割和光镜图像中的细胞分割方面取得了良好的效果。它已经成为生物医学图像分割任务的一种流行的神经网络结构[42],[43],[44],[45]。塞瓦斯托波尔斯卡[43]应用U-net直接分割视网膜眼底图像中的视盘和视杯,用于青光眼诊断。Royer al.[44]在光学相干断层扫描(OCT)图像中使用了类似的网络进行视网膜层分割。Normanet等人[42]使用U-net从膝关节MRI数据中分割软骨和半月板。U-net还被应用于直接从CT图像中分割肺部[45]。
对于不同的医学图像分割任务,U-Net已经做了很多变化。Fuet et al.[4]采用CRF来收集多阶段特征图,以提高船只检测性能。随后,通过在U-Net框架中加入多尺度输入和深度监督,提出了一种改进的U-Net框架(称为M-Net)[2],用于视盘和视杯的联合分割。深度监督主要引入与中期特征相关的额外损失函数。在深度监督的基础上,Chen等[46]提出了Voxresnet来分割体积脑,Douet等[47]提出了3D深度监督网络(3D DSN)来自动分割CT体积中的肺。
为了增强U-Net的特征学习能力,提出了一些新的模块来代替原有的模块。Stefan oset et.[48]提出了一种分支残差U-Net(BRU-Net)来分割病理性OCT视网膜层,用于老年性黄斑变性的诊断。BRU-net依靠残余连接和扩张卷积来增强最终的OCT视网膜层分割。Gibsonet等人[49]在每个编码块中引入了密集连接,以便在腹部CT上自动分割多个器官。Kumaret al.[21]提出了一种用于婴儿大脑MRI分割的InfiNet。除了上述基于U-Net的医学图像分割的研究成果外,一些研究人员还对U-Net进行了改进,使之适用于一般的图像分割。Penget等人[50]提出了一种改进语义分割的全局卷积网络。Linet等人[51]提出了一种多路径精化网络,它包括残差卷积单元、多分辨率融合和链式残差池化。赵等人[52]采用空间金字塔汇集的方法对提取的特征图进行聚集,提高了语义分割的性能。
U-Net及其变体的一个共同限制是连续的池化操作或卷积跨度降低了特征分辨率以学习日益抽象的特征表示。虽然这种不变性对分类或目标检测任务是有益的,但它经常阻碍需要详细空间信息的密集预测任务。直观地说,在中间阶段保持高分辨率特征图可以提高分割性能。但是,这增加了特征图的大小,不利于加快训练速度,减轻优化的难度。因此,在加速训练和保持高分辨率之间存在权衡。一般来说,U网结构可以看作是编解码器结构。编码器的目标是逐步降低特征地图的空间维度,捕捉更多的高层语义特征。解码器的目的是恢复物体的细节和空间维度。因此,在编码器中捕捉更多的高层特征,在解码器中保留更多的空间信息,以提高图像分割的性能是自然而然的。
基于上述讨论,以及神经网络更宽更深的InceptionResNet结构[53]、[54],我们提出了一种新的使用Arous卷积的Dense Arous卷积(DAC)块。原有的UNET架构通过在编码路径中采用连续的3×3卷积和池化操作,在有限的缩放范围内捕获多尺度特征。我们提出的DAC块通过向四个级联分支注入多尺度的Arous卷积,可以捕捉到更广泛和更深层次的语义特征。在该模块中,利用剩余连接来防止梯度消失。此外,我们还提出了一种基于空间金字塔池化的残差多核池化算法(RMP)[55]。RMP块还通过采用各种大小池化操作对从DAC模块提取的对象的多尺度上下文特征进行编码,而不需要额外的学习权重。综上所述,DAC块用于通过多尺度Arous卷积提取丰富的特征表示,RMP块用于进一步的上下文信息的多尺度池化操作。将新提出的DAC块和RMP块与主干编解码器结构相结合,提出了一种新的上下文编码器网络CENet。它依靠DAC块和RMP块来提取更抽象的特征,保留更多的空间信息,从而提高医学图像分割的性能。
这项工作的主要贡献总结如下:
- 我们提出了DAC块和RMP块来捕捉更多的高层特征并保留更多的空间信息。
- 我们将所提出的DAC块和RMP块与编解码器结构相结合,用于医学图像分割。
- 我们将该方法应用于视盘分割、视网膜血管检测、肺分割、细胞轮廓分割和视网膜OCT层分割等不同的任务中。结果表明,在这些不同的任务中,所提出的方法比最先进的方法具有更好的性能。
本文的其余部分组织如下。第二部分详细介绍了所提出的方法。第三部分给出了实验结果和讨论。在第四节中,我们得出了一些结论。
Method
所提出的CE-Net由三个主要部分组成:特征编码器模块、上下文提取器模块和特征解码器模块,如图1所示。
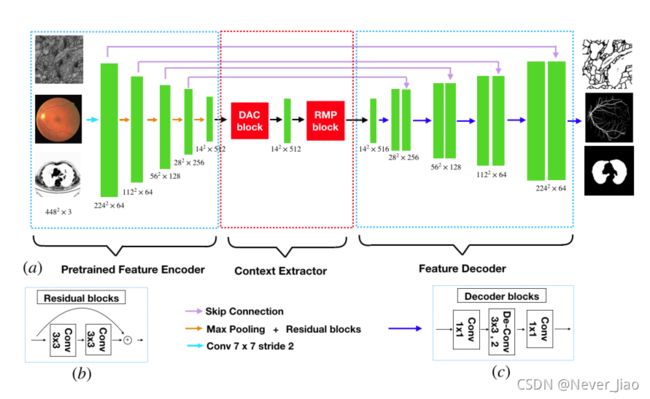
图1.提出的CE-NET图示。首先,将图像送入特征编码器模块,由ImageNet预先训练的ResNet-34块代替原来的U-Net编码块。上下文提取器用于生成更多的高层语义特征图。它包含一个密集ATROS卷积(DAC)块和一个残差多核池化(RMP)块。最后,将提取的特征送入特征解码模块。在本文中,我们采用解码块来扩大特征尺寸,取代了原来的上采样操作。解码块包含1×1卷积和3×3反卷积运算。基于跳跃连接和解码块,我们得到掩码作为分割预测图。
Feature Encoder Module
在U-Net结构中,每个编码器块包含两个卷积层和一个最大池化层。**在该方法中,我们在特征编码模块中用预先训练好的ResNet-34[53]代替它,它保留了前四个特征提取块,没有平均池化层和完全连通层。**与原来的块相比,ResNet增加了捷径机制,避免了梯度消失,加速了网络收敛,如图1(b)所示。为方便起见,我们使用带有预先训练的ResNet的改进的U-Net作为主干方法。
Context Extractor Module
上下文提取器模块是一个新提出的模块,由DAC块和RMP块组成。该模块提取上下文语义信息,生成更多高层特征图。
Atrous convolution
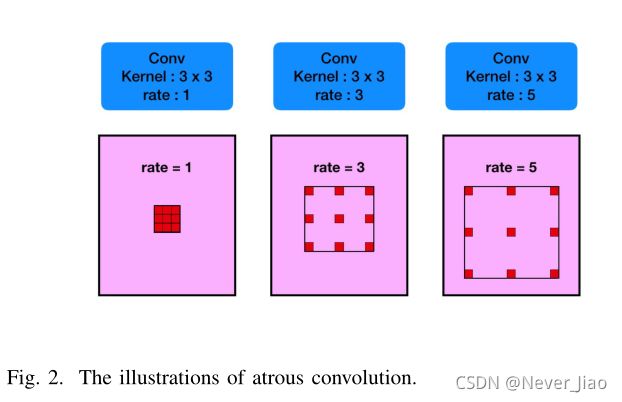
在语义分割任务和目标检测任务中,深卷积层被证明是提取图像特征表示的有效方法。然而,池化会导致图像中语义信息的丢失。为了克服这一限制,采用Atrous卷积进行密集分割[56]:
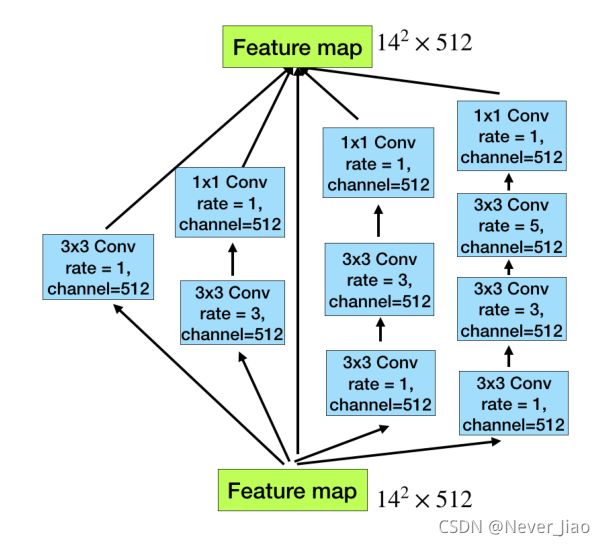
图3.Dense Atrous卷积块的图示。该网络包含4个级联分支,随着Arous卷积次数的递增,从1到1、3、5,则每个分支的感受野分别为3、7、9、19。因此,该网络可以从不同的尺度提取特征。
Arous卷积最初是为了提高小波变换的计算效率而提出的。在数学上,二维信号下的Atrous卷积计算如下:
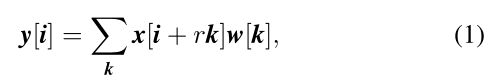
其中,输入特征图与滤波器的卷积产生输出,而atrous rate对应于我们采样输入信号的步长。它相当于将输入与上采样滤波器卷积,该上采样滤波器是通过在沿每个空间维度的两个连续滤波器值之间插入r−1个零而产生的(因此被命名为Atrus卷积,其中法语单词Arous在英语中的意思是孔)。标准卷积是rate=1的特例,而Arous卷积允许我们通过更改rate值自适应地修改滤波器感受野。如图2所示。
Dense Atrous Convolution module
Inception[54]和ResNet[53]是深度学习中的两个经典的、有代表性的体系结构。初始系列结构采用不同的感受野来拓宽体系结构。相反,ResNet采用快捷连接机制来避免梯度的爆炸和消失。它使神经网络首次突破数千层。Inception-ResNet[54]块结合了Inception和ResNet,继承了这两种方法的优点。从而成为深层CNN领域的一种基线研究方法。
如图3所示,Artous卷积以级联模式堆叠。在这种情况下,DAC有四个级联分支,随着Atrus卷积数目的逐渐增加,从1到1、3和5,则每个分支的感受场将分别为3、7、9、19。它使用不同的感受场,类似于初始结构。在每条Atracs分支中,我们应用1×1卷积来校正线性激活。最后,我们直接将原有的特征添加到其他特征中,如ResNet中的快捷机制。由于所提出的块看起来像一个紧密相连的块,我们将其命名为Dense Arous卷积块。通常情况下,大感受野的卷积可以为大目标提取和产生更多的抽象特征,而小感受野的卷积更适合于小目标。通过组合不同atrous速率的atrous卷积,DAC块能够提取不同大小对象的特征。
Residual Multi-kernel pooling
医学图像中的目标大小变化很大,这是分割中的一个挑战。例如,中晚期的肿瘤可能比早期的要大得多。为了解决这一问题,本文提出了一种残差多核池化算法,该算法主要依靠多个有效的感受野来检测不同大小的目标。
感受野的大小大致决定了我们可以使用多少语境信息。一般的最大池化操作只使用一个池化内核,如2×2。如图4所示,RMP使用4个不同大小的感受野(2×2、3×3、5×5和6×6)对全局上下文信息进行编码。四级输出包含不同大小的特征映射。为了减少权值的维数和计算量,我们在每一层池化之后使用1×1的卷积。它将特征地图的维度降低到原始维度的1N,其中N表示原始特征地图中的通道数。然后通过双线性插值对低维特征图进行上采样,得到与原始特征图相同大小的特征。最后,将原始特征与上采样特征图进行拼接。
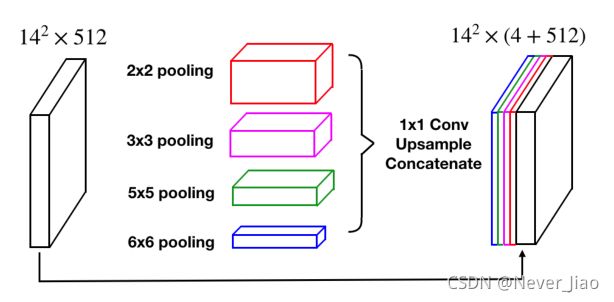
图4残差多内核池化(RMP)策略的图示。所提出的RMP使用四个不同大小的池化内核来收集上下文信息。然后将特征送入1×1卷积,以降低特征地图的维数。最后,将上采样特征与原始特征进行拼接。
Feature Decoder Module
特征解码器模块用于恢复从特征编码模块和上下文提取模块提取的高层语义特征。跳跃连接将一些详细信息从编码器带到解码器,以弥补由于连续的池化和跨步卷积操作造成的信息丢失。类似于[48],我们采用了一个有效的块来提高译码性能。在U型网络中,简单的上采样和反卷积是解码器的两种常见操作。上采样使用线性插值来增加图像大小,而反卷积(也称为转置卷积)使用卷积操作来放大图像。直观地说,转置卷积可以学习自适应映射来恢复具有更详细信息的特征。因此,我们选择使用转置卷积来恢复解码器中较高分辨率的特征。如图1©所示,它主要包括1×1卷积、3×3转置卷积和1×1卷积。基于跳跃连接和解码器块,特征解码模块输出与原始输入相同大小的掩码。
Loss Function
我们的框架是一个端到端的深度学习系统。如图1所示,我们需要训练所提出的方法来预测每个像素是前景还是背景,这是一个像素分类问题。最常见的损失函数是交叉熵损失函数。
然而,医学图像中的视盘、视网膜血管等物体在图像中往往占据很小的区域。对于这样的任务,交叉熵损失并不是最优的。在本文中,我们用Dice系数损失函数[57]、[58]来代替常用的交叉熵损失。以下部分还进行了对比实验和讨论。Dice系数是重叠的量度,广泛用于在已知ground truth的情况下评估分割性能,如公式(2)所示
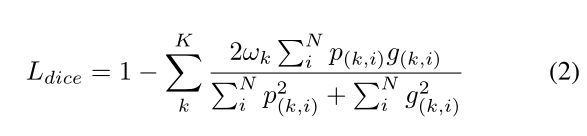
其中N是像素数,p(k,i)∈[0,1]和g(k,i)∈{0,1}分别表示类k的预测概率和ground truth 标签,k是类号,∑kωk=1是类权重。在本文中,我们经验地设定了ωk=1/k。
最终的loss函数定义为:
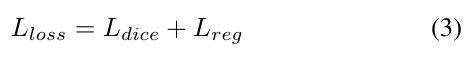
其中Lrega表示用于避免过拟合的正则化损失(也称为权重衰减)[59]。
为了评估CE-Net的性能,我们将该方法应用于五种不同的医学图像分割任务:视盘分割、视网膜血管检测、肺分割、细胞轮廓分割和视网膜OCT层分割。
Experiment
Experimental Setup
在这一部分中,我们首先介绍在训练和测试阶段使用的图像预处理和数据增强策略。
Training phase
由于训练图像的数量有限,数据集被扩充以降低过度拟合的风险[36]。首先,我们进行数据增强,包括水平翻转、垂直翻转和对角翻转。以这种方式,原始数据集中的每个图像被增加到2×2×2=8个图像。其次,图像预处理的解决方案主要包括90%到110%的缩放、HSV颜色空间的颜色抖动和图像的随机平移。该随机图像预处理方法可以增强数据增强能力。
Testing phase
为了提高医学图像分割方法的鲁棒性,我们还采用了测试增强策略,如[60]、[61]中的方法,包括图像水平翻转、垂直翻转和对角翻转(相当于预测每幅图像8次)。然后对8个预测值进行平均,得到最终的预测图。所有基线方法在测试阶段都使用相同的策略。
Experiment settings
我们提出的网络是基于在ImageNet上预先训练的ResNet。实现基于公共PyTorch平台。训练测试台为Ubuntu 16.04系统,采用NVIDIA GeForce Titan显卡,内存为12G。
在训练过程中,除了Adam优化外,我们采用了小批量随机梯度下降算法,批大小为8,动量为0.9,权值衰减为0.0001。我们使用SGD优化,因为最近的研究[62][63]表明,SGD通常获得更好的性能,尽管Adam优化的收敛速度更快。此外,我们使用多学习率策略,其中学习率乘以![]()
,power=0.9和初始学习率4e-3 ITER3[52]。最大的epoch是100。我们已经在Github1上发布了我们的代码https://github.com/Guzaiwang/CE-Net。
Optic disc segmentation
我们首先测试了所提出的CE-Net算法在视盘分割中的应用。我们的实验使用了三个数据集,ORIGA[66],Messidor[67]和RIMONE-R1[68]。ORIGA数据集包含650幅图像,尺寸为3072×2048。它分为两组:用于训练的A组和用于测试的B组[69]。在本文中,我们按照相同的数据集划分来训练和测试我们的模型。Messidor数据集是由Messidor项目合作伙伴提供的公共数据集。它由1200张大小不同的图像组成:1440×960、2240×1488、2340×1536。Messidor数据集最初是为糖尿病视网膜病变(DR)分级而收集的。随后,官方网站2也提供了每张图片的盘片边界。RIM-One数据集由三个版本组成。图像数量分别为169张、455张和159张。本文使用的是首次发布的数据集(RIM-ONE-R1),RIM-ONE-R1数据集中有五种不同的专家标注。我们按照[70]中的划分获得Messidor和RIM-One-R1数据集中的训练和测试图像。应该注意的是,ORIGA和Messidor数据集提供完整图像,而RIM-One-R1提供裁剪后的图像。
为了根据视网膜眼底图像的原始分辨率分割视盘,我们按照[71]中提出的方法,在最亮点附近裁剪800×800个区域,除了RIM-One-R1数据集,其中包含视盘的区域已经被裁剪和提供。
为了评估性能,我们采用了常用的重叠误差来评估视盘分割的准确性:
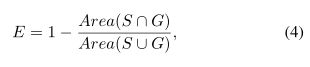
其中S和G分别表示分割后的ground truth视盘和手动分割的视盘。除了平均值,我们还计算了相应的标准差。
我们将我们的方法与最先进的算法进行了比较。比较了五种不同的算法,包括超像素分类法[1]、U-Net法[10]、M-Net法[2]、faster RCNN法[72]和DeepDisc法[65]。所有基线模型都是从其原始实现中采用的。
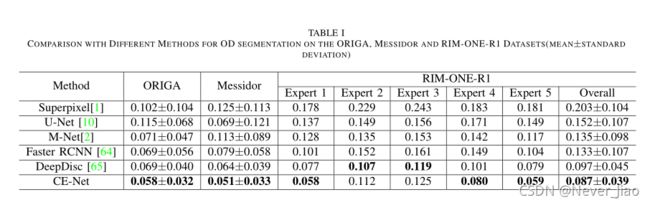
表I显示了这些方法的重叠误差的平均值和标准差。正如我们所看到的,所提出的CE-Net算法的性能优于目前最先进的光盘分割方法。特别是,它在ORIGA数据集中实现了0.058的重叠误差,与最新的faster RCNN或DeepDisc方法的0.069相比,相对减少了15.9%。在Messidor数据集上,CE-NET的重叠误差为0.051,比DeepDisc的0.064相对降低了20.3%.。RIM-One-R1数据集有五个独立的注释。在我们的实验中,我们遵循[70]中的相同设置来使用交叉验证来获得结果。虽然与专家2和专家3的注释相比,CE-Net的性能略逊于DeepDisc,但总体结果仍然表明CE-Net的性能优于DeepDisc和其他方法。
我们还给出了图5中的四个示例结果,以直观地将我们的方法与一些有竞争力的方法进行比较,包括基于超像素的方法、M-Net方法和DeepDisc方法。实验结果表明,该方法获得了更准确的分割结果。

图5.示例结果。从左到右:原始眼底图像、基于超像素的方法[1]、M-Net[2]、DeepDisc[65]、CE-Net和ground truth mask获得的最新结果。
Retinal Vessel Detection
第二个应用是视网膜血管检测。我们使用包含40个图像的公共驱动器 [73]数据集。在驱动器中,提供了两个专家手册注释,文献[4]中选择第一个作为性能评估的基础事实。这40幅图像被分为20幅用于训练的图像和20幅用于测试的图像。为了比较血管检测的性能,我们计算了敏感度(SEN)和准确度(ACC)这两个评价指标,这两个指标也在[4][6] 中进行了计算。
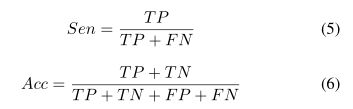
其中TP、TN、FP和FN分别表示真阳性、真阴性、假阳性和假阴性的数量。此外,我们还引入了接收器工作特征曲线下面积(AUC)来衡量分割性能。
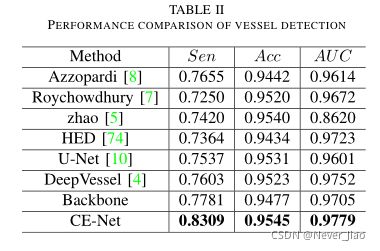
我们将所提出的CE-Net算法与目前最先进的算法[5]、[8]、[7]进行了比较。此外,还比较了一些经典的基于深度学习的方法[74]、[10]、[4]。表二显示了这些方法之间的比较。通过比较,CE-Net分别达到了0.8309、0.9545和0.9779的INSEN、ACCADAUC,优于其他方法。与主干相比,TES从0.7781提高到0.8309提高了6.8%,Acc从0.9477增加到0.9545,AUC从0.9705增加到0.9779,这表明所提出的DAC和RMP块同样有利于视网膜血管的检测。我们在图6中给出了一些直观比较的例子。
Lung segmentation
下一个应用是肺部分割任务,即从Luna肺结节分析大赛的二维CT图像中分割肺部结构。Luna大赛最初是针对以下挑战赛道进行的:结节检测和减少假阳性。因为分割的肺是进一步的肺结节候选的基础,所以我们采用挑战数据集来评估我们提出的CE-Net。该数据集包含534个2D样本(512×512像素)以及各自的标签图像,可以从官方网站3免费下载。我们将80%的图像用于训练,其余的用于测试,并进行交叉验证。评价指标包括重叠误差、准确度和灵敏度,类似于视盘分割和血管检测。在表III中,除了计算平均值外,还计算了相应的标准差。
从表III的对比中可以看出,CE-Net的重叠误差达到0.038,敏感度得分达到0.8309,准确度得分达到0.9545,优于U-Net。我们还将CE-Net与主干进行了比较,重叠误差从0.044降低到0.038,敏感度从0.967提高到0.980,准确率从0.988提高到0.990,进一步支持了我们提出的DAC块和RMP块对肺分割是有利的。在图6中,我们还给出了几个肺分割的可视比较的例子。
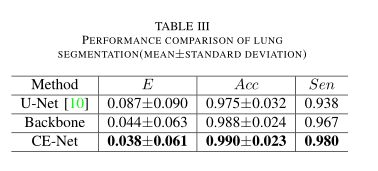
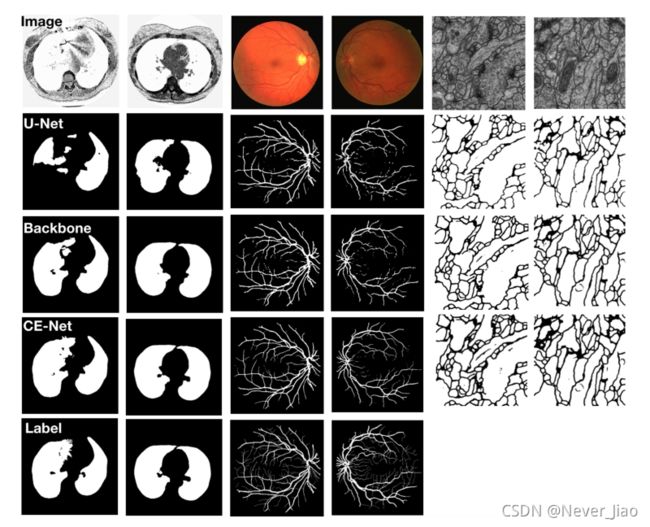
图6.肺分割、血管检测和细胞轮廓分割的样本结果。从上到下:原始图像、U-Net、backbone、CE-Net和ground truth(细胞图像的地面实况未给出)。
Cell contour segmentation
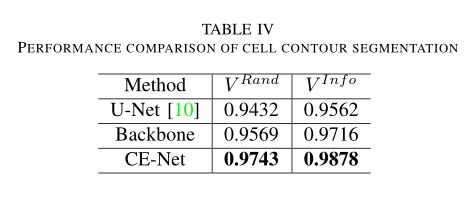
第四个应用是细胞轮廓分割。细胞分割的任务是分割电子显微镜记录中的神经元结构。该数据集由EM Challenges提供,该挑战始于ISBI 2012,目前仍在接受新的贡献[75]。训练集包含30张图片(512×512像素),可以从官方网站4下载。测试集由30张图片组成,也是公开的。然而,相应的ground truth并不为人所知。测试集上的结果是通过将预测mask发送给组织者获得的,然后组织者将计算并发布结果。从官方网站上的声明来看,以下指标最适合于分割结果的定量评估:边缘细化后的前景受限兰特评分(VRand)和边缘细化后的前景受限信息理论评分(VInf O)。VRand主要通过合并Rand分裂分数和Rand合并分数来计算加权调和均值,用来衡量分割性能。类似地,VInf忽略计算信息论分数的加权调和平均值。分数越高,分割效果越好。这两种算法的具体计算过程和更多细节可以在[76]中找到。
我们将CE-Net与原来的U-Net和backbone进行了比较,最终结果显示在TableIV中。我们的CE-Net性能优于U-Net和主干网。这表明我们提出的CE-Net对于细胞轮廓分割任务是有效的。我们还在图6中给出了几个直观比较的例子,尽管基本事实不可用。
Retinal OCT Layer Segmentation
以上四个应用都是在两类分割问题上进行的,其中我们只需要从背景中分割出地面目标。在本文中,我们还证明了我们的方法适用于多类分割任务。我们以视网膜OCT层分割为例,应用CE-Net对11个视网膜层进行分割[77]。该数据集包含20个3D卷,每个卷有256次2D扫描。人工划分了10个边界,将每个二维图像分为11个部分:边界1对应于内界膜(ILM);神经纤维层和神经节细胞层之间的边界2(NFL/GCL);内网状层和内核层之间的边界3(IPL/INL);内核层和外丛状层之间的边界4(INL/OPL);外网层和外核层之间的边界5(OPL/ONL);边界6。边界8对应内段下界(低IS),外段与视网膜色素上皮(OS/RPE)边界9,Bruchs膜与脉络膜边界10(BM/脉络膜)。为了评价分割效果,我们采用了常用的平均绝对误差[77]来评价视网膜OCT层分割的准确性。
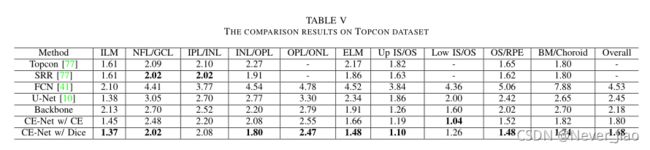
我们将我们提出的方法与一些最先进的OCT层分割方法进行了比较:Topcon内置方法[77]、通过重建减少斑点(SRR)方法[77]、FCN[41]和U-Net[10]。
性能比较汇总在表V中。与U-Net和Backbone方法相比,我们的CENet的总体平均绝对误差为1.68,比2.45和2.18分别相对降低了31.4%和22.9%。与Topcon内置方法和SRR相比,我们的CE-Net在大多数场景下也取得了更好的结果。这表明我们提出的CE-Net也可以应用于多类分割任务。此外,我们还进行了交叉熵损失和Dice损失的对比实验。TableV表明,有Dice损失的CE网优于有交叉熵损失的CE-Net。
我们还给出了图7中的一些示例结果,以直观地将我们的方法与U-Net和主干方法进行比较。图像清晰地显示了CE-Net更准确的分割结果。
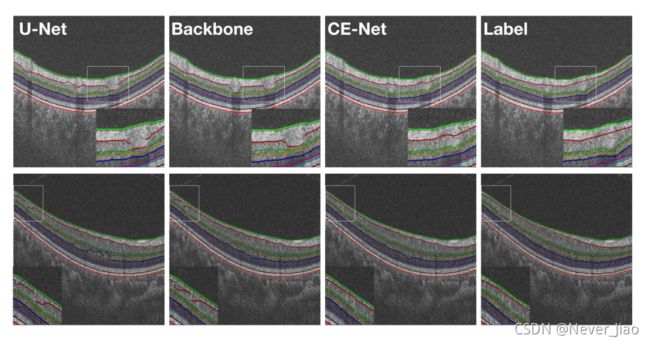
图7.示例结果。从左到右:U-Net、主干、CE-Net和Ground-Truth掩码。不同图层之间的边缘已用彩色线条标记。
Ablation Study
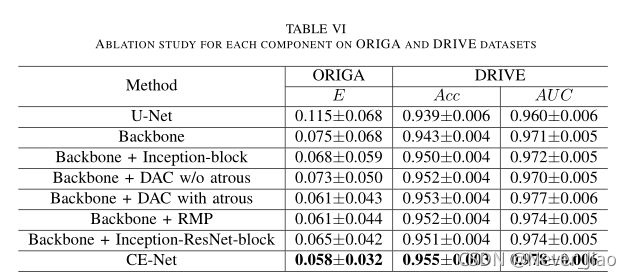
为了证明预先训练的ResNet、DAC和RMP块在所建议的CE-Net中的有效性,我们以ORIGA和DRIVE数据集为例进行了以下消融研究:
Ablation study for adopting pretrained ResNet model:
我们提出的方法是基于U-Net的,因此U-Net是最基本的基线模型。我们使用残差块来代替UNET的原始编码块,目的是增强学习能力。我们称这种带有预训练残差块和特征解码器的改进的U型网络为“主干”。最近的工作[78]指出,ImageNet预训练在很大程度上有助于规避优化问题,从预先训练的权重进行微调比从头开始收敛得更快。我们还进行了实验,将训练前的结果与没有训练的结果进行比较。图8显示了这两种情况下损失的变化。正如我们所看到的,在有预训练的情况下,损失下降得比没有预训练的情况下更快。表VI显示了分割结果。通过采用预先训练好的ResNet模块,主干方法取得了较好的性能。对于OD分割,重叠误差从0.115降低到0.075,降低了34.8%。在视网膜血管检测方面,AcandAUCare分别从0.939和0.960增加到0.943和0.971。结果表明,预先训练的ResNet块是有益的。
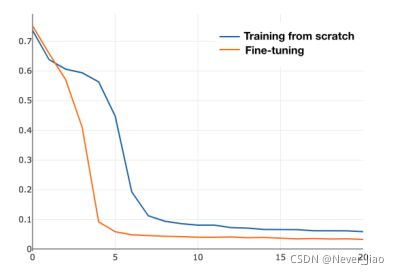
图8.橙色线表示从预先训练的重量进行微调的训练损失,而蓝色表示从头开始的端到端训练损失。
Ablation study for dense atrous convolution block
所提出的DAC块采用不同速率的Atrous卷积,并组装在类似先启块中。因此,我们首先进行实验来验证Arous卷积的有效性。我们使用规则卷积来代替DAC模块中的atrous卷积(称为主干+DAC,不带atrous)。如表六所示,我们提出的数模转换模块(称为主干+带有atrous的数模转换)将OD分割的重叠误差从0.073降低到0.061,降低了16.4%,提高了视网膜血管检测的准确性。这表明,与常规卷积相比,Arous卷积有助于提取高层语义特征。我们还将我们提出的DAC块与常规的初始-V2块(称为主干+初始-块)进行了比较。对比结果表明,DAC块的分割效果优于常规的起始块,OD分割的重叠误差从0.068降低到0.061,相对降低了10.3%。最终,重叠误差从骨干网的0.075降低到0.061(骨干网+数模转换器),降低了18.7%。这表明所提出的DAC块能够进一步提取全局信息以获得高分辨率的高层语义特征图,这对于我们的分割任务是有用的。
Ablation study for residual multi-kernel pooling module
表VI还显示了RMP的效果,它提高了OD分割的性能。带有RMP模块的主干被称为“主干+RMP”。与主干相比,OD分割的重叠误差从0.075分降低到0.061分,重叠误差降低了18.7%;而视网膜血管检测的AUC评分从0.943分和0.971分提高到0.952分和0.974分。RMP模块可以对全局信息进行编码,改变特征地图的组合方式。
Ablation study for network with similar complexity:
研究人员已经证明,复杂性是网络能力的体现[79],复杂性的增加通常会带来更好的性能。因此,人们担心改进可能来自网络复杂性的增加。为了缓解这种担忧,我们将我们的网络与具有类似复杂性的网络进行了比较。在本文中,我们将其与上述由常规的Inception-ResNet-V2块(Backbone+InceptionResNet-Block)支持的主干进行比较。表VI表明,我们的CE-Net具有更好的性能,OD分割的重叠误差从0.065降低到0.058,可接受AUC分数从0.951和0.974提高到0.955和0.978。
Conclusions
医学图像分割是医学图像分析的重要内容。本文提出了一种端到端的深度学习框架CE-Net用于医学图像分割。与U-Net相比,CE-Net在特征编码器中采用了预先训练好的ResNet块。在ResNet改进的UNET结构中,引入了一种新的致密ATORS卷积块和剩余多核池,以捕捉更多的高层特征并保留更多的空间信息。通过使用新的训练数据和人工地面真实数据对模型进行微调,我们的方法可以应用于新的应用。实验结果表明,该方法能够提高医学图像在不同任务中的分割效果,包括视盘分割、视网膜血管检测、肺分割、细胞轮廓分割和视网膜OCT层分割。该方法具有一定的通用性,可推广应用于其他二维医学图像分割任务。在本文中,我们的方法已经在二维图像上得到了验证,三维数据的扩展将是未来可能的工作。