深度学习入门(三十六)计算性能——异步计算、自动并行
深度学习入门(三十六)计算性能——异步计算、自动并行
- 前言
- 计算性能——异步计算
-
- 教材
-
- 1 异步计算
-
- 1.1 通过后端异步处理
- 1.2 小结
- 2 自动并行
-
- 2.1 基于GPU的并行计算
- 2.2 并行计算与通信
- 3.3 小结
前言
核心内容来自博客链接1博客连接2希望大家多多支持作者
本文记录用,防止遗忘
计算性能——异步计算
教材
今天的计算机是高度并行的系统,由多个CPU核、多个GPU、多个处理单元组成。通常每个CPU核有多个线程,每个设备通常有多个GPU,每个GPU有多个处理单元。总之,我们可以同时处理许多不同的事情,并且通常是在不同的设备上。不幸的是,Python并不善于编写并行和异步代码,至少在没有额外帮助的情况下不是好选择。归根结底,Python是单线程的,将来也是不太可能改变的。因此在诸多的深度学习框架中,MXNet和TensorFlow之类则采用了一种异步编程(asynchronous programming)模型来提高性能,而PyTorch则使用了Python自己的调度器来实现不同的性能权衡。对于PyTorch来说GPU操作在默认情况下是异步的。当你调用一个使用GPU的函数时,操作会排队到特定的设备上,但不一定要等到以后才执行。这允许我们并行执行更多的计算,包括在CPU或其他GPU上的操作。
因此,了解异步编程是如何工作的,通过主动地减少计算需求和相互依赖,有助于我们开发更高效的程序。这使我们能够减少内存开销并提高处理器利用率。
import os
import subprocess
import numpy
import torch
from torch import nn
from d2l import torch as d2l
1 异步计算
1.1 通过后端异步处理
作为热身,考虑一个简单问题:我们要生成一个随机矩阵并将其相乘。让我们在NumPy和PyTorch张量中都这样做,看看它们的区别。请注意,PyTorch的tensor是在GPU上定义的。
# GPU计算热身
device = d2l.try_gpu()
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('torch'):
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
输出:
numpy: 1.2837 sec
torch: 0.0010 sec
通过PyTorch的基准输出比较快了几个数量级。NumPy点积是在CPU上执行的,而PyTorch矩阵乘法是在GPU上执行的,后者的速度要快得多。但巨大的时间差距表明一定还有其他原因。默认情况下,GPU操作在PyTorch中是异步的。强制PyTorch在返回之前完成所有计算,这种强制说明了之前发生的情况:计算是由后端执行,而前端将控制权返回给了Python。
with d2l.Benchmark():
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
torch.cuda.synchronize(device)
输出:
Done: 0.0106 sec
广义上说,PyTorch有一个用于与用户直接交互的前端(例如通过Python),还有一个由系统用来执行计算的后端。如图所示,用户可以用各种前端语言编写PyTorch程序,如Python和C++。不管使用的前端编程语言是什么,PyTorch程序的执行主要发生在C++实现的后端。由前端语言发出的操作被传递到后端执行。后端管理自己的线程,这些线程不断收集和执行排队的任务。请注意,要使其工作,后端必须能够跟踪计算图中各个步骤之间的依赖关系。因此,不可能并行化相互依赖的操作。
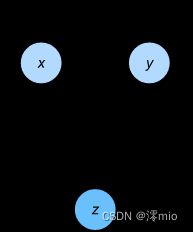
让我们看另一个简单例子,以便更好地理解依赖关系图。
x = torch.ones((1, 2), device=device)
y = torch.ones((1, 2), device=device)
z = x * y + 2
z
输出:
tensor([[3., 3.]], device='cuda:0')
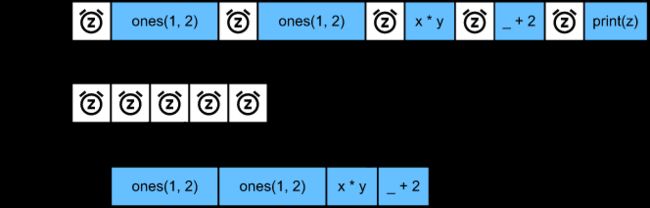
上面的代码片段在图中进行了说明。每当Python前端线程执行前三条语句中的一条语句时,它只是将任务返回到后端队列。当最后一个语句的结果需要被打印出来时,Python前端线程将等待C++后端线程完成变量z的结果计算。这种设计的一个好处是Python前端线程不需要执行实际的计算。因此,不管Python的性能如何,对程序的整体性能几乎没有影响。 下图演示了前端和后端如何交互。
1.2 小结
1、深度学习框架可以将Python前端的控制与后端的执行解耦,使得命令可以快速地异步插入后端、并行执行。
2、异步产生了一个相当灵活的前端,但请注意:过度填充任务队列可能会导致内存消耗过多。建议对每个小批量进行同步,以保持前端和后端大致同步。
3、芯片供应商提供了复杂的性能分析工具,以获得对深度学习效率更精确的洞察。
2 自动并行
深度学习框架(例如,MxNet和PyTorch)会在后端自动构建计算图。利用计算图,系统可以了解所有依赖关系,并且可以选择性地并行执行多个不相互依赖的任务以提高速度。
通常情况下单个操作符将使用所有CPU或单个GPU上的所有计算资源。例如,即使在一台机器上有多个CPU处理器,dot 操作符也将使用所有CPU上的所有核心(和线程)。这样的行为同样适用于单个GPU。因此,并行化对于单设备计算机来说并不是很有用,而并行化对于多个设备就很重要了。虽然并行化通常应用在多个GPU之间,但增加本地CPU以后还将提高少许性能。借助自动并行化框架的便利性,我们可以依靠几行Python代码实现相同的目标。更广泛地考虑,我们对自动并行计算的讨论主要集中在使用CPU和GPU的并行计算上,以及计算和通信的并行化内容。
请注意,我们至少需要两个GPU来运行本节中的实验。
import torch
from d2l import torch as d2l
2.1 基于GPU的并行计算
让我们从定义一个具有参考性的用于测试的工作负载开始:下面的run函数将执行10次“矩阵-矩阵”乘法时需要使用的数据分配到两个变量(x_gpu1和x_gpu2)中,这两个变量分别位于我们选择的不同设备上。
devices = d2l.try_all_gpus()
def run(x):
return [x.mm(x) for _ in range(50)]
x_gpu1 = torch.rand(size=(4000, 4000), device=devices[0])
x_gpu2 = torch.rand(size=(4000, 4000), device=devices[1])
现在我们使用函数来数据。我们通过在测量之前预热设备(对设备执行一次传递)来确保缓存的作用不影响最终的结果。torch.cuda.synchronize()函数将会等待一个CUDA设备上的所有流中的所有核心的计算完成。函数接受一个device参数,代表是哪个设备需要同步。如果device参数是None(默认值),它将使用current_device()找出的当前设备。
run(x_gpu1)
run(x_gpu2) # 预热设备
torch.cuda.synchronize(devices[0])
torch.cuda.synchronize(devices[1])
with d2l.Benchmark('GPU1 time'):
run(x_gpu1)
torch.cuda.synchronize(devices[0])
with d2l.Benchmark('GPU2 time'):
run(x_gpu2)
torch.cuda.synchronize(devices[1])
输出:
GPU1 time: 0.5036 sec
GPU2 time: 0.5141 sec
如果我们删除两个任务之间的synchronize语句,系统就可以在两个设备上自动实现并行计算。
with d2l.Benchmark('GPU1 & GPU2'):
run(x_gpu1)
run(x_gpu2)
torch.cuda.synchronize()
输出:
GPU1 & GPU2: 0.5043 sec
在上述情况下,总执行时间小于两个部分执行时间的总和,因为深度学习框架自动调度两个GPU设备上的计算,而不需要用户编写复杂的代码。
2.2 并行计算与通信
在许多情况下,我们需要在不同的设备之间移动数据,比如在CPU和GPU之间,或者在不同的GPU之间。例如,当我们打算执行分布式优化时,就需要移动数据来聚合多个加速卡上的梯度。让我们通过在GPU上计算,然后将结果复制回CPU来模拟这个过程。
def copy_to_cpu(x, non_blocking=False):
return [y.to('cpu', non_blocking=non_blocking) for y in x]
with d2l.Benchmark('在GPU1上运行'):
y = run(x_gpu1)
torch.cuda.synchronize()
with d2l.Benchmark('复制到CPU'):
y_cpu = copy_to_cpu(y)
torch.cuda.synchronize()
输出:
在GPU1上运行: 0.5064 sec
复制到CPU: 2.4303 sec
这种方式效率不高。注意到当列表中的其余部分还在计算时,我们可能就已经开始将y的部分复制到CPU了。例如,当我们计算一个小批量的(反传)梯度时。某些参数的梯度将比其他参数的梯度更早可用。因此,在GPU仍在运行时就开始使用PCI-Express总线带宽来移动数据对我们是有利的。在PyTorch中,to()和copy_()等函数都允许显式的non_blocking参数,这允许在不需要同步时调用方可以绕过同步。设置non_blocking=True让我们模拟这个场景。
with d2l.Benchmark('在GPU1上运行并复制到CPU'):
y = run(x_gpu1)
y_cpu = copy_to_cpu(y, True)
torch.cuda.synchronize()
输出:
在GPU1上运行并复制到CPU: 1.9874 sec
两个操作所需的总时间少于它们各部分操作所需时间的总和。请注意,与并行计算的区别是通信操作使用的资源:CPU和GPU之间的总线。事实上,我们可以在两个设备上同时进行计算和通信。如上所述,计算和通信之间存在的依赖关系是必须先计算y[i],然后才能将其复制到CPU。幸运的是,系统可以在计算y[i]的同时复制y[i-1],以减少总的运行时间。
最后,我们给出了一个简单的两层多层感知机在CPU和两个GPU上训练时的计算图及其依赖关系的例子。手动调度由此产生的并行程序将是相当痛苦的。这就是基于图的计算后端进行优化的优势所在。
3.3 小结
1、现代系统拥有多种设备,如多个GPU和多个CPU,还可以并行地、异步地使用它们。
2、现代系统还拥有各种通信资源,如PCI Express、存储(通常是固态硬盘或网络存储)和网络带宽,为了达到最高效率可以并行使用它们。
3、后端可以通过自动化地并行计算和通信来提高性能