李宏毅机器学习笔记12:RNN(2)
Recurrent Neural Network(Ⅱ)
上一篇文章介绍了RNN的基本架构,像这么复杂的结构,我们该如何训练呢?
1. Loss Function
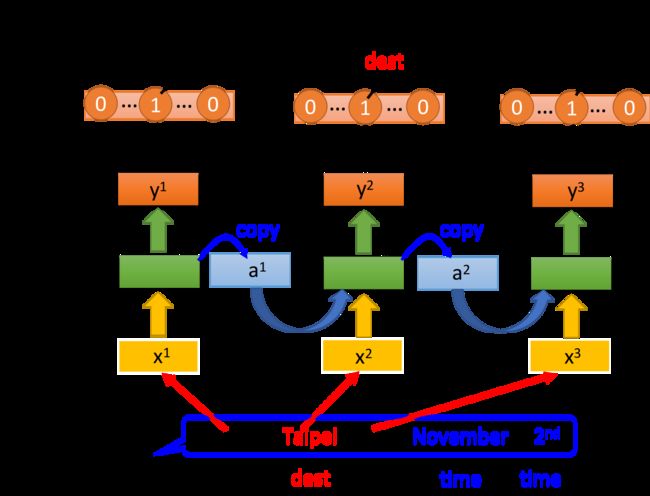
依旧是Slot Filling的例子,我们需要把model的输出 y i y^i yi与映射到slot的reference vector求交叉熵,比如“Taipei”对应到的是“dest”这个slot,则reference vector在“dest”位置上值为1,其余维度值为0
-
RNN的output和reference vector的cross entropy之和就是损失函数,也是要minimize的对象
-
需要注意的是,word要依次输入model,比如“arrive”必须要在“Taipei”前输入,不能打乱语序
2.Training
有了损失函数后,训练其实也是用梯度下降法,为了计算方便,这里采取了反向传播(Backpropagation)的进阶版,Backpropagation through time,简称BPTT算法
BPTT算法与BP算法非常类似,只是多了一些时间维度上的信息

不幸的是,RNN的训练并没有那么容易
我们希望随着epoch的增加,参数的更新,loss应该要像下图的蓝色曲线一样慢慢下降,但在训练RNN的时候,你可能会遇到类似绿色曲线一样的学习曲线,loss剧烈抖动,并且会在某个时刻跳到无穷大,导致程序运行失败

3. Error Surface
分析可知,RNN的error surface,即loss由于参数产生的变化,是非常陡峭崎岖的
下图中, z z z轴代表loss, x x x轴和 y y y轴代表两个参数 w 1 w_1 w1和 w 2 w_2 w2,可以看到loss在某些地方非常平坦,在某些地方又非常的陡峭

想要解决这个问题,就要采用Clipping方法,当gradient即将大于某个threshold的时候,就让它停止增长,比如当gradient大于15的时候就直接让它等于15
为什么RNN会有这种奇特的特性呢?
下图给出了一个直观的解释:
-
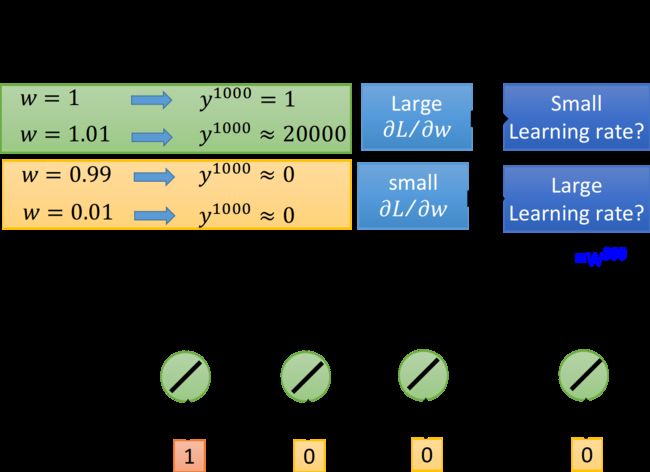
假设RNN只含1个neuron,它是linear的,input和output的weight都是1,没有bias,从当前时刻的memory值接到下一时刻的input的weight是 w w w,按照时间点顺序输入[1, 0, 0, 0, …, 0]
-
当第1个时间点输入1的时候,在第1000个时间点,RNN输出的 y 1000 = w 999 y^{1000}=w^{999} y1000=w999,想要知道参数 w w w的梯度,只需要改变 w w w的值,观察对RNN的输出有多大的影响即可:
- 当 w w w从1->1.01,得到的 y 1000 y^{1000} y1000就从1变到了20000,这表示 w w w的梯度很大,需要调低学习率
- 当 w w w从0.99->0.01,则 y 1000 y^{1000} y1000几乎没有变化,这表示 w w w的梯度很小,需要调高学习率
- 从中可以看出gradient时大时小,error surface很崎岖,尤其是在 w = 1 w=1 w=1的周围,gradient几乎是突变的,这让我们很难去调整learning rate
因此我们可以解释,RNN训练困难,是由于它把同样的操作在不断的时间转换中重复使用
从memory接到neuron输入的参数 w w w,在不同的时间点被反复使用, w w w的变化有时候可能对RNN的输出没有影响,而一旦产生影响,经过长时间的不断累积,该影响就会被放得无限大,因此RNN经常会遇到这两个问题:
- 梯度消失(gradient vanishing),一直在梯度平缓的地方停滞不前
- 梯度爆炸(gradient explode),梯度的更新步伐迈得太大导致直接飞出有效区间
4.Help Techniques
有什么技巧可以帮我们解决这个问题呢?
LSTM就是最广泛使用的技巧,它会把error surface上那些比较平坦的地方拿掉,从而解决梯度消失(gradient vanishing)的问题,但它无法处理梯度崎岖的部分,因而也就无法解决梯度爆炸的问题(gradient explode)
但由于做LSTM的时候,大部分地方的梯度变化都很剧烈,因此训练时可以放心地把learning rate设的小一些
Q:为什么要把RNN换成LSTM?
A:LSTM可以解决梯度消失的问题
Q:为什么LSTM能够解决梯度消失的问题?
A:RNN和LSTM对memory的处理其实是不一样的:
- 在RNN中,每个新的时间点,memory里的旧值都会被新值所覆盖
- 在LSTM中,每个新的时间点,memory里的值会乘上 f ( g f ) f(g_f) f(gf)与新值相加
对RNN来说, w w w对memory的影响每次都会被清除,而对LSTM来说,除非forget gate被打开,否则 w w w对memory的影响就不会被清除,而是一直累加保留,因此它不会有梯度消失的问题
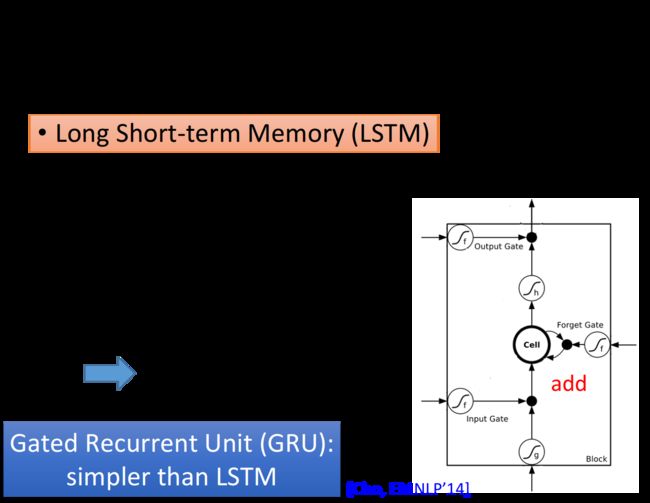
另一个版本GRU (Gated Recurrent Unit),只有两个gate,需要的参数量比LSTM少,鲁棒性比LSTM好,不容易过拟合,它的基本精神是旧的不去,新的不来, GRU会把input gate和forget gate连起来,当forget gate把memory里的值清空时,input gate才会打开,再放入新的值
此外,还有很多技术可以用来处理梯度消失的问题,比如Clockwise RNN、SCRN等

5.More Applications
在Slot Filling中,我们输入一个word vector输出它的label,除此之外RNN还可以做更复杂的事情
- 多对一
- 多对多
Sentiment Analysis
语义情绪分析,我们可以把某影片相关的文章爬下来,并分析其正面情绪or负面情绪
RNN的输入是字符序列,在不同时间点输入不同的字符,并在最后一个时间点输出该文章的语义情绪

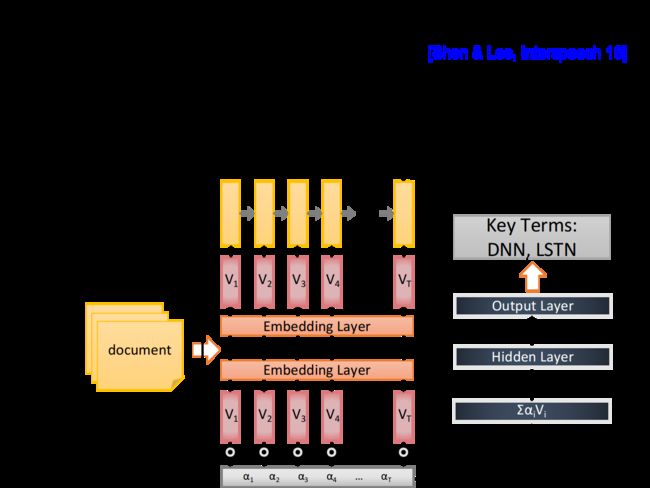
Key term Extraction
关键词分析,RNN可以分析一篇文章并提取出其中的关键词,这里需要把含有关键词标签的文章作为RNN的训练数据
Output is shorter
如果输入输出都是sequence,且输出的sequence比输入的sequence要短,RNN可以处理这个问题
以语音识别为例,输入是一段声音信号,每隔一小段时间就用1个vector来表示,因此输入为vector sequence,而输出则是character vector
- 如果依旧使用Slot Filling的方法,只能做到每个vector对应1个输出的character,识别结果就像是下图中的“好好好棒棒棒棒棒”,但这不是我们想要的,可以使用Trimming的技术把重复内容消去,剩下“好棒”
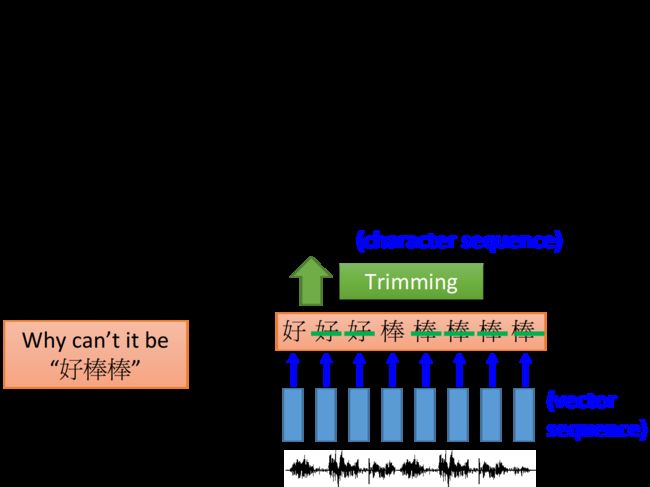
但“好棒”和“好棒棒”实际上是不一样的,如何区分呢?
CTC算法
需要用到CTC算法,它的基本思想是,输出不只是字符,还要填充NULL,输出的时候去掉NULL就可以得到连词的效果
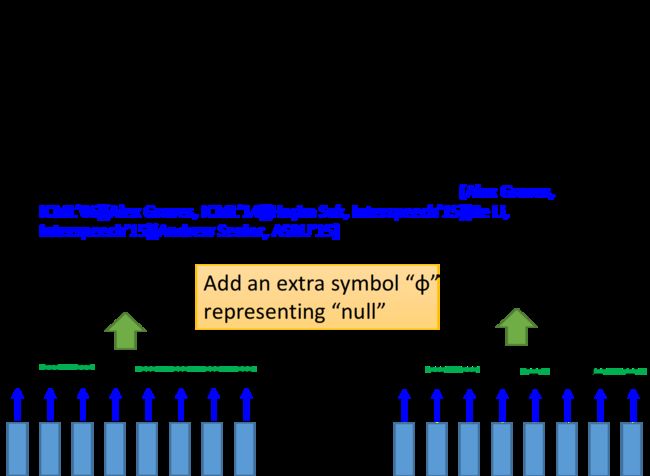
- 下图是CTC的示例,RNN的输出就是英文字母+NULL,google的语音识别系统就是用CTC实现的

Sequence to Sequence Learning
在Seq2Seq中,RNN的输入输出都是sequence,但是长度不同
在CTC中,input比较长,output比较短;而在Seq2Seq中,并不确定谁长谁短
比如现在要做机器翻译,将英文的word sequence翻译成中文的character sequence
假设在两个时间点分别输入“machine”和“learning”,则在最后1个时间点memory就存了整个句子的信息,接下来让RNN输出,就会得到“机”,把“机”当做input,并读取memory里的值,就会输出“器”,依次类推,这个RNN甚至会一直输出,不知道什么时候会停止
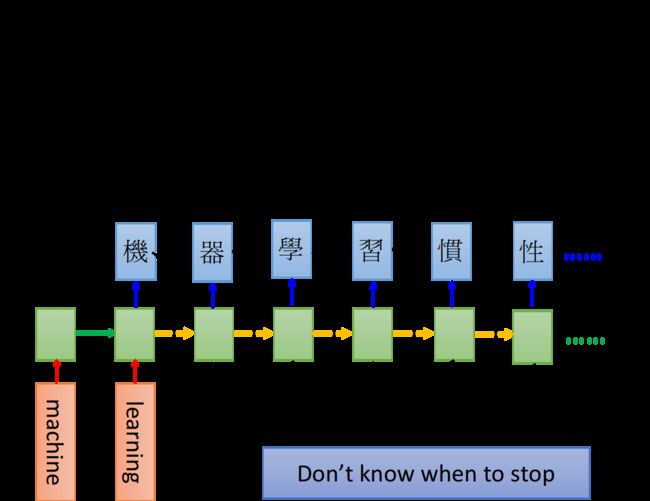
怎样才能让机器停止输出呢?
可以多加一个叫做“断”的symbol “===”,当输出到这个symbol时,机器就停止输出

具体的处理技巧这里不再详述
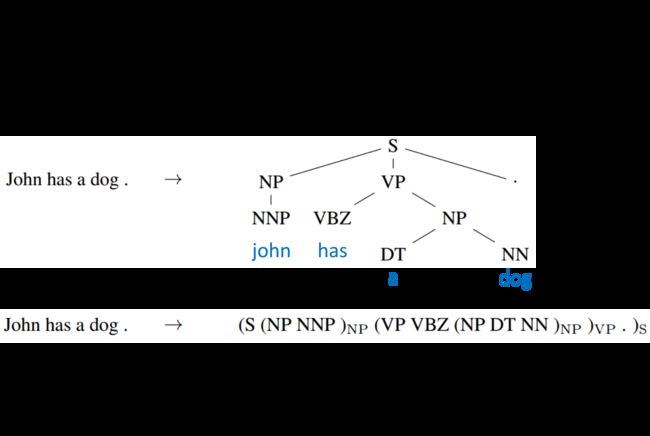
Seq2Seq for Syntatic Parsing
Seq2Seq还可以用在句法解析上,让机器看一个句子,它可以自动生成树状的语法结构图
Seq2Seq for Auto-encoder Text
如果用bag-of-word来表示一篇文章,就很容易丢失词语之间的联系,丢失语序上的信息
比如“白血球消灭了感染病”和“感染病消灭了白血球”,两者bag-of-word是相同的,但语义却是完全相反的

这里就可以使用Seq2Seq Autoencoder,在考虑了语序的情况下,把文章编码成vector,只需要把RNN当做编码器和解码器即可
我们输入word sequence,通过RNN变成embedded vector,再通过另一个RNN解压回去,如果能够得到一模一样的句子,则压缩后的vector就代表了这篇文章中最重要的信息
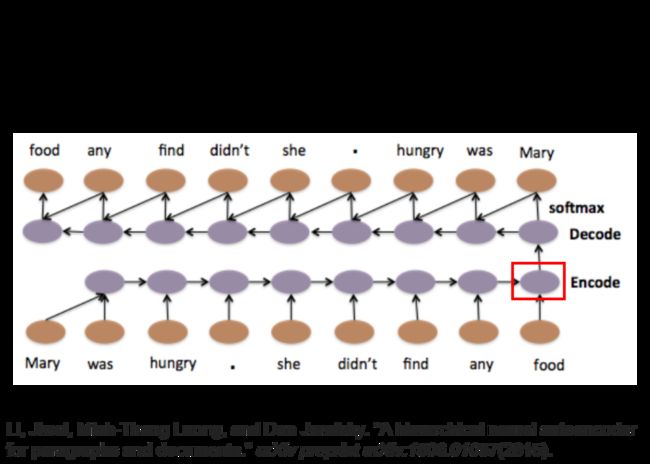
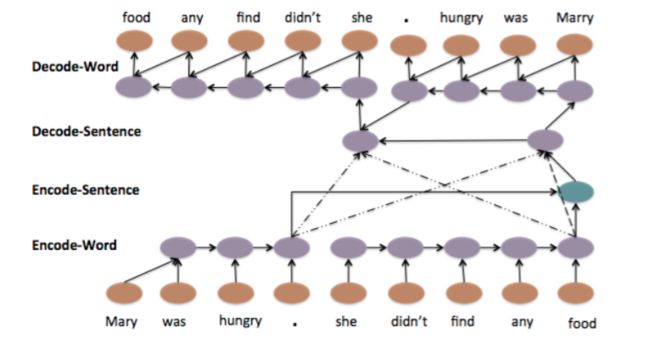
这个结构甚至可以被层次化,我们可以对句子的几个部分分别做vector的转换,最后合并起来得到整个句子的vector
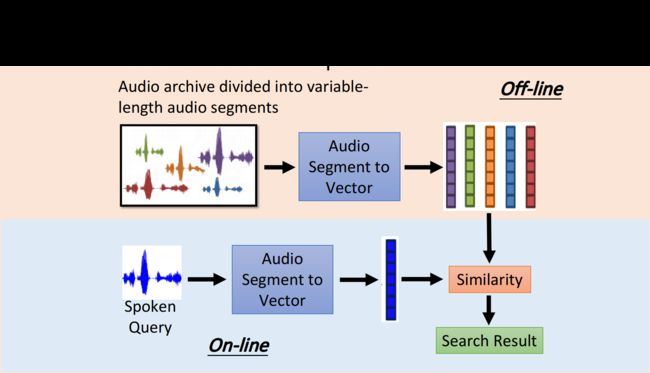
Seq2Seq for Auto-encoder Speech
Seq2Seq autoencoder还可以用在语音处理上,它可以把一段语音信号编码成vector
这种方法可以把声音信号都转化为低维的vecotr,并通过计算相似度来做语音搜索
-
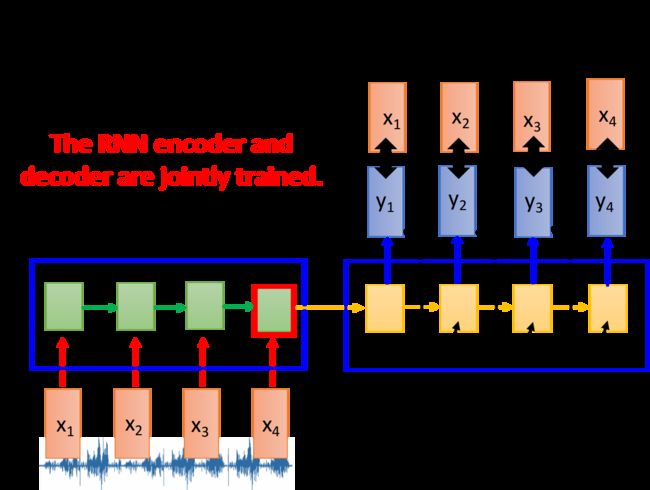
先把声音信号转化成声学特征向量(acoustic features),再通过RNN编码,最后一个时间点存在memory里的值就代表了整个声音信号的信息
-
为了能够对该神经网络训练,还需要一个RNN作为解码器,得到还原后的 y i y_i yi,使之与 x i x_i xi的差距最小
Attention-based Model
除了RNN之外,Attention-based Model也用到了memory的思想
机器会有自己的记忆池,神经网络通过操控读写头去读或者写指定位置的信息,这个过程跟图灵机很像,因此也被称为neural turing machine

这种方法通常用在阅读理解上,让机器读一篇文章,再把每句话的语义都存到不同的vector中,接下来让用户向机器提问,神经网络就会去调用读写头的中央处理器,取出memory中与查询语句相关的信息,综合处理之后,可以给出正确的回答