Keras : 利用卷积神经网络CNN对图像进行分类,以mnist数据集为例建立模型并预测
我是本期目录酱!
-
-
- 引入
- 计算机视觉
- 图像特征
- 如何区分图像的类别
- 卷积神经网络
-
- 卷积Convolution
- 卷积层
- 池化Pooling
- 卷积神经网络
- 以mnist数据集为例建立模型并预测
-
- 简单分析
- py代码(全/包括预测本地图片)
- 碎碎念念
-
引入
阴雨连绵的周五,附带陈杉片刻不停的步伐,和半路响起的上课铃
本学期的第一次迟到(针对ldw老师),不期而至了呢
顺便昨晚没休息好(可能不是),在老师讲课的时候困意发起多次攻击,我以为我能承受住然后我就溃败了,丢盔弃甲之后老师也停止授课(不是,主要是知识点讲完了),巧的是困意小队发出撤退信号,我直接活力回归,真 奇 妙
言归正传,讲的是卷积神经网络的图像分类
计算机视觉
从计算机视觉开始讲起,错过第一张PPT,该死的下雨天
眼睛 ≠ 计算机视觉 , 摄像机也不
中间的内容被迫不记得了,这是结论。
我记得这时候我想的是原来这个和老师没关系,我真的对计算机视觉提不起兴趣呢,好无聊下一个(其实本来也就知道的,但是可能还是有点不认同,心底的那种)
开始困。
代入感极强,已经不想写了
接着下面讲了如何算是理解图像的内容,针对计算机来说,包括但是不止
- 图像分类:就是图里面是猫猫还是狗狗还是你,这样
- 图像识别:图里面是哪一种,或者是哪一只猫猫,波斯猫还是加菲猫还是哆啦A梦,这样(上课将的例子是人脸识别出来你,这样
- 目标检测:忘记了讲课时候说的例子嗯,应该是在图像中把猫猫框出来这样
- 图像分割:参考美图秀秀中的自动扣图功能
- 显著性:人在看物体的时候具有一定的“偏好”,这个很难讲清楚嗯
- 立体视觉:上课拿的手机上面自带的红外距离检测功能做例子,但我已经迷糊了不太懂这是什么概念
- 三维重建:ycz老师也讲过,就是从数字图像到图像的还原,简单来说
- 图像恢复:前段时间(或者几年前/时间着实快)较火的修复老照片嗯
- 物体追踪:开始困,主要用来推测行为趋势,比如在走路的你会接着走呢还是停下,这样
- 自体运动:更困了,主要用来推测运动轨迹,例子没听清楚好像和车子有关emm导航?行车记录仪?
- 姿势识别:老师没举例子,我随便讲一个好了比如华为的隔屏操作(等我火了记得打钱orz)
前面还有一个强调的共识(可以这么说),就是图像里单个像素内容只有颜色信息,不表示任何复杂语义很有道理,从后面代码可以直接体现出来
图像特征
介绍了俩种传统图像特征的检测方法
1 . HOG,就是方向梯度直方图,全称Histogram of Oriented Gradient
从下面的图可以比较明显的识别出来人的面部特征嗯

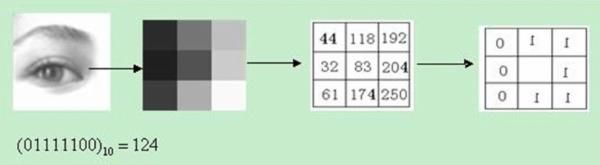
2 . LBP,就是局部二值模式,全称Local Binary Pattern
以下面的图片作为例子,从图像中拿出一小块3*3的矩阵,针对中心的点,颜色更深的赋值为0,颜色更浅的赋值为1,然后把所赋值的环拆开来就可以用一个数值代替这个矩阵了
另外还有一些别的LBP算子
老师说上面的是数学家用来检测特征的方法,果不其然,太难啦,且枯燥无趣
如何区分图像的类别
接着引入了一个例子,就是如何区分图像的类别

目标呢就是区分和
欣赏卖家秀和买家秀orz↓

讲到底还是我没什么绘画天赋,无语子
言归正传,解决这个问题主要是思路要清晰,对不(本来我以为是让我们实现呢,还突然清醒了一下)
首先要有效描述图像的内容,比如颜色=没有效果
其次就是要找出区分俩者的关键特征,举例鱼可以只露出尾巴或者眼睛,所以这俩个特征并不是区别自行车的关键嗯
最后一个就是逻辑分类,有啥啥特征的归为哪一类这样子
后面我们建立模型也是按照这个思路来嗯
卷积神经网络
卷积Convolution
形象地说就是滚动式的加权平均,看图即懂
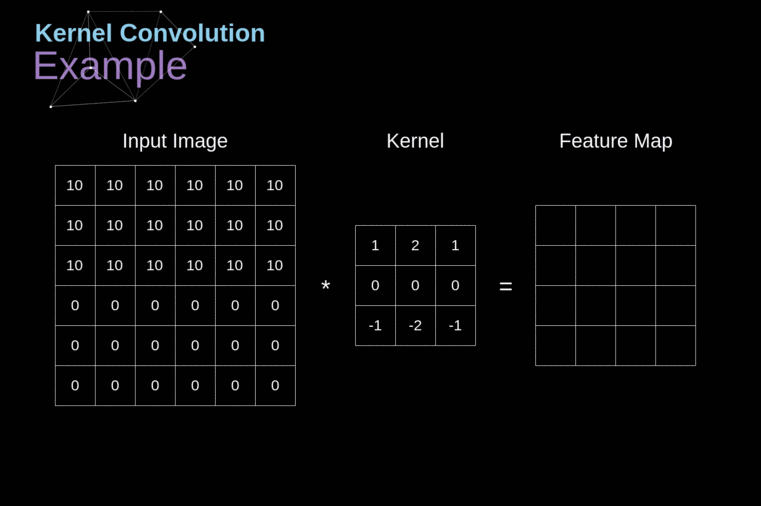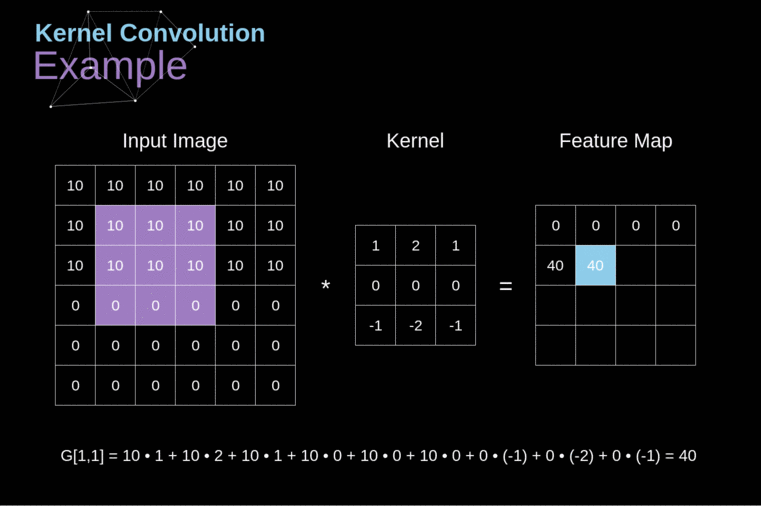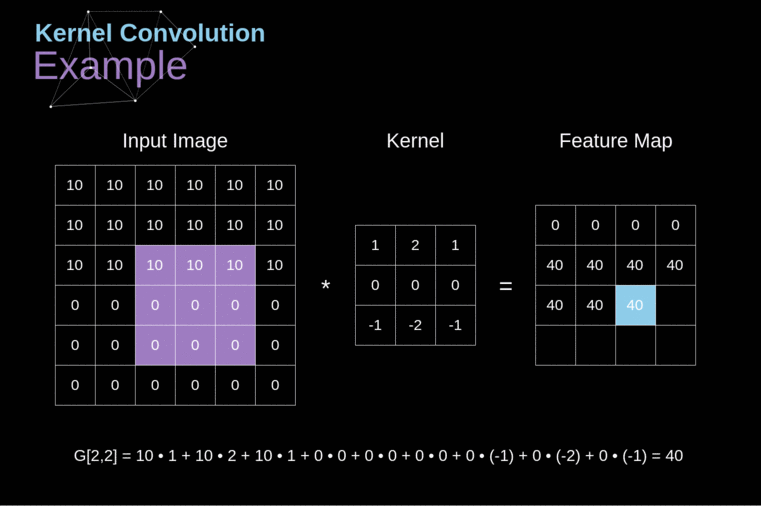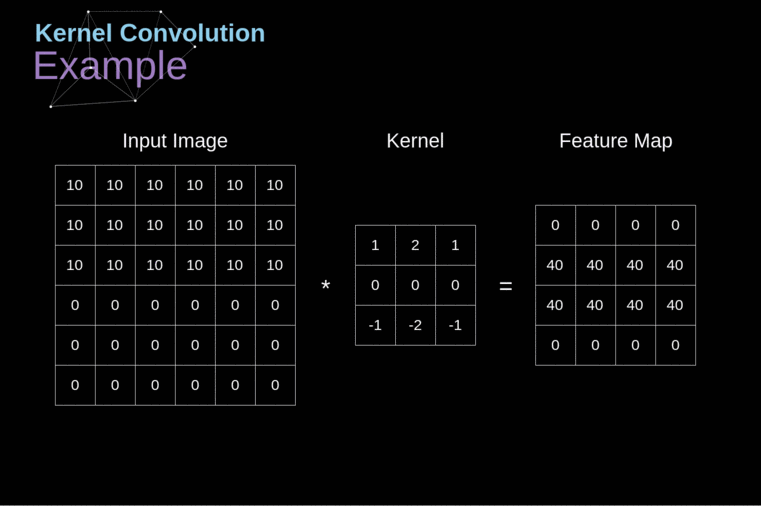
官方讲就是对于一个有噪声的函数y=f(x),使用一个核函数kernel(n)/k(n)对其进行滤波操作(还是形象比较言简意赅·真)
卷积层
对图像进行三维卷积运算,得到特征图
卷积操作沟通了临近像素,增加了视野,当图像内容和卷积核形状相近(吻合)的时候,激活度会很高,可以说,卷积操作能够完成特征提取的操作。另外,输出特征图的通道数目就等于使用的卷积核个数。
顺便,上面的那个gif,可以看到特征图的图像尺寸变小了一些(小多少就要看卷积核的大小了),如果想要特征图的尺寸保持不变的话,padding参数设置成same就行。
解释一下卷积层的代码
tf.keras.layers.Conv2D(
filters,
kernel_size,
strides=(1, 1),
padding='valid',
data_format=None,
dilation_rate=(1, 1),
activation=None,
use_bias=True,
kernel_initializer='glorot_uniform',
bias_initializer='zeros',
kernel_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
bias_constraint=None,
**kwargs
)
主要看下padding
padding: one of “valid” or “same” (case-insensitive). “valid” means no padding. “same” results in padding evenly to the left/right or up/down of the input such that output has the same height/width dimension as the input.
顺带解释一下其他的参数好了
- filters 卷积过滤器的数量,对应输出的维数
- kernel_size 整数,过滤器的大小,如果为一个整数则宽和高相同
- strides 横向和纵向的步长,如果为一个整数则横向和纵向相同
- padding valid:表示不够卷积核大小的块,则丢弃;same表示不够卷积核大小的块就补0,所以输出和输入形状相同
- data_format channels_last为(batch,height,width,channels),channels_first为(batch,channels,height,width)
- dilation_rate 扩张卷积的扩张率,默认(1,1)
- activation 激活函数,None是线性函数
- use_bias 是否使用偏差量
- kernel_initializer 卷积核的初始化。
- bias_initializer 偏差向量的初始化。如果是None,则使用默认的初始值
- kernel_regularizer 卷积核的正则项
- bias_regularizer 偏差向量的正则项
- activity_regularizer 输出的正则函数
- bias_constraint 映射函数,当偏差向量被Optimizer更新后应用到偏差向量上。
池化Pooling
先看图,比较直观
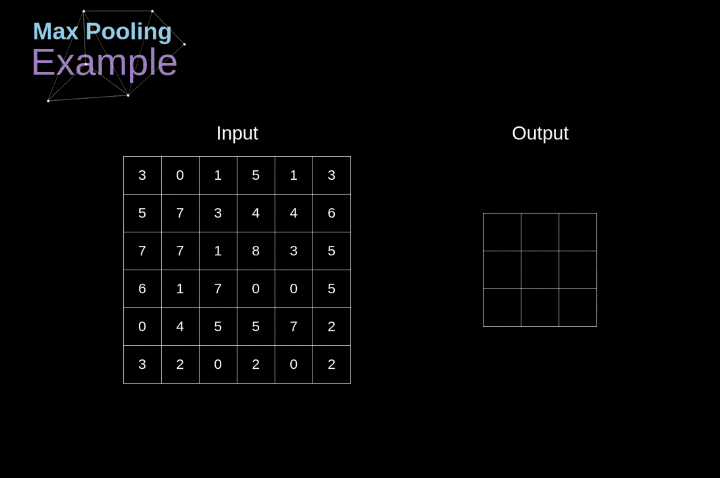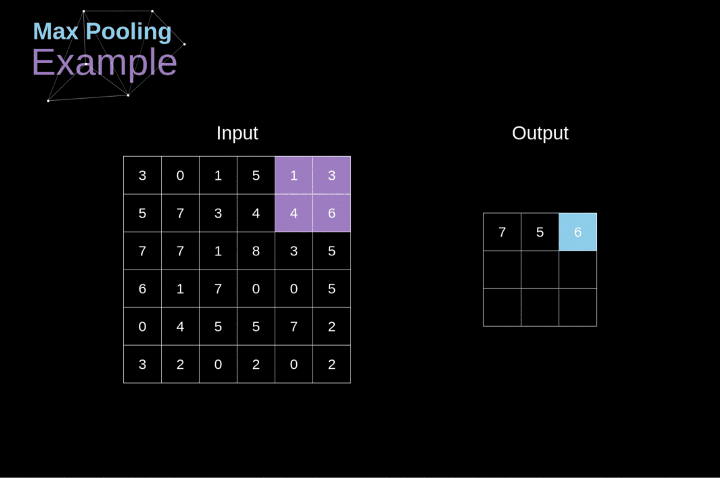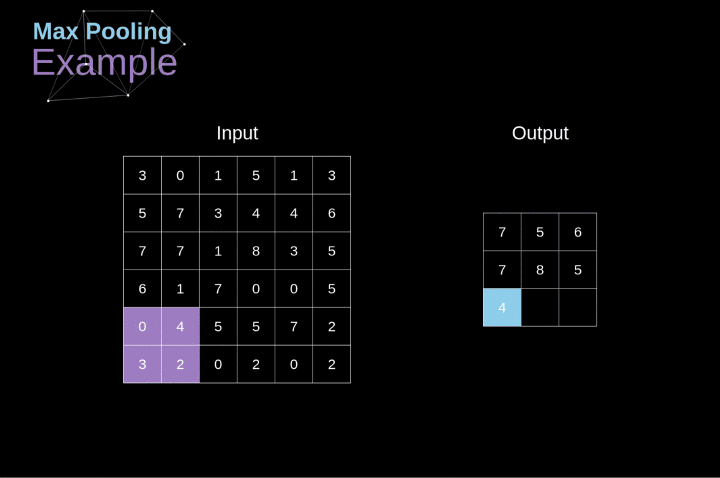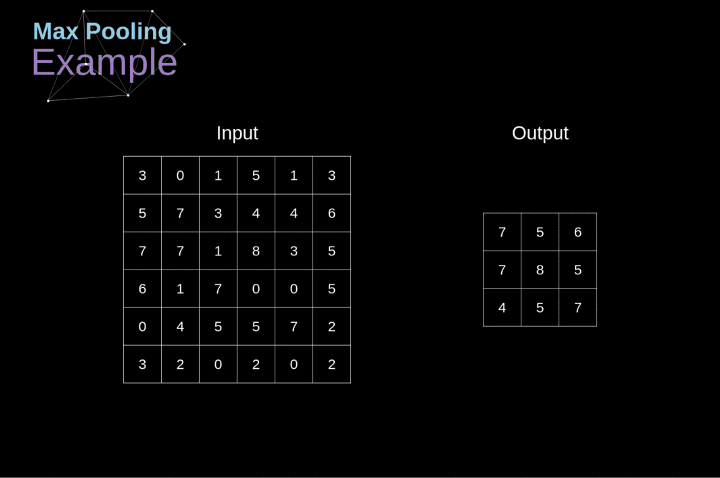
一般得到混合成块的像素,以某种倍率缩小图像,通常采用max操作,比如上面的例子就是。
能够增加视野,在某些方面,顺带具有一定的平移不变性。
卷积神经网络
okay终于讲到卷积神经网络了天
卷积神经网络就是反复使用卷积和池化操作来增加视野,PPT尚说类似人类视觉机制,在低级特征的基础上构建高级特征,最终理解图像的宏观内容(我可能睡着了,印象中老师应该就是念了一下或者呼应的part我还没来/在马不停蹄赶来的路上嗯)
以mnist数据集为例建立模型并预测
简单分析
重头戏begin!
其实也没啥好讲的(爬)
和上次不一样的是不需要将图片转变成向量了(多此一举)需要做的是将图像直接输入,构建卷积神经网络训练就行。
l老师还特地提了一嘴mnist数据集很干净,在数据集比较杂的情况下,转变成向量可能效果就不是很美妙了嗯
要回顾前面的概念请点keras训练模型须知
训练集和测试集的划分,构建输入层、隐藏层(包括卷积层和池化层)和输出层,然后训练然后控制台可以看到相关参数。
以上是老师提供代码的全部内容,个人觉得不太合理,没加预测不够严谨。所以我就手动加了(狗头,代码往下划
py代码(全/包括预测本地图片)
# -*- coding: utf-8 -*-
# @TIME : 2020/9/25 9:31
# @Author : Chen Shan
# @Email : [email protected]
# @File : MNIST_CNN.py
# @Software : PyCharm
import numpy as np
#import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# form PIL import Image
import cv2
#读取数据
def load_mnist(): #读取离线的MNIST.npz文件。
path = r'mnist.npz' #放置mnist.py的目录,这里默认跟本代码在同一个文件夹之下。
f = np.load(path)
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
f.close()
return (x_train, y_train), (x_test, y_test)
(x_train, y_train), (x_test, y_test) = load_mnist()
#数据预处理
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
# print(x_train.shape[0], "train samples")
# print(x_test.shape[0], "test samples")
# convert class vectors to binary class matrices
num_classes = 10
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
#构建模型
input_shape = (28, 28, 1)
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.summary()
#训练
batch_size = 128
epochs = 5
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1,verbose=2)
#测试
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])
# 加载待预测数据
def load_data():
pre_x=[]
path = r'F:/project/DeepLearning/img/new3.png'
img = cv2.imread(path)
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
img_arr = img_gray.reshape(28, 28, 1)
img_arr = img_arr.astype('float32') / 255
# array = np.asarray(img_gray,dtype="float32")
# print(img_gray.shape)
pre_x.append(img_arr)
return pre_x
pre_x = load_data()
pre_x = np.expand_dims(pre_x, -1)
# 通过模型预测结果并输出
predict = model.predict(pre_x)
# print(predict)
predict = np.argmax(predict)
print("The result of model recognition is: "+str(predict))
碎碎念念
其实预测的话也不是很难,主要就是一个predict,保持数据格式传进去就行了。
虽然但是我还是遇到了一个错误,然后也是多亏了这个错误,直接改正给出结果,顺便与之前的不完全统计结果出现偏差了(这个不完全统计出现在我的实验报告里面嗯)
慢慢来
想先讲遇到的错误, ValueError: Input 0 of layer sequential is incompatible with the layer: : expected min_ndim=4, found ndim=3. Full shape received: [None, 28, 1]
菜鸟英语翻译一下,类型错误布拉布拉布拉布拉输入类型错误少了一个维度,前面缺了一个没找到布拉(有人能完整翻译的话请帮我一下/本人水平着实有限)
然后就往上翻了一下,果然有一步没处理干净
成了,结果预测结果输出0???啊嘞百分之90+的准确率,于是我又换了一个,哦还是不对,天,然后发现一个点,黑白像素。
果不其然,换了一下基本就都预测正确了呢✌

我想应该是向量的话就和像素值没多大关系了,毕竟都是直接被拍扁算的,但是卷积的话就是一直缩小一直缩小,所以可能会有一定影响嗯。
念叨完了886,下周会不迟到也不睡觉嗯(学生本分)
更新,下周睡得可香了,啥都没听见……当事人准备自学然后写作业……