机器学习模型评估——混淆矩阵
混淆矩阵
什么是混淆矩阵(Confusion Matrix)?我们在做分类问题时会用到机器学习分类模型,不管是二分类还是多分类问题,我们都要对模型的性能进行评估,看看模型的分类效果是否好,有多好!我们常常会选择一个合适的评估指标进行衡量,比如我们熟悉的ACC,AUC,F1-score,召回率等等,而混淆矩阵也是和它们一样的功能,混淆矩阵可以直观的展示我们分类器对每个样本的分类情况,知道有哪些类别分正确了,哪些类别被错误地分到了其他类别,混淆矩阵就做这么个事。
概括:混淆矩阵就是我们用来评估模型分类好坏的(特别是在类别不均衡的时候!)
概念
首先我们来看一张图:
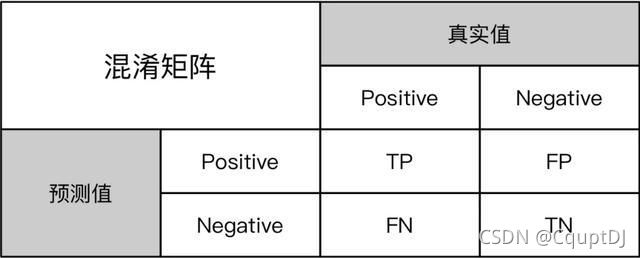
这张图是我从网上找的经典解释图,TN(真正例),FP(假正例),FN(假反例),TP(真反例),上面的图是对于二分类的举例,多分类是一个道理。值得注意的是,我们常用的评价指标F1-score,ACC等四个指标都是通过混淆矩阵进行计算的。
重要性
混淆矩阵的用处非常大,我们评估一个模型的性能不能只从局限的一个方面或者两个方面,而是要从多方面去衡量,这样的模型才更有鲁棒性。特别是当我们遇到数据类别不均衡的时候就可以体现混淆矩阵的优势。
举个例子
predict= [0, 0, 0, 0, 0, 0, 0 ,0, 0, 0] (预测值)
actual= [0, 0, 0, 1, 0, 0, 0, 0, 0, 1] (真实值)
我们可以看到,例子中“1”样本为2个,“0”样本为8个,正负样本比例为1:4,此时如果我们通过ACC(准确率)来评估模型,当我们模型预测值全部为0时,准确率可以达到80%,非常高,那是不是说明模型非常好呢,并不是!说白了,就算我们不用模型,全部蒙0都可以有80%的准确率,那模型有什么用呢,根本没用,模型有没有学到有用的特征我们根本就判断不了,这时候我们可以画混淆矩阵来看看:

我们看看混淆矩阵的对角线,对“0”类8个全部预测正确了,但是对于“1”类是一个没对啊!现在看得就很明白了,我们这个模型是基本没有什么用的。而如果仅仅是通过准确率去评估的话,我们就会被欺骗,还以为模型挺不错的,事实上毛用没有哈哈。
可视化
sklearn库中提供了可以让我们计算混淆矩阵的接口,而我们为了更加直观的观察混淆矩阵,我们最好画个混淆矩阵图:
from sklearn.metrics import confusion_matrix
import seaborn as sns
import pandas as pd
classes=[0,1]
guess = [0, 0, 0, 0, 0, 0, 0 ,0, 0, 0]
fact = [0, 0, 0, 1, 0, 0, 0, 0, 0, 1]
cm = confusion_matrix(guess, fact,labels=classes)
df=pd.DataFrame(cm,index=classes,columns=classes)
sns.heatmap(df,annot=True)
这个画出来就是上面那个例子的混淆矩阵图,如果要画其他数据的图直接换数据即可,颜色也可以根据自己的喜好调哦!
写在最后
本人才疏学浅,如果有理解不到位或者错误的地方请指正!