pytorch-ssd源码中的损失函数与匹配策略
源代码:
https://github.com/amdegroot/ssd.pytorch
一. Loss解析
SSD的损失函数包含两个部分,一个是定位损失 L l o c L_{loc} Lloc,一个是分类损失 L c o n f L_{conf} Lconf,整个损失函数表达如下:
![]()
其中 N N N是先验框的正样本数量, c c c是类别置信度预测值, l l l是先验框对应的边界框预测值, g g g是ground truth的位置参数, x x x代表网络的预测值。对于位置损失,采用Smooth L1 Loss,位置信息都是encode之后的数值。而对于分类损失,首先需要使用hard negtive mining将正负样本按照1:3 的比例把负样本抽样出来,抽样的方法是:针对所有batch的confidence,按照置信度误差进行降序排列,取出前top_k个负样本。损失函数可以用下图表示:

1. localization loss
代码如下,注意之前的match函数内部会改变 loc_t, conf_t 的值
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t, requires_grad=False)
#这个时候的loc_t 已经返回了 prior box相对于GT的偏移量
#这个时候的conf_t 已经返回了每个priorbox各自的label
pos = conf_t > 0 # 筛选出 >0 的box下标(大部分都是=0的)
num_pos = pos.sum(dim=1, keepdim=True)
# 位置(localization)损失函数, 使用 Smooth L1 函数求损失
# loc_data:[batch, num_priors, 4]
# pos: [batch, num_priors]
# pos_idx: [batch, num_priors, 4], 复制下标成坐标格式, 以便获取坐标值
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)
loc_t = loc_t[pos_idx].view(-1, 4)
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False)
loc_t记录的是每个default box变换到对应的gt框的回归偏置值,conf_t记录的是每个default box对应的gt框的类别,并且iou小于阈值的被设置为0,表示为背景
2. confidence loss
对于分类问题,是一个交叉熵损失函数,但是直接用交叉熵损失函数会有一个问题,那就是原来的prior box的数量会造成有很多的负样本,所以先要先进行一次Hard Negative Mining,只选取部分负样本,具体数量设置为正例的3倍
这里的conf_logP(即loss_c)是采用了logsoftmax的思想
batch_conf = conf_data.view(-1, self.num_classes)
conf_logP = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1, 1))
具体解释见下图:
正样本位置pos计算loss_l的时候已经得出,接下来寻找负样本
首先将正样本均置为0
loss_c[pos] = 0 # 剩下分类为背景的框的损失值
接着进行两次排序得到原来prior box中每个loss排第几,进行负样本选取
loss_c = loss_c.view(num, -1)
_, loss_idx = loss_c.sort(1, descending=True)
_, idx_rank = loss_idx.sort(1)
num_pos = pos.long().sum(1, keepdim=True)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
neg = idx_rank < num_neg.expand_as(idx_rank)
上述操作过后就选出了正负样本的index,用这些进行损失函数的计算
由于 pos矩阵和neg矩阵中的值都是1或者0。因此pos矩阵相当于记录了default box中正样本框的序号,同理neg矩阵记录的就是负样本框的序号。
我们要明白一件事就是 pos矩阵中为1的肯定是正样本,但并非说为0的就一定是负样本。neg矩阵中为1的肯定是负样本,也并非说为0的就一定是正样本,因为由于Hard Negative Mining的关系,负样本的数目被设置成了是正样本的三倍,所以这就导致了并非所有pos中为0的框都是负样本。
然后使用一个技巧,所有default box中 pos 和 neg中的值加起来大于0的框,才作为真正的训练样本 conf_p。意思就是conf_p中的框不是正样本就是负样本。意在去除pos=0且neg=0的框,这类框的特点是,与GroundTrue不怎么沾边,被分类成背景框,且作为背景框的损失值还很小,就是说这类框必是背景框了。要作为训练数据的框,要么是与GroundTrue交叠比较大的正样本,要么是损失值大的背景框,就是说它看上去是背景,但好像又不是背景的框。
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
targets_weighted = conf_t[(pos+neg).gt(0)]
loss_c = F.cross_entropy(conf_p, targets_weighted, reduction='sum')
3.最终的loss
以系数α控制比例,相加即为总的loss
# Sum of losses: L(x,c,l,g) = (Lconf(x, c) + αLloc(x,l,g)) / N
N = num_pos.data.sum()
loss_l /= N
loss_c /= N
return loss_l, loss_c
这里涉及到两次sort得出原数据中的大小排名,选前top_k个
a = torch.Tensor([2,3,7,9,5])
_, b = a.sort(descending = True) output [0, 1, 4, 2, 3]
_, d = b.sort() output [4, 3, 1, 0, 2] #可以看到了输出的数是每个数排第几
二. match函数解析
这里主要对疑难点,下面这两条语句进行解析
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # ensure best prior
# TODO refactor: index best_prior_idx with long tensor
# ensure every gt matches with its prior of max overlap
for j in range(best_prior_idx.size(0)):
best_truth_idx[best_prior_idx[j]] = j
参考: match() 函数中先验框(anchor,PriorBox)与目标框匹配过程超详细解析
总的原则:要缓解正负样本失衡,其中一个符合直觉的做法就是产生尽量多的正样本,所以,尽可能的为每个目标都匹配上至少一个 priorBox
要实现“确保每个gt框都匹配上至少一个 priorBox”,从两方面做起:
- 确保该匹配的 overlap 足够大只能保证它不会被删除
best_truth_overlap.index_fill_(0, best_prior_idx, 2) # ensure best prior
上面这条语句就是做这个的,因为iou中overlap值不够阈值的会被归为负样本,有时候一个gt框即使最大的overlap也会小于人为设定的阈值,所以这里强行将和每个gt框的最大overlap值设置为2,确保其不会小于阈值而被分为负样本。实际2换成大于阈值的任意数均可,保证其被保留即可。
- 仅确保不被删除是不够的,如果一开始这个匹配就没有被选中,“保留下来”也是无从说起的,所以我们还得确保这个匹配被选中
因为最后conf过滤小于阈值的框是由best_truth_idx选择的
conf = labels[best_truth_idx] + 1 # Shape: [num_priors]
这个变量的含义是和一个default box所有gt框中最大的iou的gt框下标
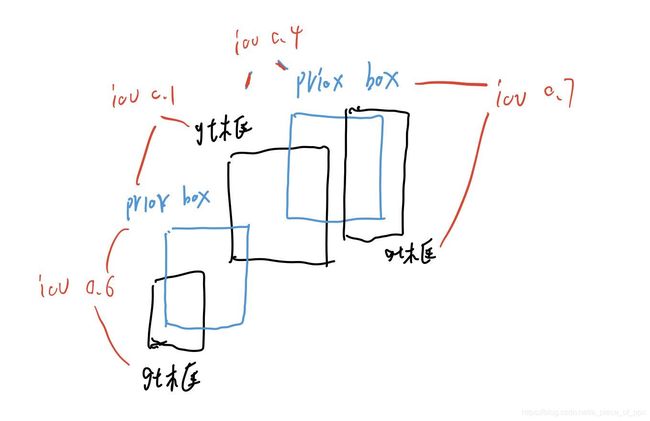
在上图中,如果单向选择,即找priox box(default box)中最大iou的gt框匹配,则最中间的gt框就没有匹配的prior box了,为了满足尽可能的为每个目标都匹配上至少一个 priorBox,强制将和中间gt框最大iou的priox box匹配为该gt框,即
best_truth_idx[best_prior_idx[j]] = j
match函数根据下标获取每个priorbox对应的gtbox的坐标, 然后对坐标进行相应编码, 并存储起来, 同时将gt类别也存储起来, 到此, 匹配完成.
参考
- SSD 源码实现 (PyTorch)
- 【SSD算法】史上最全代码解析-核心篇
- SSD代码以及论文解读
- 目标检测算法之SSD代码解析(万字长文超详细)
- ssd(Single Shot MultiBox Detector)代码解读之(三)multibox loss损失函数