NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
- 5.5 实践:基于ResNet18网络完成图像分类任务
-
- 5.5.1 数据处理
-
- 5.5.1.1数据集介绍
- 5.5.1.2 数据读取
- 5.5.1.3 构造Dataset类
- 5.5.2 模型构建
- 5.5.3 模型训练
- 5.5.4 模型评价
- 5.5.5 模型预测
- 5.5.6 什么是预训练模型?什么是迁移学习?
- 5.5.7 比较“使用预训练模型”和“不使用预训练模型”的效果。
- 思考题
-
- 1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度ResNet(18,34,50,101和152),并简单谈谈自己的看法。
- 2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet。
- 总结
- 参考链接
- 参考文献
5.5 实践:基于ResNet18网络完成图像分类任务
图像分类(Image Classification是计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。很多任务可以转换为图像分类任务,比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。

- 数据集:CIFAR-10数据集,
- 网络:ResNet18模型,
- 损失函数:交叉熵损失,
- 优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
- 评价指标:准确率。
5.5.1 数据处理
5.5.1.1数据集介绍
CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为32×32像素。CIFAR-10数据集的示例如上图 所示。
5.5.1.2 数据读取
在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。
最终的数据集构成为:
- 训练集:40 000条样本。
- 验证集:10 000条样本。
- 测试集:10 000条样本。
读取一个batch数据的代码如下所示:
import os
import pickle
import numpy as np
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_'+str(batch_id))
#加载数据集文件
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding = 'latin1')
imgs = batch['data'].reshape((len(batch['data']),3,32,32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
imgs_batch, labels_batch = load_cifar10_batch(folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py',
batch_id=1, mode='train')
查看数据的维度:
#打印一下每个batch中X和y的维度
print ("batch of imgs shape: ",imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
运行结果:
![]()
可视化观察其中的一张样本图像和对应的标签,代码如下所示:
import matplotlib.pyplot as plt
image, label = imgs_batch[1], labels_batch[1]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1,2,0))
plt.savefig('cnn-car.pdf')
运行结果:


5.5.1.3 构造Dataset类
import torch
from torch.utils.data import Dataset,DataLoader
import torchvision.transforms as transforms
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py', mode='train'):
if mode == 'train':
#加载batch1-batch4作为训练集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate([self.labels, labels_batch])
elif mode == 'dev':
#加载batch5作为验证集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
#加载测试集
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transforms = transforms.Compose([transforms.Resize(32),transforms.ToTensor(), transforms.Normalize(mean=[0.4914,0.4822,0.4465], std=[0.2023, 0.1994, 0.2010])])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_dataset = CIFAR10Dataset(folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py', mode='test')
5.5.2 模型构建
使用PyTorch API中的Resnet18进行图像分类实验。
from torchvision.models import resnet18
resnet18_model = resnet18(pretrained=True)
5.5.3 模型训练
复用RunnerV3类,实例化RunnerV3类,并传入训练配置。
使用训练集和验证集进行模型训练,共训练30个epoch。
在实验中,保存准确率最高的模型作为最佳模型。代码实现如下:
import torch.nn.functional as F
import torch.optim as opt
from nndl import RunnerV3, Accuracy
# 学习率大小
lr = 0.001
# 批次大小
batch_size = 64
# 加载数据
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
# 定义网络
model = resnet18_model.to(device)
# 定义优化器,这里使用Adam优化器以及l2正则化策略,相关内容在7.3.3.2和7.6.2中会进行详细介绍
optimizer = opt.Adam(lr=lr,params=model.parameters(), weight_decay=0.005)
# 定义损失函数
loss_fn = F.cross_entropy
loss_fn = loss_fn
# 定义评价指标
metric = Accuracy(is_logist=True)
# 实例化RunnerV3
runner = RunnerV3(model, optimizer, loss_fn, metric)
# 启动训练
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
注:使用到的RunnerV3和Accuracy如下:
RunnerV3:
class RunnerV3(object):
def __init__(self, model, optimizer, loss_fn, metric, **kwargs):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric # 只用于计算评价指标
# 记录训练过程中的评价指标变化情况
self.dev_scores = []
# 记录训练过程中的损失函数变化情况
self.train_epoch_losses = [] # 一个epoch记录一次loss
self.train_step_losses = [] # 一个step记录一次loss
self.dev_losses = []
# 记录全局最优指标
self.best_score = 0
def train(self, train_loader, dev_loader=None, **kwargs):
# 将模型切换为训练模式
self.model.train()
# 传入训练轮数,如果没有传入值则默认为0
num_epochs = kwargs.get("num_epochs", 0)
# 传入log打印频率,如果没有传入值则默认为100
log_steps = kwargs.get("log_steps", 100)
# 评价频率
eval_steps = kwargs.get("eval_steps", 0)
# 传入模型保存路径,如果没有传入值则默认为"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
custom_print_log = kwargs.get("custom_print_log", None)
# 训练总的步数
num_training_steps = num_epochs * len(train_loader)
if eval_steps:
if self.metric is None:
raise RuntimeError('Error: Metric can not be None!')
if dev_loader is None:
raise RuntimeError('Error: dev_loader can not be None!')
# 运行的step数目
global_step = 0
# 进行num_epochs轮训练
for epoch in range(num_epochs):
# 用于统计训练集的损失
total_loss = 0
for step, data in enumerate(train_loader):
X, y = data
# 获取模型预测
logits = self.model(X.to(device))
loss = self.loss_fn(logits, y.long().to(device)) # 默认求mean
total_loss += loss
# 训练过程中,每个step的loss进行保存
self.train_step_losses.append((global_step, loss.item()))
if log_steps and global_step % log_steps == 0:
print(
f"[Train] epoch: {epoch}/{num_epochs}, step: {global_step}/{num_training_steps}, loss: {loss.item():.5f}")
# 梯度反向传播,计算每个参数的梯度值
loss.backward()
if custom_print_log:
custom_print_log(self)
# 小批量梯度下降进行参数更新
self.optimizer.step()
# 梯度归零
self.optimizer.zero_grad()
# 判断是否需要评价
if eval_steps > 0 and global_step > 0 and \
(global_step % eval_steps == 0 or global_step == (num_training_steps - 1)):
dev_score, dev_loss = self.evaluate(dev_loader, global_step=global_step)
print(f"[Evaluate] dev score: {dev_score:.5f}, dev loss: {dev_loss:.5f}")
# 将模型切换为训练模式
self.model.train()
# 如果当前指标为最优指标,保存该模型
if dev_score > self.best_score:
self.save_model(save_path)
print(
f"[Evaluate] best accuracy performence has been updated: {self.best_score:.5f} --> {dev_score:.5f}")
self.best_score = dev_score
global_step += 1
# 当前epoch 训练loss累计值
trn_loss = (total_loss / len(train_loader)).item()
# epoch粒度的训练loss保存
self.train_epoch_losses.append(trn_loss)
print("[Train] Training done!")
# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def evaluate(self, dev_loader, **kwargs):
assert self.metric is not None
# 将模型设置为评估模式
self.model.eval()
global_step = kwargs.get("global_step", -1)
# 用于统计训练集的损失
total_loss = 0
# 重置评价
self.metric.reset()
# 遍历验证集每个批次
for batch_id, data in enumerate(dev_loader):
X, y = data
# 计算模型输出
logits = self.model(X.to(device))
# 计算损失函数
loss = self.loss_fn(logits, y.long().to(device)).item()
# 累积损失
total_loss += loss
# 累积评价
self.metric.update(logits, y.to(device))
dev_loss = (total_loss / len(dev_loader))
dev_score = self.metric.accumulate()
# 记录验证集loss
if global_step != -1:
self.dev_losses.append((global_step, dev_loss))
self.dev_scores.append(dev_score)
return dev_score, dev_loss
# 模型评估阶段,使用'torch.no_grad()'控制不计算和存储梯度
@torch.no_grad()
def predict(self, x, **kwargs):
# 将模型设置为评估模式
self.model.eval()
# 运行模型前向计算,得到预测值
logits = self.model(x.to(device))
return logits
def save_model(self, save_path):
torch.save(self.model.state_dict(), save_path)
def load_model(self, model_path):
state_dict = torch.load(model_path)
self.model.load_state_dict(state_dict)
Accuracy:
class Accuracy():
def __init__(self, is_logist=True):
# 用于统计正确的样本个数
self.num_correct = 0
# 用于统计样本的总数
self.num_count = 0
self.is_logist = is_logist
def update(self, outputs, labels):
# 判断是二分类任务还是多分类任务,shape[1]=1时为二分类任务,shape[1]>1时为多分类任务
if outputs.shape[1] == 1: # 二分类
outputs = torch.squeeze(outputs, dim=-1)
if self.is_logist:
# logist判断是否大于0
preds = torch.tensor((outputs >= 0), dtype=torch.float32)
else:
# 如果不是logist,判断每个概率值是否大于0.5,当大于0.5时,类别为1,否则类别为0
preds = torch.tensor((outputs >= 0.5), dtype=torch.float32)
else:
# 多分类时,使用'torch.argmax'计算最大元素索引作为类别
preds = torch.argmax(outputs, dim=1)
# 获取本批数据中预测正确的样本个数
labels = torch.squeeze(labels, dim=-1)
batch_correct = torch.sum(torch.tensor(preds == labels, dtype=torch.float32)).cpu().numpy()
batch_count = len(labels)
# 更新num_correct 和 num_count
self.num_correct += batch_correct
self.num_count += batch_count
def accumulate(self):
# 使用累计的数据,计算总的指标
if self.num_count == 0:
return 0
return self.num_correct / self.num_count
def reset(self):
# 重置正确的数目和总数
self.num_correct = 0
self.num_count = 0
def name(self):
return "Accuracy"
注:一开始想偷懒不修改GPU代码,后来发现不用GPU训练太慢了,所以重新定义了cuda加速训练,代码如下:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
其他的模型、损失函数都直接放到device上训练就行。
运行结果:
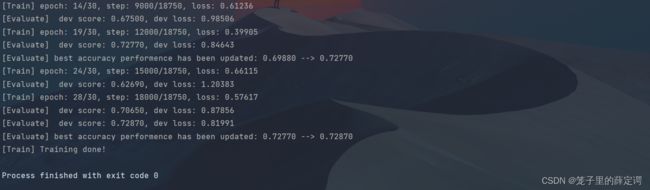
可视化观察训练集与验证集的准确率及损失变化情况。
from nndl import plot
plot(runner, fig_name='cnn-loss4.pdf')
注:plot代码如下
def plot(runner, fig_name):
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
train_items = runner.train_step_losses[::30]
train_steps = [x[0] for x in train_items]
train_losses = [x[1] for x in train_items]
plt.plot(train_steps, train_losses, color='#8E004D', label="Train loss")
if runner.dev_losses[0][0] != -1:
dev_steps = [x[0] for x in runner.dev_losses]
dev_losses = [x[1] for x in runner.dev_losses]
plt.plot(dev_steps, dev_losses, color='#E20079', linestyle='--', label="Dev loss")
# 绘制坐标轴和图例
plt.ylabel("loss", fontsize='x-large')
plt.xlabel("step", fontsize='x-large')
plt.legend(loc='upper right', fontsize='x-large')
plt.subplot(1, 2, 2)
# 绘制评价准确率变化曲线
if runner.dev_losses[0][0] != -1:
plt.plot(dev_steps, runner.dev_scores,
color='#E20079', linestyle="--", label="Dev accuracy")
else:
plt.plot(list(range(len(runner.dev_scores))), runner.dev_scores,
color='#E20079', linestyle="--", label="Dev accuracy")
# 绘制坐标轴和图例
plt.ylabel("score", fontsize='x-large')
plt.xlabel("step", fontsize='x-large')
plt.legend(loc='lower right', fontsize='x-large')
plt.savefig(fig_name)
plt.show()
运行结果:

5.5.4 模型评价
使用测试数据对在训练过程中保存的最佳模型进行评价,观察模型在测试集上的准确率以及损失情况。代码实现如下:
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(test_loader)
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
运行结果:

5.5.5 模型预测
同样地,也可以使用保存好的模型,对测试集中的数据进行模型预测,观察模型效果,具体代码实现如下:
import matplotlib.pyplot as plt
#获取测试集中的一个batch的数据
X, label = next(iter(test_loader))
logits = runner.predict(X,dim=1)
#多分类,使用softmax计算预测概率
pred = F.softmax(logits)
# print(pred)
#获取概率最大的类别
pred_class = torch.argmax(pred[2][0]).cpu().numpy()
label = label[2].item()
#输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
#可视化图片
plt.figure(figsize=(2, 2))
imgs, labels = load_cifar10_batch(folder_path='D:\project\DL\cifar-10-batches-py', mode='test')
plt.imshow(imgs[2].transpose(1,2,0))
plt.savefig('cnn-test-vis.pdf')
运行结果:


5.5.6 什么是预训练模型?什么是迁移学习?
我把预训练模型看做知识铺垫(只不过这里是对计算机的知识铺垫)。
举个例子:现在有个紧急比赛,需要让小baby在一个月内学会跑步。
预训练模型:任务出现之前,我就已经先教会他怎么爬、怎么站立了。现在比赛来了,我只需让它在之前的基础上随便学学都能很快学会。而且耗时要大大缩短!
不使用预训练模型:什么都没教过他,直接让他学会怎么跑步。那他还要自己摸索怎么爬,怎么站立?这两步学会了才能学跑步。但是他本身是一个小baby,让它自己摸索爬和站立的过程是非常长的。等他学完这两步比赛都结束了!
对应到神经网络上:训练一个神经网络要学习的东西其实就是一个合适的参数。
不使用预训练模型就是随机初始化所有的模型参数,然后模型从0开始学习针对当前这个任务的合适参数。
预训练方式表现在模型参数上,就是我之前已经拿一个合适的任务(这个任务可能是和很多任务有共同之处的任务)提前训练好了所有的模型参数(预训练)。我们不需要再从0开始训练所有参数了,但是针对我们目前这个任务,有些参数可能不合适,我们只需要在当前参数的基础上稍加修改(微调)就可以得到比较好的效果,这样学习时间必然会大大减小。而且,由于预训练过程和我们当前的任务不是同时进行的,所以可以提前花很长时间把几千亿乃至万万亿参数(现在应该还没)提前预训练好,以求和更多的具体任务都有重合,从而只需要我们微调就可以在各项任务达到不错的效果。
迁移学习: 顾名思义就是把一个场景学习到的模型应用到另一个场景。
出现这一领域的原因很简单:深度学习以大量数据做支撑才能训练出合适的参数,但是有很大可能我们无法建模型所需规模的数据,所以需要借助迁移学习,在一个模型训练任务中针对某种类型数据获得的关系也可以轻松地应用于同一领域的不同问题。
5.5.7 比较“使用预训练模型”和“不使用预训练模型”的效果。
使用预训练模型已经在上文做了测试,接下来不使用预训练模型做测试:
只需要修改这一行就行:
resnet18_model = resnet18(pretrained=False)
不使用预训练模型运行结果:


使用预训练模型的运行结果:
对比使用预训练模型和不使用预训练模型,可以直观得到三个结果:
1.使用预训练模型收敛速度更快,更稳定(从损失的可视化可以看出)。
2.使用预训练模型的准确率更高(从运行结果可以看出)。
3.我直观感觉训练时间是相差不多的,之所以说使用预训练模型速度更快应该是它的收敛速度更快,但是训练时间应该差不多吧(当时忘了记录一下训练时间,跑一次时间比较长,所以没跑第二遍)。
不对比训练时间有点小遗憾,所以又在我的机器重新训练了两遍,环境配置以及硬件如下:
python 3.6.13
pytorch 1.10.2
cuda 11.3
cudnn 8.0
显卡 GTX1650Ti
使用预训练模型训练时间:
 不使用预训练模型训练时间:
不使用预训练模型训练时间:
 和我上面的感受差不多,使用预训练模型训练时间为584S,不使用预训练模型训练时间为602S,也就差个20S左右。
和我上面的感受差不多,使用预训练模型训练时间为584S,不使用预训练模型训练时间为602S,也就差个20S左右。
思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度ResNet(18,34,50,101和152),并简单谈谈自己的看法。
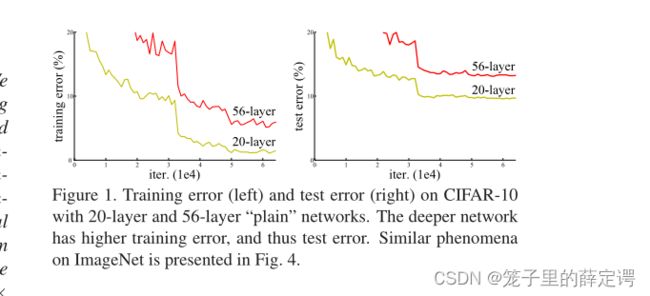
开幕雷击,作者一开始边提出:随着网络层数的加深,暴露出一个对于训练精度来说,被称为“退化“的问题:随着网络深度增加,在训练集上的精度达到饱和,然后迅速下降。显然,这种现象不是过拟合造成的,因为过拟合会使得训练集上的精度极高。如果此时向一个深度适当的模型添加更多层的话会带来更高的训练误差,如上图所示。
然后引出自己的残差网络,并提出结论:不论网络的深浅,使用残差学习总是有好处的:浅时能够加快收敛,深时可以解决退化问题,使求解器找到较好的解。
接下来简单评价ResNet(18,34,50,101和152):


上面两张论文中的结果图可以很直接的得出:对于普通网络结构:更深的 34-layer plain net比稍浅的18-layer plain net在验证集上拥有更高的错误率。对于残差网络结构:结果与plain nets相反,34-layer ResNet的性能优于18-layer ResNet。更重要的是,34-layer ResNet的训练错误率更低,在验证集上的泛化能力更强。这些现象说明 degradation problem已经被很好地解决了,并且从增加的深度中获得了精度的提升。
接着作者提出了三种更深的ResNet网络结构,ResNet50、ResNet101和ResNet152:

ResNet50:通过将34-layer net中的每个2-layer block替换成Fig.5中的bottleneck design获得,结果为一个50-layer ResNet。增加维度时使用上述中的方案B(option B);该模型的计算量为3.8 billion个FLOPs
ResNet101和ResNet152:作者通过使用更多3-layer blocks构建了 101-layer 和 152-layer ResNets,如Table 1所示。虽然152-layer ResNet(11.3 billion FLOPS)已经非常深,但是计算量仍然比VGG-16/19 networks(15.3/19.6 billion FLOPS)低。
最后总结:50/101/152-layer ResNets都比34-layer ResNets精度高很多。所以,随着网络层数的增加,并没有看到退化问题,反而在性能上获得了重大提升。这证明残差学习在一定程度上解决了退化问题,使得网络能够继续从增加的深度中获得性能提升。
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet。
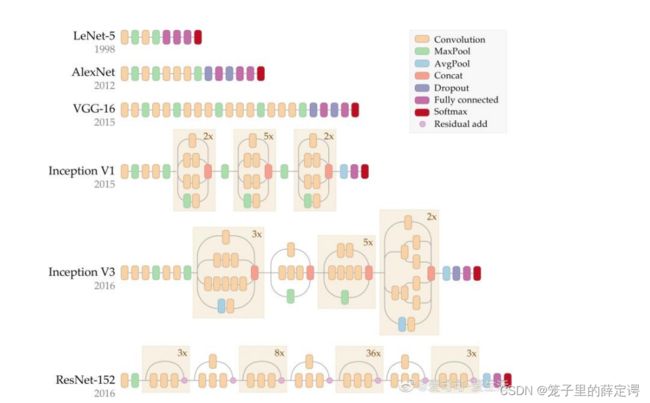
首先放上老师的一张图,对这五种网络结构有一个直观的感受,然后根据时间线简单评价。
首先是Lenet(1998年,Yan LeCun)
 第一眼看到,觉得平平无奇,就是图像输入进去,进行卷积+池化+全连接(原文介绍该网络架构分成三个模块,具体可看原文),但是万事开头难,第一次将卷积神经网络应用到图像分类任务并取得巨大成功足以证明它的含金量。
第一眼看到,觉得平平无奇,就是图像输入进去,进行卷积+池化+全连接(原文介绍该网络架构分成三个模块,具体可看原文),但是万事开头难,第一次将卷积神经网络应用到图像分类任务并取得巨大成功足以证明它的含金量。
紧着着是Alexnet(2012,Alex Krizhevsky)
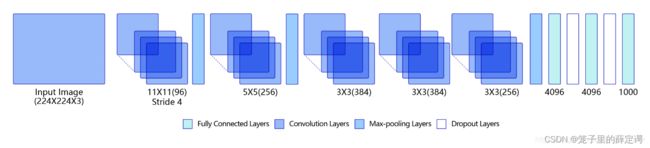 从这张图和最一开始那张图都可以看出网络结构加深了,包含五层卷积和三层全连接,分成了四个模块(具体可见原文)。该网络架构不仅加深了网络结构,而且从数据增广、使用Dropout抑制过拟合、使用ReLu激活函数减少梯度消失现象三种方法改进模型的训练过程,取得当年ImageNet比赛的冠军。
从这张图和最一开始那张图都可以看出网络结构加深了,包含五层卷积和三层全连接,分成了四个模块(具体可见原文)。该网络架构不仅加深了网络结构,而且从数据增广、使用Dropout抑制过拟合、使用ReLu激活函数减少梯度消失现象三种方法改进模型的训练过程,取得当年ImageNet比赛的冠军。
然后是VGG(2014,Simonyan和Zisserman,命名由来是论文作者所在的实验室为Visual Geometry Group)
 由架构图可知,VGG网络结构由13层卷积和3层全连接层。VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。
由架构图可知,VGG网络结构由13层卷积和3层全连接层。VGG网络的设计严格使用3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。 在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。
因为上面的Alexnet模型通过构造多层网络,取得了较好效果,但是只是做深了网络结构并没有给出神经网络设计的方向。VGG通过小尺寸卷积核和pooling层构造深度卷积神经网络,取得更好的效果,证明了增加网络的深度,可以更好的学习图像中
的特征模式。其网络结构设计方法,为构建深度神经网络提供了方向。
再然后就是GoogLeNet(2014)
 GoogLeNet的架构如上图所示,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3 ×3最大池化层来减小输出高宽(具体可见原论文,只做简单评价)。
GoogLeNet的架构如上图所示,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3 ×3最大池化层来减小输出高宽(具体可见原论文,只做简单评价)。
这个就比较有意思了,它的主要特点是网络不仅有深度,还在横向上具有“宽度”(区别于VGG)。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征,而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决这个问题,GoogLeNet提出了一种被称为Inception模块的方案。如 下图 所示:
 (a)是Inception模块的设计思想,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征。
(a)是Inception模块的设计思想,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征。
(b) 为了减小参数量,Inception模块使用了图(b)中的设计方式,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。基于这一设计思想,形成了上图(b)中所示的结构。
最后是ResNet(2015,Kaiming He)
 通过前面几个经典模型学习,可以发现随着深度学习的不断发展,模型的层数越来越多,网络结构也越来越复杂。那么是否加深网络结构,就一定会得到更好的效果呢?从理论上来说,假设新增加的层都是恒等映射,只要原有的层学出跟原模型一样的参数,那么深模型结构就能达到原模型结构的效果。换句话说,原模型的解只是新模型的解的子空间,在新模型解的空间里应该能找到比原模型解对应的子空间更好的结果。但是实践表明,增加网络的层数之后,训练误差往往不降反升。
通过前面几个经典模型学习,可以发现随着深度学习的不断发展,模型的层数越来越多,网络结构也越来越复杂。那么是否加深网络结构,就一定会得到更好的效果呢?从理论上来说,假设新增加的层都是恒等映射,只要原有的层学出跟原模型一样的参数,那么深模型结构就能达到原模型结构的效果。换句话说,原模型的解只是新模型的解的子空间,在新模型解的空间里应该能找到比原模型解对应的子空间更好的结果。但是实践表明,增加网络的层数之后,训练误差往往不降反升。
Kaiming He等人提出了残差网络ResNet来解决上述问题,其基本思想如 下图 所示:
 至于为什么使用ResNet容易学习,以及它的前世今生,我的上个实验报已经详细介绍,不做过多评价。
至于为什么使用ResNet容易学习,以及它的前世今生,我的上个实验报已经详细介绍,不做过多评价。
总结
我特别喜欢拿代码的流程图来形成脑子里的框架,但是卷积实在是没啥代码流程图,就是输入->卷积(清楚输入输出大小,尺寸)->池化->全连接->输出,也就是一个编码器,端到端学习了属于是。
于是参考老师的总结,绘制了一个老师的简易版总结:

卷积分类以及卷积的一些概念我觉得知道干嘛的、懂计算就行; 像 其他卷积 这三种我经常可以见到,用处很大; CNN反向传播是这个专业的基本功,基本功不能丢;经典CNN是常识性的东西,应该懂由来、原理、应用。
参考链接
老师的博客
老师的博客园
五种经典CNN网络讲解
参考文献
[1] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learn- ing applied to document recognition. Proc. of the IEEE, 86(11):2278–2324, 1998
[2] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, pages 1097–1105, 2012.
[3] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014b.
[4]Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolu- tions. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015.
[5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016a.