深度学习实战 1 YOLOv5结合BiFPN
目录
1. BiFPN论文简介
2. 在Common.py中添加定义模块(Concat)
3. 将类名加入进去,修改yolo.py
4. 修改train.py
5. 修改配置文件yolov5.yaml
1. BiFPN论文简介
论文《EfficientDet: Scalable and Efficient Object Detection》地址:https://arxiv.org/abs/1911.09070
BiFPN 全称 Bidirectional Feature Pyramid Network 加权双向(自顶向下 + 自低向上)特征金字塔网络。

图中蓝色部分为自顶向下的通路,传递的是高层特征的语义信息;红色部分是自底向上的通路,传递的是低层特征的位置信息;紫色部分是同一层在输入节点和输入节点间新加的一条边。
- 我们删除那些只有一条输入边的节点。这么做的思路很简单:如果一个节点只有一条输入边而没有特征融合,那么它对旨在融合不同特征的特征网络的贡献就会很小。删除它对我们的网络影响不大,同时简化了双向网络;如上图d 的 P7右边第一个节点
- 如果原始输入节点和输出节点处于同一层,我们会在原始输入节点和输出节点之间添加一条额外的边。思路:以在不增加太多成本的情况下融合更多的特性;
- 与只有一个自顶向下和一个自底向上路径的PANet不同,我们处理每个双向路径(自顶向下和自底而上)路径作为一个特征网络层,并重复同一层多次,以实现更高层次的特征融合。如下图EfficientNet 的网络结构所示,我们对BiFPN是重复使用多次的。而这个使用次数也不是我们认为设定的,而是作为参数一起加入网络的设计当中,使用NAS技术算出来的。

Weighted Feature Fusion 带权特征融合:学习不同输入特征的重要性,对不同输入特征有区分的融合。
设计思路:传统的特征融合往往只是简单的 feature map 叠加/相加 (sum them up),比如使用concat或者shortcut连接,而不对同时加进来的 feature map 进行区分。然而,不同的输入 feature map 具有不同的分辨率,它们对融合输入 feature map 的贡献也是不同的,因此简单的对他们进行相加或叠加处理并不是最佳的操作。所以这里我们提出了一种简单而高效的加权特融合的机制。
常见的带权特征融合有三种方法。

2. 在Common.py中添加定义模块(Concat)
# 结合BiFPN 设置可学习参数 学习不同分支的权重
# 两个分支concat操作
class BiFPN_Concat2(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat2, self).__init__()
self.d = dimension
self.w = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
# 设置可学习参数 nn.Parameter的作用是:将一个不可训练的类型Tensor转换成可以训练的类型
parameter
# 并且会向宿主模型注册该参数 成为其一部分 即model.parameters()会包含这个parameter
# 从而在参数优化的时候可以自动一起优化
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1]]
return torch.cat(x, self.d)
# 三个分支concat操作
class BiFPN_Concat3(nn.Module):
def __init__(self, dimension=1):
super(BiFPN_Concat3, self).__init__()
self.d = dimension
self.w = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.epsilon = 0.0001
def forward(self, x):
w = self.w
weight = w / (torch.sum(w, dim=0) + self.epsilon) # 将权重进行归一化
# Fast normalized fusion
x = [weight[0] * x[0], weight[1] * x[1], weight[2] * x[2]]
return torch.cat(x, self.d)
3. 将类名加入进去,修改yolo.py
models/yolo.py中的parse_model函数中搜索elif m is Concat:语句,在其后面加上BiFPN_Concat相关语句
# 添加bifpn_concat结构
elif m in [Concat, BiFPN_Concat2, BiFPN_Concat3]:
c2 = sum(ch[x] for x in f)

4. 修改train.py
1.调用模块
from models.common import BiFPN_Concat2, BiFPN_Concat3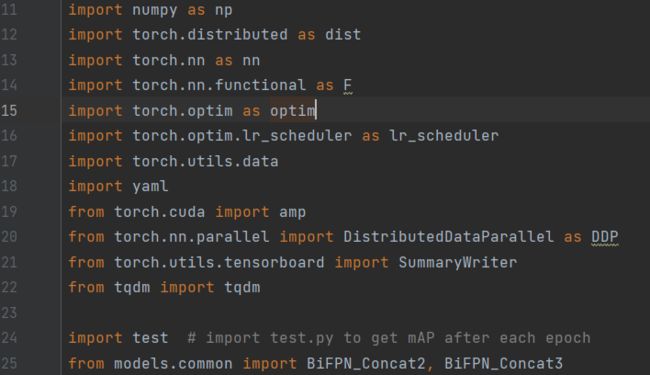
2.向优化器器中添加BiFPN的权重参数
yolov5.0 版本将BiFPN_Concat2和BiFPN_Concat3函数中定义的w参数,Ctrl+F快捷检索pg0
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in model.named_modules():
# hasattr: 测试指定的对象是否具有给定的属性,返回一个布尔值
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter):
pg2.append(v.bias) # biases
if isinstance(v, nn.BatchNorm2d):
pg0.append(v.weight) # no decay
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):
pg1.append(v.weight) # apply decay
elif isinstance(v, BiFPN_Concat2) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
pg1.append(v.w)
elif isinstance(v, BiFPN_Concat3) and hasattr(v, 'w') and isinstance(v.w, nn.Parameter):
pg1.append(v.w)
if opt.adam:
optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
logger.info('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
del pg0, pg1, pg2
yolov5.6.0以上版本可以Ctrl+F快捷检索# Optimizer,以6.2版本为例

5. 修改配置文件yolov5.yaml
将Concat全部换成BiFPN_Concat
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, BiFPN_Concat2, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, BiFPN_Concat2, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14,6], 1,BiFPN_Concat3, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, BiFPN_Concat2, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]