综述:计算机视觉中的通道注意力机制
综述:计算机视觉中的通道注意力机制
-
- 1. INTRODUCTION:
- 2. 计算机视觉中的注意力机制
-
- 2.1. 通用形式
- 2.2 通道注意力 | channel attention | what to pay attention to
-
- 2.2.1 SENet
- 2.2.2 GSoP-Net
- 2.2.3 SRM
- 2.2.4 GCT
- 2.2.5 ECANet
- 2.2.6 FcaNet
- 2.2.7 EncNet
- 2.2.8 通道注意力机制模型总结
- 3. 论文链接
这是一篇从数据域的角度,给注意力机制分为六类的综述,涵盖论文数量多。
论文题目:Attention Mechanisms in Computer Vision: A Survey
论文链接:https://arxiv.org/pdf/2111.07624.pdf
论文代码: https://github.com/MenghaoGuo/Awesome-Vision-Attentions
ABSTRACT: 人类可以自然有效地在复杂场景中发现显著区域。在这种观察的激励下,注意力机制被引入计算机视觉,目的是模仿人类视觉系统的这一方面。这种注意力机制可以看作是一个基于输入图像特征的动态权重调整过程。注意力机制在许多视觉任务中取得了巨大的成功,包括图像分类、目标检测、语义分割、视频理解、图像生成、三维视觉、多模态任务和自监督学习。在这项调查中,我们对计算机视觉中的各种注意力机制进行了全面的回顾,并根据方法对它们进行了分类,如通道注意、空间注意、时间注意和分支注意;相关代码在https://github.com/MenghaoGuo/Awesome-Vision-Attentions。我们还提出了注意力机制研究的未来方向。


1. INTRODUCTION:
将注意力转移到最重要的部分被称为注意力机制;人类使用视觉系统来帮助高效地分析和理解复杂场景。这反过来又促使研究人员将注意力机制引入计算机视觉系统,以提高其性能。在视觉系统中,注意力机制可以被视为一个动态选择过程,通过根据输入的重要性自适应地加权特征来实现。注意力机制在很多视觉任务中都有好处,例如:图像分类、目标检测、语义分割、人脸识别、人物再识别、动作识别、少量显示学习、医学图像处理,图像生成、姿势估计、超分辨率、三维视觉和多模式任务。

过去十年,注意力机制在计算机视觉中逐渐起重要作用。图3简要地总结了基于deep learning 的CV领域中attention-based模型的发展历史。成果大致可以分为四个阶段。
- 第一阶段:从RAM开始的开创性工作,将深度神经网络与注意力机制相结合。它反复预测重要区域。并以端到端的方式更新整个网络。之后,许多工作采用了相似的注意力策略。在这个阶段,RNN在注意力机制中是非常重要的工具。
- 第二阶段:从STN中,引入了一个子网络来预测放射变换用于选择输入中的重要区域。明确预测待判别的输入特征是第二阶段的主要特征。DCN是这个阶段的代表性工作。
- 第三阶段:从SENet开始,提出了通道注意力网络(channel-attention network)能自适应地预测潜在的关键特征。CBAM和ECANet是这个阶段具有代表性的工作。
- 第四阶段:self-attention自注意力机制。自注意力机制最早是在NLP中提出并广泛使用。Non-local网络是最早在CV中使用自注意力机制,并在视频理解和目标检测中取得成功。像EMANet,CCNet,HamNet和the Stand-Alone Network遵循此范式并提高了速度,质量和泛化能力。最近,深度自注意力网络(visual transformers)出现,展现了基于attention-based模型的巨大潜力。
| Attention cateory | Description | Translation |
|---|---|---|
| Channel attention(what to pay attention to) | Generate attention mask across the channel domain and use it to select important channels | 在通道域中生成注意力掩码,并使用它选择重要通道 |
| Spatial attention(where to pay attention to) | Generate attention mask across spatial domains and use it to select important spatial regions or predict the most relevant spatial position directly | 生成跨空间域的注意力掩码,并使用它来选择重要的空间区域或直接预测最相关的空间位置 |
| Temporal attention(when to pay attention to) | Generate attention mask in time and use it to select key frames | 及时生成注意力掩码,并使用它选择关键帧 |
| Branch attention(which to pay attention to) | Generate attention mask across the different branches and use it to select important branches | 在不同的分支上生成注意力掩码,并使用它来选择重要的分支 |
| Channel & spatial attention | Predict channel and spatial attention masks separately or generate a joint 3-D channel, height, width attention mask directly and use it to select important features | 分别预测通道和空间注意力掩码,或直接生成一个联合的三维通道、高度、宽度注意力掩码,并使用它选择重要特征 |
| Spatial & temporal attention | Compute temporal and spatial attention masks separately, or produce a joint spatiotemporal attention mask, to focus on informative regions | 分别计算时间和空间注意力掩码,或生成联合时空注意力掩码,以关注信息区域 |

2. 计算机视觉中的注意力机制
| Symbol | Description | Translation |
|---|---|---|
| X | input feature map, X ∈ R C × H × W {X\in{R^{C\times{H}\times{W}}}} X∈RC×H×W | 输入特征图,维度 |
| Y | output feature map | 输出特征图 |
| W | learnable kernel weight | 待学习权重 |
| FC | fully-connected layer | 全连接层 |
| Conv | convolution | 卷积层 |
| GAP | global average pooling | 全局平均池化 |
| GMP | global max pooling | 全局最大池化 |
| [ ] | concatenation | 拼接(串联) |
| δ | ReLU activation | ReLU激活函数 |
| σ | sigmoid activation | sigmoid激活函数 |
| tanh | tanh activation | tanh激活函数 |
| Softmax | softmax activation | softmax激活函数 |
| BN | batch normalization | 批标准化 |
| Expand | expan input by repetition | 重复输入 |
2.1. 通用形式
当我们在日常生活中看到一个场景时,我们会把注意力集中在识别区域,并快速处理这些区域。上述过程可表述为:
A t t e n t i o n = f ( g ( x ) , x ) {Attention = f(g(x),x)} Attention=f(g(x),x)
g ( x ) {g(x)} g(x)可以表示为产生注意力,这对应于注意待识别区域的过程; f ( g ( x ) , x ) {f(g(x),x)} f(g(x),x)表示基于attention g ( x ) {g(x)} g(x)处理输入 x x x,这与处理关键区域、获取信息是一致的。
根据上述定义,我们发现几乎所有现存的注意力机制都能够被写成上述形式。这里我们列举了self-attention的Non-Local和spatial attention的SENet。
Non-Local可以写成:

SENet可以写成:

因此,我们会通过上述形式介绍各种注意力机制方式。
2.2 通道注意力 | channel attention | what to pay attention to

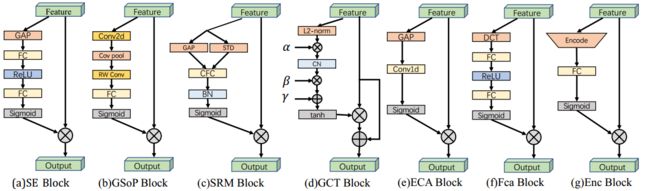
2.2.1 SENet


- squeeze模块:全局平均池化(GAP),压缩通道 [ H , W ] [H,W] [H,W]-> [ 1 , 1 ] [1,1] [1,1]
- excitation模块:后接全连接层( W 1 W_1 W1)->ReLU层(δ)->全连接层( W 2 W_2 W2)->Sigmoid(σ)
- 将得到的结果和原特征图相乘,为每一个通道给不同的权重
2.2.2 GSoP-Net

创新点:改进了squeeze模块。global average pooling(GAP) -> global second-order pooling(GSoP)

动机:SENet仅仅采用了全局平均池化方法,GSoP-Net认为这是不够的,这限制了注意力机制的建模能力,因此提出了global second-order pooling(GSoP) block在收集全局信息的同时对高阶统计数据建模.
和SEBlock一样,GSoPBlock同样有 squeeze和excitation两部分结构。
- squeeze模块:
- 1 × 1 {1\times1} 1×1卷积(Conv)将通道维度从 [ C , H , W ] [C,H,W] [C,H,W]-> [ C ′ , H , W ] [C^{'},H,W] [C′,H,W], ( C ′ < C ) (C^{'}
- 协方差矩阵(Cov) C ′ × C ′ {C^{'}\times{C^{'}}} C′×C′,计算各通道间的相关性
- 接下来,对协方差矩阵执行逐行归一化。归一化协方差矩阵中的每个 ( i , j ) {(i,j)} (i,j)表示信道i与信道j相关联
- excitation模块
1.行卷积(RC)以保持结构信息并输出向量
2. 利用全连接层(W)和sigmoid函数(σ)得到C维注意力向量(通道权重) - 将得到的结果和原特征图相乘,为每一个通道给不同的权重
通过使用全局二阶池化(GSoP),GSoPBlock提高了通过SEBlock收集全局信息的能力。然而,这是以额外计算为代价的。因此,通常在几个剩余块之后添加单个GSoPBlock。
2.2.3 SRM

创新点:改进了squeeze模块和excitation模块。提出了style-based recalibration module (SRM)。它利用输入特征的均值(mean)和标准差(std)来提高捕获全局信息的能力。它还采用了一个轻量级的通道全连接层(CFC)代替原有的全连接层(FC),以减少计算需求。
动机:以风格迁移的成功为动机,即提升精度的同时,减少计算量,提出了新的squeeze模块和轻量级全连接层。
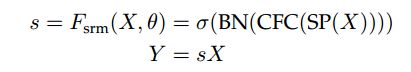
- squeeze模块:使用style pooling(SP),它结合了全局平均池化和全局标准差池化。(为什么输出为 C × d {C\times{d}} C×d:当只用全局平均池化就是 C × 1 {C\times{1}} C×1;当用了全局平均池化和全局标准差池化就是 C × 2 {C\times{2}} C×2;当用了全局平均池化和全局标准差池化和全局最大池化就是 C × 3 {C\times{3}} C×3)
- excitation模块:
- 与通道等宽的全连接层CFC(Channel-wise fully-connected layer) ,含义:通道维度由 [ C , d ] {[C,d]} [C,d]变为 [ C , 1 ] {[C,1]} [C,1],即对于每一个通道,都有一个全连接层输入为d,输出为1(原文:This operation can be viewed as a channel-independent, fully connected layer with d input nodes and a single output)
- 利用BN层和sigmoid函数(σ)得到C维注意力向量
- 将得到的结果和原特征图相乘,为每一个通道给不同的权重
2.2.4 GCT

动机:由于excitation模块中全连接层的计算需求和参数数量,在每个卷积层之后使用SE块是不切实际的。提出了gated channel transformation (GCT)。减少计算量,在backbone中可以加入更多层注意力机制。
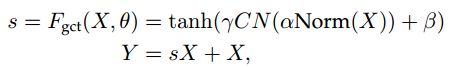
- l2-normalization(Norm),对输入特征图Norm,通道数从 C , H , W {C,H,W} C,H,W-> [ C , 1 , 1 ] [C,1,1] [C,1,1],乘以可训练权重 α \alpha α,输出结果作为第二部分的输入用 s i n s_{in} sin表示
- channel normalization(CN),对应图中中间部分,具体操作为
s o u t = C N o r m ( s i n ) s i n ; s i n , s o u t = [ C , 1 , 1 ] {s_{out}=\cfrac{{\sqrt{C}}}{Norm(s_{in})}}s_{in}; s_{in},s_{out}=[C,1,1] sout=Norm(sin)Csin;sin,sout=[C,1,1]
- 乘以可训练权重 γ \gamma γ和偏置 β \beta β,输出结果用 s ′ s^{'} s′表示
- s = 1 + t a n h ( s ′ ) s=1+tanh(s^{'}) s=1+tanh(s′)
GCT block的参数比SE block少,而且由于它很轻量,可以添加到CNN的每个卷积层之后。
2.2.5 ECANet

创新点:论文动机出发点说了一大堆,具体表现就是,用一维卷积替换了SENet中的全连接层

- 全局平均池化(GAP)
- 一维卷积(Conv1D)后接激活函数Sigmoid(σ)
- 将得到的结果和原特征图相乘,为每一个通道给不同的权重
注:文中对卷积核大小有自适应算法,即根据通道的长度,调整卷积核k的大小。原论文给出超参数 γ = 2 {\gamma=2} γ=2, b = 1 {b=1} b=1。 ∣ ∣ o d d {||_{odd}} ∣∣odd表示k只能取奇整数

2.2.6 FcaNet

动机:在squeeze模块中仅使用全局平均池化(GAP)限制了表达能力。为了获得更强大的表示能力,他们重新思考了从压缩角度捕获的全局信息,并分析了频域中的GAP。他们证明了全局平均池是离散余弦变换(DCT)的一个特例,并利用这一观察结果提出了一种新的多光谱注意通道(multi-spectral channel attention)。

- 将输入特征图 x ∈ R C × H × W {x\in{R^{C\times{H}\times{W}}}} x∈RC×H×W分解(Group)为许多部分 x i ∈ R C i × H × W {x^{i}\in{R^{C^{i}\times{H}\times{W}}}} xi∈RCi×H×W,每一段长度相等
- 对每一段 x i {x^i} xi应用2D 离散余弦变换(DCT, discrete cosine transform)。2D DCT可以使用预处理结果来减少计算
- 在处理完每个部分后,所有结果都被连接到一个向量中
- 后接全连接层( W 1 W_1 W1)->ReLU层(δ)->全连接层( W 2 W_2 W2)->Sigmoid(σ)
- 将得到的结果和原特征图相乘,为每一个通道给不同的权重
注:2D DCT 看不懂。。。。。。
2.2.7 EncNet

动机:受SENet的启发,提出了上下文编码模块(CEM, context encoding module),该模块结合了语义编码损失(SE-loss, semantic encoding loss),以建模场景上下文和对象类别概率之间的关系,从而利用全局场景上下文信息进行语义分割。

给定一个输入特征映射,CEM首先在训练阶段学习K个聚类中心D, D = { d 1 , . . . , d K } {D=\{d_1,...,d_K\}} D={d1,...,dK}和一组平滑因子S, S = { s 1 , . . . , s K } {S=\{s_1,...,s_K\}} S={s1,...,sK}。接下来,它使用软分配权重对输入中的局部描述子和相应的聚类中心之间的差异进行求和,以获得置换不变描述子。然后,为了提高计算效率,它将聚合应用于K个簇中心的描述符,而不是级联。形式上,CEM可以写成如上公式。
2.2.8 通道注意力机制模型总结
3. 论文链接
| 论文缩写 | 论文名称 | 链接 | 权重范围 | 论文投稿 |
|---|---|---|---|
| SE Block | Squeeze-and-Excitation Networks | (0,1) | CVPR2018 |
| GSoP Block | Global Second-order Pooling Convolutional Networks | (0,1) | CVPR2019 |
| SRM Block | SRM : A Style-based Recalibration Module for Convolutional Neural Networks | (0,1) | ICCV2019 |
| GCT Block | Gated Channel Transformation for Visual Recognition | (0,1) | CVPR2020 |
| ECA Block | ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks | (0,1) | CVPR2020 |
| Fca Block | FcaNet: Frequency Channel Attention Networks | (0,1) | ICCV2021 |
| Enc Block | Context Encoding for Semantic Segmentation | (-1,1) | CVPR2018 |